Preface
主要内容:
在前面两篇SVM博客中我们所考虑的都是样本数据可以继续线性划分的情况,在这里我们将介绍非线性划分。
L1 Norm Soft Margin SVM(软间隔SVM)
Coordinate Ascent(坐标上升法)
Sequential Minimal Optimization(序列最小优化算法, SMO)
L1 Norm Soft Margin SVM
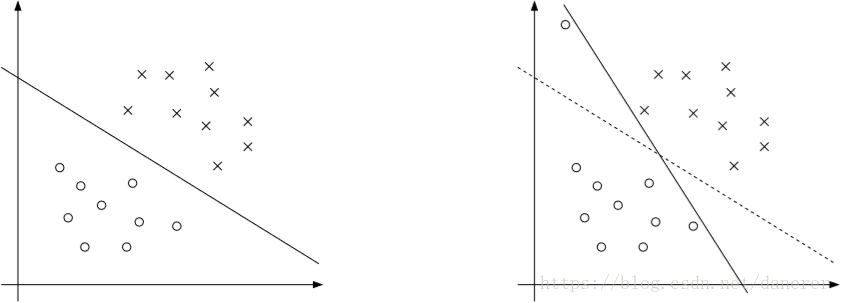
在下图中分别展示了两种情况:
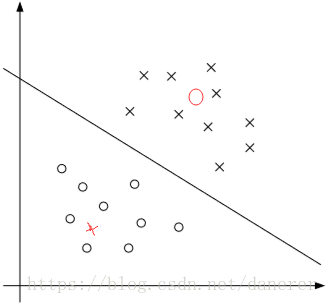
- 一个离群点(或噪声)可以造成超平面的移动,这可以看出离群点(或噪声)对于超平面的划分造成了不好的影响。
- 一个离群点(或噪声)在另外一个类中,这时我们就无法进行线性划分。
这时我们的原始问题就可以定义为:
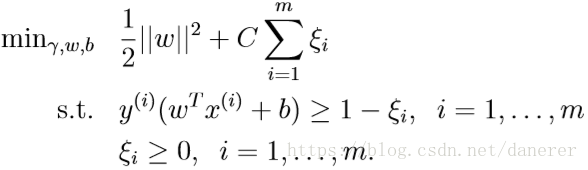
其中加入离群点(或噪声)的影响因素
。
引入非负参数
(松弛变量),就允许某些样本点的函数间隔小于 1,即在最大间隔区间里面,或者函数间隔是负数,即样本点在对方的区域中。
控制参数
权重大小,
越大表明离群点对目标函数影响越大,也就是越不希望看到离群点。
按照以前的办法,我们首先够造拉格朗日算子:
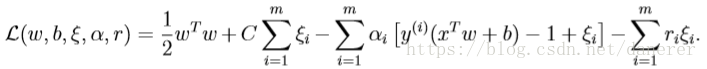
接着我们构造这个原始优化问题的对偶问题:
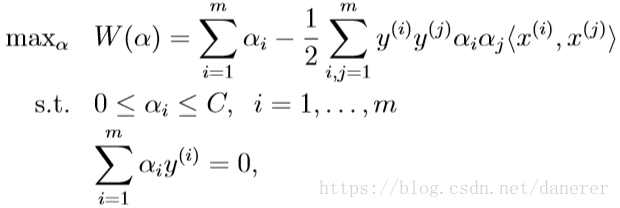
继而通过KKT条件,我们得到下述用于求解优化问题最优解的
的收敛条件:
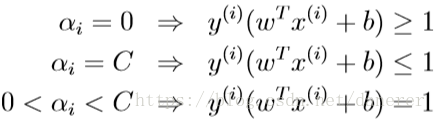
Coordinate Ascent
定义无约束优化问题为:
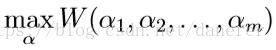
现在使用坐标

对于这个算法的解释为:
最内层循环语句表示的意思是,求除了
之外所有参数都固定的
的最大值。
这里我们进行最大化求导的顺序 i 是从 1 到 m,可以通过更改优化顺序来使 W 能够更快地增加并收敛。如果 W 在内循环中能够很快地达到最优,那么坐 标上升法会是一个很高效的求极值方法。
在下图中,我们可以清楚的看出坐标上升法的结果:
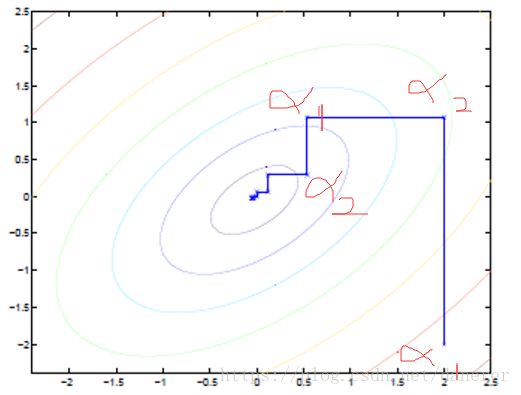
椭圆代表了二次函数的各个等高线,变量数为 2,起始坐标是(2,-2)。图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。先保持
不变,变化
使得函数值最大,记录此时的
,再保持
,变化
函数值最大,记录此时的
最后得到收敛点——最大值。
Sequential Minimal Optimization
我们回到解决原始优化问题的对偶问题上来:
这里我们将使用改变的坐标上升法来解决问题:
按照坐标上升的思路,我们首先固定除
以外的所有参数,然后在
上求最大值。但是只是固定一个
参数,将不能使得还满足约束条件 。所以这里我们使用Sequential Minimal Optimization(序列最小优化算法, SMO)算法来解决问题。即我们固定两个
以外的所有参数,然后此基础上上求最大值,即下图所示:

接下来我们通过选择
来具体探索SMO算法。
首先我们知道对偶优化问题的约束条件
。
所以有:
其次对于
方形约束条件,我们可以得到:
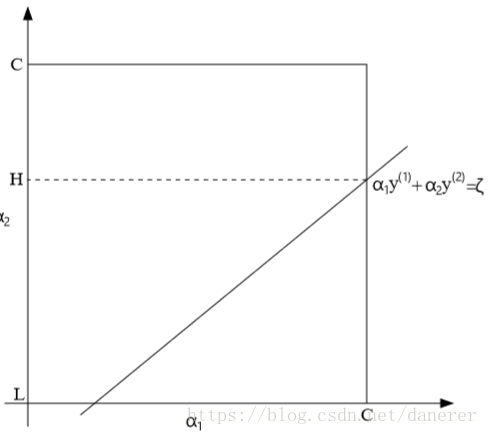
所以有:
所以有:
由于固定两个
以外的所有参数,所以有得到一个二次函数:
从我们十分容易的得到二次函数的最值。
最后我们需要考虑
方形约束条件,
当二次函数的最值的在方形约束条件规定的区域内时,我们无需进行任何工作;
当二次函数的最值的不在方形约束条件规定的区域内时,我们需进行裁剪,使其落在区域内;
总之,二次函数的最值一定在方形约束条件规定的区域内的
线段上。