论文:Relation Networks for Object Detection
论文链接:https://arxiv.org/abs/1711.11575
代码链接:https://github.com/msracver/Relation-Networks-for-Object-Detection
这篇是CVPR2018的oral文章,通过引入object relation module来刻画object之间的关系,借助这样的attention来提升object detection的效果。
这篇文章的出发点在于目前大部分的目标检测(object detection)算法都是独立地检测图像中的object,但显然如果模型能学到object之间的关系显然对于检测效果提升会有帮助,因此这篇文章希望在检测过程中可以通过利用图像中object之间的相互关系或者叫图像内容(context)来优化检测效果,这种关系既包括相对位置关系也包括图像特征关系。显然,关于object的相对位置关系的利用是一个非常有意思的点,尤其是能够实现相对位置关系的attention非常不易,这也是这篇文章的吸引力。具体做法上借鉴了最近几年火热的attention机制(主要是attention is all you need这篇文章的思想)的启发,这篇文章提出一个模块(module):object relation module来描述object之间的关系,从而以attention的形式附加到原来的特征上最后进行回归和分类,另外这篇文章的一个亮点是同时将这种attention机制引入nms操作中,不仅实现了真正意义上的end-to-end训练,而且对于原本的检测网络也有提升。值得注意的是object relation module和网络结构的耦合度非常低,同时输出的维度和输入的维度相同,因此可以非常方便地插入到其他网络结构中,而且可以叠加插入。
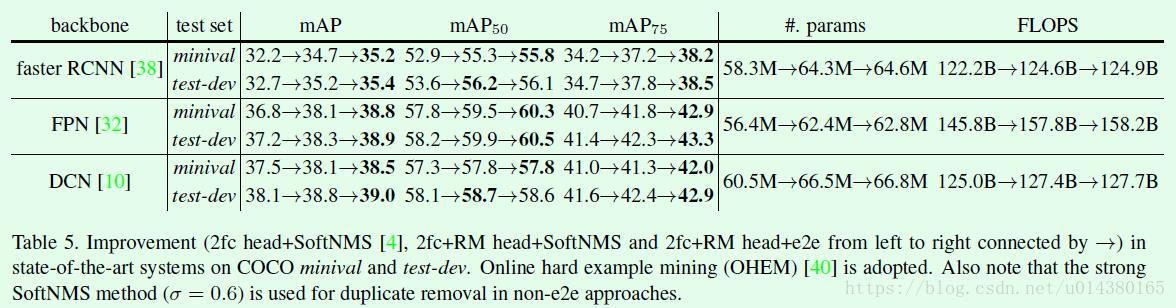
在这篇文章中,object relation module主要放在两个全连接层后面和NMS模块,如Figure1中的红色虚线框所示。在Figure1中,作者将目前目标检测算法分为4步:1、特征提取主网络;2、得到ROI及特征(RPN网络就包含在其中);3、基于ROI做边框回归和object分类;4、NMS处理,去除重复框。从作者的分步情况和源码可以清晰地看出,这篇文章主要是基于Faster RCNN系列算法(Faster RCNN,FPN等)引入object relation module。
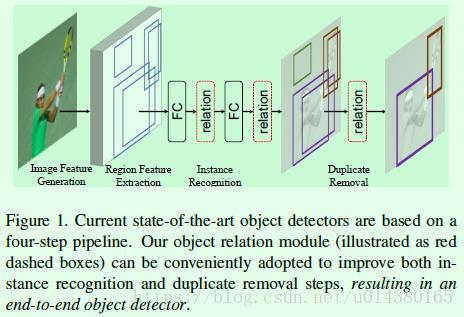
接下来介绍object relation module。因为这篇文章是借鉴了attention is all you need中的attention思想,因此先来了解下那篇文章中的主要公式。在attention is all you need这篇文章中介绍了一个基本的attention模块:scaled dot-product attention,如公式1所示。
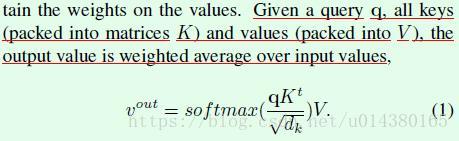
接下来定义两个重要的变量。假设输入中有N个object,那么N个object的两种特征集合如下所示,fA是常规的图像特征(appearance feature),fG是位置特征(geometric feature)。这两种特征是后续算法的基础。
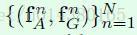
那么受公式1的启发,可以用公式2来刻画第n个object和所有object之间的关系特征(relation feature)。其中fAm表示第m个object的图像特征。Wv是一个线性变换操作,在代码中用1*1的卷积层实现。wmn是用来描述不同object之间的关系权重(relation weight),该变量通过后面的一系列公式可以得到。计算得到的关系特征fR将和原有的图像特征fA融合并传递给下一层网络,这就完成了attention过程。那么公式2和公式1有什么联系呢?简单讲,公式2中的WV对应公式1中的V,公式2中的wmn对应公式1中的softmax()。
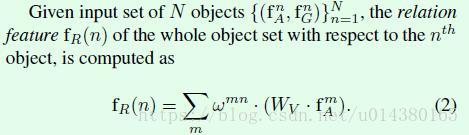
公式2中的wmn通过下面的公式3实现。从公式形式可以看出是一个归一化操作,因此在源码中也是通过softmax层实现(和公式1中的softmax操作对应),只不过对输入中的wG先做了一个log操作,然后将log(wG)+wA作为softmax的输入就能得到公式3。提前说一下该公式中的两个重要变量wG和wA分别表示object的位置特征权重(geometric weight)和object的图像特征权重(appearance weight),后面通过公式4和5分别得到。这里我直接用wG代替wGmn,用wA代替wAmn,一方面是因为实际代码实现中对这些变量的实现都是基于所有object统一得到,另一方面是书写简单。

公式4是计算公式3中的wA变量,也就是图像特征权重。在代码中,WKfA通过全连接层来实现,WK就是全连接层的参数,fA就是object特征;同理WQfA也是通过全连接层实现,WQ是全连接层参数。最后再做一个scale操作。
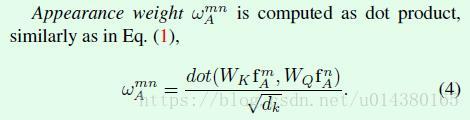
公式5是计算公式3中的wG变量,也就是位置特征权重。首先对fG做了坐标上的变换,如下面截图,主要进行尺度归一化和log操作,可以增加尺度不变性,不至于因为数值变化范围过大引起训练的发散。可以看出坐标变换公式和目标检测算法中的回归目标构造非常相似,最大的不同点在于对x和y做了log操作,原因在于这里要处理的xm与xn、ym与yn之间的距离要比目标检测算法中的距离远,因为目标检测算法中的距离是预测框和roi之间的距离,而这里是不同预测框(或者说是不同roi)之间的距离,因此加上log可以避免数值变化范围过大。EG操作主要是将4维的坐标信息embedding成高维的坐标信息(比如默认是64维),借鉴的是attention is all you need这篇文章的思想,主要由一些cosine函数和sine函数构成。接着,将WG和embedding特征相乘,这里WG也是通过全连接层实现的。最后的max操作类似relu层,主要目的在于对位置特征权重做一定的限制。wG的引入是本文和attention is all you need这篇文章较大的不同点。

fG的坐标变换公式:
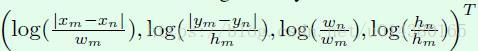
在得到一个关系特征fR后,这篇文章最后的做法是融合多个(Nr个,默认是16)关系特征后再和图像特征fA做融合,如公式6所示。这里有个细节是关于关系特征的融合方式,这里采用的concat,主要原因在于计算量少,因为每个fR的通道维度是fA的1/Nr倍,concat后的维度和fA相同。假如用element-wise add的方式进行融合,那么每个fR的维度和fA都一样,这样的加法计算量太大。

综上,可以用下面的Algorithm 1来概括前面提到的公式算法,源码中的实现基本上和Algorithm 1相同,这在前面介绍公式的时候已经详细介绍了,这里就不再赘述。注意几个参数的默认值:dk默认是64,dg默认是64。

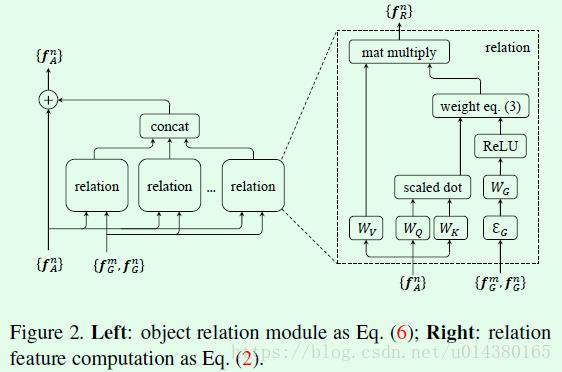
Figure2是用图表来描述Algorithm 1的算法过程。左图是整体上的attention模块和图像特征fA的融合;右图是attention模块的详细构建过程,和前面的公式2~5对应。
介绍完object relation module,接下来就是怎么应用在目标检测算法中了。Figure3是object relation module插入目标检测算法的示意图,左图是插入两个全连接层的情况,在全连接层之后会基于提取到的特征和roi的坐标构建attention,然后将attention加到特征中传递给下一个全连接层,再重复一次后就开始做框的坐标回归和分类。右图是插入NMS模块的情况,图像特征通过预测框得分的高低顺序和预测框特征的融合得到,然后将该融合特征与预测框坐标作为relation模块的输入得到attention结果,最后将NMS当作是一个二分类过程,并基于relation模块输出特征计算分类概率。
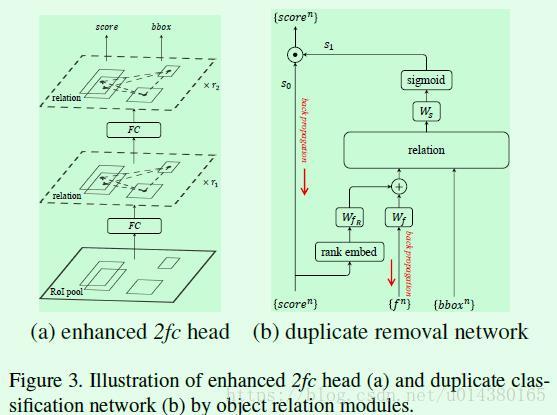
下面以object relation module插入全连接层为例,了解下这篇文章大致是怎么做的。首先是原有的全连接层形式如公式9所示:

这篇文章直接在每个全连接层后面接RM(relation module),输出的维度和输入维度一致,如公式10所示。RM右上角的r1和r2表示数量,源码中默认是1,因为RM不改变输入的维度,所以RM的数量可以任意添加。
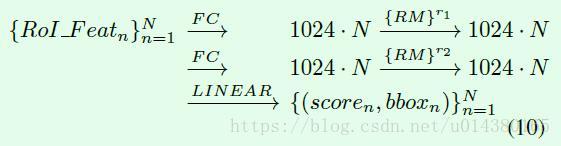
介绍完relation module在检测模块(全连接层)的嵌入后,另一部分重要的内容是relation module在NMS模块的嵌入。
NMS的思想简单讲就是根据将和当前预测得分最高的框的IOU大于某个阈值的框过滤。因此这其实是一个二分类的问题,也就是针对每个ground truth,只有一个预测为该类的框是对的,其他预测为该类的框都是错的。具体实现参考前面的Figure3(b),其中s0是预测框的socre,这个socre对应公式9和10中最后一行的输出socre;s1是二分类的结果(1表示对的;0表示错的,要移除)。那么这个二分类怎么做呢?主要分成3步:1、先获取输入score的排序信息(index),然后对index做embedding,并将embedding后的index和图像特征(f)通过一些全连接层(维度从1024降为128)后进行融合,融合后的特征作为relation module的输入之一。2、预测框的坐标作为relation module的另一个输入,经过relation module后得到关系特征。3、关系特征经过一个线性变换(Figure3(b)中的Ws)后作为sigmoid的输入得到分类结果,这样就完成了预测框的二分类,且基于的特征引入了attention。
因此将NMS纳入end-to-end训练后,整体网络的损失函数不仅包含原来的坐标回归和分类损失函数,还包含NMS的二分类损失函数。
实验结果:
Table1主要做了3个验证:1、验证引入位置特征(geometric feature)的有效性(a);2、验证关系特征数量的影响(b);3、验证relation module在两个全连接层中的数量的影响(c)。

Table2主要是验证RM效果提升是否是因为参数量增加带来的。因此这里做了一些增加fc层、加宽fc层和增加residual结构的操作,最后表明效果的提升并非由于参数量提升带来。
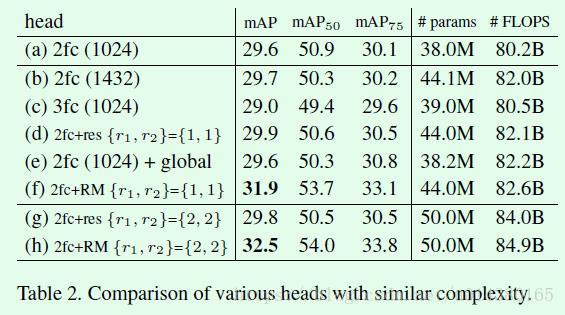
Table5是关于在不同算法上引入FM的效果。