Scale-Aware Trident Networks for Object detection
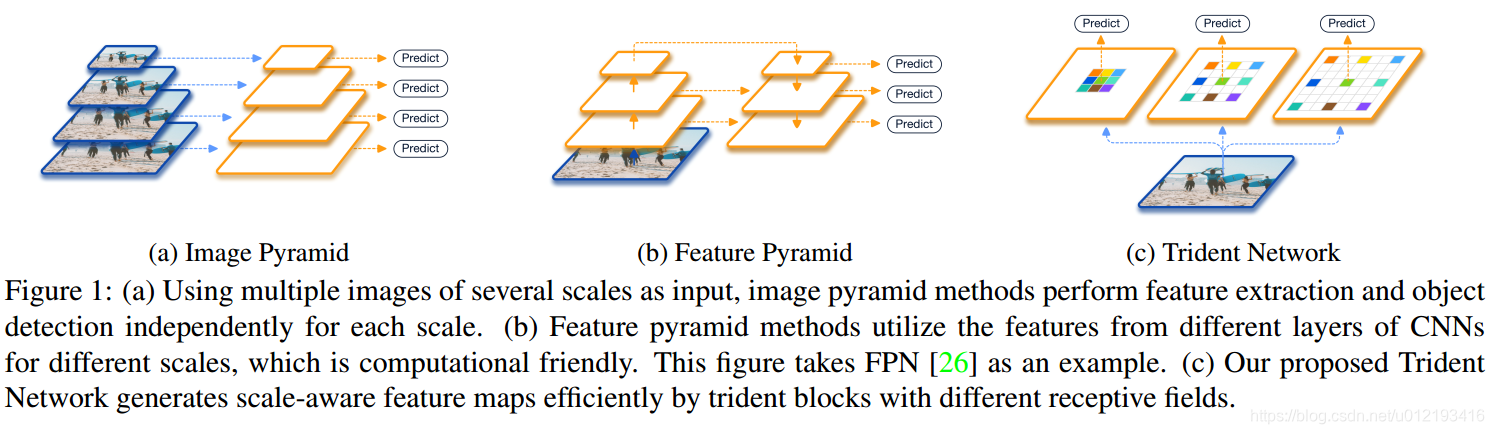
传统: image pyramid(直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中进行检测,multi-scale training/testing 仍然是一个不可缺少的组件)
DL: feature pyramid(FPN,top-down 分支补充底层的语义信息不足)
对于一个backbone有哪些因素会影响性能。
Network depth
Downsample rate
Receptive field
前两者,网络越深结果越好,下采样次数过多对于小物体的检测有负面影响。
验证性试验:分别使用一个resnet50和resnet101作为backbone,改变作用一个stage中每个3*3 conv的dilation rate,只改变网络的感受野。不用尺度物体的检测性能和dilation rate正相关,更大的感受野对于达吾提性能对更好,更小的感受野对于小物体更加友好。

那么有没有办法将不同的感受野的有点结合在一起?
TridentNet在原始的backbone上做了三点变化:
第一:构造了不同receptive field的parallel multi-branch
第二:对于trident block中每一个branch的weight是share的
第三:对于每个branch,训练和测试都只负责一定尺度范围的样本,scale-aware
测试阶段,可以只保留一个branch来近似完整的TridentNet的结果,寻找这样的single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1的map,但是和baseline相比不会引入任何额外的计算和参数。

三个并行分支均进行predict,只是三个dilated rate不同
Conv4分成3个branch后不融合直接各自接scale specific的rpn head和fast rcnn head?那你们怎么给conv3单独接一个trident block
自从加了trident block的地方开始,这个网络就分成3个branch,加trident block的地方dilation rate不同,后面不加的stage share一样的weight,结构和dilation rate。如果从第一层加就是三个并行的网络。
并行分支预测,但是感受野不一样,那么我不并行而是多尺度分支预测,不同分支的感受野肯定不一样,效果如果?
后者不就是常规设计了,我利用的msdn不也是融合了多尺度信息嘛
多尺度的关键在于控制感受野:
1.通过普通卷积downsample,2.通过dilation。从这个意义上是类似的,不过dilation的好处是可以基于同一个feature map来base,这里的创意在于共享参数,除了可以降低参数量以外,更大的意义在于捕获scale invarient的表征,不过这种invarient是通过人工显示设计的。
Deformable cnn自适应
这个最后的single branch approach是指inference的时候还是只用了一个dilation rate,不可能精度变高的,有一点低。
这里的提升是不是来自训练时的multi branch提供了data augmentation的作用?
(结构有点自相似的问道,不同尺度的特征还是可以在网络中的不同层次上体现出来)
权重共享,三个multi-branch的参数只和一个branch的时候一致?
后面的就是三条支路,三个loss加在一起算更快。
Multi branch
Weight share + scale aware