文章目录
1. Motivation
- intuition: 认为建模物体之间的关系会帮助目标检测。
Although it is well believed for years that modeling relations between objects would help object recognition, there has not been evidence that the idea is working in the deep learning era.
- 但是现在的方法还是在依赖于对每个物体单独识别.
All state-of-the-art object detection systems still rely on recognizing object instances individually, with- out exploiting their relations during learning.
- 本文的方法收到NLP中attention模块的启发。
Our approach is motivated by the success of attention modules in natural language processing field.
2. Contribution
作者认为添加的realtion模块第一次实现了端到端的目标检测器。
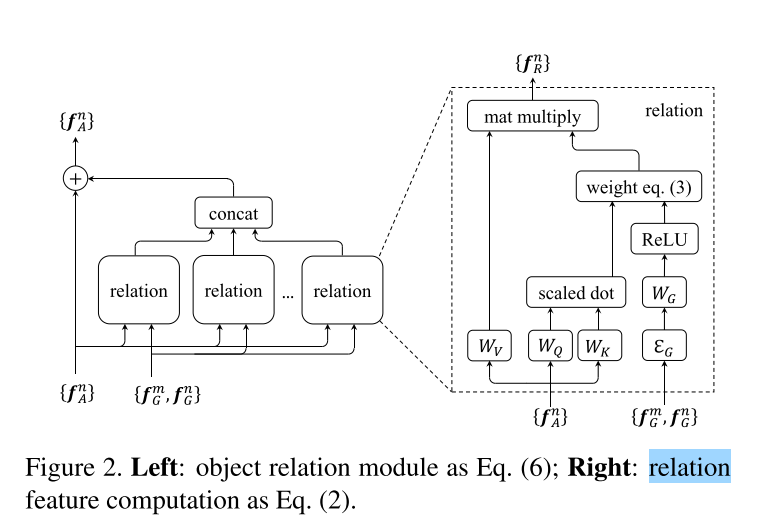
本文提出了一个object relation module(物体关系模块)来建模,在外表特征和几何特征中,通过交互,同时处理集合中的objects,所提出的模块将原始的attention权重延伸至2个成分,分别是original weight和geometric weight。几何权重建模了物体之间的空间关系,并且只考虑了相对的几何关系(relative geometric),这么做使得模型具有平移不变性(对于目标检测是一个理想的属性)。
这里有个问题,为什么对于object recognition来说,平移不变性是一个好属性?
translation invariant)指的是CNN对于同一张图及其平移后的版本,都能输出同样的结果。
于图像分类(image classification)问题来说肯定是最理想的,因为对于一个物体的平移并不应该改变它的类别。而对于其它问题,比如物体检测(detection)、物体分割(segmentation)来说,这个性质则不应该有,原因是当输入发生平移时,输出也应该相应地进行平移。这种性质又称为平移等价性(translation equivalence)。
新的模块称为object relation module,是可微分的并且in-place(输入输出没有维度的变化)。
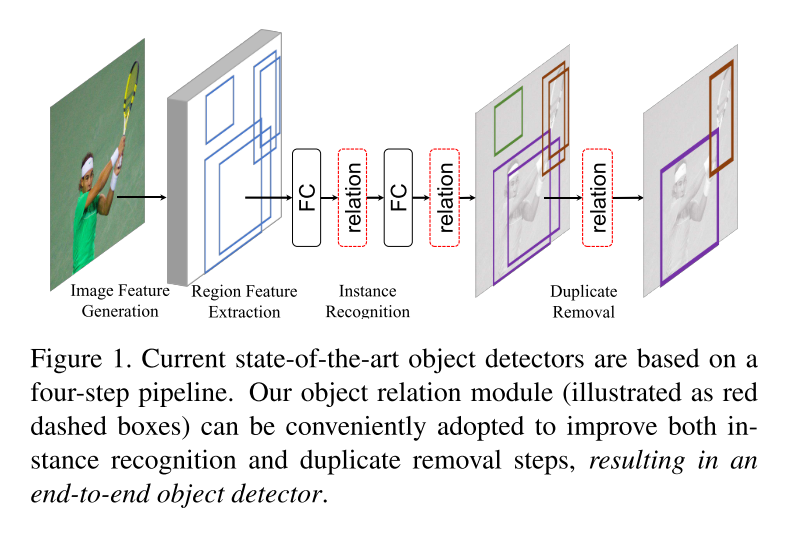
relation module作为一个basic building block,可以加入SOTA 目标检测的网络结构中,如图1所示,在Instance Recognition和Duplicate Removal 模块中加入了raltion模块,同时改善实例的识别以及去除重复的步骤,具体作用如下:
-
对于instance recognition,relation module可以联合所有合理的objects并且改善识别检测的精度。
-
对于duplicate removal, 传统的NMS会被取代,被一个轻量级的关系网络来改善,实现end-to-end。
3. Object Relation Moudle
对于Scaled Dot-Product Attention,公式如下:
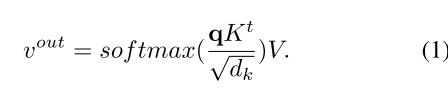
然后开始描述object relation的计算公式,首先给定一个object,由它自己的几何特征 f G f_G fG以及外表特征 f A f_A fA组成,其中 f G f_G fG是一个4维的bbox, f A f_A fA取决于对应的任务。
给定一个N个物体的集合 ( f A n , f G n ) n = 1 N {(f_A^n,f_G^n)}_{n=1}^N (fAn,fGn)n=1N,关于第n个object的与全体物体集合的关系特征relation feature f R ( n ) f_R(n) fR(n),表示为:
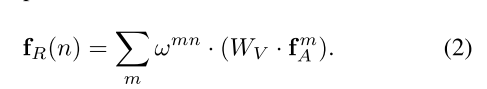
公式2表示输出 f R ( n ) f_R(n) fR(n)是来自于除object n以外的其他物体的appearance 特征的一个加权集合, W v W_v Wv与公式1中的V相关,relation weight w m n w^{mn} wmn表示了来自于其他物体的影响,关系权重表示为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VJjjwHVu-1611391066247)(https://raw.githubusercontent.com/Wei-i/My_Image_Hosting/main/img/image-20210119215842192.png)]
- Appearance weight w A m n w_A^{mn} wAmn通过点乘来计算,与公式(1)相似,表示为:
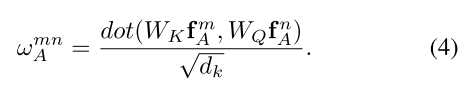
这里的 W k W_k Wk和 W Q W_Q WQ和公式(1)中的K,Q具有相似的作用。他们将原始的特征 f A m f_A^m fAm和 f A n f_A^n fAn投影到 subspaces,来测量他们有多匹配,投影后得到的特征维度是 d k d_k dk。
- Geometry weight几何权重被表示为:
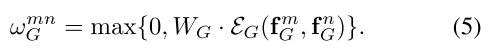
公式5包含2步,首先,2个物体的几何特征会被embed为高维的表示方法,定义为 ε G \varepsilon _G εG,为了使它具有平移不变性和尺度不变,一个4维的相对集合特征定义为: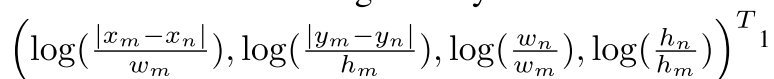 ,通过attention文章中的position encoding方法,计算cos和sin函数的不同波长wavelengths,将这个4维的特征embed为高维的表示,embedding后的 特征维度为 d g d_g dg。
,通过attention文章中的position encoding方法,计算cos和sin函数的不同波长wavelengths,将这个4维的特征embed为高维的表示,embedding后的 特征维度为 d g d_g dg。
第二步,将得到的embedded feature乘上 W G W_G WG,并用ReLu函数实现非线性化。
最后得到relation module,还做了一个残差的结构,我理解object n的 f A n f_A^n fAn等于原 f A n f_A^n fAn加上由逻辑权重和其他m个obejcts对它的逻辑特征的concat和,公式如下:
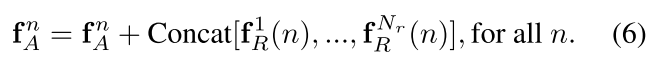
Concat(.)用于合并多种关系特征。公式2中的每一个关系函数可以给$(W_k,W_Q,W_G,W_V) 4 个 矩 阵 所 表 示 , 总 共 有 4 4个矩阵所表示,总共有4 4个矩阵所表示,总共有4N_r$。整个流程如图2所示,参数的数量为:
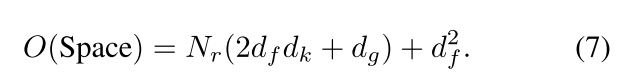
算法如下图所示,时间复杂度为:
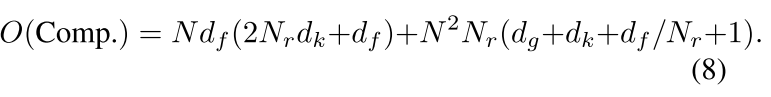

4. Relation Networks For Object Detection
4.1 Realtion for Instance Recognition
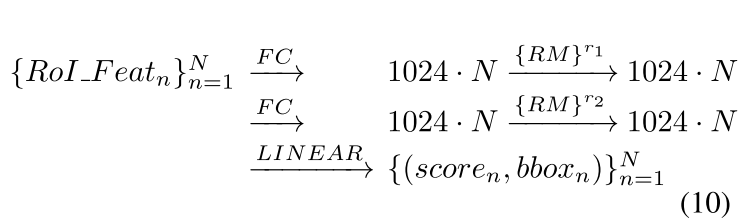
给定第n个proposal,2个1024维的FC层被使用,最后通过一个线性层,得到目标的分类以及bbox的回归。过程可以被简要表示为:

使用改进版本的2fc+RM head可以被简要表示为如下,其中r1,r2表示一个关系模块重复了多少次。如图3左半部分所示,为enhanced 2fc head。
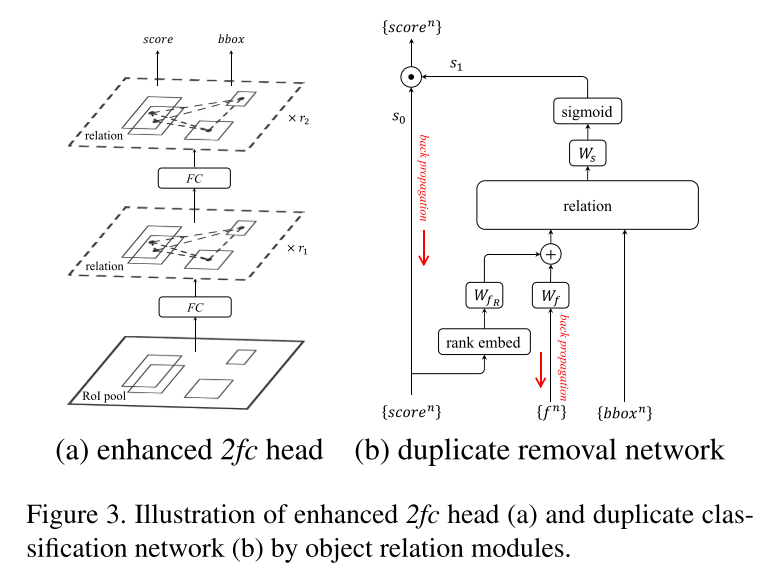
4.2 Relation for Duplicate Removal
NMS作为贪心并且需要手动设置阈值参数,使得NMS变成了一个次优化的问题,作者提出的关系模块可以学习去重。duplicate removal可以看做是一个二分类的问题,对于每一个GT,只有一个detected object能与之匹配,将其归为correct,而其他的预测框都认为是duplicate的。
这个分类通过图3(b)duplicate removal network来实现。首先,duplicate removal网络的输入为:对于每一个gt的所有预测框的集合(也就是图上的 s c o r e n , f n , b b o x n score^n,f^n,bbox^n scoren,fn,bboxn,通过公式10分别对应着前面的分类输出,每一个预测框的1024维度特征,以及bbox的回归输出。)
s1作为relation module的输出,s0作为分类分支输出的得分值。将s0×s1得到最后的classification score。因此一个好的检测需要这2个得分都要大。 s 1 ∈ [ 0 , 1 ] s_1 \in [0,1] s1∈[0,1],1代表正确,而0代表错误。
这个网络有三个步骤,首先第一步将1024-d 特征与分类得分进行融合,去产生appearance feature;第二步,relation模块将所有物体的appearance feature进行transform;最后,每一个object的transformed features通过线性分类层以及sigmoid来输出最后的概率值(0,1)。
-
Rank feature
作者发现将score转换为一个rank,即对于一个gt,将N个pred objects进行降序排列,会更加的有效,而不是直接使用他们的值,然后使用position encoding,将rank feature和1024-d appearance feature继续编码为高维度的特征(128-d)。
-
Multiple thresholds
收到COCO eval中map(0.5-0.95)的启发,稳重使用多种阈值, η ∈ { 0.5 , 0.6 , 0.7 , 0.8 , 0.9 } \eta \in\{0.5, 0.6,0.7,0.8,0.9\} η∈{ 0.5,0.6,0.7,0.8,0.9}。对于不同的IOU阈值和正确检测,分类器 W s W_s Ws变为输出多种的概率。从而实现了多种二分类loss。这种训练方式可以很好的平衡不同的情况。
-
training
对于final score,采用BCEloss。
虽然大部分的候选框都是重复的,正确的比例小于0.01,但是作者发现只使用普通的交叉熵损失也可以work,这归结于final scores是s0和s1的乘法。因为大部分的候选框都有很小的s0,因此s0s1的值也很小。损失 L = − l o g ( 1 − s 0 s 1 ) L=-log(1-s_0s_1) L=−log(1−s0s1),反向传播的梯度 ∂ 2 L ∂ s 1 = s 0 1 − s 0 s 1 \frac{\partial^{2}L}{\partial s_1}=\frac{s_0}{1-s_0s_1} ∂s1∂2L=1−s0s1s0都比较小。直观上来说,训练时要focus一些s0较高的重复候选框,这和focal loss的思想有点相似。
-
inference
L T o t a l − l o s s = L R P N + L i n s t a n c e − r e c o g n i t i o n + L d u p l i c a t e − c l a s s i f i c a t i o n l o s s L_{Total-loss} = L_{RPN} + L_{instance-recognition} + L_{duplicate-classification loss} LTotal−loss=LRPN+Linstance−recognition+Lduplicate−classificationloss,可以实现e2e,并且反向传播的梯度可以通过1024d 特征以及得分,同样可以further反传到head以及backbone网络中。
4.3 End-to-End Object Detection
The end-to-end training is clearly feasible, but does it work?
对于端到端的目标检测,作者抛出了2个问题,来证明加入relation module的e2e网络是可行的。
First, the goals of instance recognition step and duplicate removal step seem contradictory.
首先,看似instance recognition和duplicate removal 2个步骤是矛盾的,instance recognition需要所有的候选框去匹配gt,并且拥有高精度,而后者只希望留下一个correct的候选框。但作者认为2个模块这是互补的,作者在实验中标明,相比于单独训练,结合2个网络可以更快的收敛。并且通过 s 0 s 1 s_0s_1 s0s1这2个module的目标是reconciled的。前者只需要对好的候选框产生高的得分值s0,不用考虑重复的问题,而后者模块只需要对duplicates产生低的得分值s1。
Second, the binary classification ground truth label in the duplicate removal step depends on the output from the instance recognition step, and changes during the course of end-to-end training.
在duplicate removal step中,二分类的gt label取决于instance recognition 模块的输出,并且会随着训练而改变。但在实验中并没有观察到这种不稳定造成的影响,作者猜测是因为duplicate removal network易于训练,不稳定的标签可以用作正则化的手段。
5. Experiments
5.1 Relation for Instance Recognition
- Relation module improves instance recognition

- Does the improvement come from more parameters or depths?
5.2. Relation for Duplicate Removal


- compared with NMS