Ralation Networks for Object Detection算法详解
算法背景
论文标题:Ralation Networks for Object Detection
下载地址:https://arxiv.org/abs/1711.11575
论文日期:2018.1.14
摘要
物体之间的模型关系对于目标检测非常重要,但是目前的目标检测算法仍然是独立地识别物体,没有学习目标物体之间关系。本文提出了一个目标检测模型,同时处理一系列物体通过联系他们表面特征与几何形状,因此,允许建模他们的关系,不需要额外的监督,并且很容易嵌入现有的网络中。它被证明在改进现代对象检测流水线中的对象识别和重复删除步骤方面是有效的。它验证了基于CNN的检测中建模对象关系的有效性。
算法简介
在深度学习算法开始流行之前,许多算法都认为文本信息以及目标物体之间的联系对于目标识别非常重要,但是在现在先进的目标检测算法中,大家都是独立地识别每一个物体,不考虑联系。
不考虑联系的原因
目标物体之间的联系很难建模,一个物体可以在图片中的任意位置,任意尺寸,任意类别,任意数量,但是CNN方法大多数只有一个简单的常规结构,目前尚不清楚如何利用现有方法解决非常规行为的问题。
应用启发
本文的方法是由自然语言处理领域的attention modules的成功所启发。一个attention module能够通过从一堆元素(原始语句中的所有词)中收集信息(特征)来影响一个独立元素(例如机器学习翻译中一个句子里面的一个词),收集权重是自主学习的,通过驱动目标任务,一个attention module能在元素之间建立依赖,而不用在定位和特征分布上进行多余的假设,attention module被成功地应用到视觉问题。
实现方法
本文提出了一个应用attention module的目标检测算法,建立在一个基础的attention module上,有一个明显的区别就是初始元素是目标而不是单词。
物体在尺寸/比例方面有一个2D空间内的布局与变化。他们的定位或几何特征是在一个常规的场景,比单词在1维空间的定位更复杂并且更重要。
提出的模型拓展了原来的attention module权重为两个元素:原始权重,一个新几何权重。后面的元素建模了目标与仅考虑相关几何之间的空间关系,让模型具有平移不变性,对于目标识别的一个很好的属性,新的几何权重在实验中被证实很重要。
这个模型被称为目标关系模型, 分享了attention module的相同优点,会利用输入的变量数量,平行运行(与顺序关系模型相反),是完全不同的并且是对应位置的(在输入与输出之间维度不变),因此,它作用为一个基础构造块因此可以在任意结构中灵活使用。
object relation module和网络结构的耦合度非常低,同时输出的维度和输入的维度相同,因此可以非常方便地插入到其他网络结构中,而且可以叠加插入。
被应用于改进实例识别步骤并且学习重复移除步骤。
在实例识别中,关系模块可以对所有对象进行联合推理,并提高识别准确性(第4.2节)。 对于重复删除,传统的NMS方法由轻量级关系网络(第4.3节)替换和改进,从而产生了我们所知的第一个端到端对象检测器(第4.4节)。
一组对象被同时处理,推理和相互影响,而不是单独识别。
- 以attention的形式附加到原来的特征上最后进行回归和分类,
- 同时将这种attention机制引入nms操作中。
算法细节
算法结构
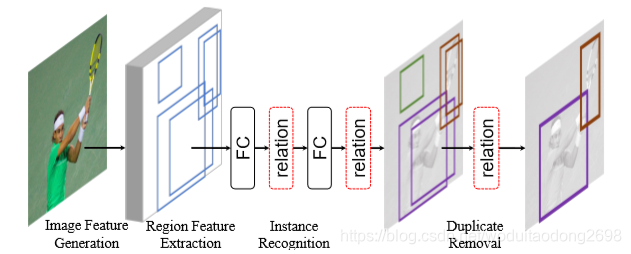
首先在图片中生成特征,然后进行区域特征提取,使用object relation module在instance recognition与duplicate removel两部分,使神经网络成为一个端到端的目标检测器。
训练步骤:
1、特征提取主网络;
2、得到ROI及特征(RPN网络就包含在其中);
3、基于ROI做边框回归和object分类;
4、NMS处理,去除重复框。
算法伪代码

N:目标物体的数量;
N_r:目标物体之间的关系数量;
f_A:外观特征;
d_f:外观特征的维度;
f_G:几何特征;
d_g:几何特征的维度;
d_k:关键特征维度;
W^r:学习权重;
目标关系模型
基于基础attention module,又命名为缩放点运算关注,输入是由查询与关键特征维度组成,查询在所有关键特征之间进行进行点运算从而获得他们的相似性。最后一个softmax函数用来获得权重。
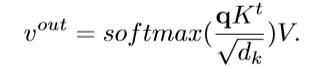
目标物体关系计算,由几何特征(定位)与外观特征(分类)两部分组成。几何特征是一个4维的边界框,外观特征由任务确定。
可以用公式2来刻画第n个object和所有object之间的关系特征(relation feature)。其中fAm表示第m个object的图像特征。Wv是一个线性变换操作,在代码中用1*1的卷积层实现。wmn是用来描述不同object之间的关系权重(relation weight),该变量通过后面的一系列公式可以得到。计算得到的关系特征fR将和原有的图像特征fA融合并传递给下一层网络,这就完成了attention过程。那么公式2和公式1有什么联系呢?简单讲,公式2中的WV对应公式1中的V,公式2中的wmn对应公式1中的softmax()。
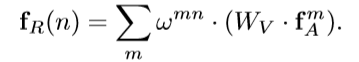
其中,
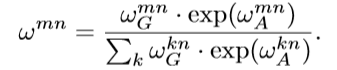
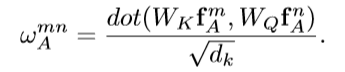
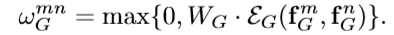
首先将两个物体的几何特征嵌入到高维特征表示,4维的相关几何特征:
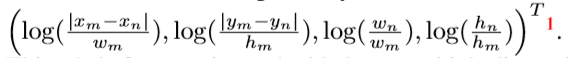
然后使用W_G转换嵌入特征到一个缩放的权重,并且修剪为0,使用ReLU非线性函数。
零修剪操作仅限制于确定几何关系的物体之间。
在得到一个关系特征fR后,这篇文章最后的做法是融合多个(Nr个,默认是16)关系特征后再和图像特征fA做融合,如公式6所示。这里有个细节是关于关系特征的融合方式,这里采用的concat,主要原因在于计算量少,因为每个fR的通道维度是fA的1/Nr倍,concat后的维度和fA相同。假如用element-wise add的方式进行融合,那么每个fR的维度和fA都一样,这样的加法计算量太大。
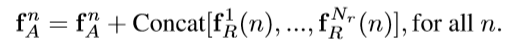
目标关系模型计算细节
左图是整体上的attention模块和图像特征fA的融合;右图是attention模块的详细构建过程。
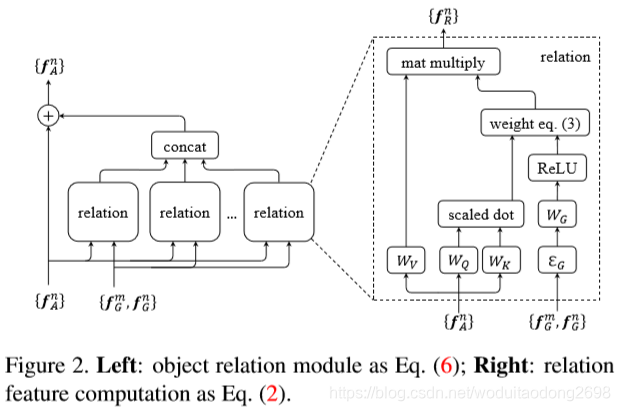
神经网络结构细节
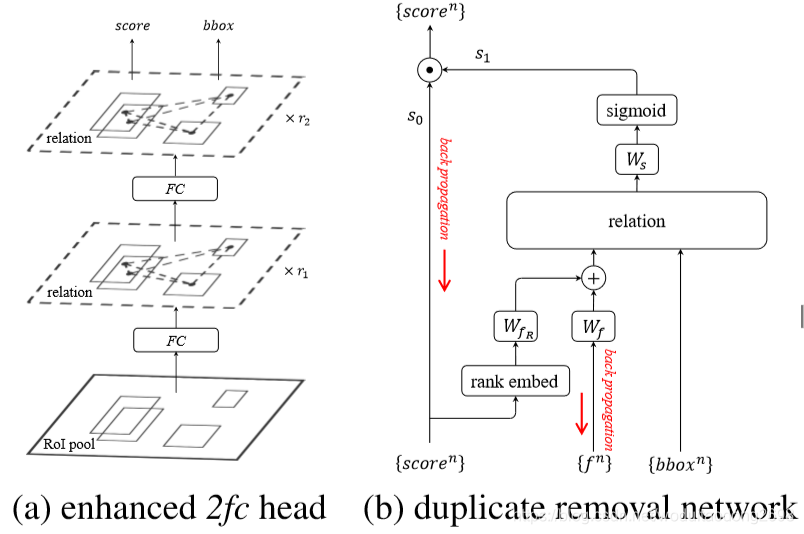
左边的图片是在RoI pooling之后加上了两个全连接层,在全连接层之后会基于提取到的特征和roi的坐标构建attention,最后在对得到的框进行定位回归与分类。
右图是插入NMS过程,重复删除是一个二分类问题,图像特征通过预测框得分的高低顺序和预测框特征的融合得到,然后将该融合特征与预测框坐标作为relation模块的输入得到attention结果,最后将NMS当作是一个二分类过程,并基于relation模块输出特征计算分类概率。
1、先获取输入score的排序信息(index),然后对index做embedding,并将embedding后的index和图像特征(f)通过一些全连接层(维度从1024降为128)后进行融合,融合后的特征作为relation module的输入之一。
2、预测框的坐标作为relation module的另一个输入,经过relation module后得到关系特征。
3、关系特征经过一个线性变换(Figure3(b)中的Ws)后作为sigmoid的输入得到分类结果,这样就完成了预测框的二分类,且基于的特征引入了attention。