论文名称:《Feature Pyramid Networks for Object Detection》
论文链接:https://arxiv.org/abs/1612.03144
参考代码(非官方):https://github.com/jwyang/fpn.pytorch(Pytorch实现)
综述
多尺度目标检测是计算机视觉领域的一个基础且具挑战性的课题,尤其是在目标检测方面。下图是目前常用的四种多尺度处理方法。
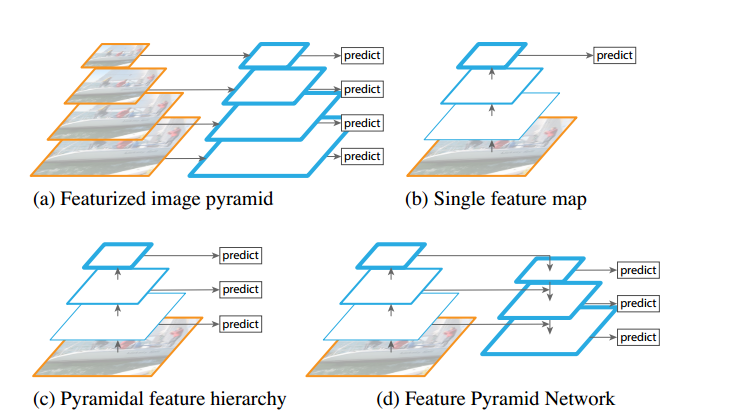
-
特征金字塔
特征金字塔是在图像金字塔基础上构建构建形成的,这种方法早期使用在人工提取的特征上。随着深度学习的流行,深度卷积特征成为主流。特征金字塔结构的优势是可以产生多尺度的特征,其中每一层都是语义信息加强的,包括高分辨率的低层。但这样的方法需要很高的时间及计算量消耗,难以在实际中应用。 -
特征最上层进行预测
由于CNN在计算的时候本身就存在多级特征图,不同层的特征图尺度也不同,天然形成了金字塔结构,其中最上层的特征语义化程度最高,可以使用进行预测,FasterRCNN便是这个思路。但由于前后层之间不同深度影响,语义信息差距太大,高分辨率的低层特征很难有代表性的检测能力。 -
特征分层预测
这种方法借鉴了特征金字塔的思路,直接强行让每层分别预测对应的尺度分辨率的检测结果,SSD就采用了类似的思想。而对于CNN而言,不同深度对应着不同层次的语义特征。浅层网络分辨率高,学的更多是细节特征,深层网络分辨率低,学的更多是语义特征。这种方法对于高分辨率的底层特征没有很好地再利用,这就对小目标的检测造成了困难。 -
特征金字塔网络
FPN的做法是:把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行一种特殊的连接,使得所有尺度下的特征都有丰富的语义信息,再进行分层预测。这种结构是在CNN网络中完成的,和前文提到的基于图片的金字塔结构不同,而且完全可以替代它。
网络具体结构
首先将任意一张图片作为输入,以全卷积的方式在多个层级输出成比例大小的特征图。FPN的网络架构图如下图所示,分为自下而上的路径、自上而下的路径及横向连接。这种结构是独立于后端的CNN结构,并可以在每一层中独立完成预测。

自下而上的路径
自下而上的路径实际上就是CNN的前馈计算。特征图经过卷积核计算,尺寸通常是越变越小的,也有一些特征层的输出尺寸和原来大小一样,作者把它们归为相同的网络阶段(network stage),使用每个阶段最后一层的输出作为参考集,经过后续处理融合后建立特征金字塔。
具体来说,对于ResNet,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,对应融合后的特征表示为{P2, P3, P4, P5}。
自上而下的路径和横向连接
自上而下的路径将更抽象、语义信息更强的高层特征图进行了上采样,然后与前一层特征进行横向连接,使其得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做主要是为了利用底层的定位细节信息。
上图显示了这种连接的具体细节。首先把高层特征做2倍上采样(使用最邻近上采样法),随后将与其对应的前一层的特征经过1*1的卷积核处理,再将通道数相同的两者通过元素间的加法(elementwise sum)结合,并重复迭代该过程,直至生成最精细的特征图。最后,用3*3的卷积核去处理融合完成的特征图(为了消除上采样的混叠效应),生成最后需要的特征图。{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相同的。

在特征金字塔网络中,所有层级共享分类层(回归层),和图像特征金字塔中所做的一样。因此需要设定所有特征图中的维度(通道数,表示为d)为定值。文章中设置d=256,因此所有额外的卷积层(比如P2)具有256通道输出。
FasterRCNN中应用
RPN的改进
RPN是Faster R-CNN中用于区域选择的子网络,它的实现是在一个13×13×256的特征图上应用9种不同尺度的anchor进行分类与回归。作者将FPN网络应用在RPN上,采用多尺度的特征图,并给每种尺度的特征图设定好对应的anchor尺寸。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2,P3,P4,P5,P6}分别对应的anchor尺度为分别对应的anchor尺度为{32^2,64^2,128^2,256^2,512^2}$。改进的RPN网络中仍然使用三种比例{1:2, 1:1, 2:1},共有15种尺寸的anchors。此外,每个层级的head都是共享参数的。
检测网络的改进
在fast RCNN中,ROI pooling操作是在同一个大小的特征图上进行的。考虑到FPN生成多尺度特征层的特性,在改进后的检测网络中,不同尺度的ROI pooling层选用了不同尺度的特征层作为输入。至于对应关系,则通过下面这个公式判别。
此外,由于把conv5也作为了金字塔结构的一部分,因此作者又增加两个1024维的轻量级全连接层,再接上分类器和边框回归。

其他
-
关于1*1卷积的作用,引用一位博主的回答3
1x1的卷积我认为有三个作用:使bottom-up对应层降维至256;缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定;组合特征。
-
CVPR现场对作者的提问
不同深度的尺度图为什么可以经过上采样后直接相加?
作者解释说这个原因在于我们做了端到端的训练,因为不同层的参数不是固定的,不同层同时给监督做 端到端训练,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid) 对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)
对于小物体,一方面它提高了小目标的分辨率信息;另一方面,如图中的挎包一样,从上到下传递过来的更全局的情景信息可以更准确判断挎包的存在及位置。- 如果不考虑时间情况下,image pyramid 是否可能会比 feature pyramid 的性能更高?
作者觉得经过精细调整训练是可能的,但是 image pyramid 主要的问题在于时间和空间占用太大,而 feature pyramid 可以在几乎不增加额外计算量情况下解决多尺度检测问题。
- 贴一张网络结构图,更直观理解网络结构
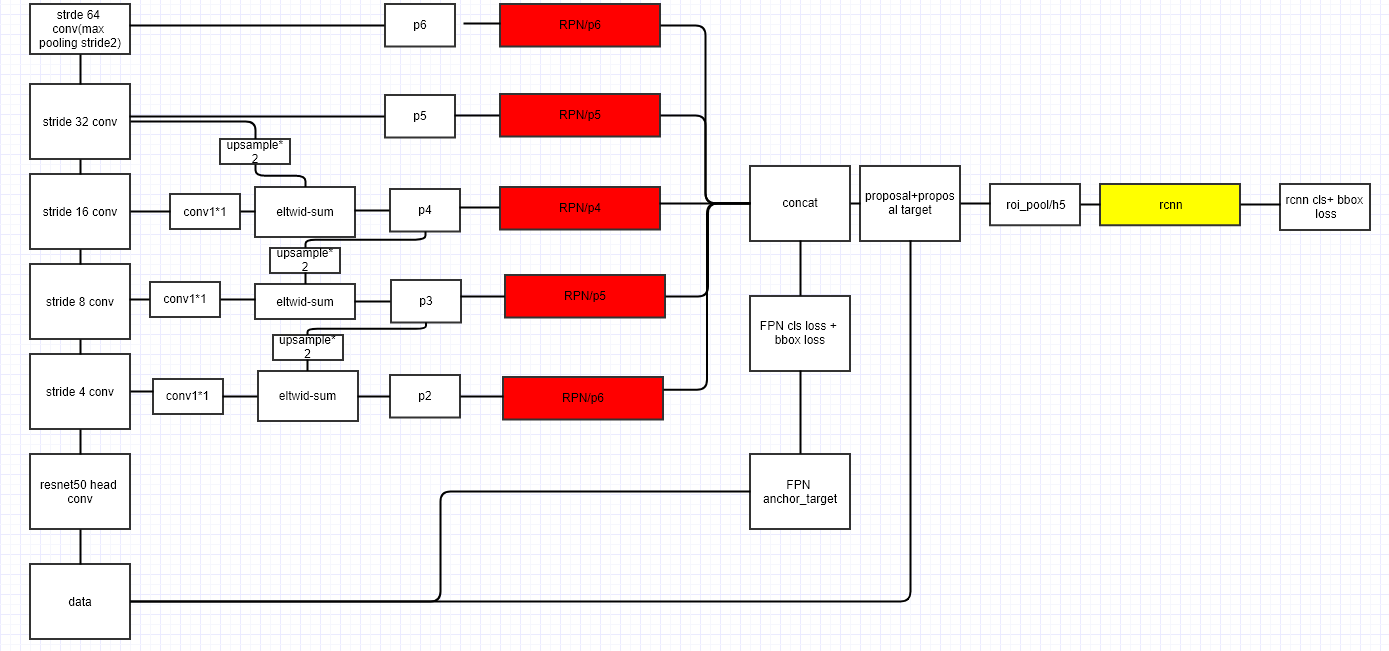
参考
1 https://blog.csdn.net/jesse_mx/article/details/54588085
2 https://zhuanlan.zhihu.com/p/36461718
3 https://zhuanlan.zhihu.com/p/35854548
4 https://zhuanlan.zhihu.com/p/26743074
5 https://github.com/unsky/FPN
