论文背景
该论文发布于2013年,此时 在图像分类任务上表现很好,但未曾在目标检测上有建树。在这论文之前的目标检测多用DPM(Deformable Part-base Model,基于部件的可变形模型),DPM模型是基于精心设计的表示以及基于流体的对象分解的图模型,利用判别图模型去构建检测的对象。该文章提出了一种基于多尺度推断的网络实现目标检测,但后面一些解决某些问题的方案,在后续发展的网络中已经不再使用,因此该笔记就不再详细记录。
简介
之前的模型都是基于分类模型之后,再进行定位操作,在本文之后,就将目标检测作为一个回归问题,输出目标为一个mask(0-1编码,非0就1)。本文中大概就是mask为1的部分就是有对象的部分。该论文的目的就是在对象分类的同时尽量定位对象。因此,本文的目的就变为了 在一张图片中检测潜在的大量不同大小的对象实例。
深层网络算法可以学习匹配手动精心设计的对象表示,因此使用DNN可以不用手动设计特征。
基于DNN的回归,网络输出的是一个二进制掩码,其输出向量大小为输出掩码网格的大小,为
,每个输出节点对应一个目标的网格,如图1所示。其次,利用全图想以及一些从该图检测的图像,构造一个基于多尺度方法的模型来提高定位的准确率,如图2所示。
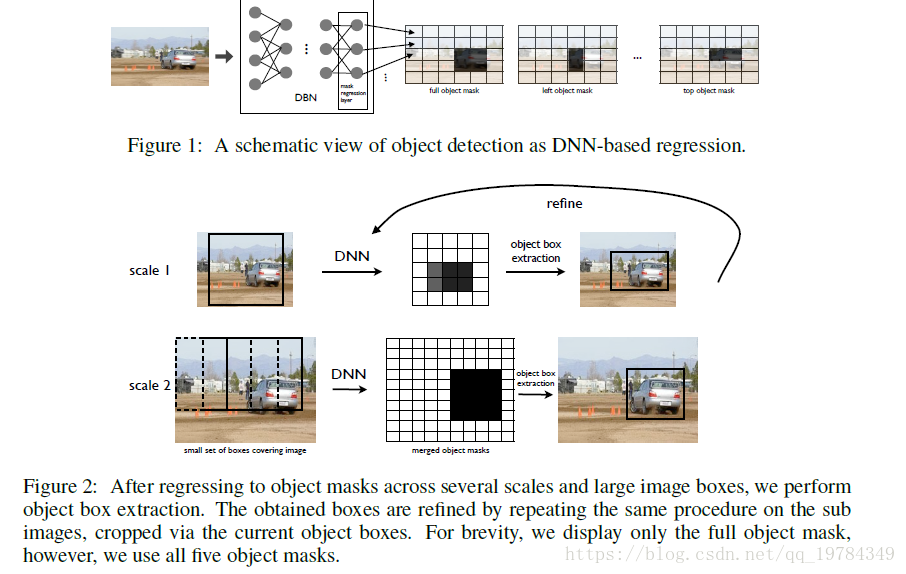
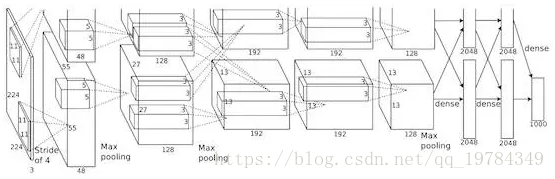
该论文的网络架构基于2012年发布的AlexNet网络,只不过将最后一层Softmax层变成了回归层。
该论文发布时的背景
当时最先进的图像检测技术是基于可变形部件的模型,这种方法之后再结合训练模型,称为图结构。这种模型可以看成两部分:第一部分是划分为部件,第二部分是训练模型(star model)。相比较DNN这种训练通用特征的模型,该方法需要专业知识。
当时已经应用DNN于医疗图像的分割技术上,但此时的DNN是用于每个像素位置的分类上。该论文提出的应用是用于局部回归。
DNN回归的检测
直觉上来说,大多数的对象对于图像大小来说都很小, 所以在生成0-1mask的时候,网络输出就容易陷入“平凡解”,即将所有输出单元都赋值为1。因此,在输出对应Ground True非零解的单元,我们基于更高的权重,以保留该结果,进而间接“惩罚”零解输出。
通过DNN生成掩码的精确对象定位
使用DNN定位存在的三个问题:
- 单个对象掩码不能有效地对彼此接近的歧义对象进行检测;
- 模型输出的掩码受到限制,所生成的掩码相对于原始图片较小,如输出24*24,原始图像为400*400,则一个掩码像素格对应16个原始图像像素格,这导致不能精确进行定位;
- 相对于图像中的检测对象,图片显得太大,因而检测对象对网络权重的影响可能不够大,因而很难去识别。
第一个问题通过产生多个mask解决。文中说的是5个(全图,包含左上角的子图,包含右上角的子图,包含左下角的子图,包含右下角的子图)。通过这五个重叠的部分,我们可以减少检测的不确定性和一些掩码的错误。【其大概意思就是,在部分图中,重叠的部分(假设是两个对象重叠)可能会有一个对象不完整,因而网络只检测了其中一个,从而解决重叠对象检测的问题】
第二个问题可通过两种方式解决:(1) 将DNN定位器应用于数个不同尺寸的较大子图上;(2) 首先推断一些边框应用于DNN定位器上,以改进检测
第三个问题,没弄清楚。。。
DNN训练
该论文应用的训练集为Pascal VOC 2007。对其中每张图片生成(裁剪)数千个样本,其中 个负样本, 正样本。如果一个样本不和任何对象的边框相交,则为负样本;如果一个裁剪得到的样本有某个(些)图像至少 的区域,则为正样本。裁剪的样本大小需要在符合的范围之内,因为DNN的输入是需要resize成固定的300*300的。【后面使用卷机运算代替了全连接层的形式,应该就不用这样resize了】
训练网络用于定位比分类要难一些,所以我们可以先用网络实现分类,从而得到预训练;进而在该参数上训练,微调得到最后的参数。(卷积层也需要训练微调)