
论文标题:A novel antibacterial peptide recognition algorithm based on BERT
代码:https://github.com/BioSequenceAnalysis/Bert-Protein
一、问题提出
抗菌肽是一种小分子多肽,是生物先天免疫系统的关键组成部分。它们的作用方式多种多样,如破坏目标细菌的细胞膜、干扰DNA产生等,对细菌、病毒和真菌具有广谱抗菌活性。
目前,AMPs(Antimicrobial peptides,抗菌肽)的识别方法主要分为湿实验法和计算机辅助识别法。
湿法实验设计复杂,操作困难且耗时。它们需要大量的人力和材料成本
计算机辅助识别方法可分为基于经验分析的方法和基于机器学习的方法。基于经验分析的方法以确定类型的AMP为模板,利用已知的经验规则对肽链性质与抗菌活性之间的关系进行统计分析,然后建立模型。
建模方法主要包括主成分分析(PCA)、偏最小二乘法等。本质上,它是为了识别待测试序列是否具有训练集的某些特定特征。缺点是依赖于训练集现有的语义模式,并且很难迁移到其他类型的AMP,现有研究表明,氨基酸序列本身包含了关于其是否具有抗菌活性的关键信息。
蛋白质序列类似于自然语言,可以自然地表达为一串字母。此外,自然进化的蛋白质通常由重复使用的模块化元件组成,这些元件表现出轻微的变化,可以以分级的方式重新排列和组装。
提出了一种新的基于BERT的模型训练算法,以实现对AMP数据集的准确识别。从UniProt中获得蛋白质序列用于预训练,然后使用三种分词方法在六个不同的AMP数据集上对模型进行微调和测试。证明了预训练的作用以及平衡正样本和负样本的作用,并最终使用构建的新数据集训练了一个通用的AMP识别模型
二、Methods
1、Data
Pretraining:UniProt下载556603条蛋白质数据作为预训练样本。
fine-turning:自行构建
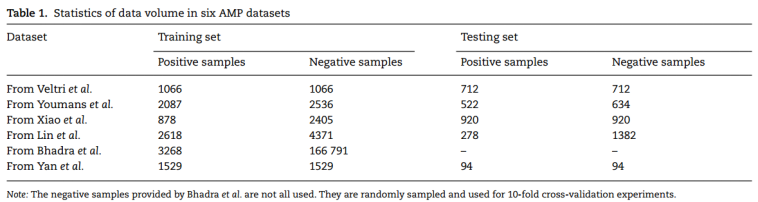
阳性样本来自APD、抗菌活性和肽结构数据库(DBAASP)、CAMPR3和LAMP,通过直接筛选功能类型、抗菌对象和肽链长度等特征获得。由于没有专门的非抗菌肽(non-AMP)数据库,研究人员通常通过在UniProt中设置一些条件(如非抗菌功能注释、细胞内蛋白质等)来过滤阴性样本。不平衡数据集对训练集的负样本进行随机下采样
2、Representation of the peptides
蛋白质都是由不同比例的氨基酸组成的。用字母表中的20个不同字母来表示20种天然氨基酸。肽链表示为x=[x1,x2,…,xn]T,其中xi是肽链中的第i个氨基酸,n是氨基酸的数目。
每个肽序列都包含标签y。当肽是AMP时,y的值为1;否则为0。
蛋白质序列不同于英文文本和中文文本。英文文本使用空格来区分序列中的每个单词,中文文本可以通过分词算法进行分割。在本文中,每个k个氨基酸作为一个组被视为一个“词”,称为k-mer,并且分别选择k=1、2、3。蛋白质序列从开始到结束是分开的。当序列的末端少于k个氨基酸时,剩余的氨基酸形成一个“单词”

3、预训练-微调

在UniProt中对未标记的蛋白质序列进行分词和掩蔽处理,并执行两个预训练任务:掩蔽语言模型(MLM)和下一句预测(NSP)
对于特定的下游任务,即AMP识别和预测,我们改变预训练模型的输出层,并使用六个不同的标记数据集对其进行微调。
4、Model training + performance evaluation
BERT库的12层Transformer,其隐藏层包含768个单元节点和12个注意力头,参数为110M,TITAN Xp上进行了1000万次训练,学习率为2e−5,batchsize为32。
敏感性(Sn)、特异性(Sp)、准确性(Acc)和马修相关系数(MCC)、AUC-ROC:
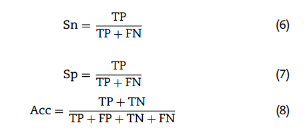
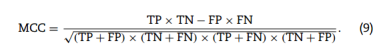
Sn和Sp分别反映了模型识别AMP和非AMP的能力,Acc体现了模型的整体预测效果。三者的取值范围为[0,1],值越大,模型预测越准确。
MCC通常被视为一种平衡指标,即使样品不平衡。值介于−1和+1,参考选择测试集中样本的真实标签与预测结果之间的相关性。值越高,相关性越大。当该值接近1时,模型的分类性能优异;当接近−1时,模型的预测结果与实际结果相反;当接近0时,模型预测结果与随机预测相似。
三、Results
1、comparsion with baseline
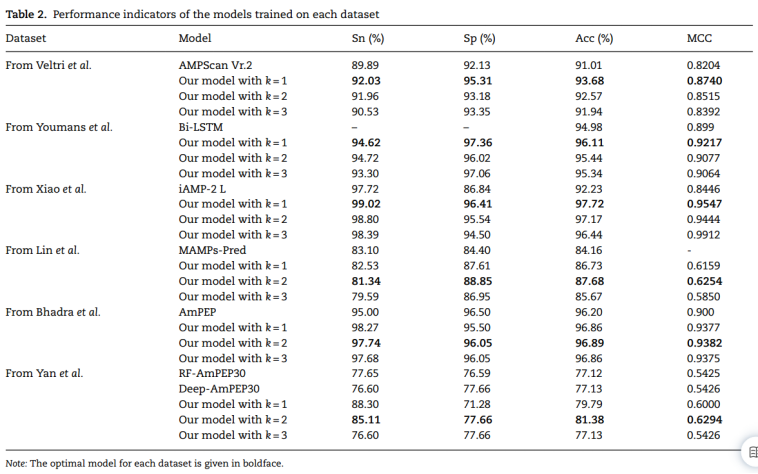
最好模型与现有模型的差异:
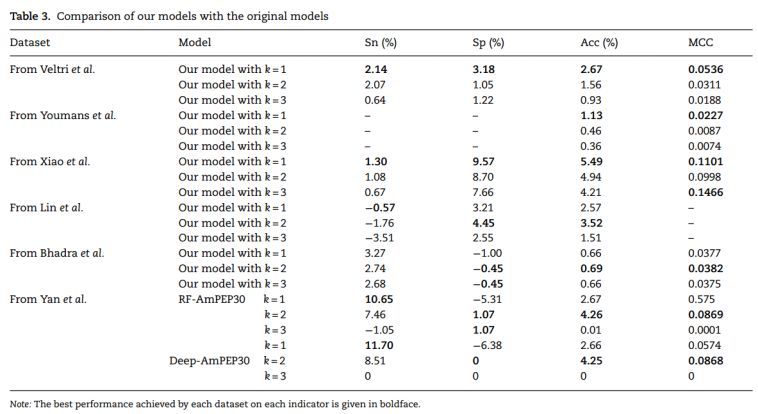
2、预训练有效性
预训练对k值较大的模型有更明显的影响:

3、Balanced dataset analysis
对每个训练集的负样本进行随机下采样,以平衡数据集。为了查看模型在不平衡训练集上的表现是否不同,选择了两个数据集:MAMPsPred模型的数据集和iAMP-2L模型的数据集:

性能:无论数据集是否平衡,该方法都显示出优异的性能。与平衡集的结果相比,在不平衡集上训练的模型的整体识别性能降低,这特别体现在Acc和MCC指标的下降上。

AmPEP模型提供的数据集中有大量的负面数据,这为尝试评估不同的正面:负面(P:N)数据比率对AMP预测的影响提供了基础。根据原始数据集(P/N比为1:51),生成了5组数据,其中P/N比为1:1、1:3、1:5、1:7和1:9。通过10倍交叉验证评估了每个分类器的预测性能。
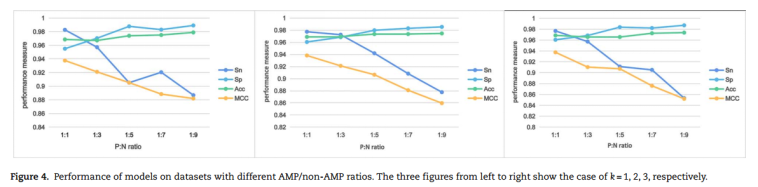
尽管随着训练集中非AMP数量的增加,Sp指数迅速增加,Acc随后被拉高,但Sn和MCC随着数据集变得更加不平衡而减少。
4、A general model
增加训练集的多样性可以在一定程度上提高模型的通用性。(i)使用AntiBP2模型的训练集来微调用UniProt预训练的模型以获得模型A(ii)使用AntiBP2模型的训练集对在上述新的AMP和非AMP数据集上训练的模型进行微调,以获得模型B。以k=1时两种方式训练的模型为例,两种模型都在一定程度上提高了测试精度:
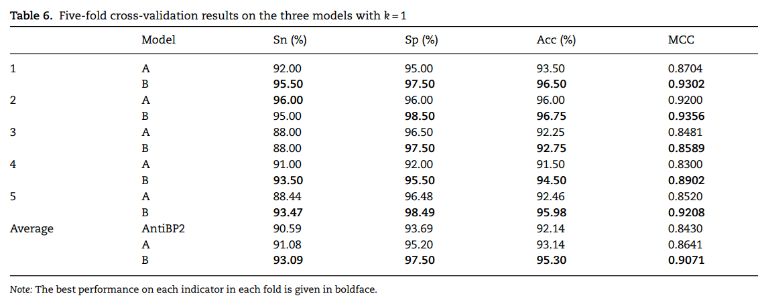
用大量AMP训练的模型具有良好的可迁移性,更适合用作新样本识别或预测任务的预训练模型,以同时捕获新数据集特有的特征和AMP序列之间的共同特征。
使用StarPepDB数据库中包含的16990个非冗余AMP序列,加上相同数量的随机选择的非冗余非AMP多肽链作为训练集来训练通用模型。对该模型进行了5倍的交叉验证,结果如表所示。每个评估指标的最佳结果用黑体字表示。

在每个测量指标中,k=1的模型是最好的。