MSGCL: inferring miRNA–disease associations based on multi-view self-supervised graph structure contrastive learning
源代码:GitHub - rxr0606/MSGCL: MSGCL


摘要:
潜在的 miRNA-疾病关联(MDA)在发现复杂的人类疾病病因学中起着重要作用。因此,MDA 预测是生物医学机器学习领域的一个热门研究课题。近年来,针对这一问题提出了几种模型,但其性能受限于过度依赖含有噪声图结构连接的相关网络信息。然而,自监督图结构学习在 MDA 任务中的应用还有待进一步研究。本研究首次将多视角自监督对比学习(MSGCL)应用于 MDA 预测。具体而言,我们生成了一个没有 miRNA 和疾病关联标签作为输入的学习者视图,并利用已知的关联网络生成锚视图,为学习者视图提供指导信号。通过设计对比损失优化图形结构,使锚点视图和学习者视图之间的一致性最大化。我们的模型类似于一个预先训练的模型,该模型不断优化高质量关联图拓扑的上游任务,从而增强关联预测的潜在表示。实验结果表明,我们提出的方法在 ROC曲线曲线下的面积(AUC)和精确/召回曲线下的面积(AUPR)分别比最先进的方法高出2.79% 和3.20% 。
关键词: miRNA-疾病关联,自我监督,对比学习,多视角
目录
2.1.多视图属性组件(Multi-view attributes component)
2.1.1.miRNA sequence similarity
2.1.2.miRNA functional similarity
2.1.3.Disease semantic similarity
2.1.4.Target-based similarity measure for diseases
2.1.5.Multi-view attributes construction
2.2.图结构建模组件(Graph structure modeling component)
2.2.1.图学习器(The graph learner MDGLP)
2.3.多视图自监督对比学习组件(Multi-view self-supervised contrastive learning component)
2.4.对比损失组件(Contrastive loss component)
2.4.1.GCN encoder and MLP projector
2.5.miRNA - 疾病预测组件(miRNA-disease prediction component)
3.5.1.Edge dropping and feature masking probabilities
3.5.3.Performance of different attributes fusion
3.5.4.Performance of different graph learners
1.引言
MiRNA 是一类内源性非编码单链 RNA 分子,长约22个核苷酸,通过转录后调控基因在真核生物中发挥其生物学功能。因此,miRNA 可以作为一个潜在的诊断标记和治疗靶点,参与复杂疾病的发病机制,如癌症[1]。例如,异常 mir-107可能导致 BACE1(分泌酶10)的异常活性,并导致阿尔茨海默病[2]。此外,许多研究表明,miRNA 与复杂的人类疾病有关,包括乳腺癌、肝癌和肺癌[3-5]。因此,迫切需要鉴定与疾病相关的 miRNA,以帮助促进疾病病理学研究。
然而,预测 miRNA 与疾病的关联(MDA)是一项具有挑战性的任务。现有的研究表明,整合不同的数据源可以获得更全面的研究视角,但它也给算法设计以生成简洁和一致的表示带来了挑战[1]。因此,MDA 预测需要新的计算方法。基于相似性度量的[6-10]和基于机器学习的[11-13]方法学习和捕获数据之间的重要关系。人们通常认为,更相似的 miRNA 更有可能与表型相似的疾病相关联。然而,基于相似度量的方法无法捕捉复杂的网络连接和非线性关系。基于机器学习的方法不能适应复杂的数据。因此,深度学习已被广泛应用于生物信息学处理非结构化数据,并提出了基于图表示学习的方法。图神经网络在生命科学和物理科学中得到了广泛的应用。GNN 分析任务已经被用于节点分类[17,18] ,墨水预测[19,20]任务已经取得了先进的性能。Han 等[21]提出了一个新的疾病-基因关联任务框架,图卷积网络矩阵分解(GCN-MF) ,将 GCN 和 MF 结合起来捕获非线性相互作用。Wu 等[22]提出了使用图形自动编码器(GAE)和随机森林来鉴定疾病相关 lncRNA 的 GAERF 模型。Tang 等[23]开发了一个多视角多通道注意图卷积网络(MMGCN)来预测潜在的 MDA 关联。然而,这些监督方法导致以下问题: (i)依赖于原始图拓扑结构。图结构一般是从较复杂的场景中提取出来的,其中不可避免地存在着不确定性、缺失性和冗余性等问题。 (ii)含有噪声的原始图结构所包含的信息通常是有限的。在其他领域,正在进行相关研究以解决上述问题,Wang 等[24]提出了一种新的无监督对比学习组件来平衡和整合多视图信息,使用药物分子实例采用 bond-aware 注意力信息传播方法进行 DDI 预测。Liu 等[25]提出了一种实用的深度图结构学习方法,该方法可以在没有标签引导的情况下学习图形特征表示,并且在节点分类和聚类任务中取得了较好的性能。他们证明了无监督的深度图学习可以学习大量的类内边,并且可以学习两个共享相似语义信息的节点之间的连接,从而提高图拓扑的质量。然而,它们都是基于同质网络的。
因此,我们提出了 MSGCL: 一种多视角自监督深度图结构对比学习来推断 MDA 预测。首先,我们构建了由 miRNA 和疾病的不同空间特征组成的多视图属性。其次,我们基于多视图属性和已知的关联构建锚视图作为优化目标来提供指导。随后,我们使用多视图属性通过 miRNA 疾病图学习器MDGLP 构建学习者视图。最后,使用 GCN编码器对邻居节点信息进行聚合,并利用对比度损失使锚和学习者视图之间的一致性最大化。MSGCL 类似于预训练策略,它不断优化和更新上游任务,最终得到一个高质量的图形结构,降低噪声,并将其发送到下游任务进行学习。我们进行了广泛的性能评估,证明了 MSGCL 可以有效地利用多视图自监督图结构对比学习来提高性能。在 HMDD3.2数据集[5]上,MSGCL 的性能优于其他几种最先进的方法。ROC曲线曲线下的面积增加了2.79% ,而精确/召回曲线下的面积则增加了3.20% 。这项研究的主要贡献如下:
(1)我们构建了两种视角,即锚视角和学习者视角。锚点视图由多视图属性和已知关联网络构成,为协同优化提供监控信号。学习者视图是通过 MDGLP 建模获得的,只使用多视图属性。
(2)据我们所知,这是首次将自监督深层图结构对比学习应用于 MDA 预测,比现有的监督图学习方法更具实用性和挑战性。特别地,我们设计了两种视图的数据增强方案,包括特征掩蔽和边drop机制。
2.方法
提出了一种多视图自监督图结构对比学习框架:MSGCL。该框架由四个组件组成。(a)将多视图属性组件作为先验信息提供给后续组件。(b)图结构建模组件利用 MDGLP 图学习器,对独立的参数图进行正则化和建模,得到一个新的拓扑结构,然后将其反馈到学习者视图中。(c)多视图自监督对比学习组件为深度图学习监督和优化提供信号,以发现隐藏的信息联系。我们定义并构造了学习者视图和锚视图,在增加了两个视图的节点和边之后,通过对比学习使两个视图的互信息最大化。在优化损失函数时,所有的远邻节点都受到信号的监督,可以获得更多的边缘信息。(d) miRNA 疾病预测组件使用在 MDGLP 更新到下游任务之后获得的最佳图拓扑用于最终关联预测。我们将在下面描述每个组件的总结。算法1和图1给出了具体的算法描述和框图。

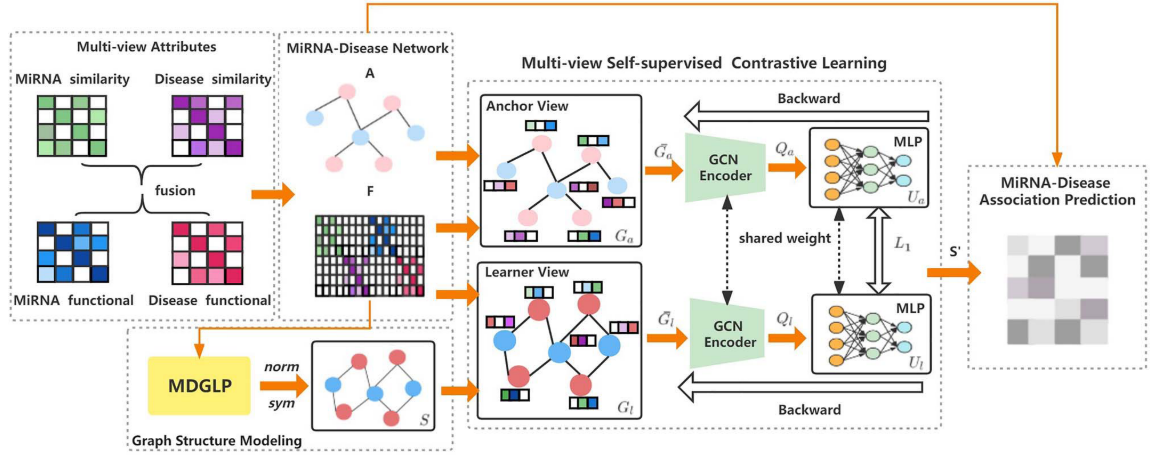
2.1.多视图属性组件(Multi-view attributes component)
我们将 miRNA 序列相似度、 miRNA 功能相似度、疾病语义相似度和疾病语义相似度计算如下:
2.1.1.miRNA sequence similarity
基于全局匹配 Needleman-Wunsch 算法[26] ,计算了 miRNA 序列相似性矩阵中的最大得分 Smax 和最小得分 Smin,得到了 mi 和 mj 之间的归一化关系 ![]() 和 miRNA 的序列相似性视图
和 miRNA 的序列相似性视图 ![]() ,其中 nm 为 miRNA 的个数,然后序列之间的相似性可以表示如下:
,其中 nm 为 miRNA 的个数,然后序列之间的相似性可以表示如下:
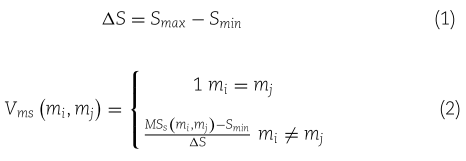
2.1.2.miRNA functional similarity
我们从 HumanNet [27]获得了包含基因-功能连接关系的基因-功能相互作用网络,并遵循以前的工作[6] ,使用 miRNA 和基因之间的关联来计算 miRNA 功能相似性。如果两个基因相等,它们是相关的,元素 ![]() 是1。我们将基因之间功能连锁的可能性称为对数似然函数(LLS) ,如果基因不相等,我们计算它们之间的 LLS。然后基因相似度图
是1。我们将基因之间功能连锁的可能性称为对数似然函数(LLS) ,如果基因不相等,我们计算它们之间的 LLS。然后基因相似度图 ![]() 表示如下:
表示如下:

其中 ![]() 包含 HumanNet 中的所有链接,
包含 HumanNet 中的所有链接,![]() 是基因 i 和 j 之间的边。然后,我们计算相似度得分:
是基因 i 和 j 之间的边。然后,我们计算相似度得分:
![]()
其中 ![]() 是一个基因,
是一个基因,![]() 是一组基因,通过相似性评分可以得到 miRNA mi 和 mj 之间的功能相似性,功能相似性视图
是一组基因,通过相似性评分可以得到 miRNA mi 和 mj 之间的功能相似性,功能相似性视图![]() 如下:
如下:
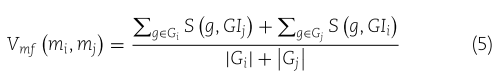
其中 ![]() 分别代表对应于
分别代表对应于 ![]() 的基因集。
的基因集。
2.1.3.Disease semantic similarity
根据 MeSH 的描述,疾病的等级关系可以转换成一个有向无环图(DAG) ,可以用来计算疾病的语义相似度,如[28,29]所述。对于疾病 z,让 ![]() 表示 z 的所有祖先(包括它自己)的集合。然后,在 DAG (z)中,疾病 z 对 zi 的语义贡献
表示 z 的所有祖先(包括它自己)的集合。然后,在 DAG (z)中,疾病 z 对 zi 的语义贡献 ![]() 可以表示如下:
可以表示如下:
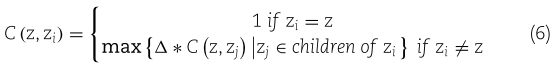
其中![]() 是语义贡献因子,我们通常设置为0.5。疾病 z 与其祖先越接近,对语义的贡献就越大。疾病之间的语义相似性表示如下:
是语义贡献因子,我们通常设置为0.5。疾病 z 与其祖先越接近,对语义的贡献就越大。疾病之间的语义相似性表示如下:

其中 ![]() 和
和 ![]() 是疾病语义值。
是疾病语义值。![]() ,其中
,其中 ![]() 表示疾病的数目。
表示疾病的数目。
2.1.4.Target-based similarity measure for diseases
计算疾病与基因之间的关联的方法与计算 miRNA 功能相似性的方法相同。同样地,可以得到疾病函数相似视图 ![]() ,其计算公式如下:
,其计算公式如下:
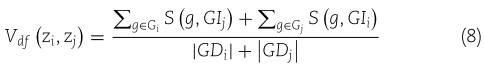
其中 ![]() 分别表示与疾病
分别表示与疾病 ![]() 和
和 ![]() 相关的基因集。
相关的基因集。
2.1.5.Multi-view attributes construction
为了使模型中的 miRNA 和疾病信息具有可比性,我们将miRNA 和疾病的基于功能相似性视图及其基于语义相似性的视图连接起来,构建了多视图属性。为了简单起见,我们考虑两种不同的模式。基于语义相似度的模块 ![]() 和基于功能相似度的模块
和基于功能相似度的模块 ![]() 定义如下:
定义如下:

最后,使用两种不同的属性组合作为锚点视图和学习者视图的输入,定义总特征 F ∈ ![]() 如下:
如下:
![]()
2.2.图结构建模组件(Graph structure modeling component)
给定一个有噪声的图结构 G = (A,F) ,A 是一个包含噪声的真实网络。我们的目标是获得优化的图拓扑 ![]() 以更好地捕获节点和边之间的潜在依赖关系。S 是在更新的 MDGLP 的每次迭代之后获得的图拓扑。最后,
以更好地捕获节点和边之间的潜在依赖关系。S 是在更新的 MDGLP 的每次迭代之后获得的图拓扑。最后,![]() 被发送到下游任务进行训练,
被发送到下游任务进行训练,![]() 是 MDGLP 学习者在对比学习优化过程中通过反向传播更新获得的最优图拓扑。
是 MDGLP 学习者在对比学习优化过程中通过反向传播更新获得的最优图拓扑。
2.2.1.图学习器(The graph learner MDGLP)
现有的许多图学习器能够对图结构进行建模,已经广泛应用于计算机视觉和自然语言处理中。根据 Fatemi 等人的工作[30-32] ,全图参量化(FGP)通过一个参数直接模拟邻接矩阵的每个元素,而不需要任何额外的输入,同时假设图中的每个边都是独立存在的。受此启发,我们将 FGP 引入到 miRNA 和疾病中,并提出了一种图学习器 MDGLP。为了进一步验证 MDGLP 对于我们的数据分布是一个合适的学习器,我们对不同的学习器进行了实验。详情见表6。我们设置 ![]() ,其中 θ 是我们要学习的参数。MDGLP 使用参数模型生成一个邻接矩阵图
,其中 θ 是我们要学习的参数。MDGLP 使用参数模型生成一个邻接矩阵图 ![]() 。因此,我们得到了
。因此,我们得到了 ![]() ,它不包含任何关于原始邻接矩阵 A 的信息。MDGLP的定义如下:
,它不包含任何关于原始邻接矩阵 A 的信息。MDGLP的定义如下:
![]()
其中 ![]() 是我们要学习的参数矩阵,它通过一个非线性激活函数 σ。在获得学习器产生的
是我们要学习的参数矩阵,它通过一个非线性激活函数 σ。在获得学习器产生的![]() 之后,我们必须将所绘制的邻接矩阵稀疏成一个非负的、对称的、归一化的邻接矩阵。因此,有必要在
之后,我们必须将所绘制的邻接矩阵稀疏成一个非负的、对称的、归一化的邻接矩阵。因此,有必要在 ![]() 上进行基于 K 最近邻的稀疏化处理。对于每个节点,我们设置一个值 K 来维护边,其余的设置为0。具体的表示如下。
上进行基于 K 最近邻的稀疏化处理。对于每个节点,我们设置一个值 K 来维护边,其余的设置为0。具体的表示如下。
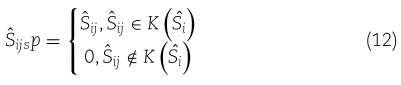
随后进行非负运算和对称归一化,具体定义如下:

其中归一化确保边缘权重在范围[0,1]内,![]() 是
是 ![]() 的度矩阵,σ 是激活函数,ELU 函数用于激活。
的度矩阵,σ 是激活函数,ELU 函数用于激活。

2.3.多视图自监督对比学习组件(Multi-view self-supervised contrastive learning component)
在学习了一个参数化的邻接矩阵后,为了给学习到的矩阵提供监督指导信号,我们通过多视图对比学习从数据本身获得了监督信号。因此,我们构造了一个用于建模图结构的学习者视图和用于从原始数据中导出引导优化信号锚点视图。为了使网络信息多样化,使对比学习能够学习更多的区分嵌入,我们对这两种视图进行了数据增强,包括 feature masking 和 edge dropping 方案。
2.3.1.学习器视图(Learner view)
基于 Fatemi 等[30,31]的想法,使用 K 最近邻(KNNs)初始化学习到的邻接矩阵,以获得一个 KNN 图,在对比学习中是非常有效的。因此,学习器视图结合了 MDGLP 和多视图属性生成的图拓扑,其定义如下:
![]()
这里,我们将 KNN 边的参数设置为1,其余的参数被初始化为0。![]() 不断地迭代使用梯度下降法,并通过反向传播更新各种参数。
不断地迭代使用梯度下降法,并通过反向传播更新各种参数。
2.3.2.锚视图(Anchor view)
锚视图主要为学习者视图提供指导信号。它的输入通常是包含噪声的原始图拓扑。与学习者视图类似,参数通过梯度下降法反向传播更新。具体定义如下:
![]()
其中 ![]() 表示原始邻接矩阵。为了方便起见,我们把 A 分割成一个四分之一的矩阵。对角线是 A,余数是0。
表示原始邻接矩阵。为了方便起见,我们把 A 分割成一个四分之一的矩阵。对角线是 A,余数是0。
2.3.3.数据增强(Data augmentation)
很容易知道,当两个视图太相似时,监督信号变得更弱,并且无法学习更多的判别嵌入[20,33,34]。然后,我们对两个视图都使用了masking and edge dropping 机制来破坏图拓扑以增强数据,使模型能够探索更丰富的底层语义信息并发现更多隐藏的连接。
对于给定的特征矩阵 F,我们随机选取少量的特征维数,并使用0来掩盖它们。同时,为了获得不同的上下文信息,我们对学习器视图和锚视图采用不同的特征掩蔽概率 ![]() 。由于两个视图的图拓扑结构已经很不相同,我们使用了相同的边降概率
。由于两个视图的图拓扑结构已经很不相同,我们使用了相同的边降概率 ![]() 。定义如下:
。定义如下:

![]() 是特征掩蔽后的特征矩阵,
是特征掩蔽后的特征矩阵,![]()
![]() 是增广特征矩阵,
是增广特征矩阵,![]() 是 F 的第1行向量的转置。
是 F 的第1行向量的转置。 ![]() 是从伯努利分布中独立提取的掩蔽向量,概率
是从伯努利分布中独立提取的掩蔽向量,概率 ![]() 。
。![]() 分别是边丢弃后学习器视图和锚视图的邻接矩阵,
分别是边丢弃后学习器视图和锚视图的邻接矩阵,![]() 是一个从概率
是一个从概率 ![]() 的伯努利分布中得出的丢弃向量。因此,数据增强的视图可表达如下:
的伯努利分布中得出的丢弃向量。因此,数据增强的视图可表达如下:
![]()
![]() 分别是数据增强后的学习器视图和锚视图。
分别是数据增强后的学习器视图和锚视图。
2.4.对比损失组件(Contrastive loss component)
对比学习的框架从 Chen 等人提出的 SimCLR 开始[34] ,其由 GCN 编码器和 MLP 组成,具体定义如下:
2.4.1.GCN encoder and MLP projector
通过两层 GCN 编码器实现 ![]() 的节点级特征表示,然后通过 MLP 投影得到投影节点的表示矩阵,具体定义如下:
的节点级特征表示,然后通过 MLP 投影得到投影节点的表示矩阵,具体定义如下:
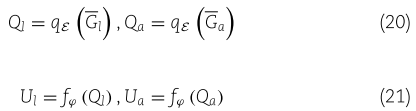
其中 ε 和 φ 分别是 GCN 编码器和 MLP 的参数,![]() ,
,![]() 。
。![]() 是 GCN 编码器和 MLP 的嵌入尺寸。
是 GCN 编码器和 MLP 的嵌入尺寸。
基于 Sohn 等人的想法[35,36] ,他们使用对称归一化的温度标度交叉熵损失 NTXent,使用对比度损失 ![]() 来最大化两个视图之间的
来最大化两个视图之间的 ![]() 。预测节点 i 的投影节点表示
。预测节点 i 的投影节点表示 ![]() 矩阵之间的一致性
矩阵之间的一致性

其中 sim 是余弦距离函数,N = nm + nd,同样地,我们得到了 ![]() 。
。
2.5.miRNA - 疾病预测组件(miRNA-disease prediction component)
将最优图结构 ![]() 迭代到具有一层的 GCN 中,得到 miRNA 和疾病的表达式
迭代到具有一层的 GCN 中,得到 miRNA 和疾病的表达式![]() 。对于
。对于![]() ,除了关联信息外,还包括关于 miRNA 和疾病存在的潜在信息。我们利用均方误差(MSE)损失,使
,除了关联信息外,还包括关于 miRNA 和疾病存在的潜在信息。我们利用均方误差(MSE)损失,使 ![]() 和真实标记矩阵 A 的误差最小。
和真实标记矩阵 A 的误差最小。
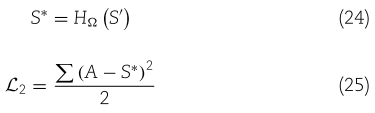
其中 ![]()
![]() 是一个可以学习的参数。
是一个可以学习的参数。
3.实验(Experiments)
我们首先使用5折交叉验证(5-CV)来选择 HMDD 3.2和 HMDD 2.0数据集上的模型参数。然后,在相同条件下测试不同模型的效果,并进行预测分析。我们同时分析了学习到的最佳邻接矩阵,并进行了实验,例如结构的多视图属性的消融和研究关键超参数的不可逆敏感性。
3.1.Experiments setting
这个实验的计算环境是一个 Ubuntu 18.04.1系统,使用 Pytorch1.4.0、 Python 3.6.9和 GEFORECE RTX 2080 TI 图形卡。此外,我们使用了 AUC 和 AUPR 两个评估指标。
3.2.Datasets
HMDD 3.2中已知的人类 MDA 已经被文献中的实验所证实,总共有35547个与1206个 miRNA 和894种疾病的关联。MiRNA 信息可以从 Mirbase 版本22[37]下载,我们从 Mirtarbase 版本8.0[38]下载了2599个 miRNA 和基因502652关系,以及来自 HumanNet V2的基因相关网络[27]。疾病的语义树和疾病-基因关系可以从 MeSH 和 DisgNet V7[39]下载。共鉴定出853个 miRNA 和591种疾病。此外,还获得了12446个经过实验验证的 MDA。同时,我们还对 HMDD 2.0进行了实验,主要包括383种疾病和495种 miRNA,提供了5430种经过实验验证的 miRNA。
3.3.Baselines
3.4.Performance comparison
3.5.Parameter analysis
3.5.1.Edge dropping and feature masking probabilities
3.5.2.Number of neighbors k
3.5.3.Performance of different attributes fusion
3.5.4.Performance of different graph learners
3.6.Case study
4.结论(Conclusion)
在这项研究中,我们首次将多视图自监督图结构对比学习方法 MSGCL 应用于 MDA 任务,并取得了优异的性能。MSGCL 不仅优化了带有噪声的原始图的拓扑结构,而且提出了用于协同对比学习的学习者视图和锚视图。通过 refine 带有噪声的原始网络,获得了高质量的图拓扑结构,提高了网络的预测性能。在 HMDD 3.2数据集上,MSGCL 的表现超过了最先进模型在5折交叉验证下。然而,我们的模型更适合于稀疏数据,当节点数太少时,所获得的先验信息不足,这将限制模型的学习能力。未来,我们希望利用图的编辑距离来准确区分图的结构,或者为锚图和学习者视图设计鉴别器,通过限制损失来增强上游任务,从而生成更好的图拓扑。