
论文链接:Learning Delicate Local Representations for Multi-Person Pose Estimation
时间:2020.03 ECCV’2020
作者团队:Yuanhao Cai, Zhicheng Wang, Zhengxiong Luo, Binyi Yin, Angang Du, Haoqian Wang, Xiangyu Zhang, Xinyu Zhou, Erjin Zhou, Jian Sun
分类:计算机视觉–人体关键点检测–2D topdown_heatmap
目录:
1.RSN50背景
2.RSN50姿态识别
3.RSN50网络架构图
4.引用
1.主要在于学习记录,如有侵权,私聊我修改
2.水平有限,不足之处感谢指出
1.RSN50背景
人体姿态估计对位置精度要求很高,涉及关键点定位和分类。空间信息有利于定位任务,语义信息有利于分类任务,为了提取这两类信息,目前的方法主要集中在层间特征(inter-level )的聚合上。之前的很多姿态估计模型为了更好的利用多尺度的feature,常会在不同level(featuremap size相同大小的为intra-level)之间融合信息(inter-level),再接几层卷积得到最后的输出。
但是有关intra-level间的信息融合研究却很少,该论文的主要关注点就是intra-level。
主要贡献:
1.提出一种新的方法 Residual Steps Network(RSN)。
2.RSN有效地聚集具有相同空间尺寸(层内特征)的特征,获得精细的局部表示,保留丰富的低层空间信息,实现精确的关键点定位。
3.提出一种高效的注意力机制——Pose Refine Machine(PRM),在输出特征的局部和全局表示之间进行权衡,进一步确定关键点位置。
2.RSN50姿态识别
- 网络结构部分
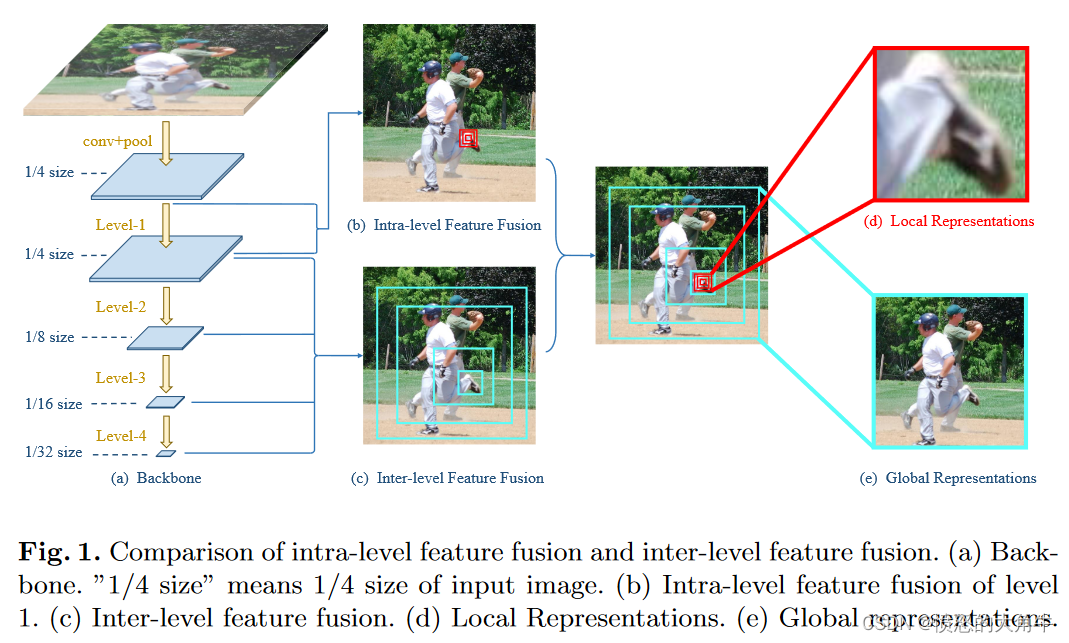
1.(a)是一个提取feature的backbone,特征图被连续地降采样到输入图像的1/4、1/8、1/16、1/32大小。
2.(c)就是inter-level feature fusion,不同层次特征的感受野之间存在很大的差距,用浅蓝色边框表示,通过层间特征融合学习到的表征相对粗糙,阻碍人体姿态的精确定位。在hourglass, CPN,MSPN等经常用到。
3.(b)就是本文着重提出的intra-level feature fusion,由红色边框表示的层内特征的感受野之间的差距相对较小。low-level的feature map可以有效的帮助网络去更准确的定位关键点的位置,可以提取更精细的局部表示,保留更精确的空间信息,这对关键点定位至关重要。

文章提出网络结构Residual Steps Network(RSN),每一个RSN里面都是由基本单元Residual Steps Block(RSB)组成。该网络受到DenseNet的启发,但DenseNet是concate的,随着模型的depth增加,模型会变得越来越大,所以改进DenseNet的连接方式由concate改为element-wise sum,同时使用中间监督,且在最后一个RSN后面接入提出的Pose Refine Machine,对featuremap做最后优化。
-
RSN网络
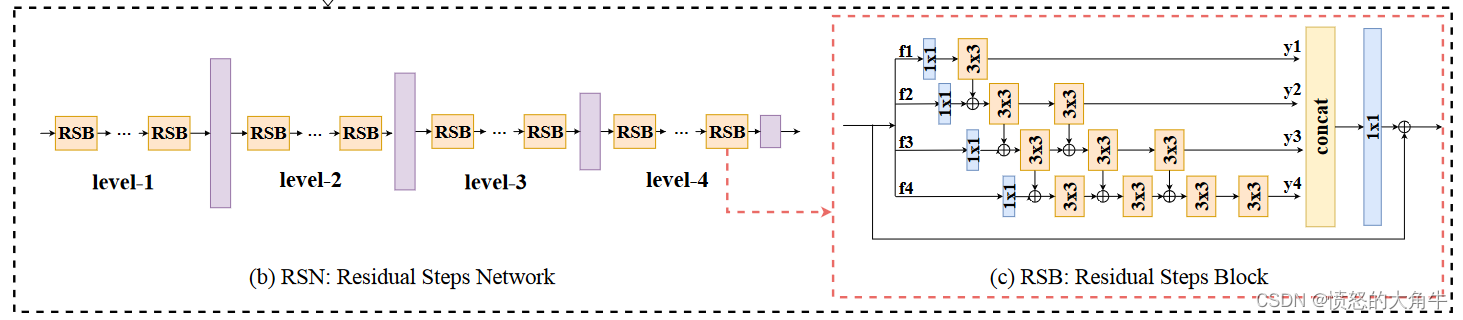 Residual Steps Network通过反复增强RSB内部高效的层内特征融合来学习精细的局部表示,RSB是RSN的组成单元。在RSB中所有的featuremap level都是相同的,所以在RSB中执行的都是intra-level feature fusion。
Residual Steps Network通过反复增强RSB内部高效的层内特征融合来学习精细的局部表示,RSB是RSN的组成单元。在RSB中所有的featuremap level都是相同的,所以在RSB中执行的都是intra-level feature fusion。
RSB首先将特征分成四个分割 f i ( i = 1 、2、3、4 ) f_i(i=1\text{、2、3、4}) fi(i=1、2、3、4),然后分别执行一个1×1conv。从conv1×1输出的每个特征都会经历n个3×3 conv。然后将输出特征 y i ( i = 1 、2、3、4 ) y_i(i=1\text{、2、3、4}) yi(i=1、2、3、4)串联起来并输入到1×1 conv,使用identity连接。
在第 i i i个分支上,前 i − 1 i-1 i−1conv3×3接收第个分支输出的特性,然后第 i i i个conv3×3被设计用来重新融合第 i − 1 i-1 i−1个conv3×3输出的特征。
由于密集的连接结构,特征的小间隙的感受野被充分融合,从而形成精细的局部表示,保留精确的空间和语义信息。同时深度连接的结构可以更好地监督低层特征,这有利于关键点定位任务。 -
RSN感受野分析
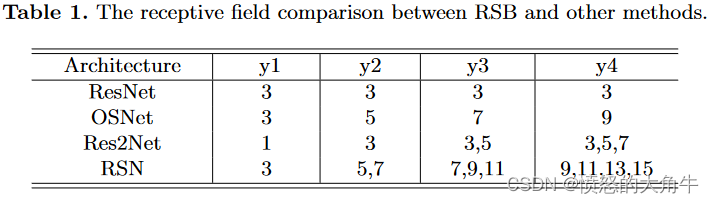
计算第 i i i个卷积层的感受野:
l k = l k − 1 + [ ( f k − 1 ) ∗ ∏ i = 1 k − 1 s i ] l_k=l_{k-1}+[(f_k-1)*\prod_{i=1}^{k-1}s_i] lk=lk−1+[(fk−1)∗i=1∏k−1si]
l k l_k lk表示第 k k k层对应的感受野大小, f k f_k fk表示第 k k k层的核大小, s i s_i si表示第 i i i层的stride。当只关注一个区块中相对感受野的变化时, f k = 3 , s i = 1 f_k=3,s_i=1 fk=3,si=1 ,则可简化为:
l k = l k − 1 + 2 l_k=l_{k-1}+2 lk=lk−1+2
表明RSN比ResNet、Res2Net和OSNet具有更广的尺度范围。
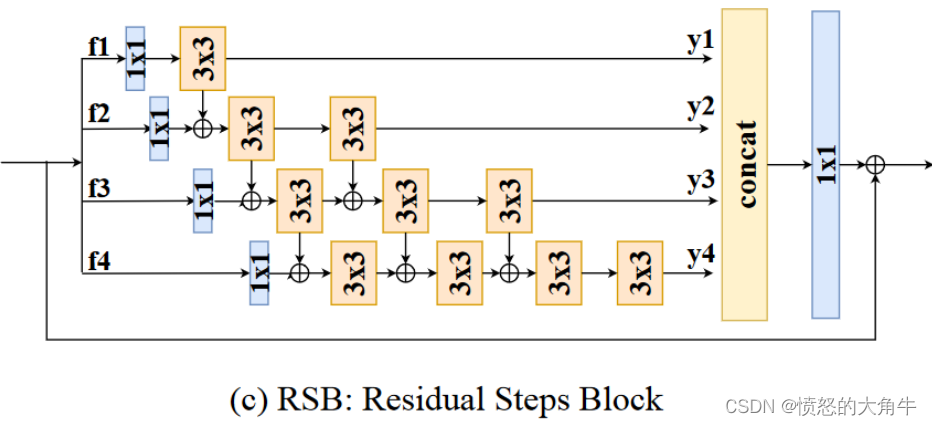
实际上, f 1 f_1 f1只有一个3x3的卷积便得到 y 1 y_1 y1,所以 y ( 1 , 1 ) = 3 \mathbf{y}_{(1,1)}=3 y(1,1)=3。 f 2 f_2 f2有两个3x3卷积,图中可以看到, y ( 2 , 1 ) \mathbf{y}_{(2,1)} y(2,1)是由 y ( 1 , 1 ) \mathbf{y}_{(1,1)} y(1,1)经过1x1卷积后的结果element-wise sum,再通过一个3x3卷积得到,只考虑branch f 2 f_2 f2的感受野,RF y ( 2 , 1 ) = 3 \mathbf{y}_{(2,1)}=3 y(2,1)=3,但由于加入 y ( 1 , 1 ) \mathbf{y}_{(1,1)} y(1,1),相当于2个3x3的卷积,所以RF y ( 2 , 1 ) = ( 3 , 5 ) \mathbf{y}_{(2,1)}=(3,5) y(2,1)=(3,5),余下的同理。
虽然RSB中所有的feature都是在同一level上,但不同branch表达的感受野大小不一样,和其它模型相比,RSB可以表达的感受野更宽,更深。
每个人类关节的大小变化很大,因此,感受野范围更广的体系结构更适合于提取与不同关节相关的特征,有助于学习更多的区分语义表示。
同时,RSN通过RSB内部的small-gap感受野在特征之间建立紧密的连接。这种深度连接的体系结构有助于学习精细的局部表示,这对于精确的人体姿态估计至关重要。 -
注意力机制——PRM
在多级网络的最后一个模块中,使用一种注意力机制-Pose Refine Machine姿势调整机(PRM)来重新加权输出特征。
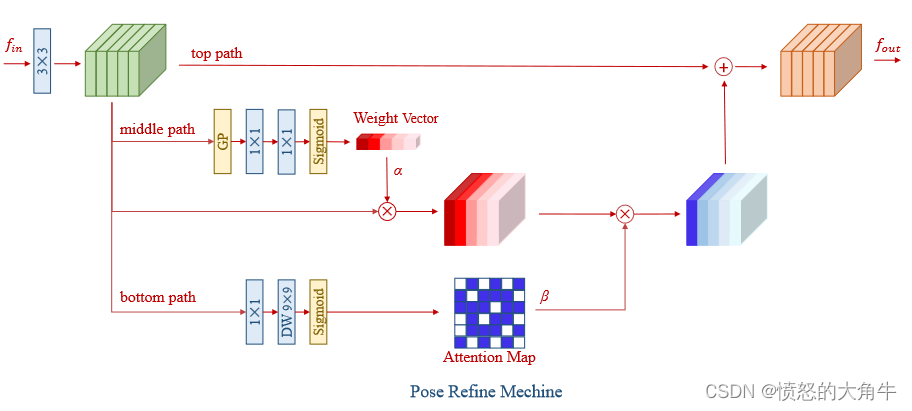
PRM首先对输入的featuremap进行3x3卷积得到feature map f f f,然后分成3个path,top path为Identity,middle path是根据SENet修改的channel attention结构,先经过global pooling,再经过2个1x1的卷积,最后通过sigmoid得到Weight Vector α \alpha α , α \alpha α会和 f f f相乘得到一个新的featuremap f m i d \mathbf{f}_{mid} fmid。bottom path是spatial attention结构,先经过1x1卷积,再通过kernel=9x9的depth wise卷积,最后通过sigmoid得到 β \beta β。PRM结构的输出 f o u t \mathbf{f}_{out} fout: f o u t = K ( f i n ) ⊙ ( 1 + β ⊙ α ) f_{out}=K(f_{in})\odot(1+\beta\odot\alpha) fout=K(fin)⊙(1+β⊙α)
PRM利用注意力机制,有效的利用由前面RSB得到的inter-level和intra-level的混合信息,channel wise attention有利于语义信息,spatial attention有利于精确定位。
PRM中的top identity mapping有助于保留本地特征,有利于精确定位关键点。middle path被设计为在通道方向上重新加权特征,而bottom path被设计为用于空间注意力。 -
总结
1.提出的RSB结构,高效的intra-level feature fusion结构,提高模型的定位精度。
2.提出的PRM结构,进一步对pose的结果进行refine。 -
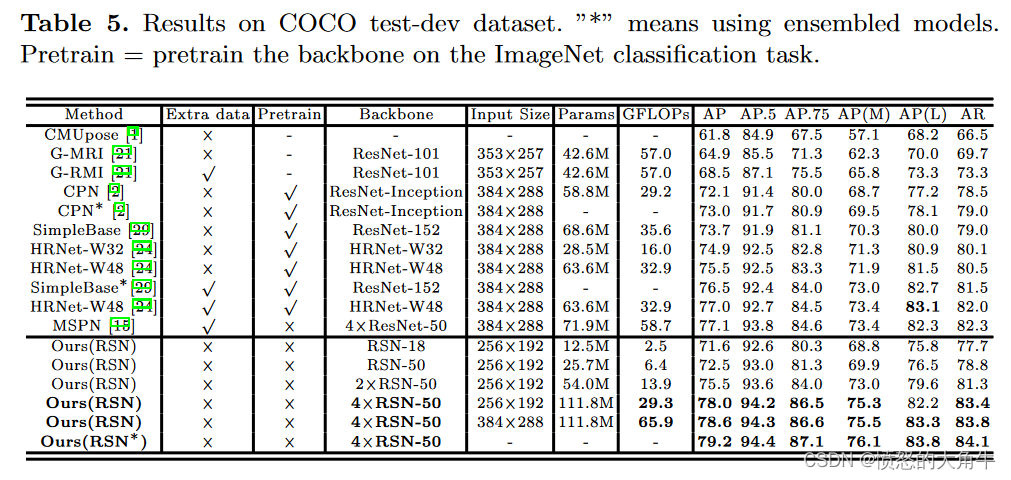
结果评估
COCO数据集评估结果
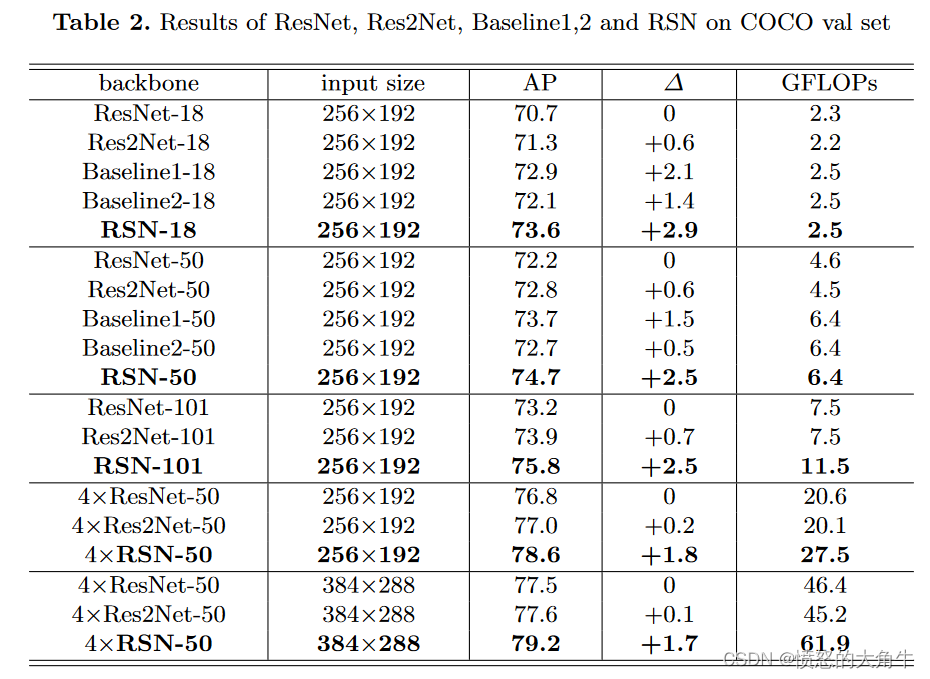
COCO minival数据集基础上对GFLOPs的控制变量评估
随着GFLOPs的增大,ResNet DenseNet Res2Net都趋向于饱和,但RSN结构仍然可以提高精度,和DenseNet的比较可以发现,element wise sum的方式要比concate的方式更有效。
不同网络不同level的最后一层卷积后的输出的不同
RSN在各个level上有效信息比 Res2Net和DenseNet多,响应更准确,范围更小,位置更准确。

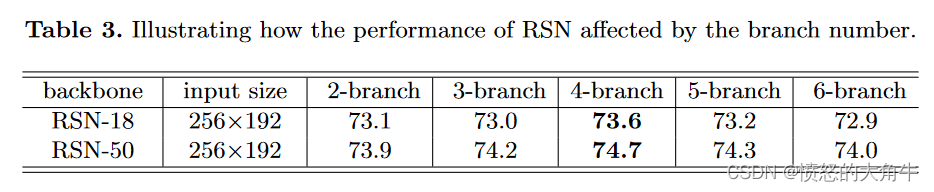
branch的控制实验
branch为多少最佳,branch=4
COCO测试集基础上的主流模型评估

3.RSN50网络架构图
