VOLO: Vision Outlooker for Visual Recognition
概述
视觉 transformer(ViTs)在视觉识别领域得到了广泛的探索。由于编码精细特征的效率较低,当在 ImageNet 这样的中型数据集上从头开始训练时,ViT 的性能仍然不如最先进的 CNN。
作者通过实验分析,作者发现:
1)输入图像的简单标记化未能对边缘、线条等重要的局部结构进行建模,导致训练样本效率低下;
2)ViT 的冗余注意力主干设计导致固定计算预算和有限训练样本的特征丰富度有限。
为了克服这些限制,作者提出了一种新的简单通用架构,称为 Vision Outlooker (VOLO),它实现了一种新颖的 Outlook 注意力操作,以滑动窗口的方式在输入图像上动态地进行局部特征聚合机制。与自注意力侧重于在粗略层面上建模局部特征的全局依赖性不同,作者提出的前景注意力目标是编码更精细的特征,这对于识别至关重要,但被自注意力忽略了。 Outlook Attention 打破了 self-attention 的瓶颈,其计算成本与输入空间维度呈二次方缩放,因此内存效率更高。
换句话说:作者提出了一种新的Vision Outlooker模块,仅使用像素空间相邻的信息来生成attention权重。
方法
Outlooker由一个 outlook attention layer来编码空间信息,而后使用一个MLP来实现不同通道间的信息的交换。
outlook attention:
1)每个空间位置的特征都具有足够的代表性,可以生成用于局部聚合其相邻特征的注意力权重;
2)密集的局部空间聚合可以有效地编码精细级别的信息。
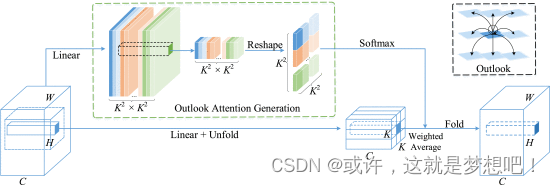
让 V Δ i , j ∈ R C × K 2 \mathbf {V}_{\Delta _{i,j}} \in \mathbb {R}^{C \times K^{2}} VΔi,j∈RC×K2 表示以 (i,j) 为中心的本地窗口内的所有值,即
V Δ i , j = { V i + p − ⌊ K 2 ⌋ , j + q − ⌊ K 2 ⌋ } , 0 ≤ p , q < K . \begin{equation*} \mathbf {V}_{\Delta _{i,j}}=\lbrace \mathbf {V}_{i+p-\lfloor \frac{K}{2} \rfloor,j+q-\lfloor \frac{K}{2} \rfloor }\rbrace, \quad 0 \leq p,q < K. \tag{1} \end{equation*} VΔi,j={
Vi+p−⌊2K⌋,j+q−⌊2K⌋},0≤p,q<K.(1)
位置 (i,j) 处的前景权重直接用作价值聚合的注意力权重,将其重塑为 A ^ i , j ∈ R K 2 × K 2 \hat{\mathbf {A}}_{i,j} \in \mathbb {R}^{K^{2}\times K^{2}} A^i,j∈RK2×K2 ,后跟 Softmax 函数。
Y Δ i , j = MatMul ( Softmax ( A ^ i , j ) , V Δ i , j ) . \begin{equation*} \mathbf {Y}_{\Delta _{i,j}} = \operatorname{MatMul}(\operatorname{Softmax}(\hat{\mathbf {A}}_{i,j}), \mathbf {V}_{\Delta _{i,j}}). \tag{2} \end{equation*} YΔi,j=MatMul(Softmax(A^i,j),VΔi,j).(2)
Outlook 注意力密集地聚合了预测值表示。将来自不同局部窗口的同一位置处的不同权重值相加,得到输出
Y ~ i , j = ∑ 0 ≤ m , n < K Y Δ i + m − ⌊ K 2 ⌋ , j + n − ⌊ K 2 ⌋ i , j . \begin{equation*} \tilde{\mathbf {Y}}_{i,j} = \sum _{0 \leq m, n < K} \mathbf {Y}_{\Delta _{i+m-\lfloor \frac{K}{2}\rfloor,j+n-\lfloor \frac{K}{2}\rfloor }}^{i,j}. \tag{3} \end{equation*} Y~i,j=0≤m,n<K∑YΔi+m−⌊2K⌋,j+n−⌊2K⌋i,j.(3)
我们的前景注意力继承了卷积和自注意力的优点。它具有以下优点。

- 首先,outlook 注意力通过测量标记表示对之间的相似性来编码空间信息,这对于特征学习来说比卷积更具参数效率,正如之前的工作[57]、[66]中所研究的那样。
- 其次,前景注意力采用滑动窗口机制对标记表示进行精细的本地编码,并在一定程度上保留了视觉任务的关键位置信息[42],[71]。
- 第三,注意力权重的生成方式简单高效。与依赖于查询键矩阵乘法的自注意力不同,我们的前景权重可以通过简单的重塑操作直接产生,从而节省计算量。为了看到这一点,我们比较了在具有滑动窗口大小 K×K
M-Adds ( S A ) ≈ 4 H W C 2 + 2 ( H W ) 2 C M-Adds ( L S A ) ≈ 4 H W C 2 + 2 H W K 2 C M-Adds ( O A ) ≈ H W C ( 2 C + N K 4 ) + H W K 2 C . \begin{align*} \text{M-Adds}(\mathbf{SA}) &\approx 4HWC^{2} + 2(HW)^{2}~C \tag{4}\\ \text{M-Adds}(\mathbf{LSA}) &\approx 4HWC^{2} + 2HWK^{2}~C \tag{5}\\ \text{M-Adds}(\mathbf{OA}) &\approx HWC(\text{2}~C + NK^{4}) + HWK^{2}~C. \tag{6} \end{align*} M-Adds(SA)M-Adds(LSA)M-Adds(OA)≈4HWC2+2(HW)2 C≈4HWC2+2HWK2 C≈HWC(2 C+NK4)+HWK2 C.(4)(5)(6)
网络架构
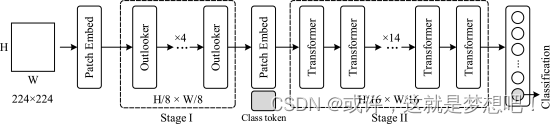
VOLO架构的整体网络架构。首先将图像发送到卷积干以进行补丁嵌入。我们的 VOLO 的主体包含两个阶段,分别由阶段 I 中提出的 Outlooker 块和阶段 II 中的 Transformer 块组成。 Outlooker 负责精细级别的特征编码。更详细的架构信息可以在表 2 中找到。

实验
训练设置
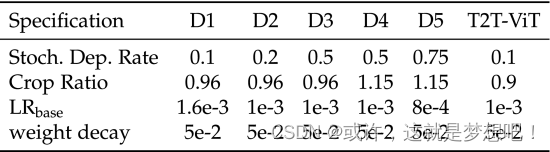
消融实验

方法比较
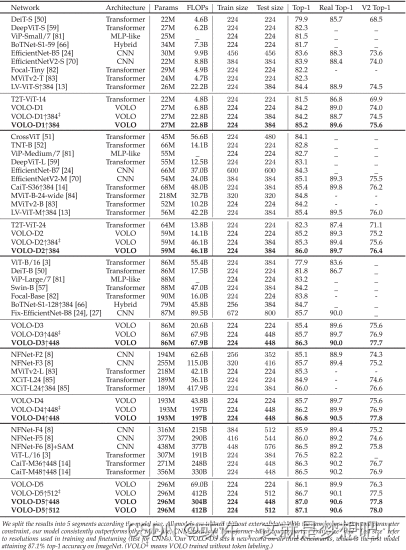
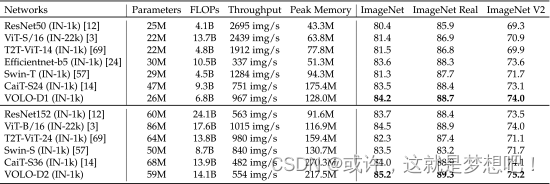
模型性能评估
reference
@article{Yuan2022Sep,
author = {Yuan, Li and Hou, Qibin and Jiang, Zihang and Feng, Jiashi and Yan, Shuicheng},
title = {
{VOLO: Vision Outlooker for Visual Recognition}},
journal = {IEEE Trans. Pattern Anal. Mach. Intell.},
volume = {45},
number = {5},
pages = {6575–6586},
year = {2022},
month = sep,
urldate = {2023-08-24},
issn = {1939-3539},
publisher = {IEEE},
language = {english},
doi = {10.1109/TPAMI.2022.3206108}
}