太长不看版:作者提出了一种DS-net,受resnet启发,设置了4个stage,分别下采样为原图的4,8,16,32倍小。每个stage中含有不同数量的block,作用是可以将输入的tensor按照channel划分为两部分(平均划分),一部分按照原来的分辨率(高分辨率)输入到cnn中来获取一些local信息,另一部分进行下采样统一成原图的32倍小(减少self-attention中的计算成本),输入到self-attention中获得global信息。最后再将二者操作成同样大小的特征图进行融合。
这个融合的过程我们自然而然的会想到使用简单的1*1卷积和上采用来对齐两个特征图,但是作者通过将feature map可视化之后发现,两个分支输出的feature map并不是对齐的,所以作者提出来一种新的融合方法。将两个分支上的特征图展平之后,经过操作得到了(QL,KL,VL)和(QG,KG,VG)这两组参数,其中L和G分别代表两个不同的分支,分别将两个分支中的参数进行了融合互换,形成了(QG,KL,VL)和(QL,KG,VG)这两组参数,然后分别输送到Co-attention中进行计算(这样得到的特征图是对齐的)。在block的最后进行融合,经过四个stage就可以将local特征和global特征进行融合,在第四个stage的最后一层使用全连接层进行分类。
作者提出这是一个即插即用的模块,并且可以应用在很多的下游任务中。作者在实验中使用FPN进行试验,具体结果请看论文。
个人总结:了解了不少论文都在分析cnn和transformer的差异并将二者的优点进行融合,各种各样的融合方式都有。我最近也在做同样的工作,自己实验结果不是很理想,看了这篇文章最大的收获就是作者将feature map可视化了之后发现两者特征是不对齐的。如果不能发现这一点而将两者输出的结果进行想当然的融合,可能真的会拉低模型精度。但是自己没还没去真正的实验这个观点。代码还没来得及看,等看完之后看看有无需要更新的再来更新,但总体感觉较为简单。本人水平有限,哪里有错误请指出!
代码地址:SteveTsui/DS-Net (github.com)
论文地址:[2105.14734] Dual-stream Network for Visual Recognition (arxiv.org)
Dual-stream Network for Visual Recognition
1、介绍
现有的工作存在问题。
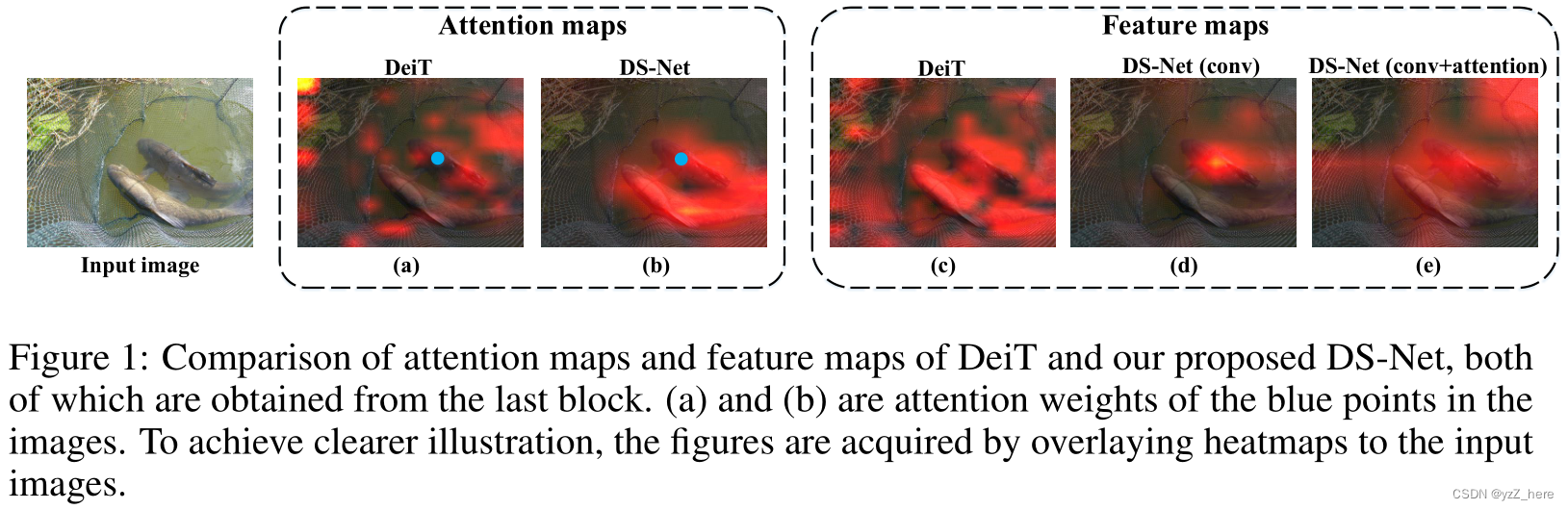
首先,上面提到的作品要么是依次执行卷积和注意力机制,要么只是在注意力机制中用卷积投影取代线性投影,这可能不是最理想的设计。此外,这两种操作的冲突特性,即卷积用于局部模式,而注意力用于全局模式,可能会在训练过程中引起歧义,这使得它们的优点无法最大程度地融合。此外,自我注意在理论上可以通过内置的全对互动来捕捉长距离信息,但很有可能注意会被高分辨率特征图中的邻近细节所混淆和干扰,无法建立起物体层面的 全局模式(见图1(a))。最后,由于序列长度的二次计算复杂性,自我注意的计算成本是难以承受的。尽管PVT[ 45 ]和APNB[ 56 ]降低了关键查询特征的采样率,以提高自我注意算子的效率,但它们都放弃了对图像局部细节的精细捕捉,这大大影响了它们的性能。
我们针对这种问题提出的解决方案。
主要提出了Dual-stream Network (DS-Net)网络。和之前工作提出的单一分支的工作不同,DS-net通过不同分辨率的输入生成了两个不同的特征图,并且通过两个分支保留了local和global信息。我们提出了一种尺度内传播模块来处理两种feature maps。高分辨率特征用于提取细粒度的local信息,并进行深度卷积。而低分辨率的特征预计将总结long-range global 信息。考虑到低分辨率特征本身包含更多的集成信息(位置和语义信息),自我注意机制更容易捕获深层信息,而不是被琐碎的细节所淹没(见图1(b))。这种双流架构将局部和全局表示分离开来,这有助于最大化它们的优点,从而产生比DeiT更好的表示(见图1中的(c)和(e))。低分辨率输入到self-attention中可以降低计算成本。在对双数据流进行并行处理后,我们在ds块末端提出了基于共同注意机制的尺度间对齐模块。这是因为局部细节和全局模式捕获图像的不同视角,这些视角不仅在像素位置上不对齐,而且在语义上也不对齐。因此,该模块设计用于建模复杂的跨尺度关系,并自适应融合局部和全局模式。
本文贡献如下:
提出了双流结构的DS-Net,在DS-block中同时保留了local信息和global信息,使得卷积和自注意力机制的优点得到了最大融合。
我们提出了Intra-scale Propagation and Inter-Scale Alignment(尺度内传播和尺度间对齐)机制,以实现不同分辨率特征内部和之间的有效信息流,从而产生更好的结果。
提出Dual-stream Feature Pyramid Network (DS-FPN),在下游任务上获得较好的成绩。
2.相关工作
Vision transformers
Local and Global Features in Transformers:尽管transformers在global信息获取上有优势,但是基于图像级别的self-attention对于细节的提取还是不到位的。
Transformers和cnn的结合
3.Method
3.1 Dual-scale Representations
网络结构图如下,受到resnet的启发,设置了4个stage,分别下采样4,8,16,32倍。我们的关键思想是在一个相对较高的分辨率中保持局部特征来保留局部细节,而用一个较低的分辨率(1/32)表示全局特征来保留全局模式。在给block中,将输入特征按照维度划分为两部分,一部分用输入到cnn中进行local信息的获取,另一部分下采样到H/32 * W/32*C/2大小之后输入到self-attention中获得global信息的获取,在block的末尾又将两个通道的feature map进行融合,
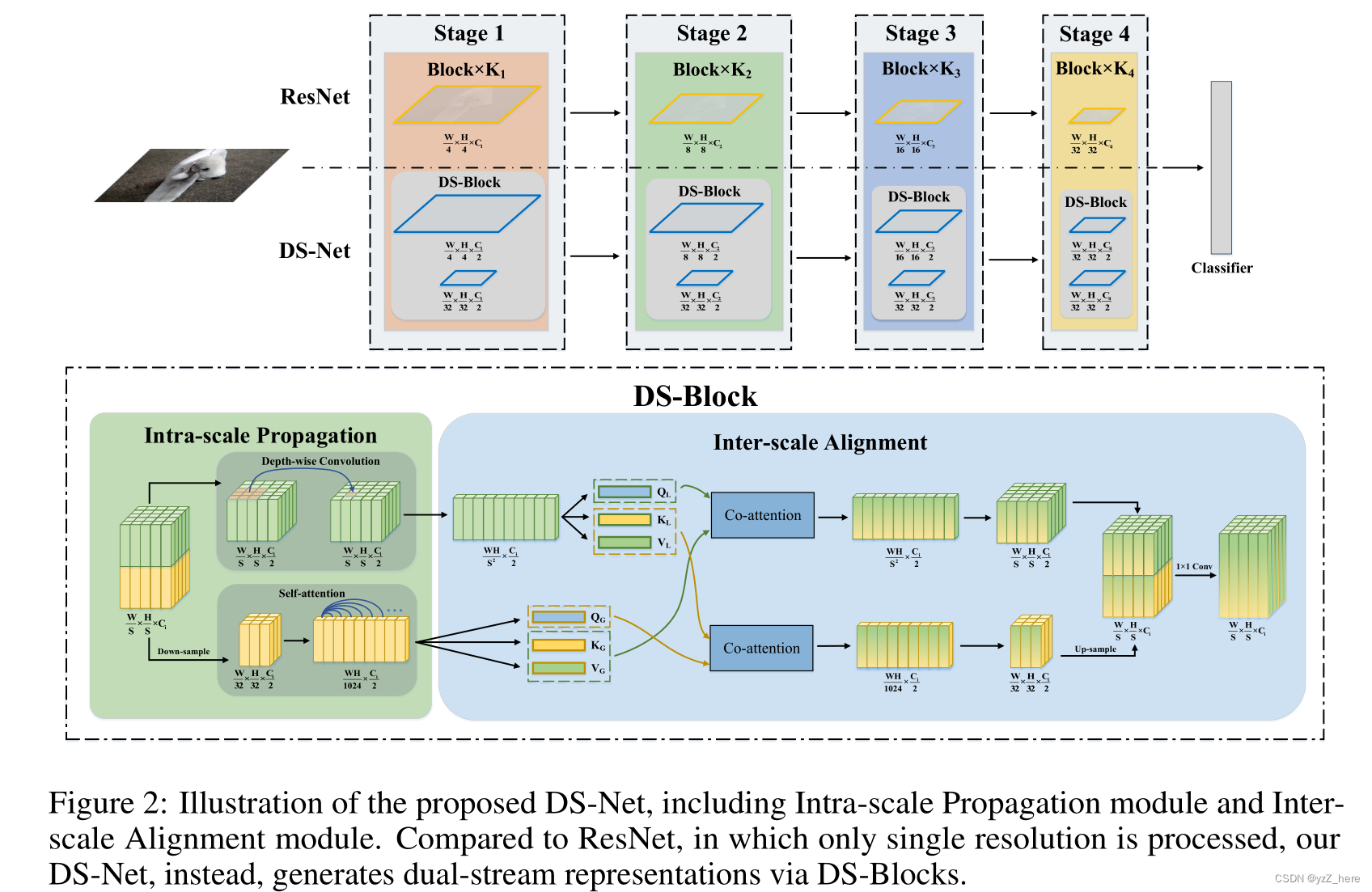
3.2 Intra-scale Propagation
局部特征和全局特征是一个图像从两个完全不同的观点表示。前者专注于细粒度细节,这对于微小物体检测和像素级定位至关重要,而后者旨在建模远程部件之间的对象级关系。因此,给定双尺度特征f l和f g,我们采用尺度内传播模块并行处理。
3.3 Inter-scale Alignment
双分支融合阶段直观的想法就是将低分辨率特征图上采用,然后通过cat操作和conv2d操作将两个分支融合起来,但这样做是缺少说服力的。观察图1中的b和d可以看出低分辨率中的global特征和高分辨率中的local特征并不是对齐的。所以在没有进行研究这两种特征图之前预定义一个连接模式是缺少说服力的。基于前面工作的启发,我们提出了a novel co-attention-based Inter-scale Alignment module,该模块的目的是计算local和global
 token之间的相互关系。如下图所示,两个分支中的KQV进行了不同的组合,上面分支中的KV和下面分支中的Q汇聚到了下面Co-attention模块中(如红框和红色箭头所示)。上面分支中的Q和下面分支中的KV汇聚到了上面的Co-attention模块中(如蓝框所示)。
token之间的相互关系。如下图所示,两个分支中的KQV进行了不同的组合,上面分支中的KV和下面分支中的Q汇聚到了下面Co-attention模块中(如红框和红色箭头所示)。上面分支中的Q和下面分支中的KV汇聚到了上面的Co-attention模块中(如蓝框所示)。
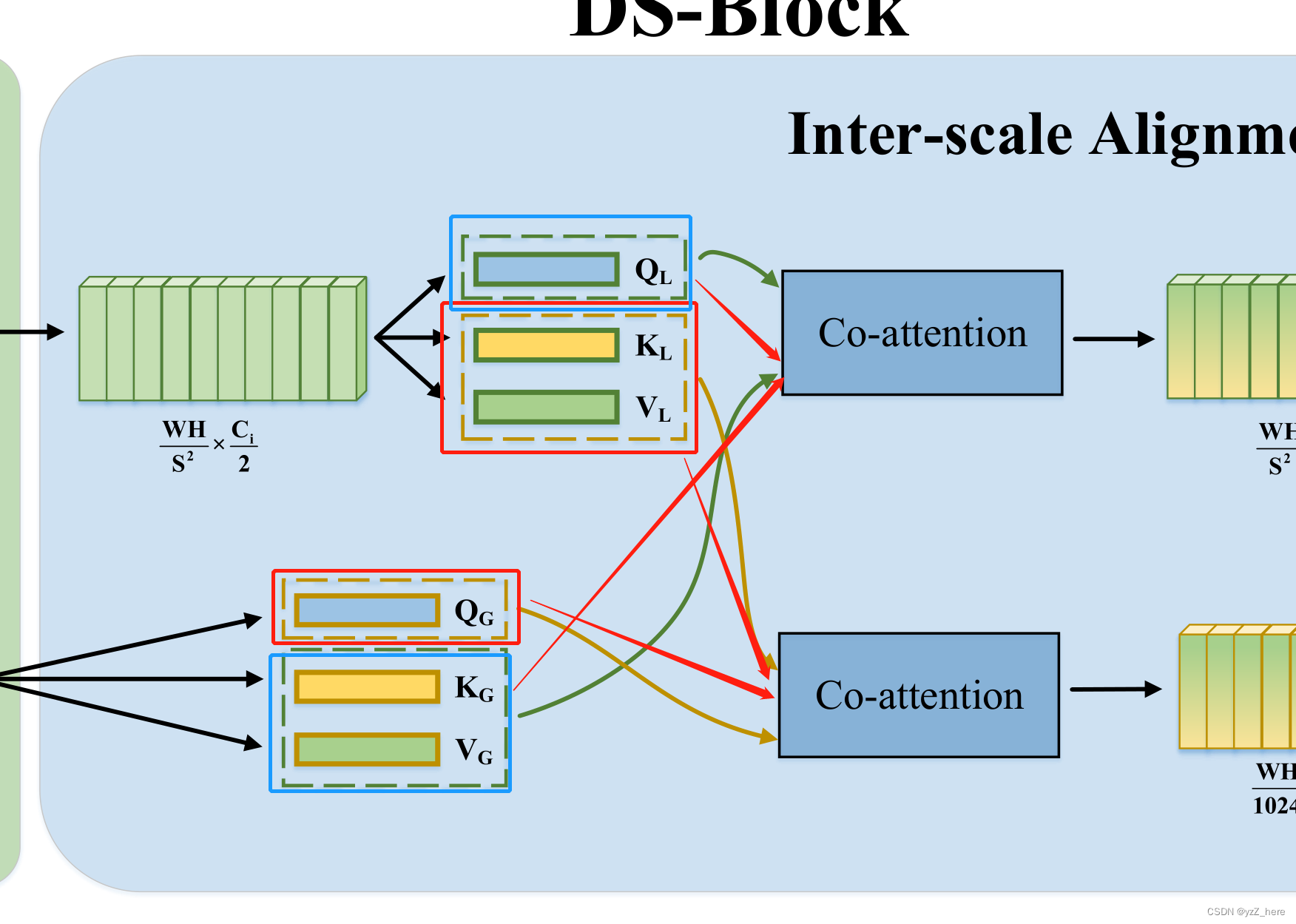
通过Co-attention模块之后全局和局部特征之间的信息有了交互,双分支特征图可以进行对齐。因为特征图已经进行了对齐操作,所以我们可以使用1*1卷积将低分辨率特征图进行上采用操作,最后在进行cat操作。在stage4的末尾我们添加一个全连接层进行分类。
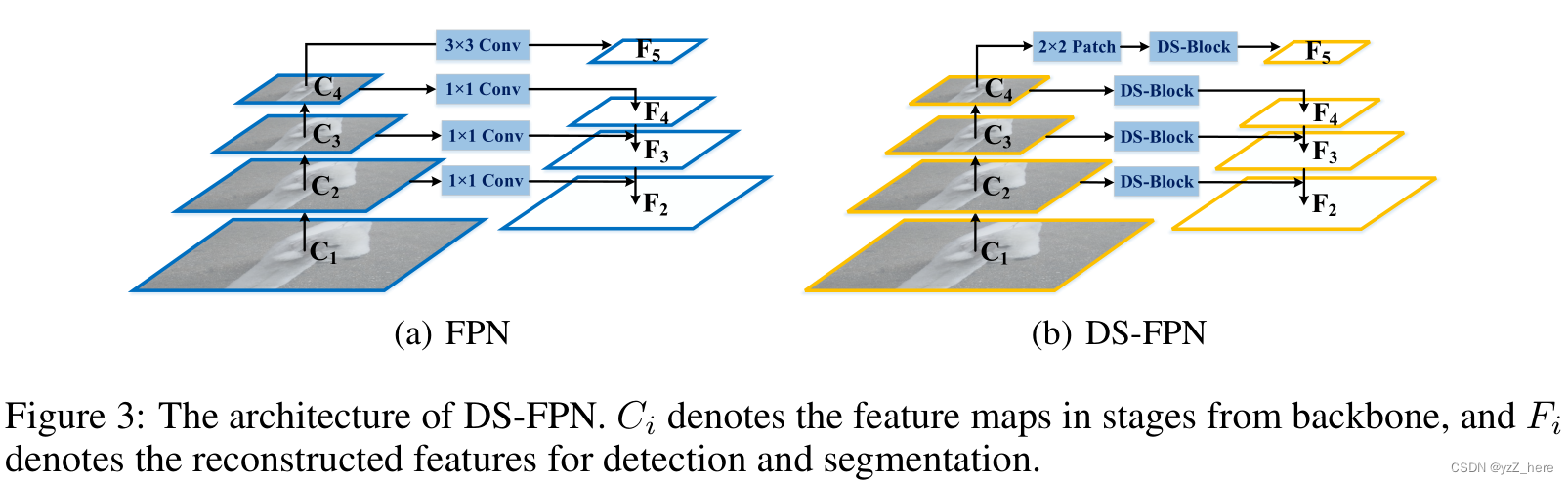
3.4 Dual-stream Feature Pyramid Networks
将上下文信息引入特征金字塔网络(FPN)[23]已经被[49,31]探讨过。然而,以往的方法由于其复杂的体系结构和高分辨率的特征映射,往往会造成大量额外的内存和计算成本。此外,非局部上下文会错过局部细节,这对微小目标检测和分割是灾难性的。在这里,我们将我们的双流设计应用到FPN中,命名为双流特征金字塔网络(Dual-stream Feature Pyramid Networks, DS-FPN),只需在每个特征金字塔尺度上添加DS-Blocks。
通过这种方法,DS-FPN能够在所有尺度上以边际增加的代价更好地获得非局部模式和局部细节,进一步提高了后续目标检测和分割头部的性能。这显示了我们DS-Net不仅可以作为主干,而且可以作为许多其他视觉架构的通用插件构建模块。
与FPN[23]类似,我们以骨干中不同尺度的图像特征作为输入,通过自顶向下的聚合方法输出相应的固定通道号的精细化特征图。我们的结构由自下而上的通道、双流横向连接和自上而下的通道组成。自下而上和自上而下的路径遵循FPN的设计,但这里的横向连接采用DS-Block通过Intra-scale Propagation和Inter-scale对齐。参见图3。
4 Experiments
略
5 Conclusion
主要是提出了一种双流网络,通过不同分辨率的特征图分别提取了local和global特征。在两种特征融合的时候提出了尺度内传播模块和尺度间对齐模块,结合卷积和自注意机制的优点,识别local和global token之间的跨尺度关系。
此外,对于下游任务,我们设计了双流特征金字塔网络(Dual-stream Feature Pyramid Network, DS-FPN),将上下文信息引入到特征金字塔中,利用边际成本进行进一步细化。由于在图像分类和密集下游任务(包括目标检测和实例分割)上的出色表现,我们提出的DS-Net在视觉任务中显示出了良好的潜力。