目录
LDSO——Direct Sparse Odometry with Loop Closure
introduction:(加入了pose graph优化和DBoW词典)
B. Point Selection with Repeatable Features
A comparison of loop closing techniques in monocular SLAM
Map-to-map matching: Clemente et al
Image-to-image matching: Cummins et al.
Image-to-map matching: Williams et al
Visual Place Recognition: A Survey
Describing Places:(局部描述子和全局描述子)
Recognizing Places(各类识别算法,相关原理)
Visual Place Recognition in Changing Environments(动态场景)
A. Describing Places in Changing Environments(在动态环境中描述地点)
B. Remembering Places in Changing Environments(在变化环境中的地点记忆问题)
-
LDSO——Direct Sparse Odometry with Loop Closure
-
introduction:(加入了pose graph优化和DBoW词典)
写论文的时候这个introduction可以用:直接法的优点啊,SLAM系统没有回环检测的缺点啊。
we present an extension of Direct Sparse Odometry (DSO) to a monocular visual SLAM system with loop closure detection and pose-graph optimization (LDSO). 在dso基础上加入了闭合检测和姿态图优化 loop closure and global map refinement are based on BoW and pose graph optimization。
LDSO retains this robustness, while at the same time ensuring repeatability of some of these points by favoring corner features in the tracking frontend. This repeatability allows to reliably detect loop closure candidates with a conventional feature-based bag-of-words (BoW) approach.
Loop closure candidates are verified geometrically and Sim(3) relative pose constraints are estimated by jointly minimizing 2D and 3D geometric error terms. These constraints are fused with a co-visibility graph of relative poses extracted from DSO’s sliding window optimization.
LDSO保留了这种稳健性,同时通过支持跟踪前端的角落特征来确保其中一些点的可重复性。 这种可重复性允许使用传统的基于特征的词袋(BoW)方法可靠地检测闭环候选。
循环回路候选者在几何上被验证,并且通过联合最小化2D和3D几何误差项来估计Sim(3)相对姿势约束。 这些约束与从DSO的滑动窗口优化中提取的相对姿势的共同可见性图融合。
The frontend may localize the camera globally against the current map [4], [5], track the camera locally with visual (keyframe) odometry (VO) [6], [7], or use a combination of both [8], [9], [10].
一个一般的SLAM系统:前端可以根据当前地图[4],[5]全局定位摄像机(orb-slam ptam),使用视觉(关键帧)测距法(VO)[6],[7]在本地跟踪摄像机(LSD-SLAM),或者使用两者的组合. (没读懂,大概指前者可以全局定位,后者只是VO吧 结合可能有局部又有全局优化。)
For example, in order to evaluate the photometric error, images of past keyframes would have to be kept in memory, (这是在说dso呢)and when incorporating measurements from previous keyframes, it is challenging to ensure estimator consistency, since information from these keyframes that is already contained in the marginalization prior should not be reused. We therefore propose to adapt DSO as our SLAM frontend to estimate visual odometry with local consistency and correct its drift with loop closure detection and pose graph optimization in the backend. Note that DSO itself consists also of a camera-tracking frontend and a backend that optimizes keyframes and point depths.(在dso基础上加入了闭合检测和姿态图优化)
However, in this work we refer to the whole of DSO as our odometry frontend.(将整个dso作为前端,虽然dso本身有前端和后端)
If we detect and match features independently from the frontend, we might not have depth estimates for those points, which we need to efficiently estimate Sim(3) pose-constraints, and if instead we attempt to reuse the points from the frontend and compute descriptors for those, they likely do not correspond to repeatable features and lead to poor loop closure detection.
The key insight here is that direct VO does not care about the repeatability of the selected (or tracked) pixels. Thus, direct VO systems have in the past been extended to SLAM either by using only keyframe proximity for loop closure detection [6] or by computing features for loop closure detection independently from frontend tracking and constraint computation [7]. Direct image alignment is then used to estimate relative pose constraints [6], [7], which requires images of keyframes to be kept available. We propose instead to gear point selection towards repeatable features and use geometric techniques to estimate constraints. In summary, our contributions are:
如果我们独立于前端检测和匹配特征,我们可能没有这些点的深度估计,我们需要深度信息来有效地估计Sim(3)姿势约束,如果我们尝试重用前端的点和计算描述符,它们可能不对应于可重复的特征并导致不良的闭环检测。
这里的关键见解是直接VO并不关心所选(或跟踪)像素的可重复性。因此,直接VO系统过去已经通过仅使用关键帧接近来进行闭环检测[6]或通过独立于前端跟踪和约束计算来计算闭环检测的特征[7](LSD-SLAM)而扩展到SLAM。然后使用直接图像对齐来估计相对姿势约束[6],[7],这需要关键帧的图像保持可用。我们建议将齿轮点选择转向可重复的特征,并使用几何技术来估计约束。总之,我们的贡献是:
1)We adapt DSO’s point selection strategy to favor repeatable corner features, while retaining its robustness against feature-poor environments. The selected corner features are then used for loop closure detection with conventional BoW.
2) We utilize the depth estimates of matched feature points to compute Sim(3) pose constraints with a combination of pose-only bundle adjustment and point cloud alignment, and — in parallel to the odometry frontend —fuse them with a co-visibility graph of relative poses extracted from DSO’s sliding window optimization.
我们利用匹配特征点的深度估计(??)来计算Sim(3)姿势约束,结合仅姿势束调整和点云对齐,并且 - 与odometry前端并行 - 将它们与从DSO的滑动窗口优化中提取的相对姿势的共视图融合。
3)We demonstrate on publicly available real-world datasets that the point selection retains the tracking frontend’s accuracy and robustness, and the pose graph optimization significantly reduces the odometry’s drift and results in overall performance comparable stateof-the-art feature-based methods, even without global bundle adjustment.
-
Related Work:
Similar to ORB-SLAM and ourwork, loop closure and global map refinement are based on BoW and pose graph optimization, but with help of the inertial sensors, it suffices to use non-rotation-invariant BRIEF descriptors and do pose graph optimization in 4 degreesof-freedom. (有了惯性传感器,只需使用非旋转不变的简要描述符,并在4自由度下进行图形优化。)While in ORB-SLAM the feature extractionstep costs almost half of the running time, the frontend tracking in VINS-Mono is based on KLT features and thus is capable of running in real-time on low-cost embedded systems. This however means, that for loop closure detection additional feature points and descriptors have to be computed for keyframes.(然而,这意味着,对于循环闭合检测,必须为关键帧计算附加特征点和描述符)
As a direct monocular SLAM system and predecessor of DSO, LSD-SLAM [7] employs FAB-MAP [15] — an appearance-only loop detection algorithm(这个到底指什么呢,应该指的是没有拓扑和metric信息的回环检测吧) — to propose candidates for large loop closures. However, FAB-MAP needs to extract its own features and cannot re-use any information from the VO frontend, and the constraint computation in turn does not re-use the feature matches, but relies on direct image alignment using the semi-dense depth maps of candidate frames in both directions and a statistical test to verify the validity of the loop closure, which also means that images of all previous keyframes need to be kept available
LSD-SLAM的回环检测方案。 我猜他的中心意思就是:前后解耦得太厉害了 一点都不相关啊 我倒要看看这篇文章有什么不同之处。
-
LOOP CLOSING IN DSO(重要!)
-
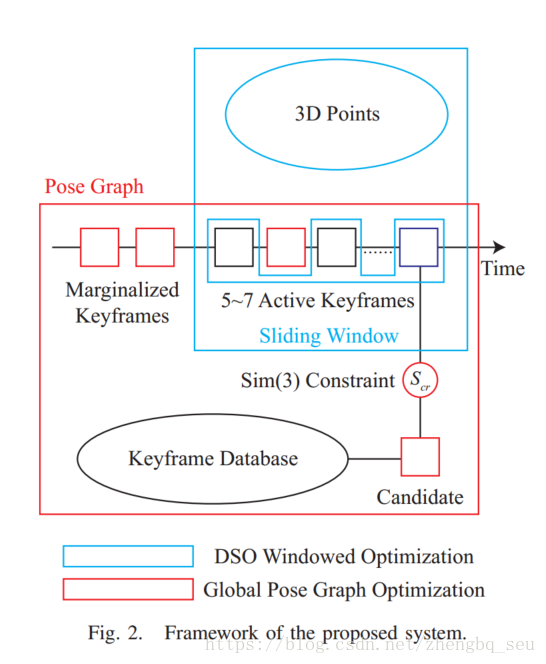
A. Framework
A global optimization pipeline is needed in order to close long-term loops for DSO. Ideally global bundle adjustment using photometric error should be used, which nicely would match the original formulation of DSO. However, in that case all the images would need to be saved, since the photometric error is computed on images. (理想情况下能进行光学全局BA肯定是很好的,但是那样就得保存所有图片,不实际)Moreover, nowadays it is still impractical to perform global photometric bundle adjustment for the amount of points selected by DSO. (对所有点进行BA也不实际啊)To avoid these problems we turn to the idea of using pose graph optimization, which leaves us several other challenges: (i) How to combine the result of global pose graph optimization with that of the windowed optimization? One step further, how to set up the pose graph constraints using the information in the sliding window, considering that pose graph optimization minimize Sim(3) geometry error between keyframes while in the sliding window we minimize the photometric error? (ii) How to propose loop candidates? (关键帧比对BoW)While the mainstream of loop detection is based on image descriptors, shall we simply add another thread to perform those feature related computations? (iii) Once loop candidates are proposed we need to compute their relative Sim(3) transformation. In a direct image alignment approach, we need to set an initial guess on the relative pose (如果有回环了,要进行对齐的时候,初值怎么办呢,这个设置很有影响)to start the Gauss-Newton or the Levenberg-Marquardt iterations, which is challenging in this case as the relative motion may be far away from identity.
需要全局优化才能闭合DSO的长期回路。理想情况下,应使用光度误差进行全局光束调整,这很好地匹配DSO的原始配方。但是,在这种情况下,需要保存所有图像,因为在图像上计算光度误差。而且,现在对DSO选择的点进行全局光度束调整仍然不切实际。为了避免这些问题,我们转向使用姿势图优化的想法,这给我们带来了其他几个挑战:(i)如何将全局姿势图优化的结果与窗口优化的结果结合?(滑动窗口也可以转换为姿态图)更进一步,考虑到姿势图优化最小化关键帧之间的Sim(3)几何误差,而在滑动窗口中我们最小化光度误差,如何使用滑动窗口中的信息设置姿势图约束?(ii)如何提出回环候选人? (BoW)虽然循环检测的主流是基于图像描述符,但我们是否应该简单地添加另一个线程来执行那些与功能相关的计算? (iii)一旦提出回环候选者,我们需要计算它们的相对Sim(3)变换。在直接图像对齐方法中,我们需要设置相对姿势的初始估计来启动高斯 - 牛顿或者Levenberg-Marquardt迭代,在这种情况下具有挑战性,因为相对运动可能远离真值。(不知道怎么解决的,还是说直接计算出当前的位姿然后加入计算就是了?)
Taking these challenges into account, we design our loop closing module as depicted in Fig. 2. Alongside the DSO window, we add a global pose graph to maintain the connectivity between keyframes. DSO’s sliding window naturally forms a co-visibility graph where we can take the relative 3D pose transformations between the keyframes as the pairwise pose measurements. For loop detection and validation, we rely on BoW and propose a novel way to combine ORB features with the original sampled points of DSO. In this way, if a loop candidate is proposed and validated, its Sim(3) constraint with respect to the current keyframe is calculated and added to the global pose graph, which is thereafter optimized to obtain a more accurate long-term camera pose estimation.
考虑到这些挑战,我们设计了循环闭合模块,如图2所示。除了DSO窗口,我们还添加了一个全局姿势图来维护关键帧之间的连接。 DSO的滑动窗口自然形成一个共视图,我们可以将关键帧之间的相对3D姿态变换作为成对姿态测量。 对于回路检测和验证,我们依靠BoW并提出一种将ORB特征与DSO的原始采样点相结合的新方法。 以这种方式,如果提出并验证了回环候选,则计算其关于当前关键帧的Sim(3)约束并将其添加到全局姿势图,其随后被优化以获得更准确的长期相机姿态估计。
-
B. Point Selection with Repeatable Features
关于点的选取:LDSO比DSO要对corners少用一点,这样的话。non-corners和corners都用于前端tracking,但是只有corners用于BoW的解算,这样既可以在弱纹理环境下鲁棒地跟踪,又可以用关键帧中尽可能少的点来做回环检测。
-
C和D没看
-
Conclusion:(包括展望)
In this paper we propose an approach to integrate loop closure and global map optimization into the fully direct VO system DSO. DSO’s original point selection is adapted to include repeatable features. For those we compute ORB descriptors and build BoW models for loop closure detection. We demonstrate that the point selection retains the original robustness and accuracy of the odometry frontend, while enabling the backend to effectively reduce global drift in rotation, translation and scale. We believe the proposed approach can be extended to future improvements of VO or SLAM. (还有很多值得改进的地方)For example, a photometric bundle adjustment layer might increase the global map accuracy.(加光学BA层) In order to ensure long-term operation, map maintenance strategies such as keyframe culling and removal of redundant 3D points may be employed.(关键帧去除和冗余3D点去除) Combining the information from 3D points of neighboring keyframes after loop closure may help to further increase the accuracy of the reconstructed geometry。
-
总结
把DSO整个系统(这个系统是有前后端的)作为前端,后端维护全局姿态图(没有点,保存所有关键帧的相互姿态)。在DSO进行像素点提取的时候,做了一点小改动(corners变少),对关键帧的corners点进行BoW编程,好进行回环检测。
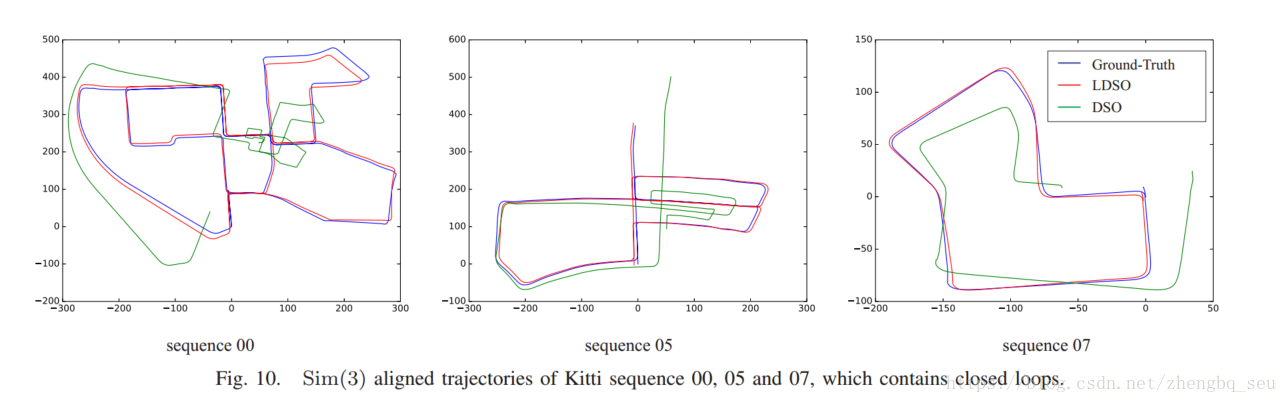
从实验图可以看出,不仅是回环检测,姿态图优化也是必要的,不然无法这么好的拟合ground-truth。但是姿态图那部分编程应该不轻松,更何况还要加线程(官方主页说是公布代码,但是Github链接无法使用了)实验效果挺好。
https://vision.in.tum.de/research/vslam/ldso 并未开源 恨啊
-
A comparison of loop closing techniques in monocular SLAM
Loop closure detection systems for monocular SLAM come in three broad categories: (i) map-to-map, (ii) image-to-image and (iii) image-to-map. (地图到地图,图像到图像,图像到地图)
-
introduction:
The approaches essentially differ in where the data association for detecting the loop closure is done — in the metric map space or in the image space.
这些方法的基本不同之处在用于检测循环闭合的数据关联的部分(在度量图空间中或在图像空间中)。
1) Map-to-map — Correspondences are sought between features in two submaps taking into account both their appearance and their relative positions. In this paper we look at the method of Clemente et al. [1], who applied the variable scale geometric compatibility branch and bound (GCBB) algorithm to loop closing in monocular SLAM. The method looks for the largest compatible set of features common to both maps, taking into account both the appearance of the features and their relative geometric location.
2) Image-to-image — Correspondences are sought between the latest image from the camera and the previously seen images. Here, we discuss the method of Cummins et al. [2,4]. Their method uses the occurrences of image features from a standard vocabulary to detect that two images are of the same part of the world. Careful consideration is given to the distinctiveness of the features — identical but indistinctive observations receive a low probability of having come from the same place. This is done to minimise false loop closures.
3) Image-to-map — Correspondences are sought between the latest frame from the camera and the features in the map. We examine the method of Williams et al. [5] who find potential correspondences to map features in the current image and then use Ransac with a three-point-pose algorithm to determine the camera pose relative to the map.
1)地图到地图 - 在两个子图中的特征之间寻找对应关系,同时考虑它们的外观和它们的相对位置。在本文中,我们来看看Clemente等人的方法。 [1],他应用变尺度几何兼容分支定界(GCBB)算法来闭环单目SLAM。该方法寻找两个地图共有的最大兼容特征集,同时考虑特征的外观及其相对几何位置。
2)图像到图像 - 在来自摄像机的最新图像和先前看到的图像之间寻找对应关系。在这里,我们讨论康明斯等人的方法。 [2,4]。他们的方法使用来自标准词汇表的图像特征的出现来检测两个图像是世界的相同部分。仔细考虑这些特征的独特性 - 相同但不明显的观察结果来自同一个地方的可能性很小。(即使相同,但是不独特,那么也不会采用)这样做是为了最小化错误的循环闭包。
3)图像到地图 - 在摄像机的最新帧和地图中的特征之间寻找对应关系。我们研究了Williams等人的方法。 [5]找到潜在的对应关系来映射当前图像中的特征,然后使用具有三点姿态算法的Ransac来确定相对于地图的相机姿势。
-
The monocular SLAM system
用的是A.Davision的mono-slam的改进版,使用了Hierarchical SLAM【10】的思想,mono本身是基于EKF的,不能用于太大的环境,所以改成很多节submap拼在一起,每个submap独立工作,通过初始帧确定姿态变化,通过两个map的共视点确定相对scale。
看了个大概。
突然意识到回环检测的优化其实我还不怎么懂。
-
Detecting loop closure
-
Map-to-map matching: Clemente et al
The system uses both similarity in visual appearance (unary constraints) (这个怎么比对啊?)and relative distances between features (binary constraints) to find the largest compatible set of common features between two submaps. Once a consistent set has been found, the relative scale, rotation, and translation needed to align the two submaps can easily be determined
(这篇文章的SLAM正好有subMap,不知道是不是特意设置的)系统使用视觉外观中的相似性(一元约束)和特征之间的相对距离(二元约束)来找到两个子图之间的最大匹配的共同特征集。 一旦找到一致的集合,就可以容易地确定对齐两个子图所需的相对比例,旋转和平移。
优点:能在发现共同特征的时候直接对齐 能用于高阶信息中!
问题:地图每次检测到的特征点不能保证是一样的 不能保证能检测到 而且 TP和FP的阈值不好取? 反正很不好用
感觉很难用啊,除非是有子图的系统,比如这篇文章。
前文说不适宜用于sparse 地图。These maps are designed to be good enough to track the camera but otherwise as sparse as possible to allow faster updates. Perhaps a map-to-map based method would be more suitable if the maps contained higher level information or there were more consistency on which potential features are added to the map.
-
Image-to-image matching: Cummins et al.
类似DBoW法。
Cummins et al. [2] have developed a method to detect loop closures based on recognising the visual appearance of previously seen places. (这算visual appearance?)The matching is performed by detecting in each image the presence or absence of features from a visual vocabulary [13] based on SURF features [14], which is learned off-line from training data.
优点:有特征点描述子,挺好。
| 1)Detects true loop closures throughout the environment when tuned for 100% precision精度高 2)Does not require metric map.不需要度量地图 |
当阈值降低的时候,会有一些FP,这个时候用essential matrix 好像可以轻松去除
缺点:耗时,这篇文章用SURF描述子(不知道用SIFT会不会更好)
1)Offline learning of good vocabulary required(需要预字典)
2)Does not make use of geometric information.(几何信息没用)
3)Does not give metric transformation directly(不能直接给出度量转换?)
-
Image-to-map matching: Williams et al
This relocalisation module determines the pose of the camera relative to a map of point features by finding correspondences between the image and the features in the map. The pose is then determined from the correspondences using Ransac and the three-point-pose algorithm(Ransac和三点法)
The relocalisation module is able to run faster than the frame rate through the use of a fast matching algorithm [3] based on the randomised fern classifier [17]. While the features are being tracked, each successful observation is used to train the classifier.
This classifier is fast but it has a high false positive rate. Incorrect classifications are handled using Ransac.(可以挺快,但是错的也多)
优点:For the Pembroke College sequence, the system successfully detected the loop closure as the features in the original map came back into view (Fig. 9(a)). Note that for this method, no common features are needed between submaps as they are for the map-to-map method (map-to-map方法需要common features ,但是Image-to-map不需要)
1) Detects true loop closures throughout the environment when tuned for 100% precision. 精度高
2) Online training for map feature appearance. 在线训练地图特征外形
3) Relative transformation between submaps with scale is computed from trajectory (从轨迹中可从子地图计算相对转换信息和尺度信息)
又快又好,因为它尽可能地用了很多信息,能用几何信息,所以轻松去除FP。scale的没有image-to-image好
缺点:
1)Requires good metric map(需要好的度量地图)
2)Very memory intensive.内存需求很大(递增)the randomised fern classifier(1.25 MB per map feature).
-
一些复合算法
Perhaps even better performance could be achieved through a hybrid system combining the benefits of the image-to-image and the image-to-map methods. The loop closure detection system developed by Eade and Drummond [19] does just this. They first use a bag of visual words approach to establish which submap is in view. This stage is similar to the image-to-image method tested in this paper. Then, local landmarks are identified in the image and the camera pose relative to the landmarks is determined in a similar way to the image-to-map method. This global to local approach harnesses the strengths of each method.
-
Visual Place Recognition: A Survey
-
What is place?
不同于机器人姿态,地点是没有方向的,因此一直以来,地点识别的一个挑战是姿态的不变性问题,即不论机器人在这个地点的哪个朝向都能确保被识别。
The addition of semantic data to maps can improve planning and navigation tasks [65] and requires place recognition to be linked with other recognition and classification tasks, especially scene classification and object recognition. These relationships are symbiotic: place recognition can improve object detection by providing contextual priming for object detection as well as contextual priors for object localization [66], and conversely, object recognition can also aid place recognition [67]–[70], particularly in indoor environments where the function of a place such as “kitchen” or “office” can be inferred from the objects within it, and used to infer the location from a labeled semantic map。
地点识别与物体识别是相辅相成的——即地点识别可以为物体识别提供预激并为物体定位提供先验条件[66];目标识别也可以帮助更好的进行地点识别[67]-[70],特别是在室内场合,例如可以从房间中的物品来判断“厨房”或“办公室”,并于从标记的语义地图中推断位置。
-
Describing Places:(局部描述子和全局描述子)
基于视觉的地点描述方法可以分为两大类:基于提取关键点的方法,以及对整张图片进行描述的方法。对于第一类方法,一些常用的特征点有SIFT [72] 以及SURF [73]。对于第二种方法,常见的全局描述因子有Gist [74] [75]。

Images described using the bag-of-words model can be efficiently compared using binary string comparison such as a Hamming distance or histogram comparison techniques.
Because the bag-of-words model ignores the geometric structure of the place it is describing, the resulting place description is pose invariant; that is, the place can be recognized regardless of the position of the robot within the place. However, the addition of geometric information to a place has been shown to improve the robustness of place matching, particularly in changing conditions [14], [87], [98]–[100]. These systems may assume a laser sensor is available for 3-D information [98], use stereo vision [14], epipolar constraints [100], [101], or simply define the scene geometry according to the position of the elements within the image [102], [103]. The tradeoff between pose invariance—recognizing places regardless of the robot orientation—and condition invariance—recognizing places when the visual appearance changes—has not yet been resolved and is a current challenge in place recognition research
因为词袋模型忽略了它所描述的地方的几何结构,所以得到的地方描述是姿势不变的; 也就是说,无论机器人在该位置内的位置如何,都可以识别该位置。 然而,已经证明向一个place添加几何信息可以提高地点匹配的稳健性,特别是在变化的条件下[14],[87],[98] - [100]。 这些系统可以假设激光传感器可用于三维信息[98],使用立体视觉[14],极线约束[100],[101],(怎么个意思?怎么用的?有什么好处?不用我记录姿态信息了吗)或者根据图像中元素的位置简单地定义场景几何 [102],[103]。无论机器人方向如何,姿势不变性识别位置之间的权衡 - 以及视觉外观变化时的条件不变性识别位置 - 尚未得到解决,并且是当前的地方识别研究挑战。(这两个有什么冲突吗?)
The bag-of-words model is typically predefined based on features extracted from a training image sequence. This approach can be limiting as the resulting model is environment dependent and needs to be retrained if a robot is moved into a new area. Nicosevici and Garcia [56] propose an online method to continuously update the vocabulary based on observations, while still being able to match prior observations with future observations. As a result, a bag-of-words model can be used without requiring a pretraining phase and can adapt to the environment, outperforming pretrained models despite requiring less a priori knowledge [56]
通常基于从训练图像序列提取的特征来预定义词袋模型。 这种方法可能是有限的,因为所得到的模型是依赖于环境的,并且如果将机器人移动到新区域中则需要重新训练。Nicosevici和Garcia [56]提出了一种在线方法,可以根据观察结果不断更新词汇表,同时仍然能够将先前的观察结果与未来的观察结果进行匹配。 因此,可以使用一个词袋模型,无需预训练阶段,并且可以适应环境,优于预训练模型,尽管需要较少的先验知识[56] (看能不能用一下)
全局描述子,比如Gist:
These systems used omnidirectional cameras which allowed rotation-invariant matching at each place
Local features can also be combined with metric information(这个跟几何信息又有什么区别呢?) to enable metric corrections to localization [2], [7], [76]. Global descriptors do not have the same flexibility,
局部特征也可以与度量信息相结合,以实现对定位的度量修正[2],[7],[76]。 全局描述符没有相同的灵活性,
While global descriptors are more pose dependent than local feature descriptors, local feature descriptors perform poorly when lighting conditions change [117] and are comprehensively outperformed by global descriptors at performing place recognition in changing conditions [118], [119]. Using global descriptors on image segments rather than whole images may provide a compromise between the two approaches, as sufficiently large image segments exhibit some of the condition invariance of whole images, and sufficiently small image segments exhibit the pose invariance of local features. McManus et al. [120] used the global descriptor HOG [121] on image patches to learn condition invariant scene signatures, while Sunderhauf ¨ et al. [122] used the Edge Boxes object proposal method [123] combined with a mid-level convolutional neural network (CNN) feature [124] to identify and extract landmarks as illustrated in Fig. 5.
虽然全局描述子比局部特征描述子更依赖于姿态,但[117]指出在光照改变的环境下局部描述子的表现很差,并且[118][119]说明了在变化情况下局部描述子的表现不及全局描述子。因此在图像分割块上使用全局描述因子或许不失为一种折中的方法,因为足够大的图像片段能表现出整张图片对环境变化的不变性,而足够小的图像片段具有局部特征对于观察姿态的不变性。 McManus, Upcroft等人在[120]中在图像块上使用全局描述子HOG来获取不随环境条件改变的场景签名;Sünderhauf, Shirazi等人则在[122]中使用Edge Boxes 物体提取方法 [123] 联合中层卷积神经网络特征[124]来确定和提取路标。
(其中局部描述子好在,它将一幅图描述成了若干个物体的组合,所以对于姿态没有全局描述子那么依赖;但无论如何,这两个都是对一幅图像进行描述,都得检测到跟原来非常一致的整个场景才能匹配上(当然局部还是好一些,没那么刚),我现在希望的是,如果能检测到单一地标就能闭合就好了,也许可以参考landmark的定位,这根目标识别也有关系了,也可以将来用到物体级别的回环检测)

SLAM++ [70]存储了一个三维物体模型数据库,并在导航期间执行物体识别,将其作为高级地点特征。与低级的地点特征比,这种做法不仅能提供丰富的语义信息,并且减少了内存需求(因为在地图中只需存储物体标签而不是完整的物体模型)。
-
Remebering Places(渐进)

A. Pure Image Retrieval 纯图像检索
The most abstract form of mapping framework for place recognition only stores appearance information about each place in the environment, with no associated position information.
Pure image retrieval assumes that matching is based solely on appearance similarity and applies image retrieval techniques from computer vision that are not specific to place-based information [3]. Although valuable information is lost by not including relative position information, there are computationally efficient indexing techniques that can be exploited
用于地点识别的最抽象的映射框架是:仅存储关于环境中的每个地点的外观信息,而没有相关联的位置信息。
纯图像检索假定匹配仅基于外观相似性,并应用计算机视觉中的图像检索技术,这些技术并非特定于基于位置的信息[3]。 尽管通过不包括相对位置信息而丢失了有价值的信息,但是存在可以被利用的计算上高效的索引技术
B. Topological Maps
Pure topological maps contain information about relative positions of places but do not store metric information regarding how these places are related [5], [6], [118], [119]. Topological information can be used to both increase the number of correct place matches and filter out incorrect matches [14], [84]. A probabilistic system like FAB-MAP can be run as a pure image retrieval process by assuming a uniform location prior at all steps, but performance improves when transition information is included through Bayesian filtering or similar techniques(也就是拓扑信息带来的?)
纯拓扑图包含有关地点相对位置的信息,但不存储有关这些地方如何相关的度量信息[5],[6],[118],[119]。 拓扑信息可用于增加正确位置匹配的数量并过滤掉不正确的匹配[14],[84]。(但我觉得拓扑图一下子麻烦了,虽然肯定也会带来鲁棒性的提高) 像FAB-MAP这样的概率系统可以通过在所有步骤之前假设一个统一的位置来作为纯图像检索过程运行,但是当通过贝叶斯过滤或类似技术包含过渡信息时性能会提高。(可以在纯图像检索基础上添加拓扑信息)
而图像检索技术可以利用逆索引技术提高效率,拓扑地图也可以利用位置先验信息来加速匹配
C. Topological-Metric Maps
As image retrieval can be enhanced by adding topological information, topological maps can be enhanced by including metric information—distance, direction, or both—on the map edges.
由于可以通过添加拓扑信息来增强图像检索,因此可以通过添加度量信息来增强拓扑图——在地图边缘加入 距离,方向或两者的信息。
These topological-metric maps can be appearance-based, in which case metric information is only included as relative poses between each place node [149]–[152]. However, metric information about the position of landmarks or objects in a place can also be stored within each node [1], [2], [26], [140], [153]–[156] The metric information within the topological place node can be stored as a sparse landmark map [2], [7], [76], or as a dense occupancy grid map [134] if depth information is extracted from the image data. Although the notion of dense spatial modeling using a truncated signed distance function representation can be traced back to the work of Moravec and Elfes [39] in the mid-1980s, it has only become feasible in the past few years with the advent of GPU technology [134].
这些拓扑度量地图可以是基于外观的,在这种情况下,度量信息只包含在每个地点节点之间的相对位置[151] - [154]。然而,关于地标或物体在一个地方的位置的度量信息也可以存储在每个节点[1] [2] [26] [141] [155] - [158]。如果从图像数据中提取深度信息,则可以将拓扑位置节点内的度量信息存储为稀疏的地标图 [2] [7] [76] 或稠密的占用栅格地图 [135]。虽然使用截断符号距离函数(TSDF)表示的密集空间建模的概念可以追溯到20世纪80年代中期Moravec和Elfes [39]的工作,但是只有在过去的几年随着 GPU技术的出现[135]才可行。
-
Recognizing Places(各类识别算法,相关原理)
Place recognition plays an important role in pose graph SLAM algorithms by providing loop closure candidates
If the place descriptions are appearance based and do not contain any metric information, but the map contains metric distances between places, the system can still use the loop closures to perform metric correction at the place level [149]–[152]. However, if the place descriptions contain metric information associated with the image features, as is the case for FrameSLAM [2], then a more precise correction can be performed
通过提供循环闭合候选,位置识别在姿势图SLAM算法中起重要作用。
如果场所描述是基于外观的并且不包含任何度量信息,但是地图包含场所之间的度量距离,则系统仍然可以使用循环闭合来在场所级别执行度量校正[149] - [152]。 但是,如果场所描述包含与图像特征相关的度量信息,如FrameSLAM [2]的情况,则可以执行更精确的校正。(就是说如果只有循环回路和map,那么map里的度量距离也可以用来度量校正,但是如果有帧帧的度量信息,那就更方便啦!我算是知道为什么LDSO要那样做了)
-
Visual Place Recognition in Changing Environments(动态场景)
(这一节也很有用啊,一般如果是街景条件下的话,关键帧会有很多动态场景,光照什么的可能我暂时考虑不了。但是动态场景如果直接用DBoW真的很有影响,所以要把动态物体和回环检测结合在一起)
A. Describing Places in Changing Environments(在动态环境中描述地点)
1)Invariant Methods:各种应对变化的描述子方案,保留,看以后能不能用
U-SURF CNN 颜色信息
2)Learning Methods(感觉还挺有用的): 通过学习每次地点如何变化的关系来选择不变规律。这种方法假设地点变化是以一种相同的方式进行改变的
Ranganthan,Matsumoto等人[212]研究了一个精细词汇表,精细词汇表类似于词典模型,因为它通过描述符(如SIFT描述符)进行空间分段,但不同之处在于它非常精细,超过1600万个单词,系统学习了这些单词的概率分布。作者提出精细词汇的动机大概是来自于“由于光照变化,视角变化等其他因素的影响,描述子会以一种高度的非线性方式进行变化,学习替代词的分布就可以学习和量化这些变化”。[212]中通过分布式学习训练多个在不同光照条件下的匹配来生成相应的概率分布。(另外一种翻译:在[211]中,通过在相同环境下的多次训练运行来学习分布,并且在不同的照明条件下匹配特征以生成概率分布。原文:In [211], the distribution was learned from multiple training runs over the same environment, and features were matched across different illumination conditions to generate the probability distribution. )改进的表现是使用了传统的词汇树[95],使得数据集中的正确匹配数提高了10%~15%。
有很多类似训练的神经网络 nice!很多想法真的很赞!
B. Remembering Places in Changing Environments(在变化环境中的地点记忆问题)
两种方式:1)如果周围环境发生改变,那么地图也需要改变以继续表示周围环境。系统必须决定什么内容要记住,什么内容要忘记。2)系统如果能保持一个地点的多种表示方式也很有用的,因为地点在不同的配置下是会变化的。
要么地图跟着场景变 要么就保存好几个版本的地图来适应各种变化。
1) Remembering and Forgetting Data:(写论文的时候有用啊感觉,感觉后面的方法是一样的,只不过我现在考虑要先把动态点删掉)
One biologically inspired mapping system passes sensor information through an analog of sensory memory to short-term memory and long-term memory storage areas [219], [220]. In the first stage, a selective attention mechanism decides which information will be upgraded from sensory memory to short-term memory, based on information from the long-term memory. The second stage involves using a rehearsal mechanism to determine which information will be transferred from short-term to long-term memory. Using attention and rehearsal mechanisms ensures that more persistent, stable, and frequently occurring features are remembered, while transient features are forgotten. Elements must be seen and recognized sufficiently often before they are considered for promotion to a higher level of memory. Furthermore, obsolete features are slowly filtered out of the long-term memory. There is a complementary problem of which elements to remember, which typically uses similar criteria [219], [221] to the forgetting process.
一个受生物学启发的建图系统将传感器信息通过感知记忆模拟传递给短期记忆和长期记忆存储区域[219],[220]。在第一阶段,选择性注意机制决定哪些信息将从感觉记忆升级到短期记忆,值得注意的是该机制基于来自长期记忆的信息。第二阶段涉及使用排练机制来确定哪些信息将从短期记忆转移到长期记忆。使用注意力和排练机制可确保记住更持久,稳定且经常出现的特征,同时忘记瞬态特征。在考虑将元素提升到更高的记忆水平之前,必须经常能充分地看到和识别该元素。此外,过时的功能会从长期记忆中慢慢过滤掉。存在一个需要记住的元素的补充问题,这些元素通常使用与遗忘过程类似的标准[219],[221]。
Andrade-Cetto and Sanfeliu [222] required that features be trustworthy and reliable as well as up-to-date in order to be retained, while Bailey [221] considered a usefulness criteria based on visibility—a feature that can be blocked by other elements of the environment is liable to suffer from occlusion errors and be less useful in the future. Johns and Yang [102] and Hafez et al. [223] used a bag-of-words model and applied a quality measure to determine useful features to retain, considering both feature
distinctiveness and feature reliability when generating a model of a location. Johns and Yang [224] also proposed a generative
bag-of-words model that considered the variance as well as the mean value of each data point when matching scenes.
Andrade-Cetto和Sanfeliu [222]要求这些功能值得信赖,可靠且最新,以便保留,而Bailey [221]则坚持基于可见性的有用性标准 - 可被环境的其他元素阻挡的特征容易受到遮挡错误的影响,并且在将来不太有用。 Johns和Yang [102]以及Hafez等人。 [223]使用词袋模型并应用质量测量来确定要保留的有用特征,在生成位置模型时考虑特征区别性和特征可靠性。 Johns和Yang [224]也提出了一种生成词袋模型,它在匹配场景时考虑了每个数据点的方差和平均值。(棒!都要看!一起用!综合考虑!)
2) Multiple Representations of the Environment:(太复杂了,有点晕,之后再看吧)
当系统维护相同的多个地图环境时,只有在需要时才添加新的地图配置,而不是按照预先设定的时间表[221]。此外,Stachniss和Burgard[228]注意到不是每个地点都需要多个地图来表示(比如在门口可能会表现出更多的变化)。这些区域可能只有1~2个关键配置(例如一扇门可能会打开或关闭)。所以世界可以用有限数量的子图来被描述得足够准确。只有在某个区域中发现了动态活动,才会把它作为子图和剩下地图分割开。使用模糊k-均值聚类和贝叶斯信息准则来确定这个地区的最优匹配数量。
这篇文章的结论可以用。