【论文阅读】Action Recognition Using Visual Attention
这是一篇16年的CNN+LSTM形式的论文,它开创性地引入了注意力机制,使得15年之后沉寂许久的CNN+LSTM的网络结构的结果得到了提升,而且本文的探索性实验做的都非常地好,非常值得一读。
论文地址:链接地址
代码(pytorch):链接地址
正文
人的视觉并不会关注场景中的所有物体,而是通常会聚焦场景中的不同的位置来获取有用的信息,所以本文在基础的CNN+LSTM的网络结构中添加了注意力机制,使得网络可以只关注那些视频中与行为类别强相关的区域。实验表明本文提出的 attention cnn-lstm 比传统的lstm要好。
注意力attention可以分为 soft attention 和hard attention,soft attention 可以使用梯度下降算法学习,而hard attention 可以使用强化学习、maximizing a variational lower bound、importance sampling算法来学习。本文的CNN+LSTM的网络结构中添加的是soft attention。
网络结构
attention CNN_LSTM的网络结构是怎样的呢?基础的CNN、LSTM网络的知识我就不详细地介绍了。具体的网络结构如下图所示:
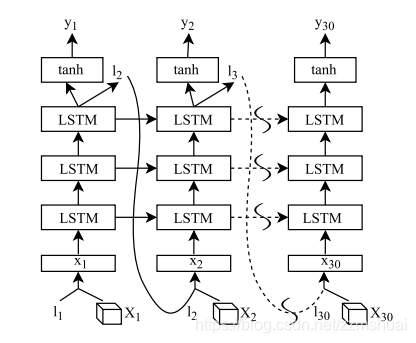
其中
表示 第
帧视频帧输入到CNN网络中输出的feature map,尺寸为
,其中K表示feature map的空间尺寸,C表示feature map的channel维度。
表示第t帧对应的注意力图,大小为
的向量,注意力图与卷积特征图相结合得到
,为当前时刻LSTM网络的输入。LSTM网络的输出经过tanh非线性变换后作为整个网络当前时刻的输出。整个网络的结构就是这样,下面会更加详细地介绍网络各个模块的计算方法。
注意力图(attention map)的计算
我们知道注意力图是要与CNN feature map 进一步结合的,那么 attention map 的大小为什么为
的向量呢?因为CNN输出的卷积特征图的尺寸为
,如果沿着feature map的空间维度展开,可以看成是 k×k个d维的向量,每一个向量对应着输入视频帧中不同区域的卷积特征值,之前说过我们添加注意力机制的目的是让网络能够关注视频帧中与行为类别相关的区域,所以attention map 的尺寸应该与feature map的空间尺寸一一对应,从而加强感兴趣区域卷积特征,减小或忽略不感兴趣区域的卷积特征。
attention map的计算方法如下式所示:
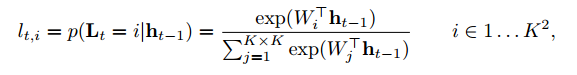
可以看到其是根据前一时刻最高层的LSTM的隐藏单元计算而来,其实就是相当于将
输入到全连接层中,得到输出再经过softmax层,最终得到的就是注意力图attention map
,全连接的尺寸为
。
注意力图与卷积特征图的结合
前面也讲到了注意力图的目的是为了确定输入帧中不同区域的卷积特征的权值,所以理所当然的结合的方法就是加权平均了,如下式所示:
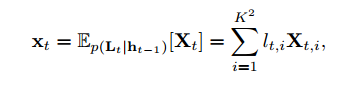
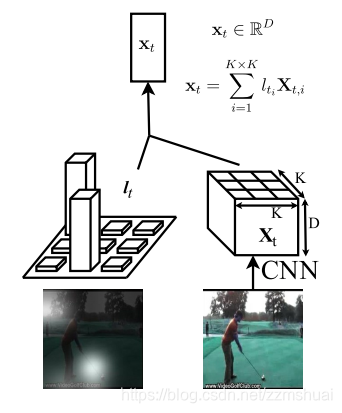
卷积feature map 经过 attention map的加权平均即为LSTM网络的输入,得到的
为大小为C的向量,其中C为feature map的channel维度,应该很容易理解。其过程如下图所示:
LSTM中 cell单元的初始化
文章中用了一种比较特别的
和
初始化的方法,如下所示:
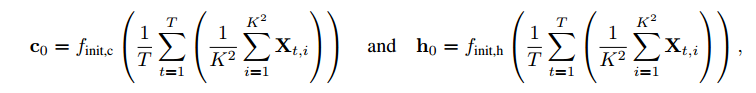
文章认为这种初始化方法会使得网络更加容易收敛,这个小trick可以先记着,说不定以后就有大用了。
网络的损失函数
本文使用的损失函数如下式所示:
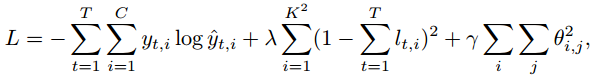
可以看到第一项为交叉熵损失,分类中最常用到的损失,不解释,第三项为正则项,也叫weight decay,也不解释了,咱们可以详细地看一看第二项,文章中称第二项为双重随机惩罚项,首先看括号内的,它的意思是 视频输入帧中第i个区域对应的attention map的权值,在所有的时间段内的加和为1(没太看懂加这个约束的用意,不过后面的实验表明
的值取0的时候准确率是最高的,有点尴尬,哈哈)。
网络细节
CNN使用的是GoogLeNet,输入的视频长度为30帧,大小为224x224,LSTM为3层,每一层的隐藏神经元为512个,在非循环层使用dropout。
实验结果
引入注意力机制是否更有优势?
因为文章提出的网络结构中引入了注意力机制,所以该网络能够聚焦于输入视频帧的局部区域,那么这种注意力机制对于行为类别的识别是否有帮助呢?文章做了相关的对比实验,使用平均池化和最大池化来代替attention map,这样网络就不会适应性地关注输入视频帧中的某一局部区域,从而可以看出引入注意力机制所带来的影响。实验结果如下表所示:
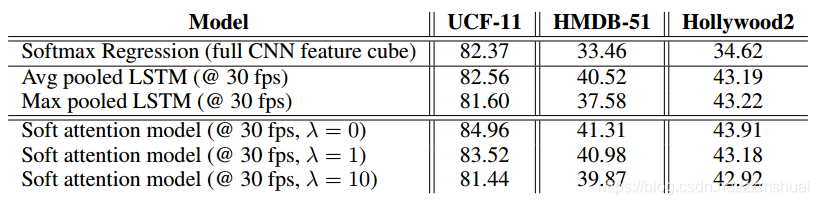
可以看到在所有的数据集上,都是soft attention model的实验结果最好,说明在网络中引入注意力机制是非常有效的。
损失项系数 对注意力机制的影响?
由上一问的表中我们可以看到 双重随机惩罚项的系数
为0时,模型的准确率最高,那么双重随机惩罚项系数
的数值对注意力会产生怎样的影响呢?即随着
的数值发生变化,模型关注的区域发生了哪些变化呢?文章做了相关的实验,实验结果如下图所示:

可以看到当
时,模型只会固定地关注视频帧中的一小部分,随着
的数值的增加,模型关注的范围越来越大,当
时,模型几乎是聚焦视频帧中的所有区域,就像平均池化一样。
模型一般会关注视频帧中的哪些区域呢?
我们知道模型引入注意力机制之后,会聚焦视频帧中的某些局部区域,视频中的区域可以分为前景和背景,那么模型主要关注哪些区域呢,文章测试了几段分类正确的视频,如下图所示:



可以发现模型不仅能聚焦于目标前景,根据前景得到正确的行为类别,同时模型在有些情况下(如摄像头距离太远)也会关注视频帧中的背景,根据背景来推理出正确的行为类别。

输入的帧率会对聚焦的区域产生影响吗?
文章同时测试了在不同的输入帧率下,模型对于视频帧聚焦区域的变化,如下图所示:

可以看到无论在30fps和6fps的输入中,模型都会关注到高尔夫球的区域,也就是说高尔夫球的区域对于attention map的响应是与输入帧率无关的。
引入注意力机制模型的缺点
上面讲了很多模型的优点,那么这种模型存在哪些缺点呢?这种模型的缺点主要有以下两点:
-
端到端训练的注意力图不是足够的稳定,如下图所示,虽然是非常简单的动作,但是模型还是聚焦到了与行为完全无关的区域(个人猜测可能是训练数据量的问题,这种端到端的注意力图还是需要庞大的数据)。

-
注意力图对最终的分类结果影响比较大,所以尽管只是改变了注意力图中聚焦的位置,而不改变网络结构中的其他参数,那么网络还是会分类错误,如下图所示,对于在篮球场玩足球的这种行为,当网络模型聚焦在地板上时,会误分类为游泳,当模型聚焦在目标人物的头顶时,会误分类为排球。所以在注意力图不是足够的稳定的情况下,这个特性也可以认为是缺点。

最理想的注意力图长啥样?
文章最后做了一个有趣的实验:最理想的注意力图张得啥样呢? 文章将网络的其他参数固定,只训练注意力图,从而可以得到最理想的attention map,以足球的行为类别为例,实验结果如下图所示:

从上图可以看到,最理想的attention map会聚焦于足球运动员的腿部。