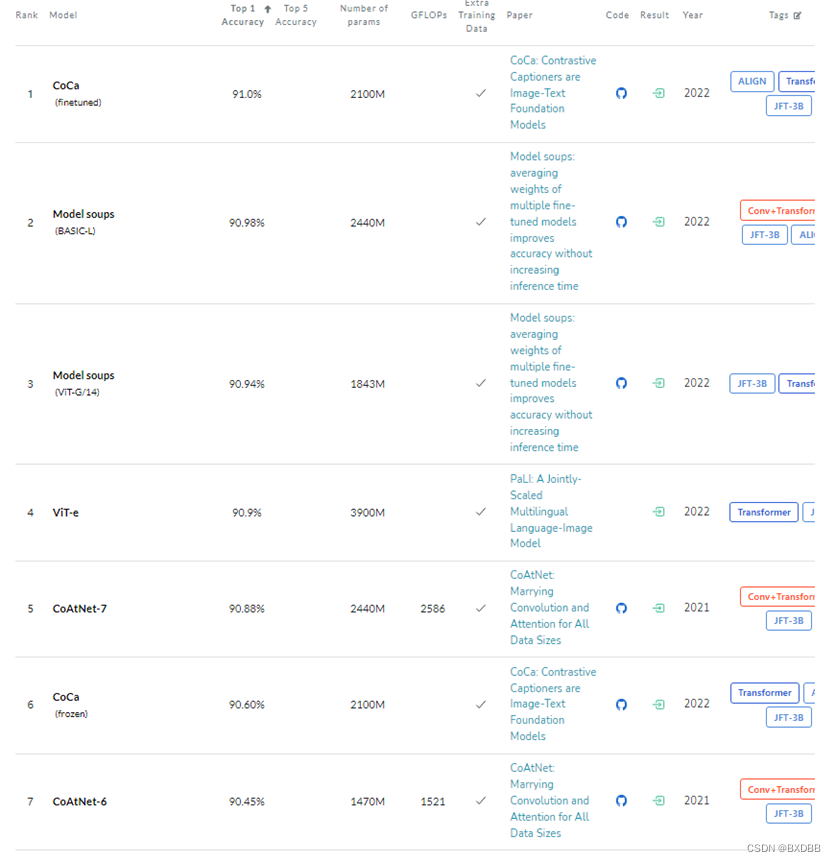
这里我截了一下在Imagenet数据集上完成图像识别任务的准确率最高的前15个模型,基本上都是ViT模型的变体,而且模型规模很大,参数量上千M。除此之外,这些模型中绝大多数是需要在额外的大规模数据集上进行训练,以增强模型的泛化性,这里用到的数据集是JFT-300M/3B,是google的非公开的数据集,所以使用这些数据集的模型都有谷歌的人参与。
出于自己实验的考虑,我就想找一个参数规模比较小,不需要用到额外大规模数据集进行训练,性能又还不错的模型。
于是选择了这篇论文提出的VOLO模型。这是一篇去年6月份公开,今年发表在pami上的论文。

论文链接:VOLO: Vision Outlooker for Visual Recognition | IEEE Journals & Magazine | IEEE Xplore
https://arxiv.org/abs/2106.13112
Code:
GitHub - sail-sg/volo: VOLO: Vision Outlooker for Visual Recognition
背景
自从自注意力机制在语言模型中取得成功(比如说Transformer),谷歌团队他们就把同样的方法用在计算机视觉任务上,ViT就是第一个可以直接用在图像分类上的纯transformer模型。
虽然ViT在视觉任务上也能取得不错的效果,但是在中等规模的数据集上,如果采取从头训练的策略的话,ViT模型的性能还是会落后于与他参数规模相当的CNN网络。
本文作者猜想ViT模型主要有以下两个主要的局限:
1. 直接把输入图像分割成一个个的patch然后flatten为token这种处理,使得ViT无法对图像的局部结构(如边和线)进行建模,因此ViT需要比CNN模型多得多的训练样本(如JFT-300M用于预训练)才能达到相当的性能;
2. ViT的注意力主干网络是直接从NLP领域拿过来用的,所以并没有针对视觉任务做相应的优化,其中存在较多的冗余导致难以学习较丰富的特征。
pilot study
为了验证自己的猜想,作者做了一个实验。

在ImageNet数据集上训练得到的ResNet50、ViT-L/16和T2T-ViT-24的特征可视化
作者把在ImageNet上训练得到的ResNet50、ViT-L\16和T2T-ViT-24模型(本文作者之前的工作)在以上这张图片上的特征进行了可视化。
通过实验观察到ResNet模型从底层(conv1)到中间层(conv25)逐步捕获到一些局部结构(边缘、线条、纹理等),如绿框所示。然而ViT却很不相同,从底层的注意力块到高层的注意力块,都在捕获全局的关系(比如说整只狗),但是对结构化的信息建模较差。该现象说明直接将图像分割展平为token,这种普通的ViT模型会忽视图像中的局部结构;
同时,还观察到ViT模型很多通道里面的值都为0或1,呈现出白色或者黑色,如红框标注所示,这说明ViT的主干网络并不像ResNets那样高效,在训练样本不足的情况下,提供的特征丰富度有限。
相关工作 Tokens-to-Token module(ICCV 2021)
针对第一个问题,作者原先有一篇论文的工作提出了Tokens-to-Token的模块,通过对一个token周围的tokens进行整合和简化来捕获一些局部结构信息。

对于一个T2T的计算流程:上一步输出的Ti首先经过一个T2T Transformer层(这个层可以是标准的Transformer层,也可以是高效的Transformer层),接着将得到的tokens做Reshape操作使其变为一个 ‘image’,【也就是将tokens的shape由(l , c)变换为(h , w , c) ,】然后就以overlapping的方式来对image进行分割,所谓overlapping的方式就是切分的块与块之间有重叠,切分之后再做flatten处理,作为当前T2T 模块的输出。(参考知乎)
通过这种有重叠的切分方式,来自周围patch的局部结构信息就会被嵌入到tokens中,通过多个T2T的迭代之后,就可以将局部结构聚合为最终tokens。并且,作者在聚合的过程中还减少了token的长度,这对后续减小时间复杂度有益。
虽然T2T模块的引入提升了原始ViT模型的性能,但与最好的CNN模型相比仍有较大差距。因此本文基于原先的工作,提出了一种新的简单而轻量级的注意机制,称为outlooker,并基于该注意力机制,提出了VOLO模型,通过2-stage架构设计实现了精细的token表示和全局信息聚合。
Outlook Attention

OutLooker的提出主要基于以下两点:
a.每个空间位置的特征都具有足够的代表性,可以生成聚集了局部邻近信息的注意力权重;
b.密集的局部空间聚合信息可以有效地编码精细层次的信息。
下面介绍本文提出的这个outlook注意力。(左上角的图展示的是一个窗口内的特征运算流程,个人感觉左上角的图和论文中的公式不太好理解,直接看代码可能更好理解一些,注意伪代码有所简化,代码中还有一些运算细节,比如说stride、多头注意力实现等)
以H×W×C的输入特征为例。对于特征中的每个(i,j)的空间位置(比如图中的蓝色小矩形柱),outlook注意力要计算它与以它为中心的大小为K*K窗口内所有邻居的相似度,也就是虚线矩形柱内的范围。
具体计算过程如伪代码所示:
比如对于一个大小为28*28*192的输入特征X,
通过线性映射和调整维度顺序得到V,大小为(192,28,28)。
然后通过unfold的操作(也就是以2为步长移动窗口,并提取出窗口内的特征)和重构矩阵、调整维度得到最终的V,大小为(196, 9, 192) 。
然后是计算注意力权重。
作者提供的代码比伪代码还多一步平均池化操作,先对X进行平均池化,得到大小为(14, 14, 192) 的中间特征,然后是输出维度为k^4的线性映射,得到输出矩阵维度为(14,14,81),再reshape成(196,9, 9),最后输入softmax函数计算注意力权重。
最后把注意力权重矩阵跟v矩阵相乘,得到维度为(196,9,192)的中间特征,再通过调整维度、重构矩阵、fold操作逆变换回去,得到(28,28,192)的特征。
以上就是一次outlook注意力机制实现的过程。在代码实现的过程中,跟transformer一样还用了多头的机制。
Network Architecture
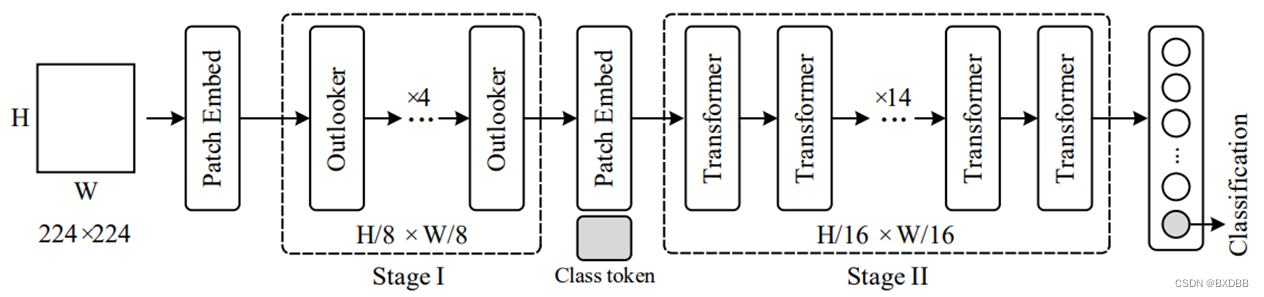
VOLO架构
VOLO的整体架构如上图所示,其中Outlooker块相对于原始的Transformer块,就是把其中的自注意力换成了刚刚介绍的outlook注意力。
对于输入的图像,先经过以卷积为主干网络的Patch Embed层提取初步的特征(tokens)。VOLO的主体包含两个阶段,第一阶段是由堆叠的Outlooker块组成的,负责编码精细层次的特征(比如说线条);第二阶段是由堆叠的Transformer块组成的,负责对全局的信息进行编码。

根据outlooker块和transformer块的数量的不同,作者这里给出了5种不同规模的模型。最小的VOLO-D1有27M个参数,最多的有296M参数,比原始的ViT模型小了很多。

在没有额外训练数据的情况下,在ImageNet数据集上进行训练,左上方的表中展示的是不同规模的VOLO模型的top1准确率。
右边这张图展示的是不同规模的三种模型所能达到的top1准确率,都是在没有额外训练数据的情况下,性能最好的基于Transformer的模型(CaiT)和基于CNN的模型(NFNet)与本文模型进行对比,可以看出在参数规模相当的情况下,本文能达到的top1准确率是最高的。
下面这张表是文中的一个消融实验的表,只是为了说明outlook注意力机制、数组增强等模型设计方式和训练策略的有效性。
代码的readme写得很详细,代码比较简洁,几乎不会遇到什么问题。使用单张GeForce 3090的卡在ImageNet的训练集(128w多张图像)上进行训练,即使是训练这个参数量最小的模型(VOLO-D1),训练一轮大概需要3个多小时,总共需要训练310轮,于是没有继续训练,我选了两个作者训练好的模型测试了一下,测试的结果跟报告的准确率是完全一样的。
参考:
[1] L. Yuan, Q. Hou, Z. Jiang, J. Feng and S. Yan, "VOLO: Vision Outlooker for Visual Recognition," in IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, doi: 10.1109/TPAMI.2022.3206108.
[2] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 558-567.
[3] https://zhuanlan.zhihu.com/p/462489302