RIS 系列 TransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer 论文阅读笔记
写在前面
这是上周读过的 TransVG 会议论文期刊升级版(RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记)。按照惯例,会议改投期刊要增加 30% 的内容,这次就来看看多了什么吧。
- 论文地址:TransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer
- 代码地址:https://github.com/djiajunustc/TransVG
- 提交于:IEEE TPAMI
- Ps:2023 年每周一篇博文阅读笔记,目前还差 2️⃣ 篇未补,主页 更多干货,欢迎关注吖,期待 5 千粉丝有您的参与呦~
一、Abstract
本文探索基于 Transformer 的网络用于视觉定位。之前方法通常解决的是视觉定位中的核心问题 ,例如采用手工设计的机制进行多模态融合及推理,缺点是方法复杂且在特定数据分布上容易过拟合。于是本文首先提出 TransVG,通过 Transformer 建立起多模态间的关联,并直接通过定位到指代目标来回归出 Box 的坐标。实验表明复杂的融合模块能被堆叠的 Transformer 编码器层替代。然而 TransVG 中的核心 Transformer 融合模块仅仅是针对单模编码器的独立 Transformer,且仅仅是在有限的视觉定位数据上进行随机训练,于是很难优化导致性能下降。基于此本文进一步提出 TransVG++ 来实现两方面的提升:利用 ViT 进行视觉特征的编码达到一个纯粹基于 Transformer 的框架;设计基于条件式的 Vision Transformer,移除外部的融合模块,再次利用统一 ViT 模块的中间层进行视觉语言的融合。实验表明方法达到了 SOTA。
二、引言
首先给出视觉定位的定义,意义。接下来对现有方法进行分类:双阶段,单阶段,如下图所示:
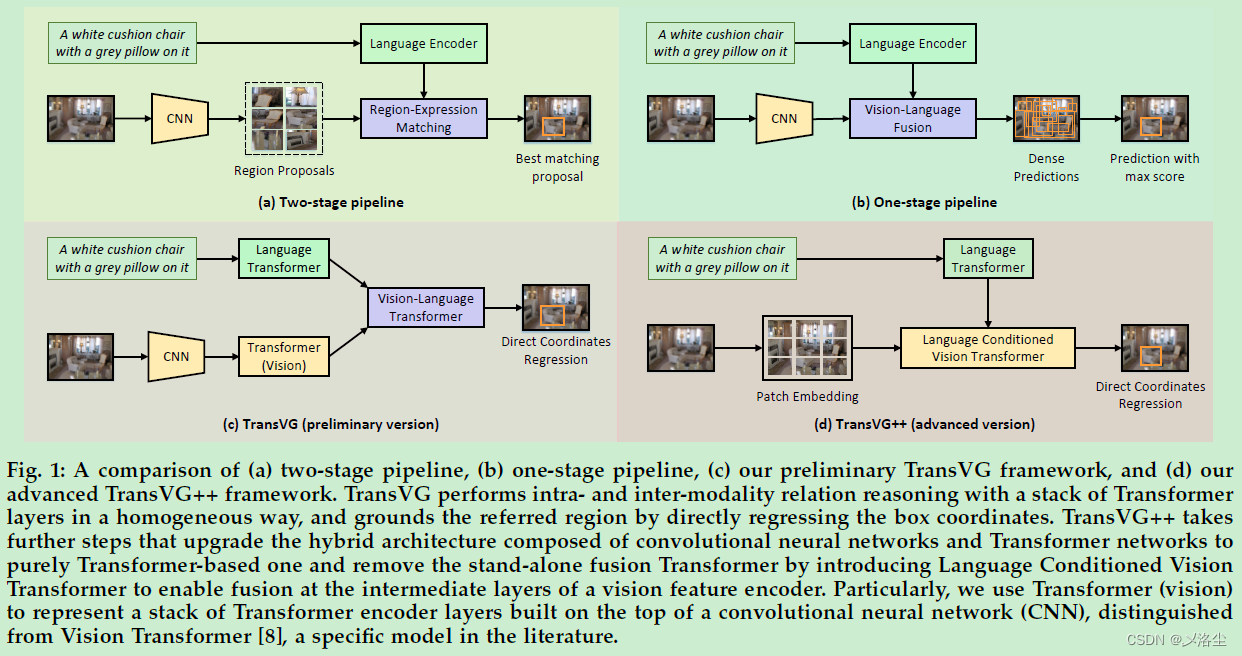
(与会议文章的图 1 相比,增加了图 d。)
两阶段方法:首先产生一组区域 proposal,然后根据区域-表达式的匹配结果选择最合适的 proposal。单阶段方法:在视觉 Backbone 和语言 Backbone 的输出上执行视觉语言融合,然后在预定的 anchor 上进行窗口滑动,从而做出稠密预测,最后输出分数最高的 box。接下来是一些方法的举例。
然而多模态融合机制中某些复杂的融合、匹配模块是建立在预先假定的语言表达式和视觉场景的依赖之上,这就使得模型很容易过拟合特定的场景,从而限制视觉-语言上下文的充分交互。此外,即使视觉定位的目的是去定位指代的目标,大多数方法仍以一种非直接的方式来实现。这些方法通常沿着图文检索和目标的检测的思路来定义语言引导的候选匹配、选择、细化问题,因而这些方法很容易受到先验信息的影响。
本文在融合模块的设计上进行改进,并将预测问题转化为简单的回归问题。首先展示上一个 Transformer 版本 TransVG 来解决视觉定位问题。实验表明结构化的融合模块能够被堆叠的 Transformer 编码器层替代。
TransVG 流程如图 1 c)所示:首先将 RGB 和语言表达式送入两个结构相同的分支:CNN 视觉分支、word embedding 语言 Transformer 分支,来建模视觉和语言内的全局线索。之后,融合提取出的视觉和语言 tokens,送入视觉-语言 Transformer 块执行跨模态的关系推理。最后直接回归出指代目标 box 的 4D 坐标。
由于 TransVG 中的视觉-语言 Transformer 是在有限的视觉定位数据中训练的,因此这一单独的模块很难去优化 。于是本文进一步引入更高级的版本:TransVG++,移除了独立的 Transformer 融合模块,取而代之的是复用的视觉特征编码器。如图 1(d) 所示,设计基于语言条件的视觉 Transformer 模块(Language Conditioned Vision Transformer (LViT))来进行视觉特征编码以视觉-语言推理。通过整合语言表达式的信息到扁平化 ViT 的中间层,LViT 的参数量非常少。此外,提出两种可选的策略,即、语言提示器 language prompter 和语言自适应器 language adapter 将 ViT 中单一模态的视觉编码器层转化到 LViT 中基于语言条件的视觉编码器上。LViT 的模型尺寸和训练成本相较于之前的方法少了很多,实验表明更大的 LViT 模型能够持续的增加 TransVG++ 变体的性能。
数据集:ReferItGame、Flickr30K Entities、RefCOCO、RefCOCO+、RefCOCOg,效果很好。本文贡献总结如下:
- 提出了第一个纯粹基于 Transformer 的框架用于视觉定位,将预测过程视为直接地指代区域 box 的坐标回归;
- 通过 Transformer 展现了一种有效捕捉模态内和模态间上下文异构关系的方法,进一步调查发现,通过整合语言信息到视觉编码器的中间层能够消除独立的融合模块;
- 实验表明方法的有效性。
本文相较于之前的会议版本提升有两个方面:移除了单独的融合模块,使得视觉编码器能够在多模态的中间层复用;将卷积神经网络和 Transformer 网络组成的混合结构升级为纯粹的 Transformer 结构。这是第一个完全基于 Transformer 的网络,实验表明方法性能很好,且效率更高。
三、相关工作
3.1 视觉定位
视觉定位旨在根据自然语言描述定位到输入图像中的指代区域。大多数方法由一个视觉特征编码器,一个语言特征编码器和一个外部的视觉-语言融合模块组成。根据融合方式的差异,当前的方法可以粗略划分为两类:两阶段/单阶段方法。前者匹配语言特征和区域水平的视觉上下文,因此首先需要利用视觉编码器来生成区域 Proposals 的集合。后者在所有空间位置上执行稠密的多模态特征融合,摒弃了区域 proposals 的需要。
两阶段方法
特点:第一阶段生成区域 proposals,第二阶段利用语言表达式选择最匹配的 proposal。而区域 proposals 要么采用基于超像素分组的外部模块生成,要么基于预训练的目标检测器得出。主要重心在于将视觉定位视为文本-区域匹配。训练损失为最大利益化的排序损失或最大化正样本目标-query 对的相似度得分。接下来是一些工作的介绍:DBNet、Similarity Net、MMI、MattNet。最近的研究进一步提升了两阶段方法,更好地建模目标间的联系,强化对应学习,或充分利用语义一致性等。
单阶段方法
单阶段方法剔除了 proposals 的生成,取而代之的是语言上下文和视觉特征在每个特征空间图上的深度融合。在得到语言-视觉特征图之后,以滑动的方式执行 bounding box 的预测。方法举例:FAOA、RCCF、ReSC、LSPN。
视觉编码器的融合
无论在单/双阶段方法中,融合模块基本都差不多:单模态特征编码器后跟着一个外部的多模态特征融合或匹配模块。本文中调查了去除标准融合模块后,复用视觉特征编码器(例如 TransVG++ 中扁平的 ViT)来执行视觉语言融合。提出的新框架有两个优势:移除了显式融合层使得框架更加轻量有效;统一的视觉编码器设计促进了计算机视觉的研究(?说大话了吧,20 年就有框架了)。
3.2 Transformer
Transformer 首次提出用于解决神经机器翻译的问题,相比于 RNN 和 LSTM,注意力机制能够更好地处理长序列问题。这一特性使得 Transformer 在计算机视觉任务和语言任务中广泛使用。
视觉任务中的 Transformer
DETR、ViT、DeiT、Swin Transformer、UViT、ViTDet。TransVG++ 同样在下游任务中探索了扁平化 ViT 的使用。
视觉-语言任务中的 Transformer
主要是预训练模型,image-text matching (ITM)、word-region alignment (WRA)、masked language modeling (MLM)、masked region modeling (MRM)。
Visual-Linguistic Pre-training(VLP)旨在学习图像文本的共同表示,方便泛化到下游任务中。相比之下,本文关注于开发一种基于 Transformer 的视觉定位框架。ViT 在视觉语言任务中表现很强,同时可以作为视觉编码器的 Backbone。但一些方法仍然在建立独立的 blocks 上进行多模态融合。而本文选择性地探索了扁平化 ViT 的更多拓展点,并移除了单独的融合层。
四、方法

如上图所示,之前的 TransVG 版本采用简单堆叠的 Transformer 编码器层来进行视觉语言特征融合,去除了手工设计的机制,例如 proposals 生成等。而现在的版本 TransVG++ 通过移除独立的融合模块,引入 Language Conditioned Vision Transformer (LViT) 基于语言的视觉 Transformer,能够起到视觉特征编码和多模态融合的作用。不同于之前的方法,TransVG 和 TransVG++ 引入了一个可学习的 [REG] token,通过输出的 [REG] token 直接回归出指代目标的 box 位置。
4.1 背景:Transformer
注意力模块
想必大家都很了解 Transformer的结构,这里只列一些公式加深巩固。给定 query token x q x^q xq 和 value token x s x^s xs,应用三个独立的全连接层(FC)分别生成 qeury embedding、key embedding、value embedding f Q f^Q fQ、 f K f^K fK、 f V f^V fV:
f Q = FC ( x q ) , f K = FC ( x s ) , f V = FC ( x s ) f^Q=\text{FC}(x^q),\quad f^K=\text{FC}(x^s),\quad f^V=\text{FC}(x^s) fQ=FC(xq),fK=FC(xs),fV=FC(xs)当 value token 和 query token 一致时,注意力模块即为自注意力模块,反之则为跨模态注意力模块。在得到 qeury、key、value embedding 后,单头注意力层计算如下:
Atn ( f q , f k , f v ) = softmax ( f q f k d k ) ⋅ f v \text{Atn}(f^q,f^k,f^v)=\text{softmax}(\frac{f^qf^k}{\sqrt{d^k}})\cdot f^v Atn(fq,fk,fv)=softmax(dkfqfk)⋅fv d k d^k dk 是 f k f^k fk 的通道维度。 softmax ( ⋅ ) \text{softmax}(\cdot) softmax(⋅) 为 softmax 函数。
编码器层

如上图所示,这里展示两种类型的 Transformer 编码器层,区别在于 layer normalization (LN) 的位置。一个 Transformer 编码器层由多头自注意力层 multihead
self-attention (MHSA) 和前向传播模块 feed forward network (FFN) 组成。FFN 由 MLP + ReLU 激活层组成。当然,还有残差结构。用公式表示后置的归一化 Transformer 编码器层(图 3(a)):
x n ′ = LN ( x n + F MSA ( x n ) ) x n + 1 = LN ( x n ′ + F FFN ( x n ′ ) ) \begin{aligned} x_{n}^{\prime}& =\operatorname{LN}(x_n+\mathcal{F}_{\text{MSA}}(x_n)) \\ x_{n+1}& =\operatorname{LN}(x'_n+\mathcal{F}_{\operatorname{FFN}}(x'_n)) \end{aligned} xn′xn+1=LN(xn+FMSA(xn))=LN(xn′+FFFN(xn′))其中输入为 x n x_n xn。前置的的归一化 Transformer 编码器层计算(图 3(b)):
x n ′ = x n + F MHSA ( L N ( x n ) ) x n + 1 = x n ′ + F F F N ( L N ( x n ′ ) ) \begin{aligned}x_n^{\prime}&=x_n+\mathcal{F}_\text{MHSA}{ ( \mathrm{LN}(x_n))}\\x_{n+1}&=x_n^{\prime}+\mathcal{F}_{\mathrm{FFN}}(\mathrm{LN}(x_n^{\prime}))\end{aligned} xn′xn+1=xn+FMHSA(LN(xn))=xn′+FFFN(LN(xn′))
4.2 之前的版本:TransVG 框架
如图 2(a) 所示,给定输入的图像+语言表达式,将其送入到视觉和语言分支,分别得到它们的 embedding。之后聚合这些 embedding,添加一个可学习的 token [REG] 来构建视觉-语言融合模块的输入。在自注意力机制的作用下,视觉-语言 Transformer 同时从不同的模态中 embed 输入的特征到公共的语义空间上。最后,[REG] token 在预测头中用于预测指代目标的 4D 坐标。
视觉分支
视觉分支由一个卷积 backbone 网络 ResNet 组成,跟着一个堆叠 6 层的后归一化 Transformer 编码器层。每个 Transformer 包含一个多头自注意力层(8 头)、FFN(2 层 FC + ReLU)。FFN 中两层 FC 的输出维度分别是 2048 和 256。
给定单张图像 z 0 ∈ R 3 × H 0 × W 0 z_{0}\in\mathbb{R}^{3\times H_{0}\times W_{0}} z0∈R3×H0×W0 作为输入,利用 Backbone 网络生成 2D 特征图 z ∈ R C × H × W z\in\mathbb{R}^{C\times H\times W} z∈RC×H×W。通常来说, C = 2048 C=2048 C=2048,2D 特征图的宽度和高度是其原始图像尺寸的 1 32 \frac{1}{32} 321,即 H = H 0 32 H=\frac{H_0}{32} H=32H0、 W = W 0 32 W=\frac{W_0}{32} W=32W0。之后利用 1 × 1 1\times1 1×1 卷积层减少 z z z 的通道维度到 C v = 256 C_v=256 Cv=256,得到 z ′ = R C v × H × W z'=\mathbb{R}^{C_v\times H\times W} z′=RCv×H×W。接下来进一步展平 z ′ z' z′ 到 z v ∈ R C v × N v z_v\in\mathbb{R}^{C_v\times N_v} zv∈RCv×Nv,其中 N v = H × W N_v=H\times W Nv=H×W 为输入 tokens 的数量。
和一般的 Transformer 类似,在每层 Transformer 解码器层给 query 和 key 添加正弦位置编码。最后视觉分支的输出为 f v f_v fv,形状与 z v z_v zv 相同。
语言分支
语言分支结构与视觉分支相同,包含一个 token embedding 层和一个语言 Transformer BERT。为了充分利用预训练的语言模型,这一分支的结构遵循标准的 BERTBASE,包含 12 层前置归一化的 Transformer 编码器层,输出维度为 C l = 768 C_l=768 Cl=768。
给定语言表达式作为输入,首先将每个单词的 ID 转化为 one-hot 向量。之后在 token embedding 层,通过查找 tokens 表将每个 one-hot 向量转化为语言 token。在开始和结尾的 token 处增加 [CLS] 和 [SEP] token。不同于视觉分支,语言分支的 tokens 添加的是可学习的位置 embedding。最后将语言 tokens 送入语言 Transformer,得到语言特征 embedding f l ∈ R C l × N l f_l\in\mathbb{R}^{C_l\times N_l} fl∈RCl×Nl,其中 N l N_l Nl 为语言 tokens 的数量。
视觉-语言融合模块
视觉语言融合模块 visual-linguistic fusion module (简写为 V-L 模块),包含两个线性投影层(分别对应视觉和语言分支的输出)和一个堆叠 6 层后归一化的 Transformer 编码器层组成的视觉语言 Transformer。
给定视觉分支的输出 token f v ∈ R 256 × N v f_v\in\mathbb{R}^{256\times N_v} fv∈R256×Nv 和语言分支的输出 token f l ∈ R 768 × N l f_l\in\mathbb{R}^{768\times N_l} fl∈R768×Nl。首先利用线性投影层将其映射到相同的维度上 g v ∈ R C p × N v g_v\in\mathbb{R}^{C_p\times N_v} gv∈RCp×Nv 和 g l ∈ R C p × N l g_l\in\mathbb{R}^{C_p\times N_l} gl∈RCp×Nl,其中 C p = 256 C_p=256 Cp=256。之后,添加一个可学习的 embedding [REG] 到 g v g_v gv 和 g l g_l gl 上。视觉语言 Transformer 的联合 tokens 输入构建如下:
x 0 = [ g r 1 , g v 1 , ⋯ , p v N v ⏟ visual tokens p v , p l 1 , p l 2 , ⋯ , p l N l ⏞ , p r ] x_0=[\underbrace{g_r^1,g_v^1,\cdots,p_v^{N_v}}_{\text{visual tokens} ~p_v},\overbrace{p_l^1,p_l^2,\cdots,p_l^{N_l}},p_r] x0=[visual tokens pv
gr1,gv1,⋯,pvNv,pl1,pl2,⋯,plNl
,pr]其中 p r ∈ R C p × 1 p_r\in\mathbb{R}^{C_p\times 1} pr∈RCp×1 表示 [REG] token,在训练开始时随机初始化, x 0 ∈ R C p × ( 1 + N v + N l ) x_0\in\mathbb{R}^{C_p\times(1+N_v+N_l)} x0∈RCp×(1+Nv+Nl)。同样的,在每层 Transformer 编码器层为输入添加可学习的位置编码。
预测头
利用 V-L 模块的输入状态 [REG] token 作为预测头的输入。为执行 box 坐标回归,在 [REG] token 上添加一个回归块,由一个包含两个 ReLU 激活函数的 MLP 和一个线性输出层组成。预测头输出 4D box 坐标。
4.3 高级版本:TransVG++ 框架
如图 2(b) 所示,TransVG++ 基于 Transformer 的完整框架构建。和 TransVG 的主要不同在于移除了单独的视觉-语言融合模块,取而代之的是新的视觉特征编码器,名为基于语言条件的视觉 Transformer,即 Language Contioned Vision Transformer (LViT)。一方面,LViT 升级了混合的视觉特征编码器,另一方面,LViT使得多模态融合在中间层发生。此外,TransVG++ 的输入不再是整个图像,而是被平等划分的图像 patches。
LViT 在单模态 ViT 的基础上少量修改得来。具体来说,一个标准的 ViT 模型由 12 层前置 Transformer 编码器层组成,核心修改在于将每个组的最后一层视觉编码器层转化为基于语言条件的视觉编码器层,这一操作将参考表达式的语言特征整合进视觉 tokens 内。另外,受 prompt tuning、network adapter 在迁移预训练模型到下游任务中的影响,本文提出两种策略来进行语言特征的整合:语言提示器 language prompter 和语言自适应器 language adapter。

语言提示器 language adapter
图 4(i) 所示为带有语言提示器的基于语言条件的视觉编码器层。首先将语言 tokens 送入前项传播网络 (Feed Forward Network (FFN)) 来生成语言提示 tokens。之后语言提示 tokens 、[REG] token 和 视觉 tokens 拼接来构成多头自注意力模块 multi-head self-attention (MHSA) 的输入。MHSA 模块的输出 tokens 被划分为两组:一组用于视觉 tokens 和 [REG] token,另外一组用于提示 tokens。在下一层时,提示 tokens 被扔掉,而另外一组 tokens 输入到下一个 FFN 来获得更下一层的输入。用于产生提示 tokens 参数的 FFN 是随机初始化的,而其他部分的参数来源于预训练 ViT Backbone 网络中原始的视觉编码器层。
语言自适应器 language prompter
图 4(ii) 所示为带有语言自适应器的基于语言条件的视觉编码器层。首先在原始视觉编码器层的 MHSA 模块和 FFN 模块间,增加额外的多头跨模态注意力模块 multi-head crossattention (MHCA),从而将语言表达式信息注入。MHCA 模块中的 query embedding 是 MHSA 模块的输出,而 key、value embedding 都是来源于语言 tokens。于是 MHCA 模块的输出,即语言自适应 tokens 是语言特征与视觉 token 的自适应聚合。之后语言自适应 tokens 被逐元素添加到视觉 tokens 上用于视觉-语言特征融合。与语言提示器类似,MHCA 的参数为随机初始化,其他部分的参数则根据预训练的 ViT Backbone 相应权重进行初始化。
要么通过语言提示器或语言自适应器,视觉编码器层能够被转化为基于语言条件的视觉编码器层,因此能够复用从语言 tokens 中吸收文本表达式的信息。这两种策略的参数和计算成本相对于整个模型的性能提升来说可以不计。
4.4 训练目标
当尝试预测大的 box 时,广泛使用的 smooth L1 损失值往往较大,反之较小。于是本文通过缩放图像来归一化 GT 坐标,并利用 GIoU 作为损失函数,这并不会被尺寸缩放所影响。
设预测的 box 为 b = ( x , y , w , h ) b=(x,y,w,h) b=(x,y,w,h),归一化后的 GT box 为 b ^ = ( x ^ , y ^ , w ^ , h ^ ) \hat b =(\hat{x},\hat{y},\hat{w},\hat{h}) b^=(x^,y^,w^,h^),TransVG 的训练目标为:
L = L smooth-l1 ( b , b ^ ) + L giou ( b , b ^ ) \mathcal{L}=\mathcal{L}_{\text{smooth-l1}}(b,\hat{b})+\mathcal{L}_{\text{giou}}(b,\hat{b}) L=Lsmooth-l1(b,b^)+Lgiou(b,b^)其中 L smooth-l1 ( ⋅ ) \mathcal{L}_{\text{smooth-l1}}(\cdot) Lsmooth-l1(⋅) 和 L giou ( ⋅ ) \mathcal{L}_{\text{giou}}(\cdot) Lgiou(⋅) 分别为 smooth L1 损失和 GIoU 损失。
五、实验
5.1 数据集和评估指标
数据集:ReferItGame、Flickr30K Entities、RefCOCO/ RefCOCO+/ RefCOCOg。
评估指标:当预测区域和 GT 的 Jaccard 重叠比大于 0.5 时,认为是一个正确预测,于是计算正确预测的准确度。
5.2 实验步骤
输入
输入图像尺寸: 640 × 640 640\times640 640×640。保持图像原始比例不变,长边为 640 640 640,短边用 RGB 通道的平均值填充到 640 640 640。对于 RefCOCOg 数据集,表达式的最大长度设为 40 40 40,其他数据集为 20 20 20。当输入语言 query 的长度大于最大长度时,除去多余的,留下两个位置给 [CLS] 和 [SEP],否则在 [SEP] 后用空的 token 填充到最大长度。
网络结构
在之前的 TransVG 版本中,采用 ResNet-50 或 ResNet-101 作为卷积 Backbone 网络,其输出为输入图像的 32 分之 1。其中 Transformer 编码器层采用后归一化结构,embedding 的维度为 256,多头注意力为 8,FFN 的隐藏维度为 2048。
在 TransVG++ 版本中,patch embedding 层将 640 × 640 640\times640 640×640 的图像划分为 16 × 16 16\times16 16×16 尺寸的 40x40 个 patches 块。这些 patches 块之后展平为向量再送入到一个全连接层,产生最初的视觉 tokens 状态。和其他方法类似,添加可学习的位置 embedding 到每个视觉 token 上。在标准 ViT 模型中,针对图像分类任务设计的位置 embedding 的分辨率为 14 × 14 14\times14 14×14。因为输入图像的尺寸仅有 224 × 224 224\times224 224×224,为了确保满足 40 个 patches 的要求,于是将 ViT 中的图像尺寸用三次插值操作调整其图像大小。
实验采用三种 ViT 的变体:ViT-tiny、ViT-small、Vi-Tbase,都用于视觉特征编码,LViT 也跟着做相应的变化。同样的语言自适应器和语言提示器的配置也跟着 ViT 而变:ViT-tiny/small/base:embedding 维度为 192/384/768,多头注意力机制中头的数量为 3/6/12,FFN 的隐藏层维度为 768/1536/3072。这一段作者估计复制粘贴没弄好,第三个还是 ViT-small。另外,凑字数的嫌疑,三个一样的东西写了三遍,烦不烦?
不管 ViT 模型如何变化,回归头的 MLP 维度始终为 256。
训练和推理细节
端到端训练,AdamW 优化器,Batch_size 32。在 TransVG 中,融合模块和预测头的初始学习率 1 0 − 4 10^{-4} 10−4,视觉和语言分支的初始学习率 1 0 − 5 10^{-5} 10−5,权重衰减为 1 0 − 4 10^{-4} 10−4。在RefCOCO、RefCOCOg 和 ReferItGame 数据集上,训练 90 epochs。在 60 个 epochs 后,学习率下降 10 个百分点。而在 Flickr30K Entities 数据集上,训练 60 个 epochs。在 40 个 epochs 后,学习率下降 10 个百分点。在 RefCOCO+ 上,训练 180 个 epochs。在 120 个 epochs 后,学习率下降 10 个百分点.
对于 TransVG++,语言分支采用预训练的 BERTBASE 模型权重进行初始化,学习率为 1 0 − 5 10^{-5} 10−5,其他参数学习率为 1 0 − 4 10^{-4} 10−4。TransVG++ 训练的 epochs 数量为 60,在 45 个 epochs 后,学习率下降 10 个百分点。视觉分支的参数来源于预训练的 MSCOCO 数据集。对于 TransVG,视觉分支初始化来源于 DETR, 而在 TransVG++ 使用 Mask R-CNN 的权重。
由于两种方法都直接输出 box 的坐标,因此推理过程无需额外操作。
这一段训练细节真是写的稀烂,不仅重复啰嗦,而且有错误粘贴,造成阅读混乱。
5.3 消融实验
5.3.1 TransVG 上的消融实验
ResNet-50 作为视觉分支的 Backbone 网络,所有比较的模型均在 ReferItGame 上训练 90 个 epochs。
[REG] Token 初始状态的设计

每个分支上 Transformer 的设计

5.3.2 TransVG++ 上的消融实验
语言分支保持不变,重点关注 LViT 的分析。所有模型均采用 ViT-tiny 作为 LViT 的 Backbone 网络,训练 60 个 epochs。
融合策略的设计

基于语言条件的视觉编码器层的位置

基于语言条件的视觉编码器层的数量

5.3.3 从 TransVG 到 TransVG++ 的提升

5.4 主要的结果和比较
5.4.1 RefCOCO/RefCOCO+/RefCOCOg
与两阶段/单阶段方法的比较

与基于 Transformer 的方法比较
同上表 7。
5.4.2 ReferItGame

5.4.3 Flickr30K Entities
同上表 8。
5.5 模型尺寸和计算成本的讨论

5.6 定性结果

六、结论
本文展示了之前版本的基于 Transformer 的工作 TransVG 及其高级版本 TransVG++ 来解决视觉定位问题。TransVG 采用简单堆叠的 Transformer 编码器来执行多模态融合和视觉定位的推理任务。TransVG++ 进一步升级到纯粹的 Transformer 结构,移除了单独的融合模块,将语言指代信息整合进 ViT Backbone。实验表明 TransVG++ 很有效。
写在后面
看了下这篇期刊论文 github 代码仓库,TransVG++ 的代码还没更新,仍是 2 年前的 TransVG 版本。也有不少人提了 issue 催促代码,作者说是等审稿完成。那估计看这个状态可能是凉了。我感觉这篇文章一些小细节没注意到,尤其是实验细节那部分,不像是个严谨的 TPAMI 论文级别呀。往后学习的同学注意下写作细节。