链接:https://arxiv.org/abs/1406.4729
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
摘要:

SPP可以用于:
1.大幅提高各种cnn的性能:
现有网络对输入图片的size要求一定,这种“人工设定”可能对accuracy造成影响。本文提出的SPP-net则是“input size/scale free”的,输出的是固定长度的representation。通过对一些经典网络进行改造可以实现精度的显著提升。
2.在对象检测中显著提速:
R-CNN需要在一幅图上的子区域上反复应用nn,而作者首先在全图中用CNN扫一次,然后提取特征并放入SPP-net,实现数量级级别的提速。
由于CNN中的卷积层的kernel在生成feature map的时候对于图片size无要求,另一方面根据全连接层的定义,输入size须一定,所以CNN的input的fixed size约束的根本来源是仅仅是全连接层。作者在最后一层卷积层之后、全连接层之前增加spp层,用于把feature map池化并生成全连接层所需的size,在避免warp和crop的同时实现信息整合。则网络结构的变化如下图所示:
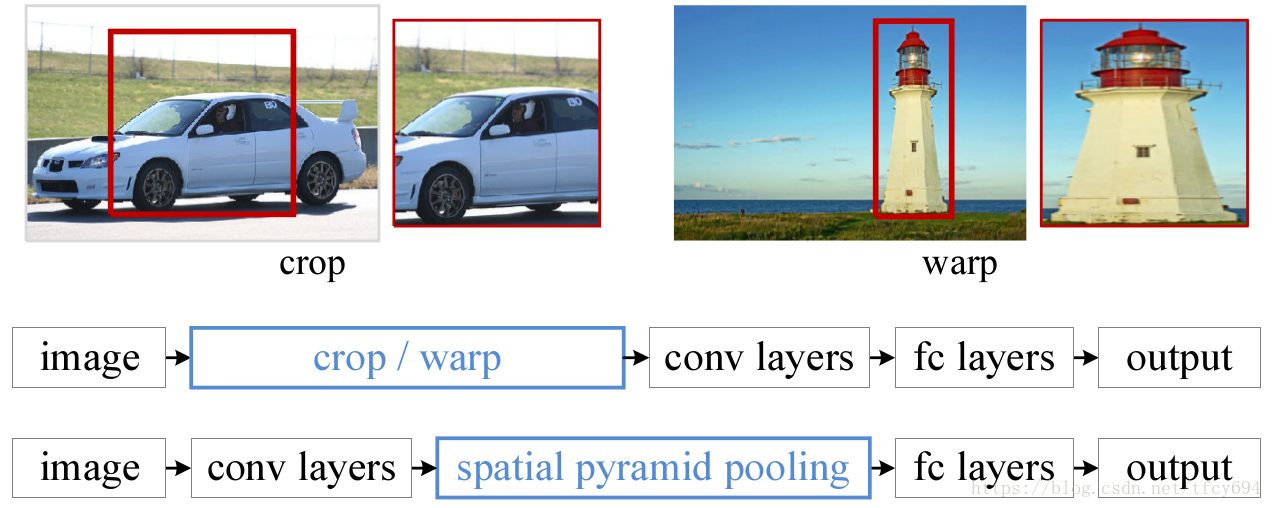
文章从三个方面进行了论述:
1。加入了SPP的DNN
2。SPP-net与图像分类
3。SPP-net与对象检测
1、SPP-net的结构
如图:
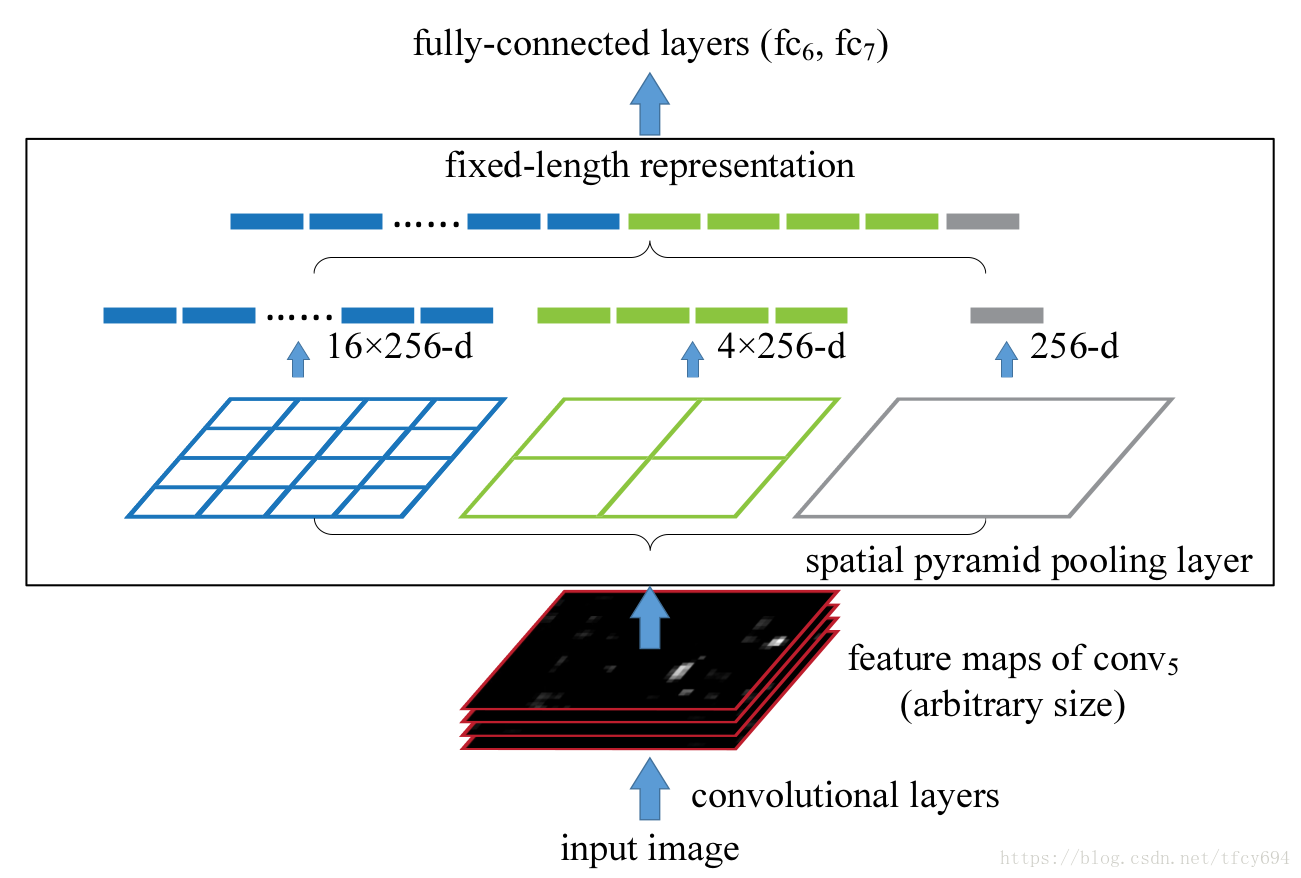
SPP层位于卷积池化层(
)和全连接层(
)之间。假设
通过256个filter生成了256维的feature map(由于每个image的size不定,所以不同image经过
输出的256个feature map的size也有不同)。把这些feature map分别最大池化成
、
、
的size并组合,得到
的向量,输入
。
这个结构很简明,理论上也能通过传统的后向传播进行训练。当然了,由于图片的size不同,为了便于GPU的运行,作者也进行了一些训练方法的改进。
2、SPP-net与图像分类
实验的baseline包括ZF-5等一些网络,通过使用SPP,其精度均取得了较大的提升。另外,增加SPP的level(上节的例子中有3个level)、增加input的size种类也可以提高accuracy。
3、SPP-net与对象检测
待续