背景
用ConvNet方法解决图像分类、检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息。论文作者发明了SPP pooling(空间金字塔池化)层,让网络可以接受任意size的输入。
方法
首先思考一个问题,为什么ConvNet需要一个固定size的图片作为输入,我们知道,Conv层只需要channel固定(彩色图片3,灰度图1),但可以接受任意w*h的输入,当然输出的w*h也会跟着变化;然而,后面的FC层却需要固定长度的vector作为输入,图片size变化->conv层输出的size变化->FC层输入的vector长度变化,这就产生了错误。
怎么解决这个问题呢?作者给出的方法是在最后一层Conv层后面加上一个SPP pooling层,SPP pooling层可以将接收到的不同size的输入转换成为固定的输出,保证FC层的输入长度固定。
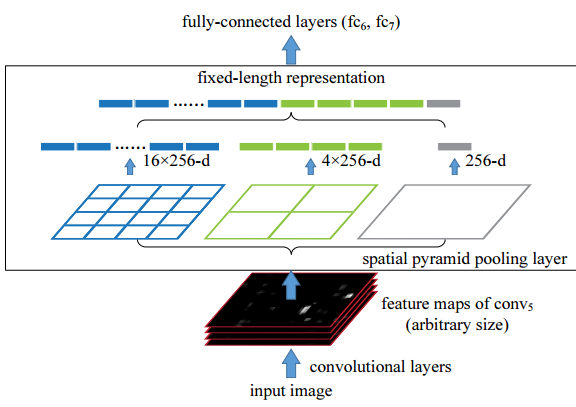
如图,SPP pooling层的原理很简单,例子如下:给定一个w*h的特征图,把其分别分成4*4、2*2、1*1的bin,在每个bin上面作pooling操作(文中使用的是max pooling),最后能得到16*256-d(256-d是最后一个conv层的输出通道数),4*256-d、1*256-d的feature vector,最后连接在一起,得到的就是21*256-d的feature vector。
可以看到,不管一开始的w和h取值多少,最后都能得到固定长度的feature vector作为FC层的输入,这样,ConvNet就能接受不同size的图片作为输入了。
总结
论文作者通过在FC层前面加上一个SPP pooling层,有效解决了ConvNet必须接受固定size的图片。