目录
5.2 Compatibility with Existing Methods
原文连接:https://arxiv.org/pdf/2007.11824.pdf
代码连接:GitHub - megvii-model/FunnelAct
Abstract:我们提出了一种用于图像识别任务的概念上简单但有效的漏斗激活,称为漏斗激活(FReLU),通过添加可忽略的空间条件开销,将ReLU和PReLU扩展到2D激活。ReLU和PReLU的形式分别为y=max(x,0)和y=max(x,px),而FReLU的格式为y=max(x,T(x)),其中T(·)是2D空间条件。此外,空间条件以简单的方式实现了像素级建模能力,通过规则卷积捕获复杂的视觉布局。我们在ImageNet、COCO检测和语义分割任务上进行了实验,显示了FReLU在视觉识别任务中的巨大改进和鲁棒性。代码位于https://github.com/megvii-model/FunnelAct.
1 Introduction
卷积神经网络(CNN)在许多视觉识别任务中取得了最先进的性能,如图像分类、对象检测和语义分割。正如在CNN框架中推广的,一种主要的层是卷积层,另一种是非线性激活层。
首先,在卷积层中,自适应地捕获空间相关性是一项挑战,已经提出了在更复杂和有效的卷积中的许多进展,以自适应地掌握图像中的局部上下文[7,18]。这些进展取得了巨大的成功,尤其是在密集的预测任务(例如,语义分割、对象检测)上。在更复杂的卷积技术的进步及其效率较低的实现方式的推动下,出现了一个问题:规则卷积能否达到类似的精度,以掌握具有挑战性的复杂图像?
第二,通常在线性捕获卷积层中的空间相关性之后,激活层充当标量非线性变换。已经提出了许多有见地的激活[31,14,5,25],但提高视觉任务的性能具有挑战性,因此目前最广泛使用的激活仍然是整流线性单元(ReLU)[32]。由卷积层和激活层的不同作用,另一个问题出现了:我们是否可以专门为视觉任务设计激活?
为了回答上面提出的两个问题,我们表明,简单但有效的视觉激活,加上规则卷积,也可以在密集和稀疏预测上实现显著改进(例如,图像分类,见图1)。为了实现这些结果,我们将激活中的空间不敏感性确定为阻碍视觉任务实现显著改善的主要障碍,并提出了一种新的视觉激活方法,以消除这种障碍。在这项工作中,我们提出了一种简单但有效的视觉激活,将ReLU和PReLU扩展到2D视觉激活。

现代视觉任务的激活解决了空间不敏感问题。正如ReLU激活中推广的那样,使用max(·)函数执行非线性,条件是手动设计的零,因此采用标量形式:y=max(x,0)。ReLU激活在许多具有挑战性的任务中始终达到最高精度。通过一系列进展[31,14,5,25],ReLU的许多变体以各种方式修改了条件,并相对提高了准确性。然而,对于视觉任务来说,进一步的改进具有挑战性。
我们的方法称为漏斗激活(FReLU),通过添加空间条件(见图2)扩展了ReLU/PReLU的精神,该空间条件易于实现,只增加了可忽略的计算开销。形式上,我们所提出的方法的形式是y=max(x,T(x)),其中T(x)表示简单有效的空间上下文特征提取器。通过在激活中使用空间条件,它简单地将ReLU和PReLU扩展为具有像素级建模能力的视觉参数化ReLU。

我们提出的视觉激活方法是一种有效但更有效的替代方法。为了证明所提出的视觉激活的有效性,我们在分类网络中替换了正常的ReLU,并使用预先训练的主干来显示其在其他两个基本视觉任务上的通用性:对象检测和语义分割。结果表明,FReLU不仅提高了单个任务的性能,而且可以很好地转移到其他视觉任务。
2 Related Work
Scalar activations:标量激活是具有单输入和单输出的激活,形式为y=f(x)。整流线性单元(ReLU)是各种任务中使用最广泛的标量激活,其形式为y=max(x,0)。它对于各种任务和数据集简单有效。为了修改否定部分,已经提出了许多变体,如Leaky ReLU、PReLU、ELU。它们保持正部分身份,并使负部分自适应地依赖于样本。
其他标量方法(如S形非线性)的形式为,Tanh非线性的形式为Tanh(x)=2σ(2x)−1.这些激活在深度神经网络中没有广泛使用,主要是因为它们饱和并杀死梯度,还涉及昂贵的操作(指数等)。
随后出现了许多进展[25,39,1,16,35,10,46],最近的搜索技术通过结合一组一元函数和二元函数,促成了一种新的搜索标量激活,称为Swish。形式为y=x∗ Sigmoid(x)在某些结构和数据集上优于其他标量激活,许多搜索结果显示出巨大的潜力。
Contextual conditional activations:除了仅依赖于神经元自身的标量激活外,条件激活是一种多对一的功能,它激活了受上下文信息制约的神经元。代表性的方法是Maxout[12],它将层扩展到多分支并选择最大值。大多数激活在权重和数据之间的线性点积上应用非线性,即:。Maxout计算
,并将ReLU和Leaky ReLU推广到同一框架中。随着辍学,Maxout网络显示出改善。然而,它增加了太多的复杂性,参数和乘法加法的数量成倍增加。
上下文选通方法使用上下文信息来提高效率,尤其是基于RNN的方法,因为特征维度相对较小。也有基于CNN的方法[34],因为2D特征尺寸具有较大的维度,所以在特征缩减之后使用该方法。
上下文条件激活通常是通道方式。然而,在本文中,我们发现空间相关性在非线性激活函数中也很重要。我们使用轻量级的CNN技术深度可分离卷积来帮助减少额外的复杂性。
Spatial dependency modeling:学习更好的空间相关性是一项挑战,一些方法使用不同形状的卷积核[41,42,40]来聚合不同范围的空间相关性。然而,它需要一个降低效率的多分支。卷积核(如萎缩卷积[18]和扩张卷积[47])的进展也通过增加感受野来提高性能。
另一类方法自适应地学习空间相关性,如STN[22]、主动卷积[24]、可变形卷积[7]。这些方法自适应地使用空间变换来细化短距离相关性,尤其是对于密集视觉任务(例如,对象检测、语义分割)。我们的简单FReLU甚至在没有复杂卷积的情况下优于它们。
此外,非本地网络提供了捕获远程依赖性的方法来解决这个问题。GCNet[3]提供了一种空间注意力机制,以更好地使用空间全局上下文。远程建模方法实现了更好的性能,但仍需要在原始网络结构中添加块,这会降低效率。我们的方法在非线性激活中解决了这一问题,更好、更有效地解决了这个问题。
Receptive field:感受野的区域和大小在视觉识别任务中至关重要[50,33]。关于有效感受野的研究[29,11]发现,不同像素的贡献不相等,中心像素的影响更大。因此,已经提出了许多方法来实现自适应感受野[7,51,49]。这些方法通过在架构中引入额外的分支(例如开发更复杂的卷积或利用注意力机制)来实现自适应接收场并提高性能。我们的方法也实现了相同的目标,但通过将感受野引入非线性激活,以更简单和有效的方式。通过使用更自适应的感受野,我们可以近似常见复杂形状的布局,从而通过使用有效的规则卷积获得比复杂卷积更好的结果。
3 Funnel Activation
FReLU是专门为视觉任务设计的,概念上很简单:ReLU的条件是手动设计的零,PReLU的条件是参数px,为此我们将其修改为二维漏斗状条件,具体取决于空间上下文。视觉条件有助于提取对象的精细空间布局。接下来,我们将介绍FReLU的关键元素,包括漏斗条件和逐像素建模能力,这是ReLU及其变体中缺少的主要部分。
ReLU:我们首先简要回顾ReLU激活。形式为max(x,0)的ReLU使用max(·)作为非线性,并使用手动设计的零作为条件。非线性变换作为线性变换的补充,例如卷积和完全连接的层。
PReLU:作为ReLU的高级变体,PReLU具有原始形式max(x,0)+p·min(x,1),其中p是一个可学习的参数,并初始化为0.25。然而,在大多数情况下,p<1,在此假设下,我们将其重写为:max(x、px),(p<1)。由于p是信道方向参数,因此无论偏置项如何,它都可以解释为1x1深度方向卷积。
Funnel condition:FReLU采用与简单非线性函数相同的max(·)。对于条件部分,FReLU将其扩展为依赖于每个像素的空间上下文的2D条件(见图2)。这与最新的方法不同,这些方法的条件取决于像素本身(例如[31,14])或信道上下文(例如[12])。我们的方法遵循ReLU的精神,使用max(·)来获得x和条件之间的最大值。

形式上,我们将漏斗条件定义为T(x)。为了实现空间条件,我们使用参数池窗口来创建空间依赖关系,具体来说,我们定义了激活函数:
这里,是在2-D空间位置(i,j)处的第c通道上的非线性激活f(·)的输入像素;函数T(·)表示漏斗条件,
表示以
为中心的
参数池窗口,
表示在同一信道中共享的该窗口上的系数,(·)代表点乘。
Pixel-wise modeling capacity:我们对漏斗条件的定义允许网络在每个像素的非线性激活中生成空间条件。网络进行非线性变换并同时创建空间依赖关系。这与在卷积层中创建空间依赖性并单独进行非线性变换的常见实践不同。在这种情况下,激活并不明确取决于空间条件;在我们的例子中,在漏斗条件下,它们确实如此。
因此,逐像素条件使网络具有逐像素建模能力,函数max(·)为每个像素提供了在查看空间上下文与否之间的选择。形式上,考虑具有n个FReLU层的网络{F1,F2,…,Fn},每个FReLU图层Fi具有k×k参数窗口。为了简洁起见,我们只分析FReLU层,而不考虑卷积层。因为在1×1和k×k之间的最大选择,F1之后的每个像素都有一个激活文件集{1,1+r}(r=k− 1). 在Fn层之后,集合变为{1,1+r,1+2r,…,1+nr},这为每个像素提供了更多的选择,如果n足够大,可以近似任何布局。通过激活场的许多不同大小,正方形的不同大小可以近似于斜线和圆弧的形状(见图3)。我们知道,图像中对象的布局通常不是水平或垂直的,它们通常是斜线或圆弧的形状,因此提取对象的空间结构可以通过空间条件提供的逐像素建模能力自然解决。我们通过实验表明,它在复杂任务中更好地捕捉不规则和详细的对象布局(见图4)。


3.1 Implementation Details
我们提出的改变很简单:我们避免了手动设计的条件,我们使用一个简单有效的空间二维条件来代替它。视觉激活导致显著改善,如图1所示。我们首先在ImageNet数据集上改变分类任务中的ReLU激活。我们使用ResNet作为分类网络,并使用预训练的网络作为其他任务的主干:目标检测和语义分割。
同一通道内的所有区域具有相同的系数
,因此只需增加少量参数即可。用
表示的区域是一个滑动窗口,大小默认设置为3 × 3的正方形,我们将二维填充设置为1,在这种情况下,
Parameter initialization:我们使用高斯初始化来初始化超参数。因此,我们得到了接近于零的条件值,这并没有太大改变原点网络的性质。我们还考察了没有参数(例如最大池化、平均池化等)的情形,这些情形并没有表现出改善。这说明了附加参数的重要性。
Parameter computation:假设有一个的卷积,输入特征大小为C × H × W输入,输出大小为
,则需要计算的参数个数为
,FLOPs (浮点运算)为
。为此我们增加了窗口为
的漏斗条件,附加的参数个数为
,附加的FLOPs个数为
。假设
,为了简化
。
因此,采用后参数的原始复杂度为 FReLU,变为
;而FLOPs的原始复杂度为
,采用视觉激活后变为
。通常
远大于
和
,因此额外的复杂度可以忽略不计。实际上附加部分(详见表1)可以忽略不计。此外,漏斗条件是一个
的滑动窗口,我们使用高度优化的深度可分离卷积算子和BN [ 21 ]层来实现。
4 Experiments
4.1 Image Classification
为了评估视觉激活的有效性,首先,我们在ImageNet 2012分类数据集[ 9、37]上进行实验,该数据集包含128万张训练图像和50K张验证图像。
通过简单地改变原始CNN结构中的ReLU,我们的视觉激活很容易在网络结构上采用。首先评估不同大小Res Net上的激活情况[ 15 ]。对于网络结构,我们采用了原有的实现方式。特别是在浅层,空间依赖性非常重要,对于较小的224 × 224输入尺寸,我们替换了除最后一个阶段外的所有阶段的ReLU,该阶段具有较小的7 × 7特征图尺寸。对于训练设置,我们使用256,600k次迭代的批处理大小,具有线性衰减调度的学习率为0.1,权重衰减为1e - 4,dropout [ 17 ]率为0.1。我们给出了验证集上的Top - 1错误率。为了公平比较,我们在相同的代码库上运行所有的结果。
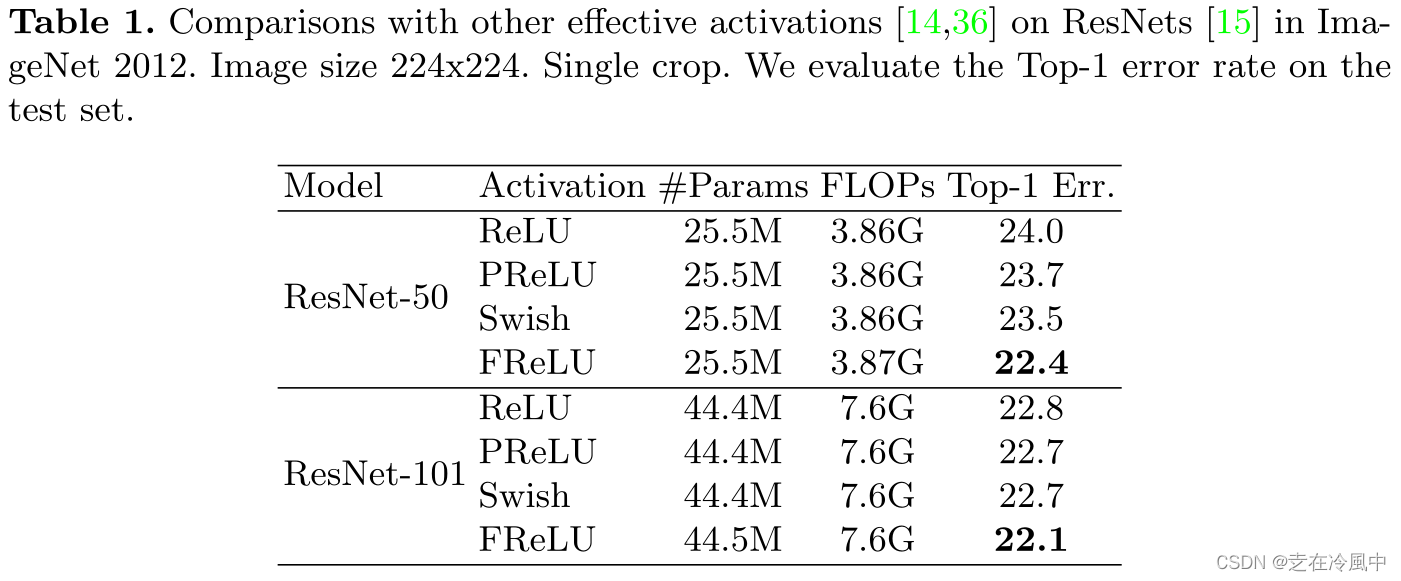
Comparisons with scalar activations:我们对不同深度( e.g. ResNet - 50、ResNet - 101)的深度残差网络[ 15 ]进行了全面的比较。我们取 ReLU作为基线并取其变体之一PReLU进行比较。此外,我们将我们的视觉激活与通过NAS [ 52、53]技术搜索到的激活Swish [ 36 ]进行了比较。与许多标量激活相比,Swish已经显示出它对各种模型结构的积极影响。
表1比较结果显示,我们的视觉激活仍然优于所有它们,而额外的复杂度可以忽略不计。我们的视觉激活在ResNet - 50和ResNet - 101上分别提高了1.6 %和0.7 %的top - 1准确率。值得注意的是,随着模型大小和模型深度的增加,其他标量激活表现出有限的提升,而视觉激活仍然有显著的提升。例如,Swish和PReLU提高了0.1 % on的准确率而视觉激活在ResNet - 101上仍有显著提高,提高了0.7 %。
Comparison on light-weight CNNs:除了深度卷积神经网络,我们还将视觉激活与最近的轻量级卷积神经网络如MobileNets [ 19 ]和ShuffleNets [ 30 ]上的其他有效激活进行了比较。我们使用与[ 30 ]相同的训练设置。模型尺寸极小,我们采用1 × 3 + 3 × 1的窗口尺寸来减少额外的参数。此外,对于MobileNet,我们将宽度乘子从0.75微调到0.73以保持模型复杂度。表2展示了在ImageNet数据集上的对比结果。我们的视觉激活也提高了轻量级CNN的准确性。ShuffleNetV2 0.5 ×只需增加少量额外的FLOPs就可以提高2.5 %的top - 1准确率。

4.2 Object Detection
为了评估视觉激活在不同任务上的泛化性能,我们在COCO数据集上进行了目标检测实验。COCO数据集有80个对象类别。我们使用trainval35k集合进行训练,使用minival集合进行测试。
我们在Retina Net [ 27 ]检测器上展示了结果。为了公平比较,我们用相同的设置在相同的代码库中训练所有的模型。我们使用批次大小为2,权重衰减为1e - 4,动量为0.9。我们使用3个尺度和3个长宽比的锚点,并使用600像素的训练和测试图像尺度。对于主干,我们使用4.1节中预训练的模型作为特征提取器,并比较不同激活之间的通用性。
表3显示了不同激活之间的比较。对比发现,我们的视觉激活比ReLU主干增加了1.4 % m AP,比Swish主干增加了0.8 % m AP。值得一提的是,在所有小、中、大物体上,FRe LU都显著优于其他物体。

我们还展示了在轻量级CNN上的比较。作为ResNet - 50的对比,我们使用预先训练好的ShuffleNetV2骨架,采用不同的激活方式。我们主要比较了FReLU与ReLU以及有效激活Swish [ 36 ]。从表3可以看出,视觉激活的效果也远远优于 ReLU和Swish主干网分别提高了1.1 %和0.8 %的m AP。而且,它增加了所有大小对象的性能。
4.3 Semantic Segmentation
我们进一步展示了在市景数据集上的语义分割结果[ 6 ]。 该数据集是一个语义城市场景理解数据集,包含19个类别。它有5000张精细标注的图像,2,975张用于训练,500张用于验证,1525张用于测试。
我们使用PSPNet [ 48 ]作为分割框架,对于训练设置我们使用poly学习率策略[ 4 ],其中基为0.01,幂为0.9,我们使用权重衰减为1e - 4,并且在每个GPU上使用批大小为2的8个GPU。
为了评估4.1节中先前预训练模型的通用性,我们使用不同激活的预训练Res Net-50 [ 15 ]主干模型,将FRe LU分别与Swish和Re LU进行比较。
在表4中,我们给出了与标量激活的比较。从结果中,我们观察到我们的视觉激活优于ReLU和搜索 Swish分别为1.7 %和1.4 %。此外,我们的视觉激活在大物体和小物体上都有显著的改善,特别是在"火车"、"公交车"、"墙"等类别上。

为了更好地可视化改进的性能,图4展示了在测试数据集上的预测结果。表明通过只改变主链激活能,结果有明显的改善。由于像素级的建模能力可以同时处理全局和细节区域(见图3),所以大目标和小目标的边界都得到了很好的分割。我们注意到,现代的识别框架都是通过ReLU激活进行精心设计的,因此视觉激活对于进一步改善结果仍然具有很大的潜力,这超出了本文工作的重点。
5 Discussion
前面的部分展示了与其他有效激活相比的最佳性能。为了进一步研究我们的视觉激活,我们进行了导管消融研究。我们首先讨论视觉激活的性质,然后讨论与现有方法的兼容性。
5.1 Properties
我们的漏斗激活主要有两个成分:1 )漏斗条件,2 ) max ( · )非线性。分别考察各成分的影响。
Ablation on the spatial condition:首先,我们比较了空间条件的不同方式。除了我们使用的参数池化方式外,为了考察附加参数的重要性,我们比较了没有附加参数的其他池化方式,它们是最大池化和平均池化。我们简单地将参数池化替换为另外两种非参数方式,并在ImageNet数据集上进行评估。
表5 ( A、B、C)显示了参数池化的重要性。在没有额外参数的情况下,结果的top - 1精度下降超过2 %,甚至比不使用空间条件的基线表现更差。表6给出了空间条件后不同归一化的比较。
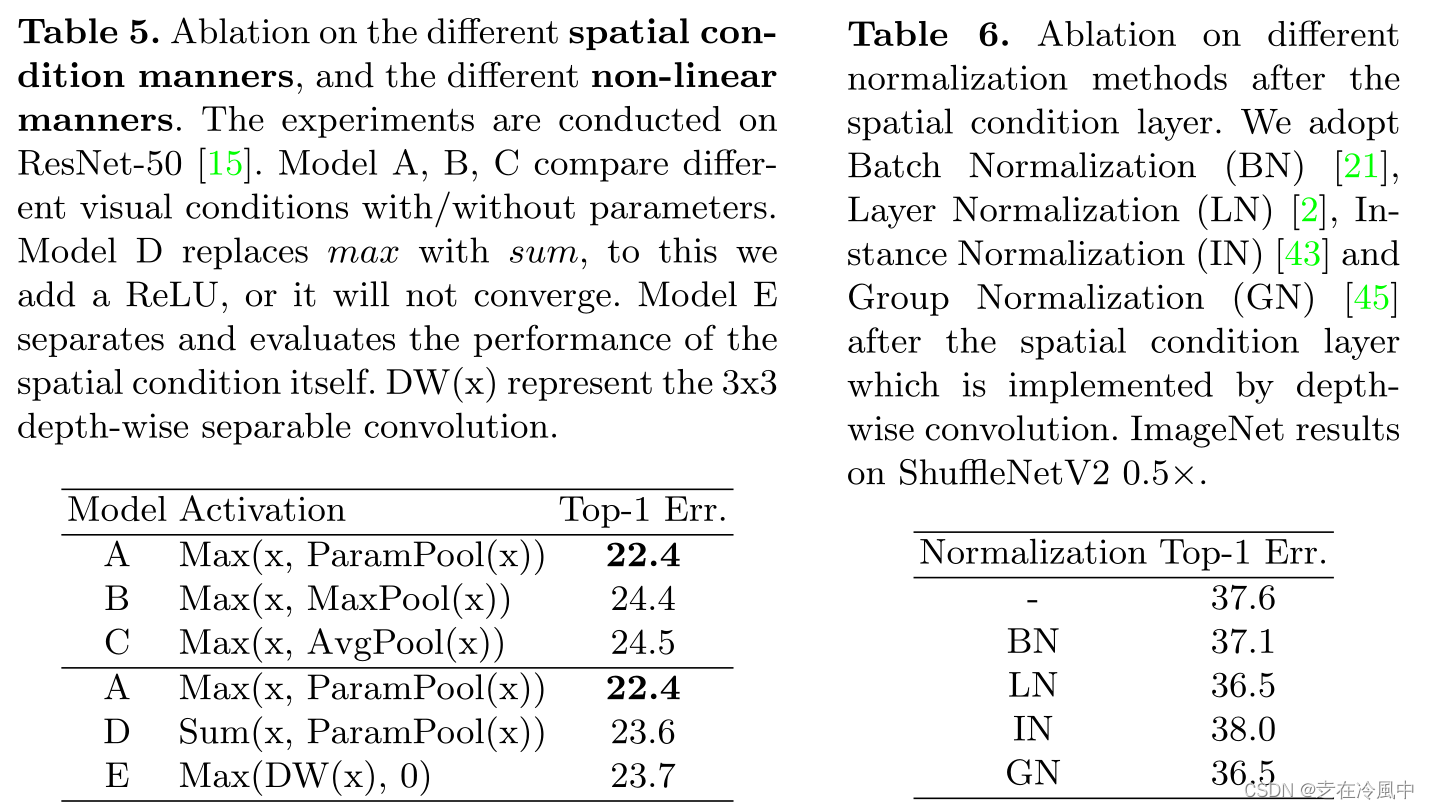
Ablation on the non-linearity:其次,我们还比较了非线性的使用。在我们的方法中,我们使用max ( · )函数来执行非线性,同时捕获视觉依赖。相比之下,我们与分别捕获视觉依赖和非线性的方式进行了比较。
对于空间上下文的捕获,我们采用了两种方式:1 )如前所述使用参数池化,然后与原始特征线性相加,2 )简单地增加一个深度可分离卷积层。对于非线性变换,我们采用ReLU函数。表5 ( A、D、E)报告了结果。与基线相比,空间上下文本身提高了约0.3 %的精度,但作为我们方法中的非线性条件,它进一步增加了1 %以上。 因此,将空间相关性和非线性分开处理并没有像同时处理它们那样有理想的效果。
Ablation on the window size:在参数化池化窗口中,窗口的大小决定了每个像素看起来的区域大小。我们在漏斗条件下简单地改变窗口大小,比较了{ 1 × 1,3 × 3,5 × 5,7 × 7 }不同大小的情况。1 × 1的情况不具备空间条件,由于参数值小于1,因此是PReLU的情况。表7为对比结果。我们得出3 × 3是最佳选择。较大的窗口大小也显示出好处,但没有超过3 × 3。
进一步,我们考虑使用不规则窗口代替正方形的情况。我们使用大小为1 × 3和3 × 1的多个窗口,我们考虑使用它们的和与最大值作为条件。表7 { B,E,F }为比较。结果表明,不规则窗口尺寸也具有最优的性能,因为它们具有更灵活的像素建模能力(图3 )。

5.2 Compatibility with Existing Methods
为了将新的激活应用到卷积网络中,我们必须选择使用哪一层,以及使用哪个阶段。此外,我们还考察了与SENet等现有有效方法的兼容性。
Compatibility with different convolution layers:首先,我们比较了不同卷积层后的位置。即考察1 × 1和3 × 3卷积后不同位置FRe LU的影响。我们在ResNet - 50 [ 15 ]和ShuffleNetV2 [ 30 ]上进行实验。我们将1 × 1卷积和3 × 3卷积后的ReLU进行替换,观察改进情况。表8显示了上述两个网络的瓶颈处的结果。从结果中我们可以看出,不同层上的改进是可比的,当采用两者时具有最优的性能。

Compatibility with different stages:其次,我们研究了CNN结构中不同阶段的兼容性。特别是在空间维度较高的图层上,视觉激活非常重要。对于浅层空间维度较大、深层通道维度较大的分类网络,在不同阶段施加视觉激活可能存在差异。对于224x224输入的ResNet - 50阶段5,其7x7特征尺寸相对较小,主要包含通道依赖而非空间依赖。因此,我们在ResNet - 50的Stage { 2-4 }上采用视觉激活,如表9所示。结果表明,采用浅层的影响较大,而采用深层的影响较小。并且,对它们都采用FRe LU具有最优的top - 1精度。

Compatibility with SENet:最后,我们与SENet [ 20 ]进行了性能比较,展示了其兼容性。由于没有CNN架构的复杂进步,它与常规卷积层一起,在所有三个视觉任务上都实现了显著的改进。我们进一步将视觉激活与最近有效的注意力模块SENet进行比较,因为SENet是最近最有效的注意力模块之一。
表10给出了结果,虽然SENet使用了额外的块来提高模型的容量,但值得注意的是,简单的视觉激活甚至优于SENet。我们也希望我们提出的视觉激活可以与其他技术共存,比如SE模块。我们在ResNet - 50的最后一个阶段采用SE模块来避免过拟合。表10还显示了FReLU与SE模块的共存情况。与SENet一起,漏斗激活进一步提升了0.3 %的准确率。

6 Conclusions
在这项工作中,我们提出了一个漏斗激活专门设计的视觉任务,它使用像素级的建模能力轻松捕获复杂的布局。我们的方法简单有效,并且与其他技术有很好的兼容性,为图像识别任务提供了新的替代激活。我们注意到,ReLU已经非常有影响力,许多先进的架构已经为其设计,但它们的设置可能不是最佳的漏斗激活。因此,仍具有较大的进一步改进潜力。
7 核心代码
class FReLU(M.Module):
r""" FReLU formulation. The funnel condition has a window size of kxk. (k=3 by default)
"""
def __init__(self, in_channels):
super().__init__()
self.conv_frelu = M.Conv2d(in_channels, in_channels, 3, 1, 1, groups=in_channels)
self.bn_frelu = M.BatchNorm2d(in_channels)
def forward(self, x):
x1 = self.conv_frelu(x)
x1 = self.bn_frelu(x1)
x = F.maximum(x, x1)
return x