文章目录
十一、ESPNet
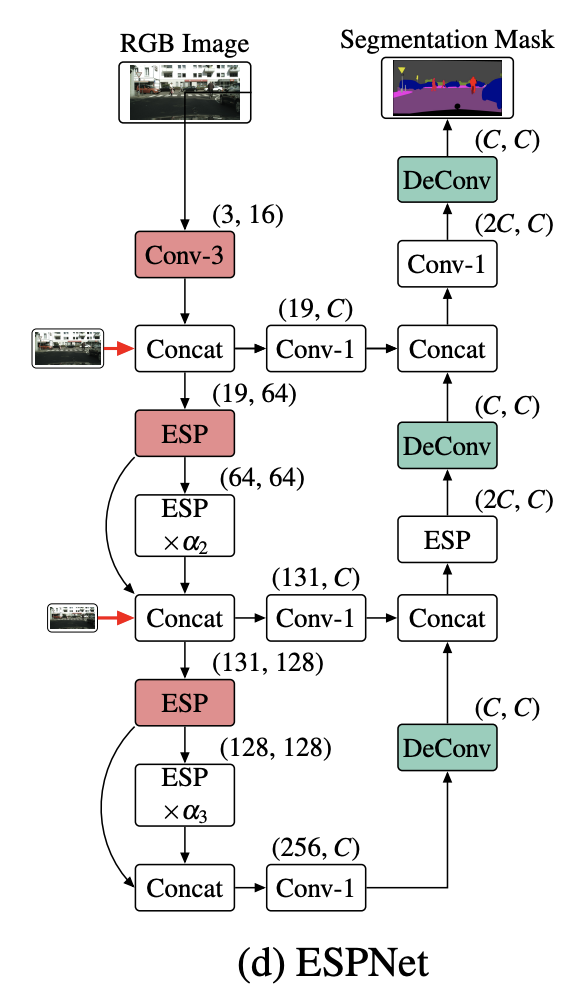
ESPNet 是一种卷积神经网络,用于在资源限制下对高分辨率图像进行语义分割。 ESPNet 基于卷积模块——高效空间金字塔(ESP),在计算、内存和功耗方面都很高效。
十二、HyperDenseNet
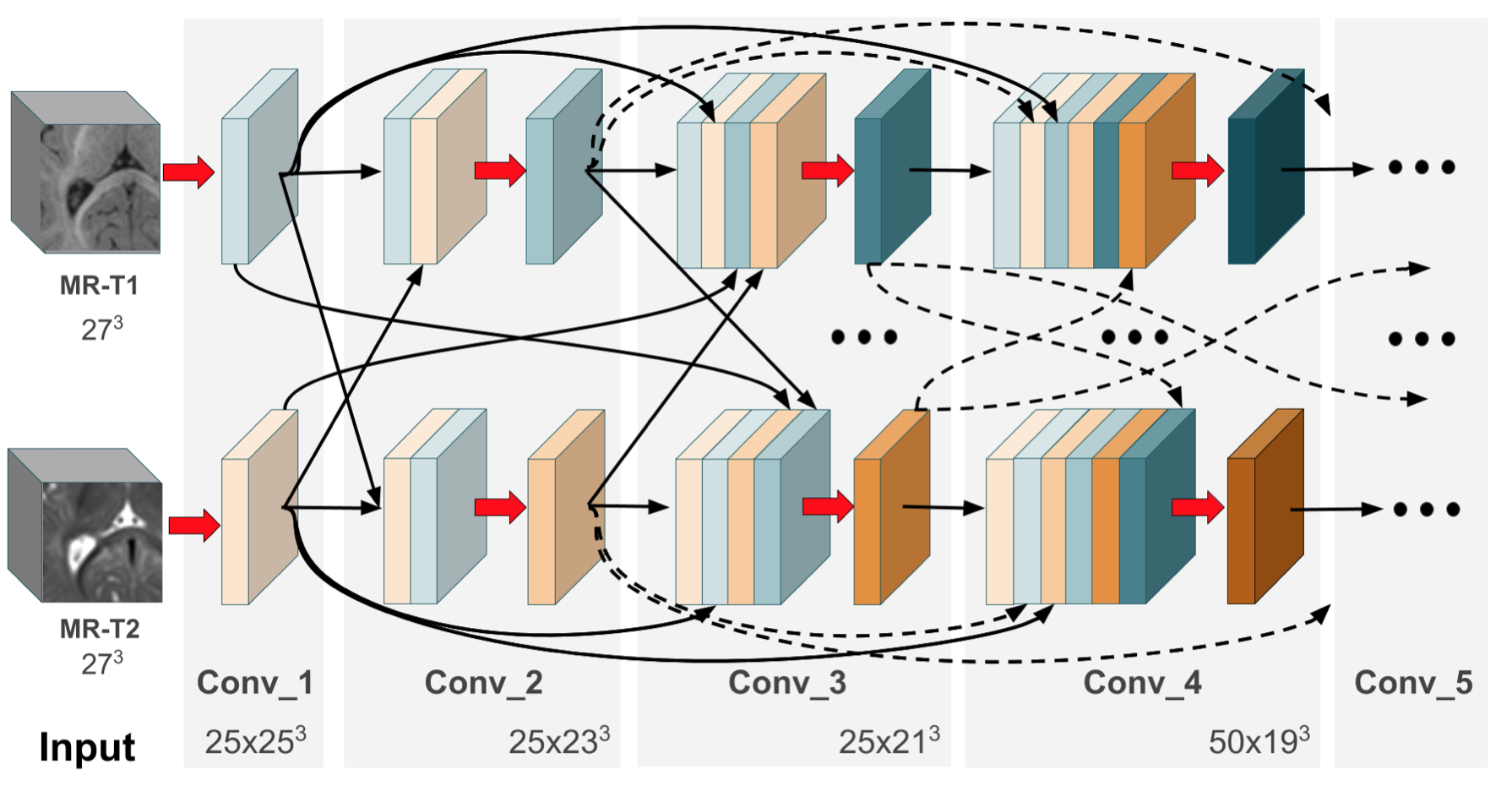
最近,密集连接在计算机视觉领域引起了广泛关注,因为它们促进了训练过程中的梯度流和隐式深度监督。 特别是,DenseNet 以前馈方式将每一层连接到其他每一层,并在自然图像分类任务中表现出了令人印象深刻的性能。 我们提出了 HyperDenseNet,这是一种 3D 全卷积神经网络,它将密集连接的定义扩展到多模态分割问题。 每种成像模式都有一条路径,密集连接不仅发生在同一路径内的层对之间,而且发生在不同路径的层对之间。 这与现有的多模态 CNN 方法形成鲜明对比,在现有的多模态 CNN 方法中,对多种模态进行建模完全依赖于单个联合层(或抽象级别)进行融合,通常在网络的输入或输出处进行融合。 因此,所提出的网络可以完全自由地学习模态之间、所有抽象级别之内和之间的更复杂的组合,这显着增加了学习表示。 我们报告了对两个不同且高度竞争的多模式脑组织分割挑战 iSEG 2017 和 MRBrainS 2013 的广泛评估,前者侧重于六个月婴儿数据,后者侧重于成人图像。 HyperDenseNet 比许多最先进的分割网络有了显着的改进,在两个基准测试中均名列前茅。 我们进一步提供了特征重用的全面实验分析,证实了超密集连接在多模态表示学习中的重要性。
十三、K-Net
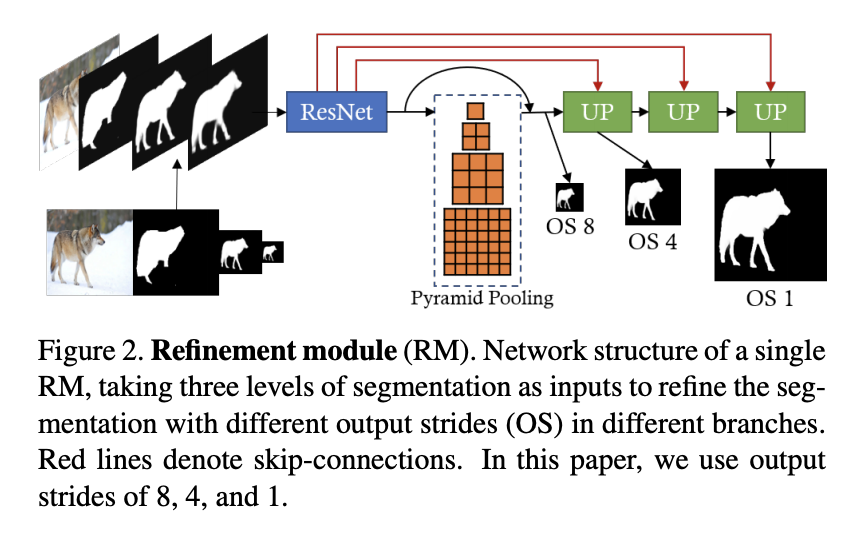
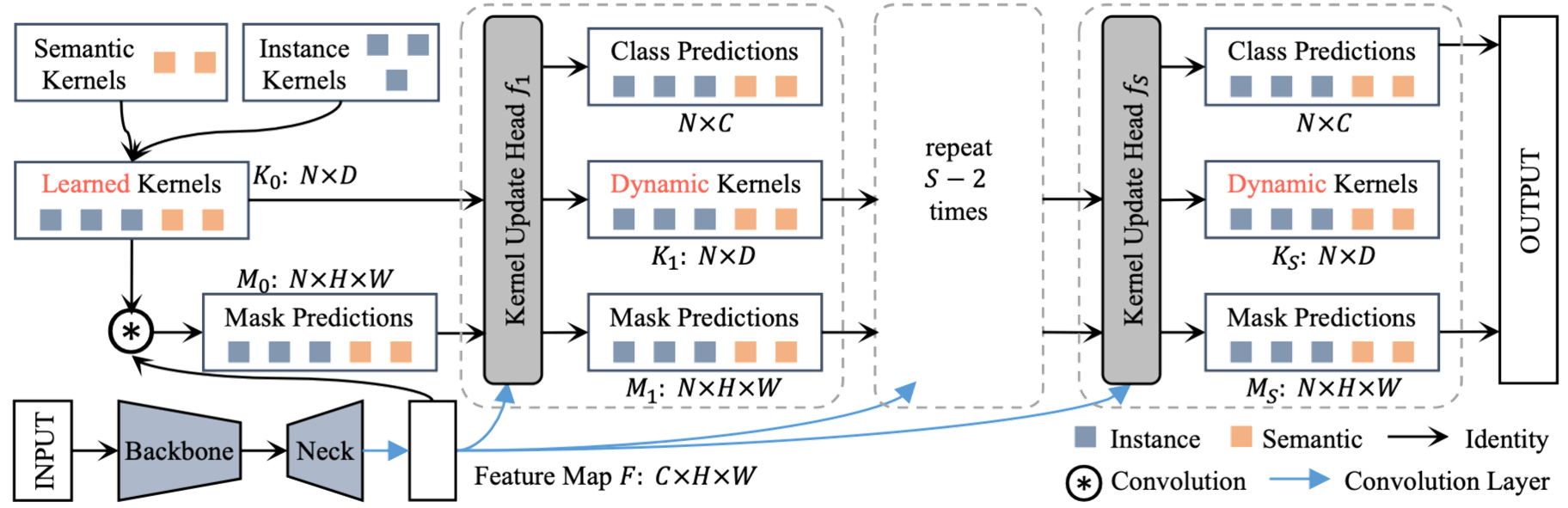
K-Net 是一个统一语义和实例分割的框架,它通过一组可学习的内核来一致地分割实例和语义类别,其中每个内核负责为潜在实例或填充类生成掩码。 它从一组随机初始化的内核开始,并根据手头的分割目标学习内核,即语义类别的语义内核和实例身份的实例内核。 语义内核和实例内核的简单组合可以自然地实现全景分割。 在前向传递中,内核对图像特征进行卷积以获得相应的分割预测。
K-Net 的设计可以动态更新内核,使其以图像上的激活为条件。 这种内容感知机制对于确保每个内核(尤其是实例内核)准确响应图像中的变化对象至关重要。 通过迭代应用这种自适应内核更新策略,K-Net 显着提高了内核的判别能力并提高了最终的分割性能。 值得注意的是,该策略普遍适用于所有分割任务的内核。
它还利用二分匹配策略为每个内核分配学习目标。 这种训练方法比传统的训练策略更有优势,因为它在图像中的内核和实例之间建立了一对一的映射。 因此,它解决了处理图像中不同数量实例的问题。 另外,它是纯粹的mask驱动,不涉及box。 因此,K-Net 天然是无 NMS 和无盒子的,这对实时应用程序很有吸引力。
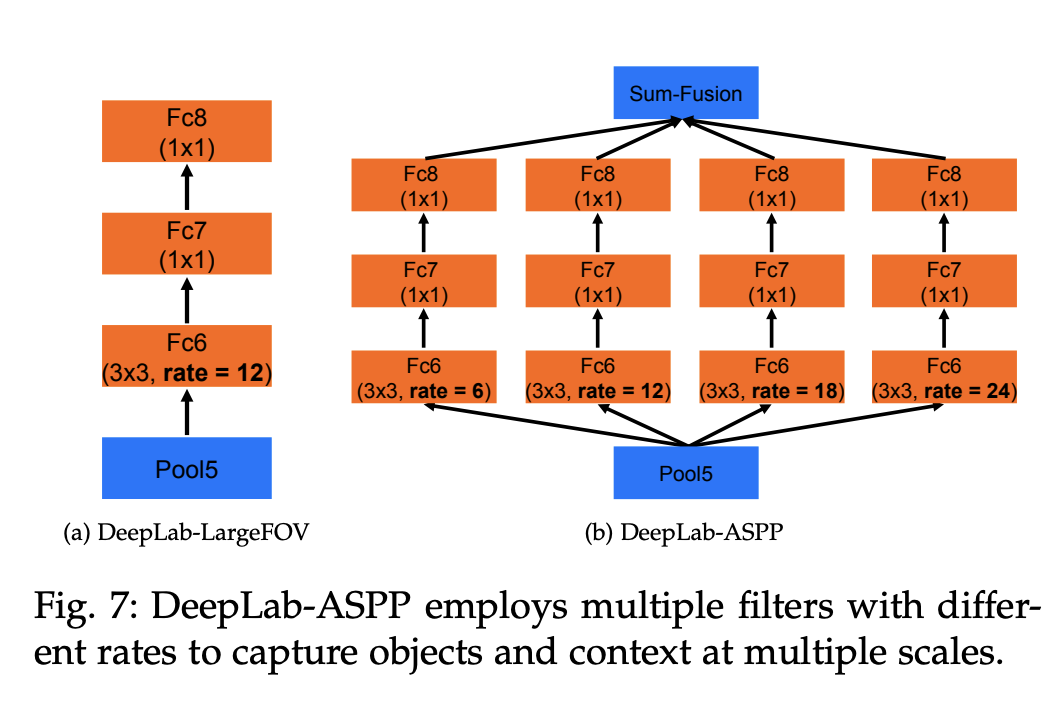
十四、DeepLabv2
DeepLabv2 是一种基于 DeepLab 的语义分割架构,具有多孔的空间金字塔池方案。 在这里,我们在输入特征图中应用了不同速率的并行扩张卷积,然后将它们融合在一起。 由于同一类的对象在图像中可能具有不同的大小,ASPP 有助于考虑不同的对象大小。
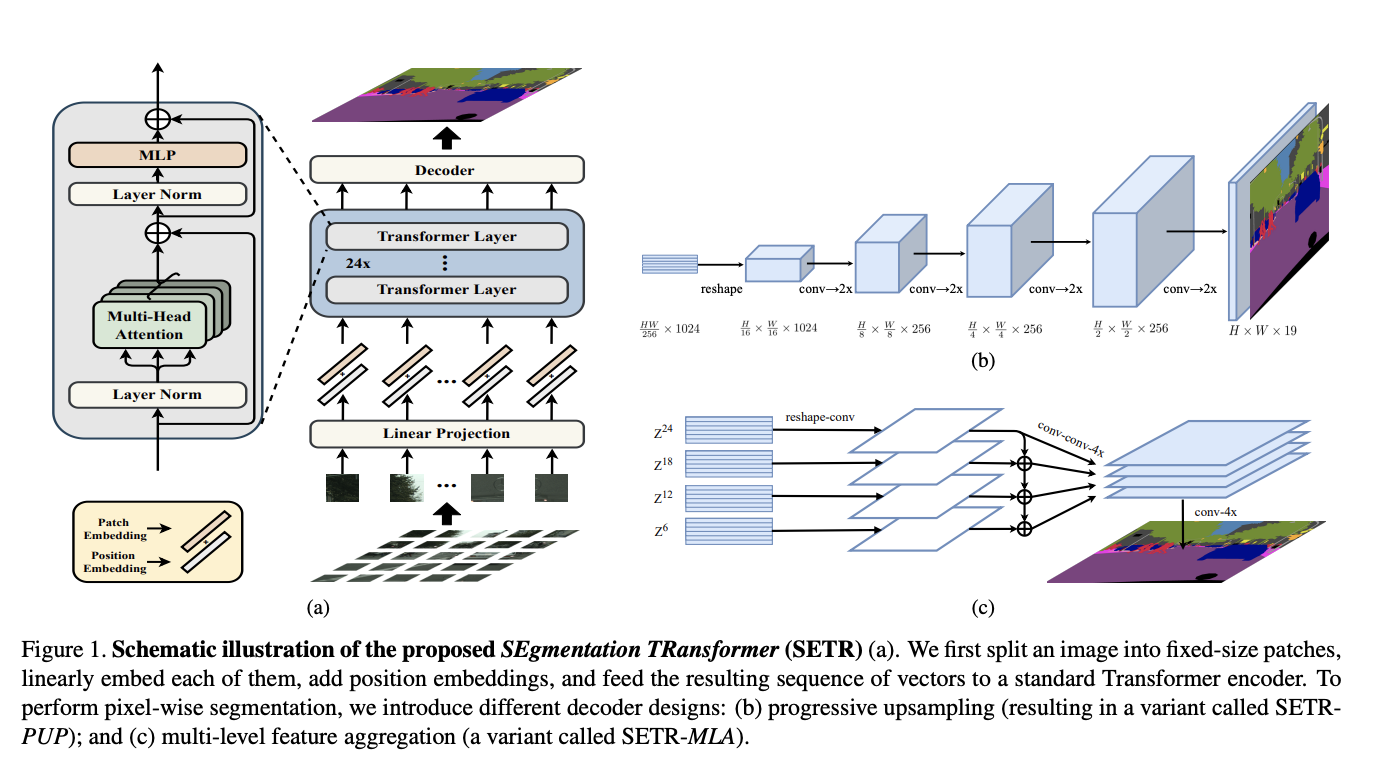
十五、Segmentation Transformer
Segmentation Transformer(简称 SETR)是一种基于 Transformer 的分割模型。 单独的变压器编码器将输入图像视为由学习的补丁嵌入表示的图像补丁序列,并使用全局自注意力模型转换该序列以进行判别性特征表示学习。 具体来说,我们首先将图像分解为固定大小的补丁网格,形成补丁序列。 将线性嵌入层应用于每个补丁的展平像素向量,然后我们获得一系列特征嵌入向量作为变压器的输入。 给定从编码器变换器学到的特征,然后使用解码器来恢复原始图像分辨率。 至关重要的是,编码器转换器的每一层都没有空间分辨率下采样,而是全局上下文建模。
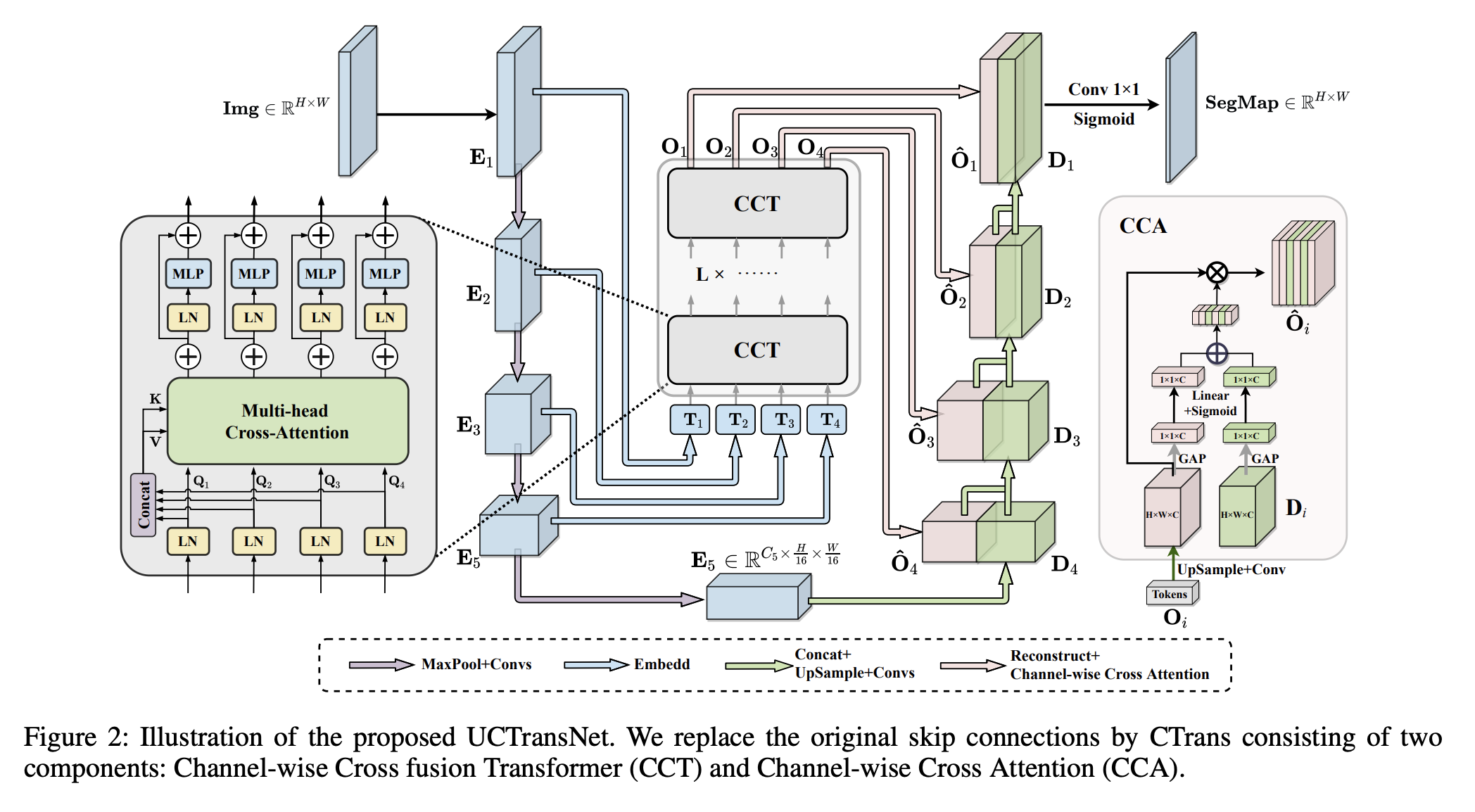
十六、UCTransNet
UCTransNet是一个用于语义分割的端到端深度学习网络,以U-Net作为网络的主要结构。 U-Net原来的skip连接被CTrans取代,CTrans由两个组件组成:Channel-wise Cross fusion Transformer(CCT)和Channel-wise Cross Attention(CCA),引导融合后的多尺度channel-wise信息有效连接到 解码器具有消除歧义的功能。
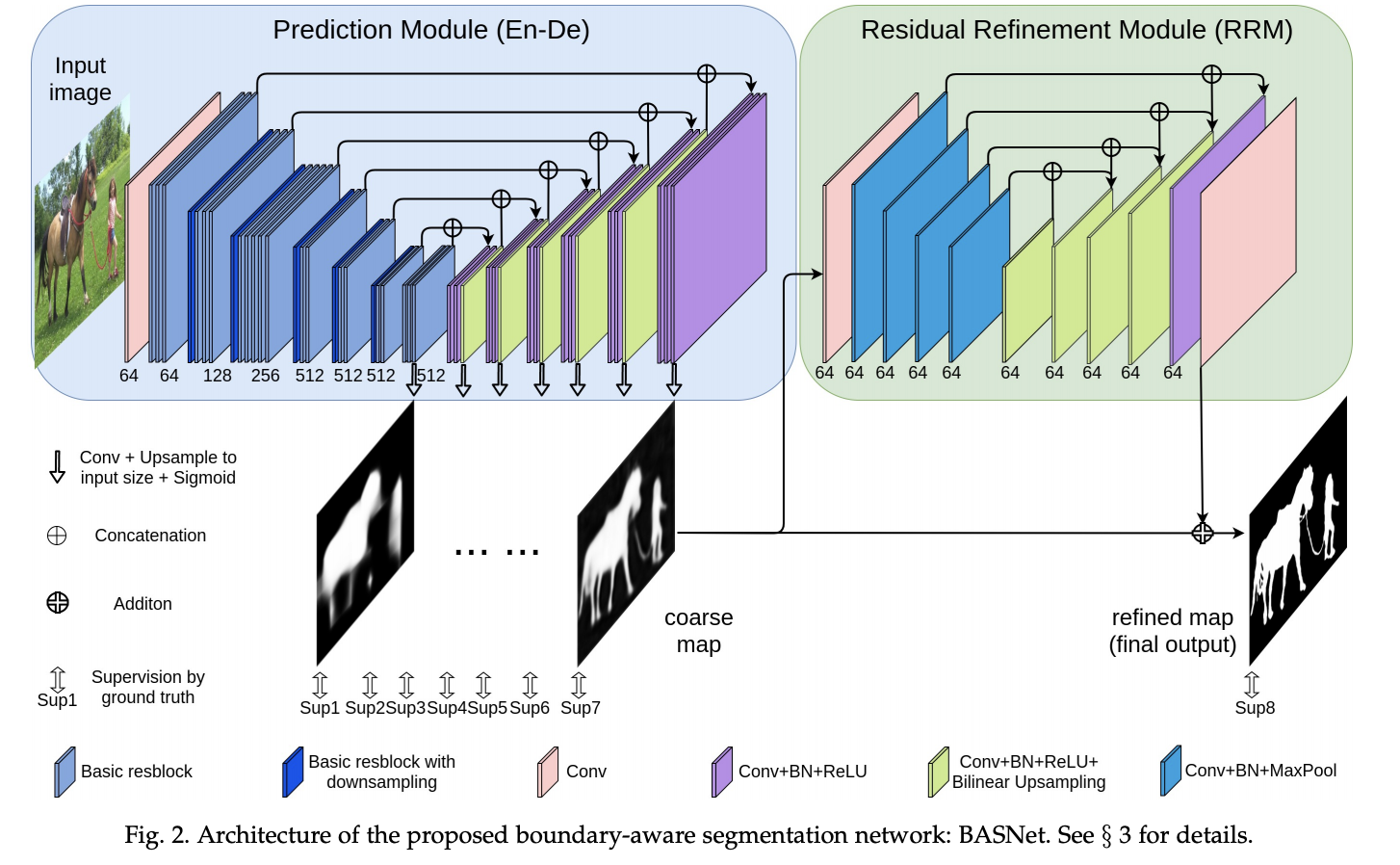
十七、Boundary-Aware Segmentation Network
BASNet,即边界感知分割网络,是一种图像分割架构,由预测细化架构和混合损失组成。 所提出的 BASNet 包含预测细化架构和混合损失,用于高精度图像分割。 预测-细化架构由密集监督的编码器-解码器网络和残差细化模块组成,分别用于预测和细化分割概率图。 混合损失是二元交叉熵、结构相似性和交集损失的组合,它引导网络学习三级(即像素级、补丁级和地图级)层次表示。
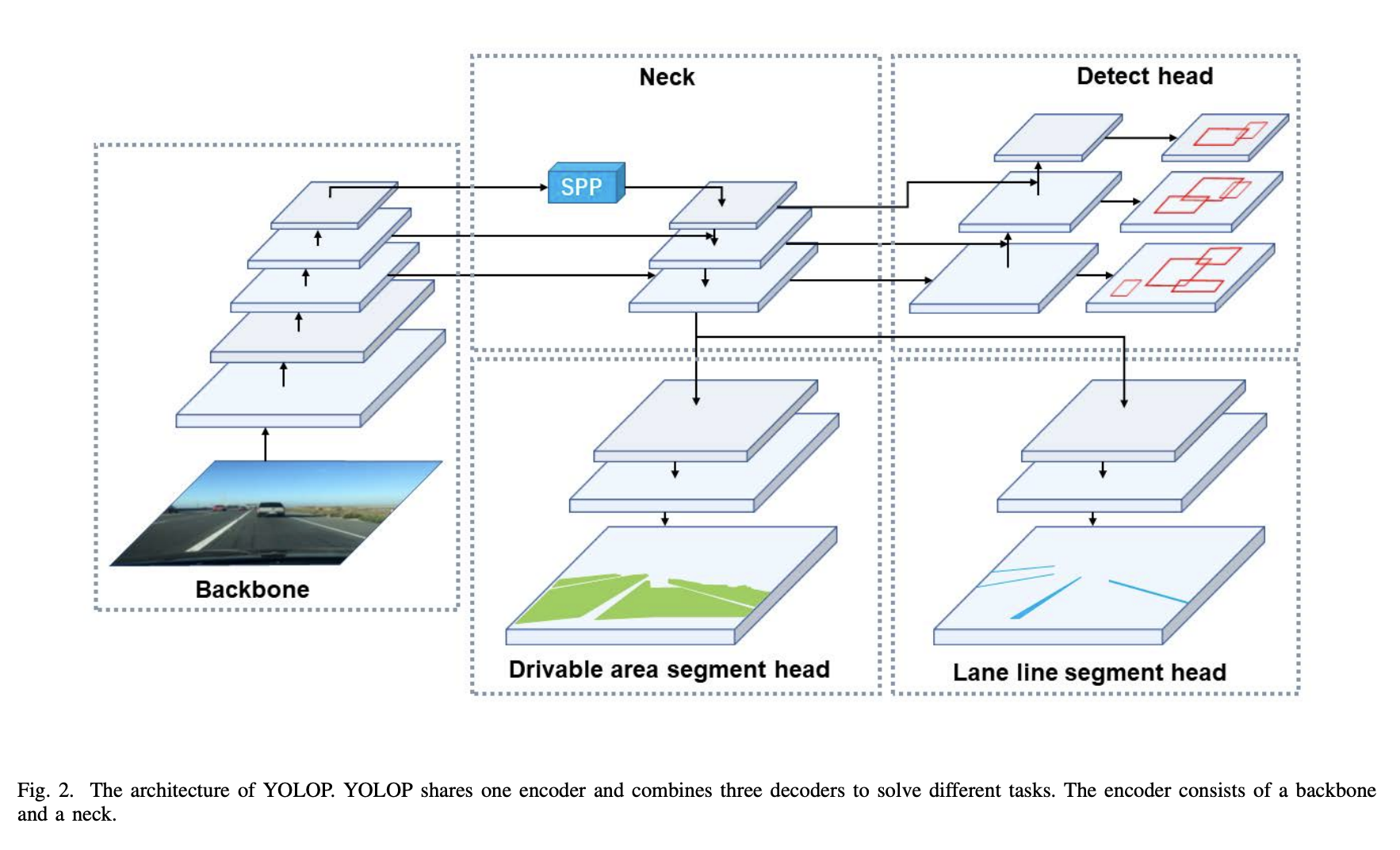
十八、YOLOP
YOLOP 是一个全景驾驶感知网络,用于同时处理交通对象检测、可驾驶区域分割和车道检测。 它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。 它可以被认为是特斯拉自动驾驶汽车 HydraNet 模型的轻量级版本。
使用来自 Scaled-yolov4 的轻量级 CNN 作为编码器来从图像中提取特征。 然后这些特征图被馈送到三个解码器以完成各自的任务。 检测解码器基于当前性能最好的单级检测网络YOLOv4,主要有两个原因:(1)单级检测网络比两级检测网络更快。 (2)单级检测器的基于网格的预测机制与其他两个语义分割任务更相关,而实例分割通常与基于区域的检测器结合,如Mask R-CNN。 编码器输出的特征图融合了不同级别和尺度的语义特征,我们的分割分支可以使用这些特征图来完成逐像素语义预测。
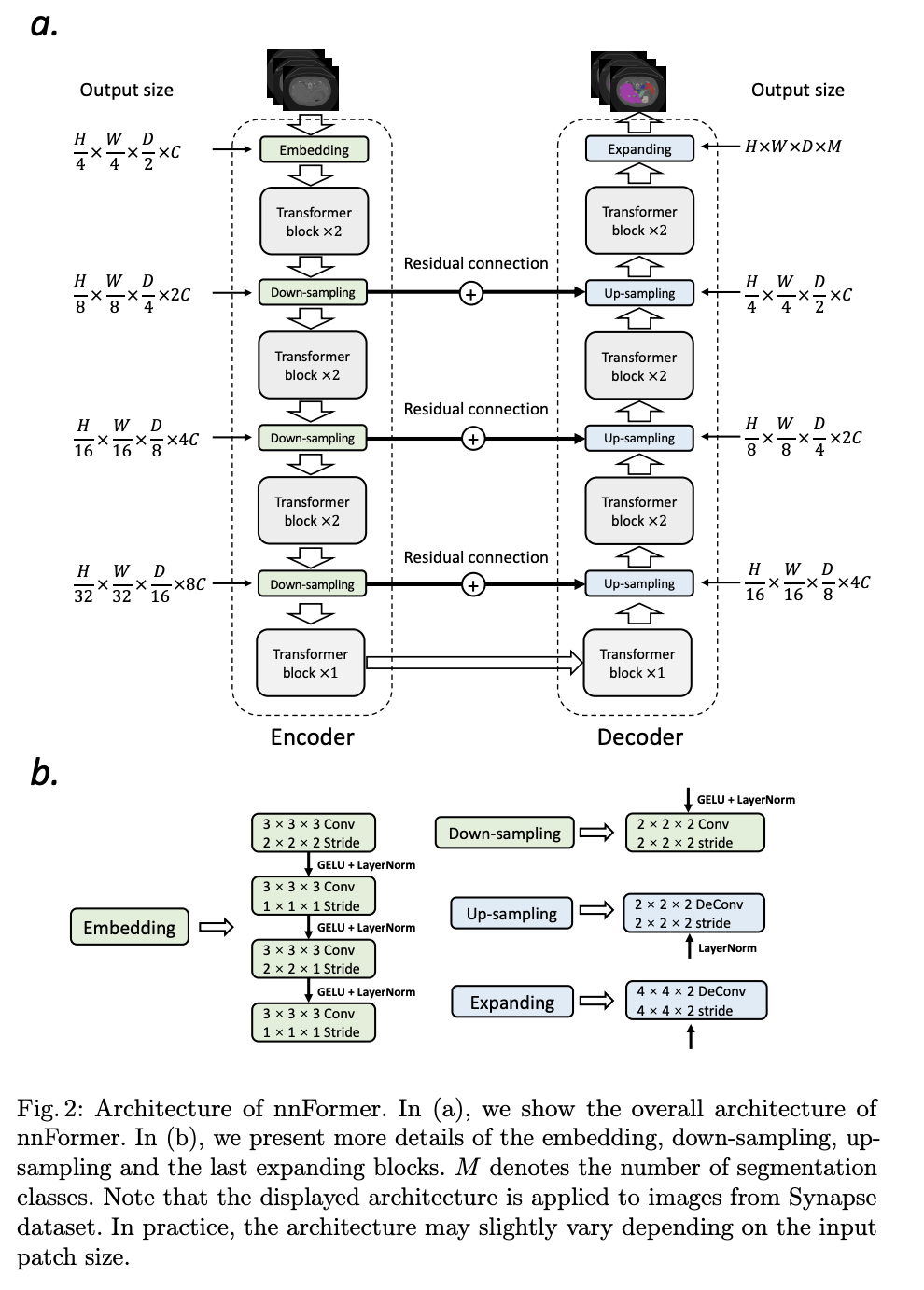
十九、nnFormer
nnFormer,或者不是另一个 transFormer,是一种语义分割模型,具有基于自注意力和卷积的经验组合的交错架构。 首先,在变压器块之前使用轻量级卷积嵌入层。 与直接展平原始像素并应用 1D 预处理相比,卷积嵌入层对精确(即像素级)空间信息进行编码,并提供低级但高分辨率的 3D 特征。 在嵌入块之后,变压器和卷积下采样块交织在一起,以将长期依赖关系与各种尺度的高级和分层对象概念完全纠缠在一起,这有助于提高学习表示的泛化能力和鲁棒性。
二十、CascadePSP
CascadePSP 是一种通用分割细化模型,可细化从低分辨率到高分辨率的任何给定分割。 该模型将初始掩码作为输入,该掩码可以是任何算法的输出,以提供粗略的对象位置。 然后CascadePSP将输出一个精致的掩模。 该模型以级联方式设计,以从粗到细的方式生成精细分割。 早期级别的粗略输出预测对象结构,该结构将用作后面级别的输入以细化边界细节。