面向零镜头跨语言图像检索与标注
摘要
最近,人们对多模态语言和视觉问题的兴趣激增。在语言方面,大多数模型主要关注英语,因为大多数多模态数据集都是单语的。我们试图通过在文本侧使用跨语言预训练来学习多模态表征的零镜头方法来弥合这一差距。
我们提出了一种简单而实用的方法来构建跨语言图像检索模型,该模型在单语训练数据集上进行训练,但可以在推理过程中以零拍跨语言方式使用。我们还引入了一个新的目标函数,该函数通过将不同的文本相互推离来收紧文本嵌入簇。为了进行评估,我们引入了一个新的1K多语言MSCOCO2014字幕测试数据集(XTD10),该数据集采用7种语言,我们使用众包平台收集。
我们使用它作为跨语言零镜头模型性能的测试集。我们还演示了如何将跨语言模型用于下游任务,如以零镜头方式进行多语言图像标记。XTD10数据集在以下位置公开
导言
图像检索在学术界和工业界都是一个研究得很好的问题。大多数研究着眼于单语环境下的图像检索,原因有两个:
•缺乏支持多种语言的多语言视觉语言数据集
•可扩展到新的和低资源的语言支持
多语言数据集收集一直是以一种模型适用于所有人的方式构建模型的主要障碍,这种方式可以为跨多种语言的图像检索提供良好的结果。大多数方法依赖于英文字幕的直接翻译,而其他方法则使用独立的图像和语言文本对。基于之前的研究学习,我们在本文中尝试探索以下想法:
One-model-fits-all:我们能否使用预训练的跨语言嵌入和单语图像-文本训练数据来学习通用嵌入空间中的表示 图像检索和标记?
多语言评估数据集:为多语言图像检索构建评估集,以在零样本检索设置中进行测试
在我们的方法中,我们试图利用跨语言句子嵌入[3,38]的最新发展,这可以有效地在一个公共嵌入空间中对齐多种语言。由于缺乏多语言句子测试数据集,为了进行评估,我们结合了10个非英语语言注释,创建了一个名为XTD10的跨语言测试数据集。
作为 [1] 的扩展,在本文中,我们还尝试在多语言图像标记上利用 One-model-fits-all 方法并将其作为零样本问题来解决。 以英语以外的语言使用的单语图像标记模型面临与图像检索问题类似的可扩展性问题和训练数据约束。 在标签级别使用英文图像标注器和直接翻译是一种直接的解决方案,但由于单词歧义,单词级别的翻译系统缺乏要捕获的上下文,因此容易出错。 法语中的 Spring 有两个翻译:Printemps(Season Spring)和 Ressort(Bouncy Spring)。 翻译模型将主要返回 Printemps,即使是对于 Bouncy Spring 的图像,因为它在翻译训练数据中的存在范围更广。 我们的上下文方法通过捕获图像上下文和文本语义来解决这些问题,而与语言无关。
2相关工作
在图像检索系统中,图像元数据(如标签)通常是有噪声且不完整的。因此,随着时间的推移,在大规模图像检索任务中,将低级视觉信息与用户的文本查询意图相匹配已经变得很流行[19]。度量学习是实现这一点的一种方法,它将来自不同模态的样本投影到一个共同的语义表示空间中。[15] 这是一种早期的单语教学法。
我们探索的主要目标之一是多语言检索支持,因此多语言多模态公共表示成为我们解决方案的一个关键方面。最近的多语言度量学习方法[5,41]试图最小化图像和标题对以及多语言文本对之间的距离。基于大型并行语言语料库的可用性,这些方法受到限制。[12] 使用图像作为轴来执行度量学习,从而使一种语言中的文本独立于其他语言。[20] 使用类似的方法,但增加了视觉对象检测和多头注意[34],有选择地将突出的视觉对象与文本短语对齐,以获得更好的性能。类似地,[4,23,27]使用独立于语言的文本编码器,使用共享权重将不同语言与公共句子嵌入空间对齐,同时创建多模态嵌入空间。这种方法允许更好的泛化。虽然上述方法为构建跨语言多模态空间提供了价值和见解,但我们选择[29]作为衡量模型性能的基线,因为这是我们发现的唯一一种遵循零样本方法的方法,在词汇层面(单词级别)上。
用多种语言手动标注数据集可能会带来巨大的开销,尤其是在处理大型语料库时。有人提出了通过网络抓取来解决这一问题的方案,但很多时候数据集都非常嘈杂。像[11,14,25,36,39]这样的数据集只提供2-3种语言的图像,这无助于将模型扩展到大量语言。因此,上面讨论的大多数模型在有限的语言支持下工作。
我们最近的工作是大规模多语言图像数据集[17]计划。一个很大的区别是,他们专注于100种语言的并行数据,但数据集是单词级概念,在字幕提供的复杂现实世界场景中,丢失了概念间和对象间的上下文
由于图像标签数据在除英语外的多种语言中都不可用,因此图像标签通常采用单语设置。与图像检索问题类似,一些工作(如[25])假设在多个目标语言中有带标签的注释图像,因此受到其语言清单的限制。我们在跨语言领域的解决方案假设或要求没有标记的训练语料库。令人惊讶的是,几乎没有零射程跨语言方法,其中之一是[35]。Wei等人提出了标签增强的零镜头学习,他们利用在英语和汉语语料库上训练的双跳跃模型,以及来自英语图像标记器的标签分数,在多模态双语空间中创建标签和图像嵌入。然后使用基于相似性的排序生成目标标签。然而,这种创建多模态嵌入的方法在文本语义上占主导地位,无法准确捕捉我们的方法试图处理的图像上下文
3.提议的方法
为了解决以上讨论的多语言图像检索问题,我们采用了一种简单但实用且有效的零样本方法,通过使用度量学习将文本和图像映射到同一嵌入空间,只使用英语文本图像对来训练模型。我们将英语文本训练数据转换为跨语言嵌入空间进行初始化,这有助于在推理过程中支持多种语言。图1概述了我们的方法。
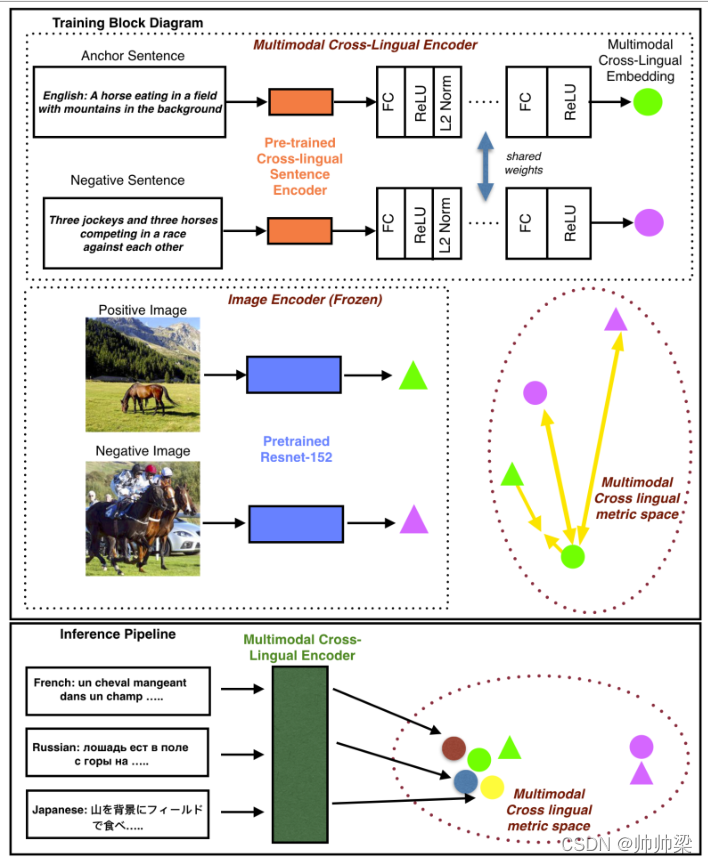
图1:我们的方法的概述
3.1模型架构
大多数涉及图像的行业用例都有一个预先训练好的图像嵌入模型。在每个用例中构建和索引新的嵌入是非常昂贵的。为了实现这种优化,在不损失通用性的情况下,我们假设存在一个预训练的图像嵌入模型,如在ImageNet[9]上训练的ResNet[16]。我们将图像嵌入提取模型冻结,不在视觉方面添加任何可训练的层。根据预先训练好的ResNet152架构,我们使用最后一个平均池层作为大小为2048的图像嵌入。
在文本编码器端,我们首先提取文本数据的句子级嵌入。 我们尝试了两种最先进的跨语言模型——LASER [3] 和多语言 USE(或 mUSE)[6, 38]。 LASER 使用与语言无关的 BiLSTM [18] 编码器来创建句子嵌入,并支持 93 种语言的句子级嵌入。 mUSE 是一个基于 Transformer [34] 的编码器,支持 16 种语言的句子级嵌入。 它对多个下游任务使用共享的多任务双编码器训练框架
在句子级嵌入提取之后,我们按顺序附加具有 dropout [33]、整流线性单元 (ReLU) 激活层 [13] 和 l2-norm 层的全连接层块。 l2-norm 层有助于保持中间特征值较小。
对于最后一个块,我们不添加 l2-norm 层以与 ResNet 输出特征保持一致。 从我们的实验中,3 个堆叠的块给了我们最好的结果。
3.2培训策略
对于每个文本标题(锚文本)和(正)图像对,我们使用[2]中的在线负采样策略在训练小批量中挖掘硬负样本。我们将与负片图像对应的标题视为硬负片文本。
我们提出了一种新的目标损失函数,称为“Multi-modal Metric Loss (M3L)”,它有助于减少锚文本与其正图像之间的距离,同时将负图像和负文本从锚文本中推开。
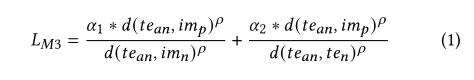
这里 t e a n te_{an} tean是文本锚点, t e n te_{n} ten是负面文本, i m p , i m n im_p,im_n imp,imn分别是正面和负面图像。 d(x,y) 是 x 和 y 之间的平方距离。 ρ \rho ρ控制距离变化的敏感度。 α 1 {\alpha _1} α1和 α 2 {\alpha _2} α2是每个负距离模态的比例因子。 对于我们的实验,我们看到当 ρ \rho ρ= 4、 α 1 {\alpha _1} α1= 0.5 和 α 2 {\alpha _2} α2 = 1 时,我们得到了最好的结果。 为了确认它的效率,我们将我们的结果与另一个称为“Positive Aware Triplet Ranking Loss (PATR)”[2] 的度量学习损失进行了比较,该损失在没有负面文本的情况下执行类似的任务。
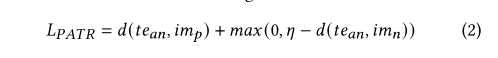
这里 η \eta η惩罚了anchor和negative image之间的距离,因此控制了clusters的紧密度。 在我们的实验中 η \eta η = 1100 给出了最好的性能。
我们使用 0.001 的学习率和 Adam Optimizer [24] (beta1=0.99)。 我们分别为维度为 [1024, 2048, 2048] 的每个全连接层添加了 [0.2, 0.1, 0.0] 的 dropout。 由于我们想要从我们的小批量中提取硬负样本,我们采用 128 的大批量并训练我们的模型 50 个 epoch。
3.3 Multi-lingual Downstream Tasks
在这里,我们将讨论如何在多语言推理过程中将我们的模型用于图像检索和图像标记等下游任务。 这两个任务都包含两个阶段:extraction and ranker
3.3.1 Image Retrieval.
我们首先使用 ResNet152 架构的最后一个平均池化层提取和索引检索语料库中所有图像的图像嵌入。 给定模型支持的任何语言的用户文本查询,我们使用经过训练的跨语言多模式文本编码器的最后一个 FC 层输出提取其嵌入。 然后,我们使用距离度量(例如余弦相似度或平方距离)找到文本嵌入和索引图像嵌入之间的相似度得分。 最后,根据图像的相似度得分对图像进行排名。
可以在相似度得分上设置阈值,低于该阈值的图像将被过滤掉。
3.3.2 Image Tagging.
图2概述了我们将零镜头多语言图像标记作为下游任务的方法。
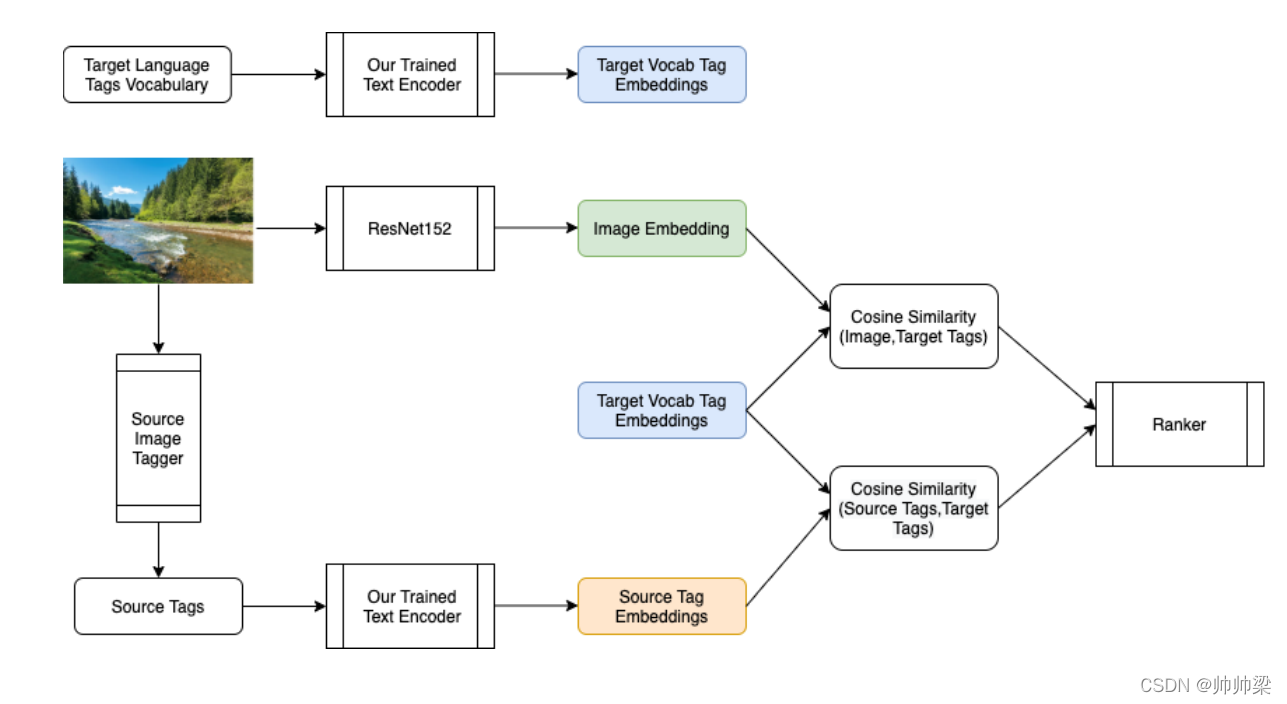
图2:推理过程中的多语言标记器概述
如上所述,跨语言图像标记利用经过训练的图像标记模型来生成源语言中的标记。我们还假设源标签和目标标签在我们的解决方案中可用。
提取阶段的第一步是使用经过训练的跨语言多模态文本编码器的最后一个 FC 层输出提取和索引整个目标语言标签词汇表的文本嵌入。 给定一张查询图像,我们使用图像标注器获取源标签,并使用经过训练的文本编码器再次提取每个标签的文本嵌入。 与图像检索任务类似,图像嵌入是使用最后一个平均池层从 ResNet152 模型中提取的。
对于排名,我们使用这些嵌入计算两组余弦相似度:图像-目标语言标签(等式 3)和源标签-目标语言标签(等式 4) 之间。 然后使用这两个相似度值从每个源标签的目标词汇表中为每个标签分配一个分数(方程 5)
根据每个源标记的这些分数进行排名后,顶部标记将作为该源标记的目标语言注释(最相似的语言就是该语言)。如果top tag已经被作为前一个源标记的注释,则使用排名第二的标记。我们按源标记排序,以保持源语言和目标语言注释的平等性。
方程变量依赖于语料库。在我们的实验中,我们观察到W1和W2的最佳结果分别为0.65和0.35。
4 EVALUATION
4.1 数据集
我们使用MSCOCO 2014[26]和人类注释数据集XTD10(表1)进行测试,使用Multi30K数据集[10]进行图像检索实验。
4.1.2 Multi30K
在 Multi30K 数据集中,每张图像都有英文、法文和德文的标题。 我们将数据 29000/1014/1000 拆分为训练/开发/测试集。
对于表 2 中仅在英语语言上训练的每个模型。我们展示了使用 PATR 和 M3L 度量学习损失的 LASER 和 mUSE 句子嵌入之间的比较。 因为训练数据只有英语,我们看到英语作为我们的上限时表现更好。 通过零样本学习,我们获得了我们测试的所有其他 10 种非英语语言的可比性能。 我们在应用 M3L + mUSE 时观察到最佳结果,因为在损失函数中添加负文本会在度量空间中创建更紧密的文本簇。
然而,对于像俄语和波兰语这样的斯拉夫语言,在使用 mUSE 和英语中的否定文本时,我们没有看到性能上有太大差异。 在将跨语言非英语嵌入与 mUSE 和 LASER 各自的英语嵌入进行聚类时,我们发现 mUSE 与 LASER 在所有语言中的重叠非常明显。 因此,我们看到使用 mUSE 训练的模型在所有语言中的性能保持一致。 我们还在 [38] 的表 7 中看到表 2 中报告的 mUSE 和 LASER 之间的类似性能趋势。 我们还怀疑,由于 LASER 接受了更多语言的训练并且是一个不太复杂的模型,因此它比 mUSE 具有更多的泛化性。
我们还使用 Multi30K 数据集报告 Recall@10,我们的模型在 M3L + mUSE 上训练,[29] 作为表 3 中的基线。基线使用 MUSE [7] 跨语言词嵌入进行训练。 我们的方法在多语言和零样本训练中都优于基线。 比较多语言与零样本训练,我们发现由于模型泛化,所有语言的训练都会降低英语的性能。 在零样本设置中,德语和法语的召回准确率略有下降,但与多语言训练结果相当
4.3定性结果
4.3.1图像检索
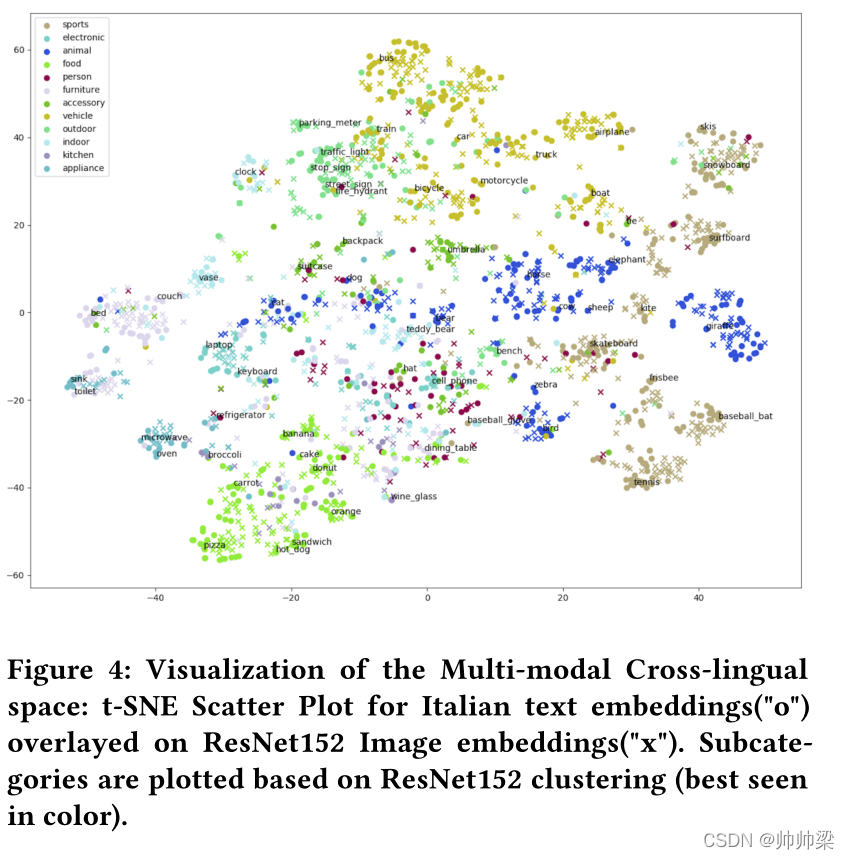
图 4:多模态跨语言空间的可视化:覆盖在 ResNet152 图像嵌入(“x”)上的意大利语文本嵌入(“o”)的 t-SNE 散点图。 子类别是根据 ResNet152 聚类绘制的(最好用彩色显示)。
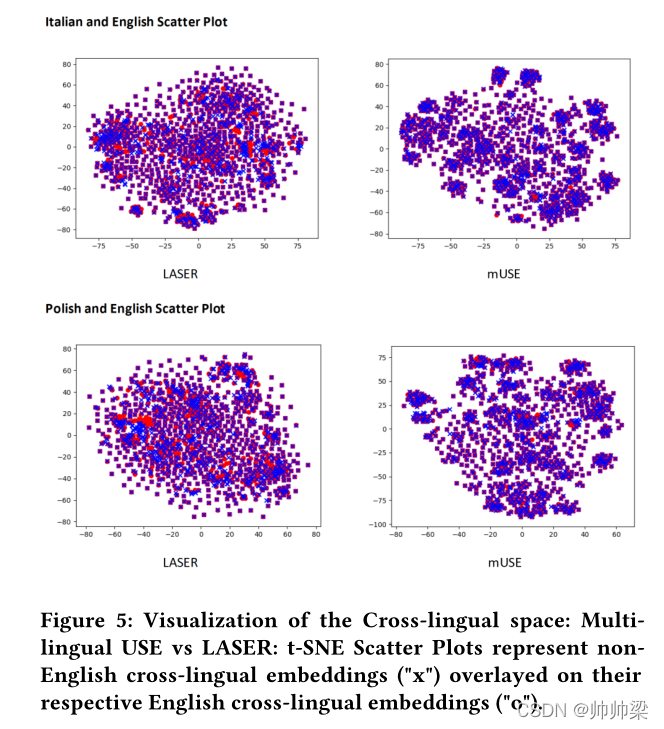
图 5:跨语言空间的可视化:多语言 USE 与 LASER:t-SNE 散点图表示覆盖在其各自的英语跨语言嵌入(“o”)上的非英语跨语言嵌入(“x”)。
在图 5 中,我们看到与 LASER 嵌入相比,英语和非英语 mUSE 跨语言嵌入彼此更紧密地聚集在一起。 这解释了为什么与 LASER 相比,我们获得的非英语语言检索结果更接近于 mUSE 的英语对应物。 我们使用在 MSCOCO2014 数据集上训练的 푈푆퐸푀3퐿 模型结果进行接下来的两个观察。 图 4 展示了与意大利多模式跨语言聚类的视觉嵌入对齐。 在图 3 中,我们可视化了 11 种语言在 Rank 1 检索到的图像。 我们的模型能够捕获所有语言的大多数结果中的所有对象。 对于 3푟푑 和 6푡ℎ 语言的 R@1 示例,对于未将所需图像作为 Rank 1 的语言,仍涵盖其相应文本标题中的所有对象概念。 对于 5푡ℎ 示例,我们看到对于法语,R@1 处的图像,图像中覆盖了岩石和灌木这 2 个物体,但没有泰迪熊。
这是因为它的法语标题“un petit ourson brun Mignon assis sur un rocher par un buisson”没有涵盖泰迪的概念,因为当翻译成英文时,它的意思是“一只可爱的小棕熊坐在灌木丛旁的岩石上”。 但是当我们使用谷歌翻译的 2 英语到法语字幕时,我们确实得到了预期的结果。
4.3.2 图像标注器
对于我们的实验,我们使用一个使用 6M Adobe Stock 3 图像创建的图像标记器来仅生成英语标签,而源语言和目标语言标签词汇表是使用 Adobe Stock 独特的图像标签创建的。 跨语言多模态文本编码器在 20M Adobe Stock 图像字幕对和 6M Adobe Stock clickthrough 数据集上进行训练,具有与本文中提到的相同架构和参数规范。
我们要强调的是,该解决方案独立于源图像标记器、文本编码器和可以轻松替换的标记词汇表。
目前跨语言多模态域不提供用于图像标记的评估数据集,因此对于多语言图像标记,我们将我们的结果与使用谷歌翻译的直接单词翻译进行比较。 我们正在努力为我们将在未来工作中发布的图像标签创建一个类似于提议的 XTD10 的数据集。 我们展示了以法语和德语作为目标语言的结果
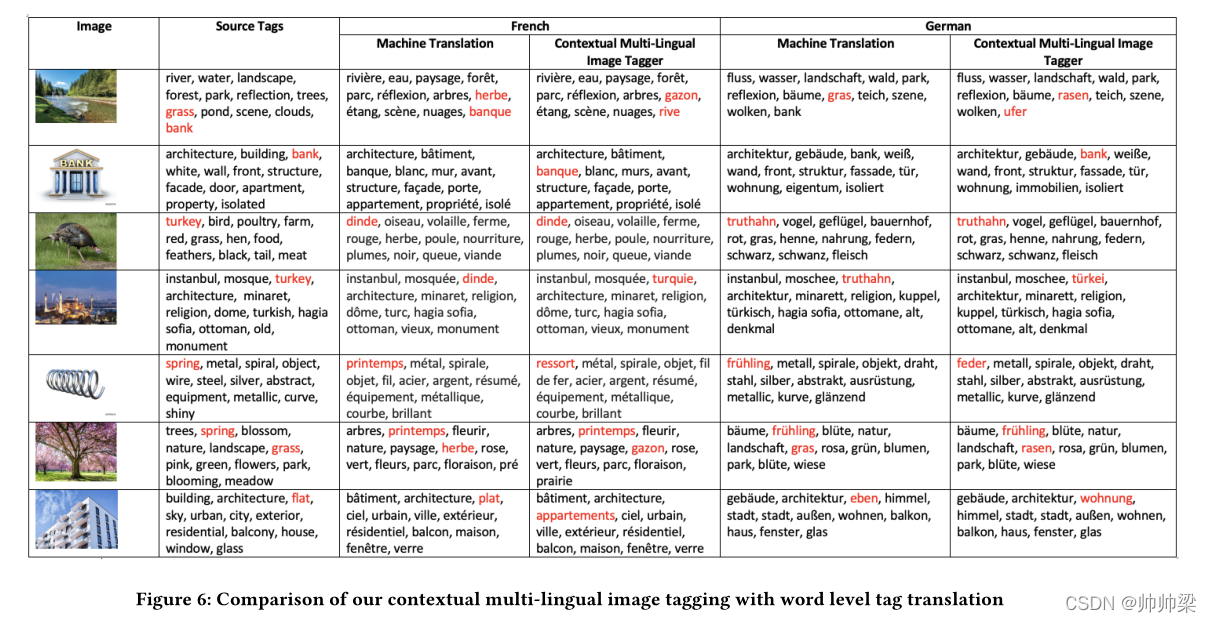
图6:上下文多语言图像标记与单词级标记翻译的比较
在图 6 中,我们展示了词级翻译和基于图像上下文的标注器之间的区别。 我们可以看到,对于像 spring、turkey、bank 等模棱两可的词,即使图像上下文不同,谷歌翻译结果也是相同的。 我们的标注器准确地捕捉上下文。 它可以区分春天是一个季节还是一个对象; 火鸡是一只鸟或一个国家; 银行作为货币银行或河岸。 对于公寓楼的图像,我们手动将源标签公寓替换为 flat。 我们的多语言标注器能够捕捉图像的上下文并提供正确的翻译 appartements 而不是法语的 Plat 和 wohnung 而不是德语的 eben。 我们还可以观察到,对于河岸和春季图像,我们的多语言标注结果与谷歌翻译的标签草不同。 标签 gazon、rasen 的法语、德语的英文翻译分别比作为植物的草更接近草坪。 我们的标注器能够从谷歌翻译中缺失的这些图像中提取上下文。
5 CONCLUSION
我们提出了一种用于跨语言图像检索的零样本设置,并用 10 种非英语语言评估了我们的模型。 这种实用的方法可以帮助在多语言训练数据稀缺的情况下扩展到语言。 我们还演示了如何将该模型以零样本的方式应用于多语言图像标记等下游任务。 未来,我们计划研究小样本设置,其中每种语言都有一些训练数据,并以端到端的方式微调图像端和文本端,进一步提高检索精度。 我们还计划为多语言创建一个新的评估数据集,我们还使用多语言图像标记来帮助标准化该领域的工作。