跨视角语言建模:走向统一的跨语言跨模式预训练
摘要
本文介绍了一种简单有效的语言模型预训练框架Cross-View Language Modeling,该框架将跨语言跨模态预训练与共享的架构和目标相结合。我们的方法受到一个关键观察的启发,即跨语言和跨模式的预训练具有相同的目标,即将同一对象的两个不同视图对齐到一个共同的语义空间中。为此,跨视图语言建模框架将多模态数据(即图像-字幕对)和多语言数据(即并行句子对)视为同一对象的两个不同视图,并通过条件掩码语言建模和对比学习来训练模型以最大化它们之间的相互信息来对齐两个视图。我们使用跨视图语言建模框架对 CCLM3(一种跨语言跨模式语言模型)进行预训练。IGLUE、多语言多模态基准和两个多语言图像文本检索数据集的经验结果表明,虽然概念上更简单,但 CCLM 显着优于先前的状态,平均绝对改进超过 10%。值得注意的是,CCLM 是第一个通过零样本跨语言迁移超越代表性英语视觉语言模型的翻译测试性能的多语言多模态模型。
1 介绍
最近,自监督语言模型预训练 [1-15] 的巨大成功已扩展到多语言 [16-19] 和多模态 [20-24] 领域。多语言预训练的进步使尖端语言技术能够使包括非英语使用者在内的更广泛的用户群体受益。同样,多模态预训练使预训练模型适用于更大的任务集和用户组。这两个方向都使人们在多语言多模式世界中的生活更加轻松。因此,下一步自然是探索多语言多模态预训练,使预训练模型能够解决用非英语语言表达的多模态任务,而无需收集这些语言的训练数据,这可以对于某些低资源语言来说非常昂贵。
多语言多模式预训练虽然很有吸引力,但也有其自身的挑战。与多语种预训练和多模态预训练并行数据量比较大的情况不同,多语种多模态语料库数量较少,语言覆盖范围也有限。 两个开创性的工作, M 3 P M^3P M3P [25] 和 U C 2 UC^2 UC2 [26],提出以英语文本或图像为中心,对齐多语言多模态表示。它们都引入了一些新的目标,以利用锚点进行对齐。
然而,最近一项关于多语言多模态预训练[27]的基准测试显示,这些多语言多模态预训练模型仍然存在不足:虽然在一些视觉和语言任务上实现了看似有希望的零距离跨语言转移性能,但它们的性能仍明显低于 “翻译-测试”,一个简单的基线,将测试示例翻译成英语,并使用仅英语的视觉语言模型进行推理。这阻止了现有的多语言多模态模型在现实应用程序中应用。相比之下,多语言预训练模型,如XLM-R [17]在大多数语言中明显优于翻译测试基线,并在实际应用中广泛使用。
本文旨在充分挖掘多语种多模态预训练的潜力。我们指出了当前技术水平两个主要局限。首先,现有的方法没有利用平行文本语料库,平行文本语料库可以容易地收集并且对于许多语言对来说是丰富的。相反,M3P用不同语言的单语文本执行屏蔽语言建模,以实现多语言对齐。然而,根据多语言预训练文献 [17, 19],平行文本被证明更有帮助。第二,为英语或图像旋转引入了一些新的预训练目标,涉及具体的架构变化和不同的输入输出格式,因此,将它们组合在一起以获得更好的性能并扩展到更大的数据并不是一件容易的事。
在这项工作中,我们认为多语言和多模态的预训练本质上实现了相同的目标,即将同一对象的两个不同的视图对齐到一个共同的语义空间。因此,我们认为这两种看似不同的策略可以结合成一个统一的框架。为此,我们引入了跨视图语言建模,这是一个简单有效的框架,将跨语言和跨模态的预训练与共享的架构和目标统一起来。具体地,我们将多模态数据(即,图像-字幕对)和多语言数据(即,平行句子对)视为同一对象的两个不同视图对。使用多模态或多语言数据作为输入,我们使用 Transformer 模型对两个视图进行编码,然后将它们的表示与跨模态和跨语言融合共享的交叉注意力 Transformer 模型融合。我们通过条件掩码语言建模目标、对比学习目标和匹配目标最大化它们之间的互信息,训练模型将两个视图对齐到一个共同的语义空间中。通过这种方式,跨视图语言建模框架无缝地结合了英语枢轴和图像枢轴方案,做到了两全其美。
为了评估我们方法的有效性,我们使用提出的跨视图语言建模框架对 CCLM(一种跨语言跨模式语言模型)进行了预训练。实验结果表明,CCLM在多语言视觉语言理解和检索任务中,在最近发布的多语言多模态基准IGLUE[27]上,在准确率和R@1方面的平均绝对值提高了11.4%和32.7%,大大超过了之前的最先进水平。值得注意的是,CCLM是第一个多语言视觉语言模型,它通过零次跨语言转移超越了单语言视觉语言模型的 "翻译-测试 "性能,我们认为这是迈向实用多语言多模式预训练的关键一步。
不同的可能是中英文吧
Contributions. :(1) 我们提出了一个跨视角的语言建模框架,将多语言和多模式的预训练与共享架构和目标统一起来。(2) 我们在公开的图像-文本对和平行句子对上用所提出的方法对CCLM进行预训练。(3) CCLM在多语言视觉语言预训练方面取得了很大的进步,首次超过了翻译测试基线。
2 相关工作
Multi-lingual Pre-training:
Vision-Language Pre-training:
Multi-lingual Multi-modal Pre-training:
3 Cross-View Language Modeling(跨视角的语言建模)
3.1 Overview(概述)
跨视角语言建模是一个简单的框架,它将跨语言预训练和跨模式预训练统一起来,具有共同的架构和目标。CCLM由一个图像编码器、一个跨语言文本编码器和一个融合模型组成。所有组件都是基于 Transformer 的。具体来说,图像编码器[33]首先将图像分割成不重叠的块,然后将这些块嵌入到transformer层中,产生 {~ vcls, ~ v1, …, ~ vN1}。对于分辨率为 224x224 且块大小为 32x32 的图像,我们有 N1 = 49。类似地,跨语言文本编码器通过变换层对文本输入进行编码,产生 { ~ wcls, ~ w1, …, ~ wN2}。N2是文本输入的长度。然后,融合模型将文本特征与相应的图像特征或基于交叉注意力的翻译文本的特征进行融合,产生{~ xcls, ~ x1, …, ~ xN2}。
如图1所示,以(文本、图像)对或(文本、翻译)对作为输入,我们将成对的输入视为两个不同的视图,并训练模型在一个共同的语义空间中对齐它们的表示。这种统一的跨视图视角使我们能够在跨语言输入和跨模态输入之间共享输入输出格式、架构和训练目标。具体来说,我们完全共享跨语言融合和跨模态融合的融合模型,并通过跨语言和跨模态输入的对比损失、匹配损失和条件掩蔽语言建模损失来优化模型。 我们选择这些目标是因为它们在跨语言和跨模式预训练文献中普遍有效 [19, 34]。我们将证明,这三种损失可以最大限度地提高图像-标题对或平行句子对之间的序列级和标记级的相互信息。另一方面,我们的实验发现,这三种损失对跨语言跨语态预训练的效果要好于某些特定任务的损失,如专门用于多语态预训练的掩蔽区域-表征语言建模或用于多语种预训练的翻译语言建模。
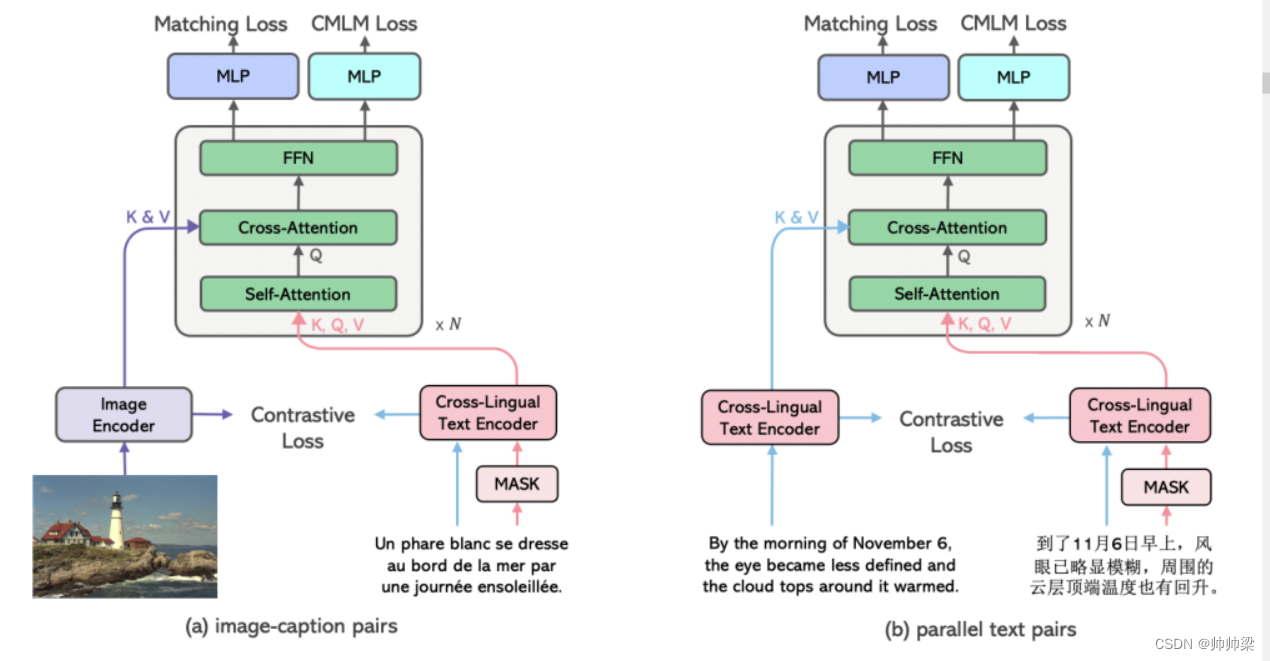
跨视图语言建模框架的图示。CCLM采用同一对象的两种不同视图,即(a)图像标题对或(b)平行句子对作为输入。CCLM首先使用Transformer编码器分别对这两个视图进行编码。然后两个视图的表示通过基于 Transformer 的融合模型进行融合,跨语言和跨模态融合共享该模型。CCLM 通过条件掩码语言建模损失、对比损失和匹配损失最大化两个视图之间的互信息来优化。
3.2 A Mutual Information Maximization Perspective(相互信息最大化视角)
4 Experiment
4.1 Experimental Settings
4.1.1 Pre-training Datasets
Multi-modal Data : 我们在图像-标题对和并行文本的组合上对 CCLM 进行了预训练。对于图像-字幕对,我们遵循 UC2 的做法,并使用他们发布的 CC3M 数据集的翻译增强版本。它包含原始的 CC3M 图像字幕对 [37] 和五种不同语言(德语、法语、捷克语、日语和中文)的机器翻译字幕。除了这个设置,我们还尝试了另一种设置,包括 COCO 数据集 [38] 和视觉基因组 (VG) 数据集 [39],它们总共包含大约 100 万个图像-字幕对。我们之所以考虑这种设置,是因为 COCO 和 VG 数据集通常用于视觉语言预训练文献中,而以前的多语言多模态预训练工作没有使用。我们将使用这两种变体训练的模型分别表示为 CCLM3M 和 CCLM4M。
多语言数据: 至于平行文本语料库,我们收集了 WikiMatrix [40] 数据集的一个子集,其中包含 IGLUE 基准测试中英语和其他语言之间的平行文本。多语言预训练数据总共由 19M 平行句对组成。
4.1.2 Implementation Details
我们通过由 12 个 Transformer 层组成的 Swin Transformer [41] 初始化图像编码器。跨语言文本编码器和融合模型分别用 XLM-R [42] 的前半部分和后半部分初始化,每层由六层组成。图像编码器将分辨率为 224 × 224 的图像作为输入。对于图像-标题对和平行文本,最大序列长度分别设置为 30 和 64。在微调期间,我们将图像分辨率提高到 384 × 384,并按照 Dosovitskiy 等人的方法对图像块的位置嵌入进行插值。 [33]。
我们将混合精度应用于预训练。在 UC2 之后,我们在 8 个 NVIDIA A100 GPU 上训练模型 30 个 epoch,批量大小设置为 1024,任务约 1.5 天。我们使用权重衰减为 0.02 的 AdamW [43] 优化器。学习率在前 2500 个步骤中从 1e-5 升温到 1e-4,并按照线性时间表衰减到 1e-5。预训练在图像字幕批次和并行文本批次之间交替进行。
4.1.3 Downstream Tasks(下游任务)
我们将 CCLM 应用于两个下游数据集,包括 IGLUE 基准,最近发布的用于评估多语言多模态预训练的基准,以及多语言图像文本检索数据集,包括多语言版本的 Flickr30K [44, 45] 和MSCOCO [46]。我们描述下游数据集的细节如下。
Flickr30K:该数据集将 Flickr30K [44] 从英语 (en) 扩展到德语 (de)、法语 (fr) 和捷克语 (cs)。它包含 31,783 张图片,每张图片提供 5 个英语和德语字幕,以及每张法语和捷克语字幕。数据集拆分定义为原始 Flickr30K。
MSCOCO:该数据集通过将字幕翻译成日语 [47] 和中文 [48] 来扩展 MSCOCO 字幕数据集 [46]。日语和中文子集分别由 820k 和 20k 字幕组成。在之前的工作之后,我们对英语和日语使用相同的训练、开发和测试拆分,如 Karpathy 和 Li [49] 中定义的那样。至于中文,我们使用 COCO-CN split [48]。
XVNLI:跨语言视觉 NLI 数据集由 IGLUE 基准测试发布。它是通过将 SNLI [50] 与其多模式 [51] 和多语言 [52] 对应物相结合来收集的。它要求模型预测文本假设是否“包含”、“矛盾”或对图像前提“中立”。
xGQA:通过将 GQA [54] 验证集手动翻译成 7 种语言来收集跨语言接地问答任务 [53]。它需要一个模型来回答关于图像的几种类型的结构化问题。我们将 GQA 建模为 Li 等人的生成任务。 [34]。
xFlickr&CO 和 WIT:xFlickr&CO 数据集是通过组合来自 Flickr30K 和 MSCOCO 的 1000 张图像以及其他 6 种语言的众包图像描述来收集的。同样,基于 Wikipedia 的图像文本数据集 [57] 是从 Wikipedia 收集的 108 种语言。我们遵循 IGLUE 中两个数据集的数据预处理和拆分细节。
**对于所有检索任务,我们应用与 ALBEF [34] 相同的排名策略进行推理。**对于 Flickr30K 和 MSCOCO 上的所有实验,我们在 8 个 GPU 上以 160 的批大小、1e-5 的学习率、0.01 的权重衰减和 0.1 的预热比对模型进行了 10 个 epoch 的微调。我们发现这些超参数在设置、数据集和语言中都能很好地工作。因此,我们不对 Flickr30K 和 MSCOCO 执行任何超参数搜索。对于 IGLUE 数据集,我们在附录的表 5 和表 6 中提供了用于微调的详细超参数。
4.1.4 比较模型
mUNITER 和 xUNITER:由 Liu 等人预训练的 UNITER [23] 模型的多语言变体。 [55]。该模型是通过在一批来自 CC3M 的具有 UNITER 目标的多模态英语数据和一批具有 MLM 目标的纯文本多语言维基百科数据之间交替进行预训练的。 mUNITER 和 xUNITER 的初始化不同:mUNITER 和 xUNITER 是从 mBERT 和 XLM-R 初始化的。
M3P:从 XLM-R 初始化的多语言多模态模型,结合多语言掩蔽语言建模、多模态代码切换掩蔽语言建模、多模态代码切换掩蔽区域建模和多模式预训练-模态代码切换视觉语言匹配。代码转换训练方法允许模型明确地将图像与非英语语言对齐。在每个多模态批次中,图像-文本对被完全用英语或根据给定的采样率使用代码转换的单词提供给模型。与 mUNITER 和 xUNITER 类似,该模型通过交替的多模态和多语言批次进行训练。
UC2:最先进的多语言视觉语言模型,它依靠(纯文本)机器翻译技术来获取五种语言(捷克语、法语、德语、日语和普通话)的 CC3M 数据。然后在多语言多模态批次上对模型进行预训练,其中字幕是从每个图像的可用语言中统一采样的。至于预训练目标。除了传统的视觉语言预训练目标外,还添加了一个视觉条件翻译语言建模目标,以改进多语言多模态对齐。
所有比较的模型都使用来自 CC3M 的多模态数据进行了预训练。 mUNITER、xUNITER 和 M3P 使用不同语言的维基百科数据作为多语言数据,而 UC2 使用 CC3M 的翻译版本作为多语言数据。然后在多语言多模态批次上对模型进行预训练,其中字幕是从每个图像的可用语言中统一采样的。至于预训练目标。除了传统的视觉语言预训练目标外,还添加了一个视觉条件翻译语言建模目标,以改进多语言多模态对齐。
所有比较的模型都使用来自 CC3M 的多模态数据进行了预训练。 mUNITER、xUNITER 和 M3P 使用不同语言的维基百科数据作为多语言数据,而 UC2 使用 CC3M 的翻译版本作为多语言数据。
4.2 Experimental Results
4.2.1 IGLUE 基准测试结果
我们首先在 IGLUE 基准上评估 CCLM。我们遵循 IGLUE 的做法,并报告零样本和少样本跨语言迁移设置的结果。在零样本设置中,在英语训练集上微调的模型直接在目标语言上进行评估。在few-shot设置中,经过英语训练的模型在评估该语言之前,会不断地用目标语言中的一些标记示例进行微调。我们按照 IGLUE 说明选择完全相同的小样本示例,以确保我们的结果与 IGLUE 中报告的结果兼容。结果如表1所示。比较模型的结果是从 IGLUE 复制的。我们省略了对 WIT 数据集的小样本评估,因为在 IGLUE 中也省略了此设置。
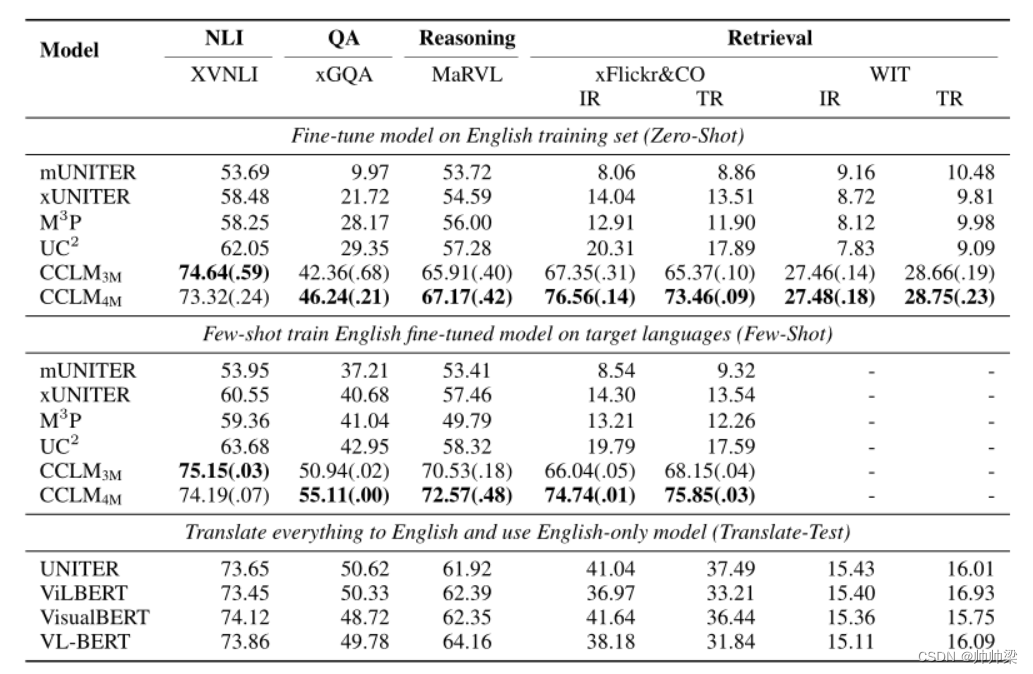
Table 1: Results on IGLUE benchmark. 检索任务(xFlickr&CO 和 WIT)和理解任务(XVNLI、xGQA、MaRVL)分别报告了 R@1 和准确度。对于我们的模型,报告了具有不同随机种子的 3 次不同运行的平均值和标准偏差(括号中)。比较模型的结果直接从 IGLUE 基准中复制而来。
首先,对于零样本跨语言迁移结果,我们可以看到 CCLM3M 在相同的多模态数据上进行预训练时,性能明显优于所有比较模型。具体来说,与之前的state-of-the-art UC2相比,CCLM3M在包括XVNLI、xGQA和MaRVL在内的多语言多模态理解任务上的平均准确率提高了11.4%,平均R@1提高了在包括 xFlickr&CO 和 WIT 在内的多语言多模态检索数据集上分别占 47.3% 和 18.2%。这证实了以前的多语言多模态模型未能充分发挥多语言多模态预训练的潜力,我们提出的跨视图语言建模框架可以更好地将多语言多模态表示与统一目标对齐。我们还发现通过添加 COCO 和 VG 数据可以进一步提高性能(CCLM4M),这些数据用于预训练大多数英语 VLM。值得注意的是,CCLM 是第一个多语言多模态预训练模型,其性能与在 IGLUE 基准测试中测试的代表性英语 VLM 的翻译测试结果具有竞争力。具体而言,CCLM4M 在 XVNLI、MaRVL、xFlickr&CO 和 WIT 的 IGLUE 基准测试中优于所有具有代表性的英语 VLM 的翻译测试结果,而在 xGQA 数据集上的表现略差。这首次证明了多语言多模式预训练在构建涉及不同语言的视觉语言任务的实际应用程序方面的潜力。
至于少样本结果,我们发现与现有模型类似,CCLM 也可以通过目标语言中的一些示例从少样本学习中受益。通过以目标语言对每个班级的几个示例进行训练,CCLM 始终以更大的优势优于英语 VLM 的翻译测试结果。这进一步证实了多语言多模态预训练的潜力。
4.2.2 Results on Multi-lingual Retrieval(多语言检索结果)
我们还将 CCLM 与传统图像检索和文本检索任务上的最先进方法进行比较,UC2 和 M3P 最初报告了它们的结果。我们遵循先前工作的实践并在三种不同的设置中进行评估,包括仅英语微调、单语言微调和全语言微调,其中模型在英语数据、目标语言数据上进行微调,以及所有语言的训练数据的组合,分别。
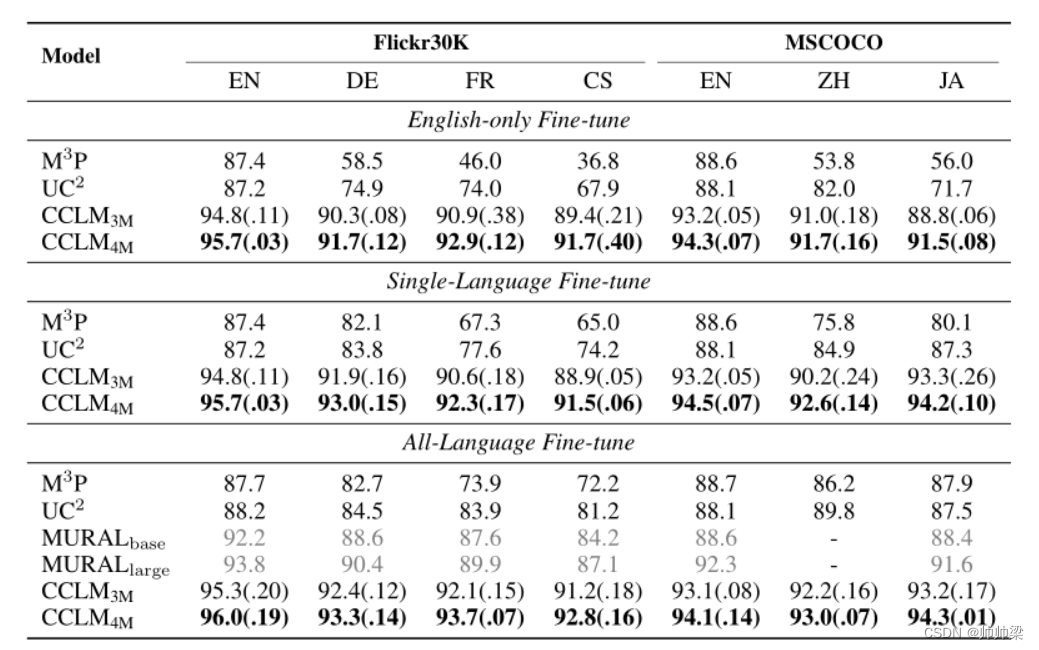
结果如表 2 所示。对于零样本跨语言迁移,我们可以看到 CCLM3M 的性能也大大优于之前的最先进技术 UC2,平均提高了 16% 以上(就平均召回而言) 跨越五种语言。这证实了我们的方法可以更好地对齐多语言多模态表示。包括 COCO 和 VG 数据也产生了一些改进,这与 IGLUE 基准上的先前结果一致。对目标语言或所有语言的组合进行微调会产生一致的改进。改进不如 UC2 和 M3P 大,这可能是因为 CCLM 的零样本跨语言迁移能力足够强,我们模型的性能已经饱和。(不微调效果也不错)
尽管如此,CCLM3M在对目标语言或所有语言的组合进行微调时,仍然大大超过了先前的最先进水平,在五种语言中平均召回率分别为9.4%和6.8%。此外,CCLM4M在所有语言的微调设置中也明显优于先前最先进的MURALlarge,四种语言的平均召回率为3.8%。这是值得注意的,因为MURALlarge比我们的模型大,而且在更多的数据上进行了预训练(450倍的图像-文本对和390倍的平行句子对)。此外,我们在表7中显示,CCLM在0-shot设置中也优于MURALlarge(不含微调)。
4.2.3 Cross-lingual Transfer Gap(跨语言转移的差距)
除了绝对的跨语言迁移结果外,我们还比较了不同模型的跨语言迁移差距。我们将模型在非英语语言上的性能与其在英语测试集上的性能的比率可视化,如图2所示。
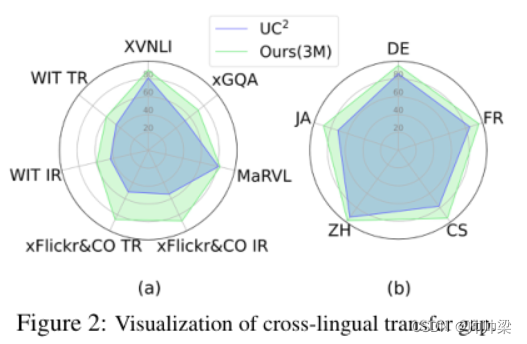
图2:跨语言迁移差距的可视化
雷达聊天记录越大,表明该模型的相对转移差距越小,可以更好地将其性能转移到非英语测试集。我们可以看到,在IGLUE基准的所有任务(a)和多语言检索数据集的所有语言(b)中,CCLM的相对跨语言转移差距始终小于UC2。绝对的跨语言转移差距甚至更为显著。例如,在表2中,我们可以看到,对于M3P,在Flickr30K和MSCOCO中,EN-CS和EN-JA之间的绝对零次跨语言转移差距分别为41.4%和32.6%。这表明,对多语言中未配对的文本进行屏蔽式语言建模对多模式模型的跨语言对齐不是很有效。UC2的差距减少到13.2%和16.4%,证明了使用机器翻译的字幕进行多语言多模式预训练的有效性。令人惊讶的是,CCLM4M进一步将这一差距降低到4%和2.8%。这进一步证实了所提出的跨视角语言建模框架能够有效地将多模态表征从英语转移到其他语言,而不需要进行特定语言的微调。
此外,我们还在图3中可视化了CCLM和基线方法中的多语言文本表示和图像表示,这清楚地表明我们的方法可以更好地对齐多语言图像-文本表示。同样值得注意的是,跨语言转移能力的提高并没有牺牲该模型在英语上的表现。 在表8中,我们可以看到CCLM在有代表性的英语视觉语言任务上的表现与最先进的英语VLM相比具有竞争力。为了完整起见,我们还在表9、10、11、12和13中报告了IGLUE基准的每种语言的结果。关于这些分析和结果,请参考附录。
4.3 Ablation Study
我们还进行了深入的消融研究,以调查不同设计选择在跨视图语言建模框架中的作用。我们预训练了 5 个消融的 CCLM 变体,其中消融了平行句对、统一架构或统一目标。所有比较的模型都使用相同的 CC3M 和 WikiMatrix 数据(除了没有平行句对)进行了 15 个 epoch 的预训练,以确保公平比较。结果如表 3 所示。首先,我们发现跨语言和跨模态融合模型中的交叉注意力和 FFN 模块的单独参数化导致结果较差,特别是对于多语言多模态理解任务,例如xGQA。我们还发现,在多语言预训练文献中使用与多模式目标不同的共同目标不如我们方法中使用的统一目标。这些观察证实了跨视图语言建模框架中统一架构和目标的重要性。此外,我们发现平行句对的使用也起着非常重要的作用。这表明以前的方法未能充分利用语言枢轴进行多语言多模态预训练的潜力。
5 Conclusion
在本文中,我们介绍了跨视图语言建模,这是一个简单而有效的框架,它统一了跨语言和跨模态的预训练。它将跨语言和跨模态预训练视为对齐同一对象的两个不同视图的表示的相同过程,从而使用共享模型架构和训练目标进行多语言多模态预训练。我们使用所提出的框架训练 CCLM,并表明它在所有下游多语言视觉语言任务上大幅提升了最新技术水平。更重要的是,它首次超越了 translate-test 基线,展示了多语言多模态预训练的潜力。我们相信我们的模型将成为未来多语言多模式研究的基础,并作为强大的基线。此外,跨视图语言建模框架还具有统一具有相同架构和目标的语音和视频等更多模态的潜力。我们把它留给未来的工作。