Training Vision Transformers for Image Retrieval 论文笔记
文章目录
概述
要明白这篇论文在讲什么,首先不可少的就是对Transformers的了解,知道为什么本文要把它用于图像检索领域,以及它天然的优势和成功的基础。
作者为什么写这篇文章
Transformers早年常用NLP领域,近来发现用于图像分类也挺好,决定试试行不行。
动手去干
作者提出了一种基于transformer的图像检索方法:采用视觉transformers生成图像描述符,并用一个度量学习到的目标训练得到的模型(这个目标结合了对比损失和微分熵正则化器)。
说人话就是先把View Transformer直接拿来用,在这个基础上微调,也就是再加一个常见的Loss,最后再前两步上搞一个正则化,三种方法都去做个实验。
功夫不负有心人
作者实验得到结论:与之前业界常用的基于卷积的方法相比,把transformers用于图像检索:NB!可行!非常强!
夸夸作者
正如原文所述,贡献巨大:
“
(1) 提出了一种简单的方法来训练视觉transformer(既可以用于基于类别的检索,也可以用于特定对象的检索),与具有相似容量的卷积模型相比,性能更好。
(2) 对于Category-level检索——在即Stanford Online Product、In-Shop和CUB-200这三个数据集上性能出色
(3) 对于特定的对象检索——在ROxford和RParis上的消融实验也表明,transformers与卷积网络在更高分辨率和更高频率下的结果相当,尤其是对于短矢量表示(128个分量)。
(4) 证明了微分熵正则化器增强了对比度损失,提高了整体性能。 ”
结构速览
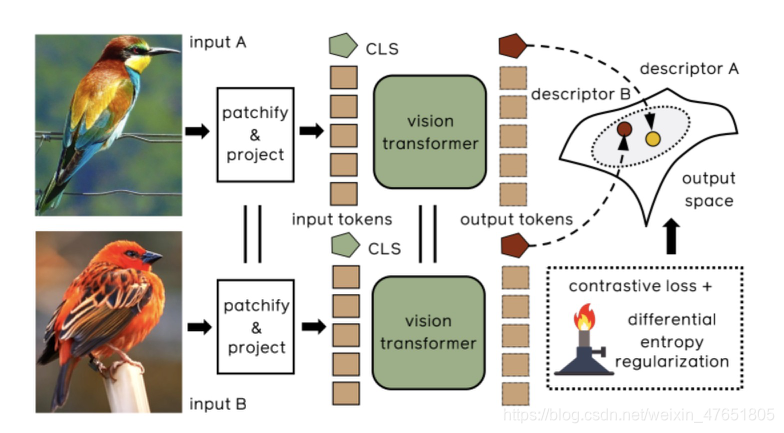
如上图所示,本文训练了一个带有Siamese 结构的transformer模型用于图像检索。两幅输入图像由transforme映射到一个公共特征空间。在训练时,由于采用了一个熵正则化器( entropy regularizer)从而对比度损失被增强了。
一、补补知识
1.1 介绍
理论基础:在计算机视觉中,学习相似性度量有许多直接的应用,如基于内容的图像检索、人脸识别和person再识别等。
研究意义:这是一个有趣的发展,因为与目前占主导地位的卷积结构相比,基于Transformers的计算机模型具有不同的感应偏差
1.2 Transformers
重要作用:有记忆功能!!!常用于预训练。
大致了解一下Transformers的结构。
输入是一串向量序列(默认列向量),然后每一层都是经过多头注意力神经网络(其最关键作用是解决长距离依赖问题)生成一个与原来长度一致新的序列。NLP中把每一个词都用一个向量来表示,然后对于每一个词所对应的向量,都有一个可以被学习的向量(也就是在反向传播过程中可以被更新的向量)来决定他要注意这个序列中的哪一个向量,从而能够依赖上下文信息。
Transformer会在输入序列的开头添加一个特殊的CLS标记,CLS标记对应的输出向量将会由所有输入向量及CLS对它们的注意力权重决定,所以能代表整个输入序列的表示。
1.3 Siamese结构
本文算法用到了Siamese结构。正如他的字面意思那样,Siamese network可以看作:“连体的神经网络”,通过共享权重来实现网络之间的连接。
二、算法细节
之前对于类别级检索和特定对象检索,这两大任务是通过不同的技术来处理的。而本文对这两个问题都使用了相同的方法。
下面逐步介绍它不同的组成部分:

- O:从视觉Transformers主干网络中直接进行特征的提取,在ImageNet上预训练
- L:使用度量学习对Transformers进行微调,特别是使用对比损失
- R:正则化输出特征空间
先验知识:了解什么是view transformer。
ViT架构:首先将输入图像分解为M个固定大小的面片(如16×16)。每个面片被线性地投影成M个向量形状的标记,并以排列不变的方式作为transformer的输入。通过向输入标记中添加一个可学习的1-D位置编码向量来合并先前的位置。另外,再添加一个可学习CLS到输入序列中,使得其相应的输出用作全局图像表示。
transformer由L层组成,每个层由两个主要模块组成:多头自我注意(MSA)层,将自我注意操作应用于输入标记的不同投影,以及前馈网络(FFN)。
本文选择使用Touvron等人(2020)引入的ViT架构的DeiT-Small的变体作为基本模型。
2.1 IRT-O:给transformer准备好的特征
- 直接从ImageNet上预训练的transformer中提取特征
- ViT体系结构中,预分类层输出M+1向量,对应于M个输入块和一个CLS嵌入到同一个空间上
- 并通过PCA进行降维,减少运算量,减少过拟合
这里使用了l2层的normalization和降维操作,normalization的实质是把一部分不是很重要的复杂信息损失掉,以此达到降低拟合难度,在transformer模型中,常常使用 layer normalization,其目的就是可以有效降低模型方差,避免模型过拟合,加速模型收敛。
2.2 IRT-L:对于图像检索的度量学习
度量学习也叫作相似度学习,顾名思义,在用于图像检索时,可通过比较两张图片的相似度来判别它们是否是相同的物体,相似度越大,检索成功的概率越高。
本文采用了之前提出的交叉批处理记忆得到的对比损失,并令margin β = 0.5作为我们的度量学习目标。
文中作者在批次大小为N的时候,把对比损失定义为下:
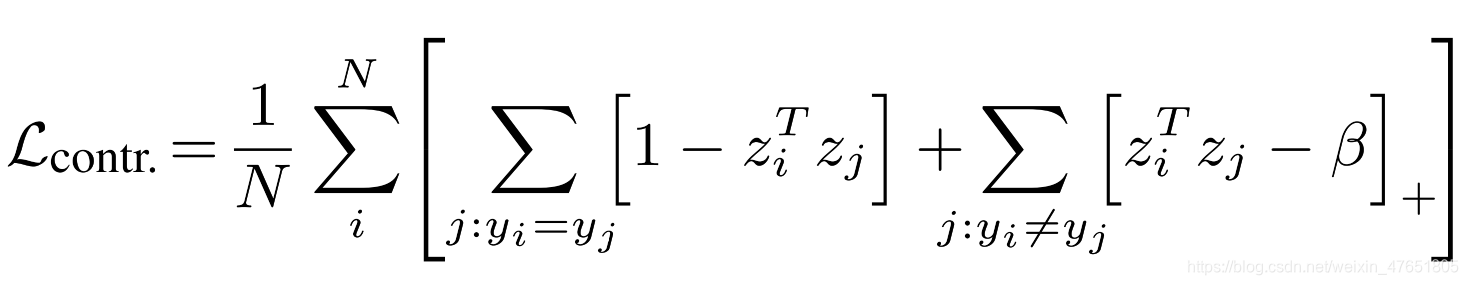
zi: 样本的编码低维表示(经过了L2层的normalization)
yi: 与zi相对应地样本的标签
对比损失最大化了zi与yi之间的相似性,其目的就是使同类样本更加靠近,负样本限制在margin外
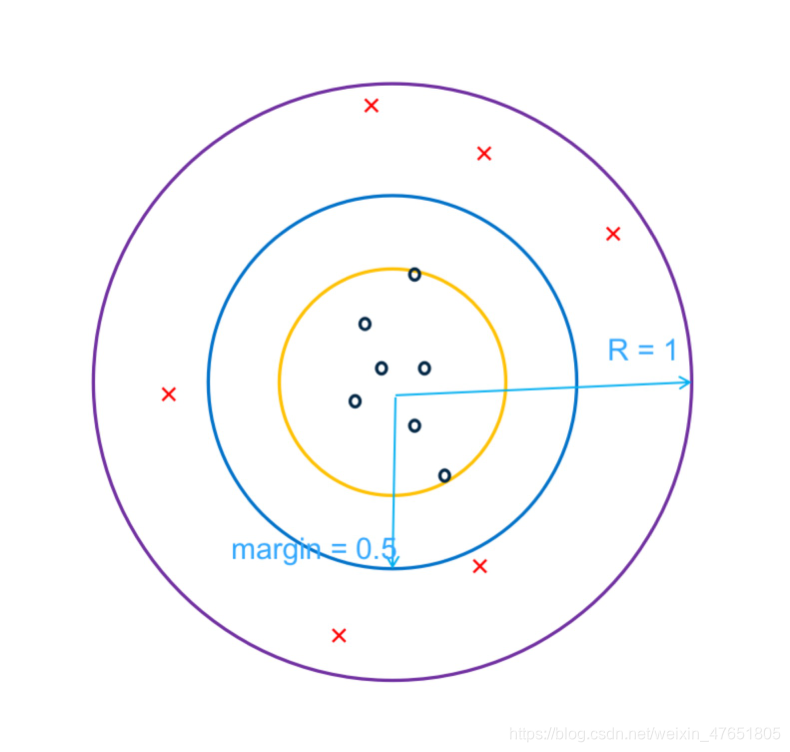
下图帮助更好的理解margin的含义:
2.3 IRT-R


2.4 分析
三、实验结果
首先描述数据集和实现细节,然后继续讨论实际得到的结果。
3.1 数据集
3.1.1 Category-level Retrieval
这里用到了3种常用数据集:
1.) Stanford Online Products (SOP)
最初是为调查度量学习问题而收集的。由网上销售的产品图片来代表 22634类别。本文先使用11,318个类别进行训练,剩下的11316种类别用于测试。
2.) CUB-200-2011
该数据集由加州理工学院在2010年提出的细粒度数据集,是目前细粒度分类识别研究的基准图像数据集。该数据集共有11788张鸟类图像,包含200类鸟类子类。
3.) In-Shop
这个是卖家秀图片集,每个商品id,有多张不同角度的卖家秀,放在同一个文件夹内
本文计算了Recall@K 评价指标,与以前的方法有一个直观的比较。
3.1.2 Particular Object Retrieval
-
训练阶段
SFM120k数据集:该数据集是通过将结构从运动和三维重建应用于大型未标记图像集合而获得的。正样本被选来以便与查询图像共同观察足够的3D Points,而负样本来自不同的3D模型。我们使用551个3D模型进行训练,162个用于验证。 -
评估阶段
本文使用牛津和巴黎数据集的revisited基准报告结果。这两个数据集分别包含70个描述建筑物的查询图像,另外还分别包含4993和6322个图像,其中可能出现相同的查询建筑物。revisited的基准测试包含3个部分:Easy(E)、Medium(M)和Hard(H),逐渐按查询/数据库对的难度分组。
3.2 实验细节
- Category-level Retrieval
使用AdamW优化器对所有模型进行优化,学习率为3.105,重量衰减为5.104,批量大小为64。对于所有实验,除非另有说明,否则对比损失率设置为β=0.5,熵正则化强度设置为λ=0.7。使用标准的数据增强方法,将图像大小调整为256×256,然后结合随机水平翻转随机裁剪为224×224。 - Particular Object Retrieval
每batch由5个元组组成(1个锚定,1个正样本,5个负样本)。对于每一代,我们随机选择2000个正样本对和22000个负样本候选(使用困难负样本挖掘)。β = 0.85,经过100代的训练进行模型的微调。
3.3 结果
-
Category-level Retrieval:
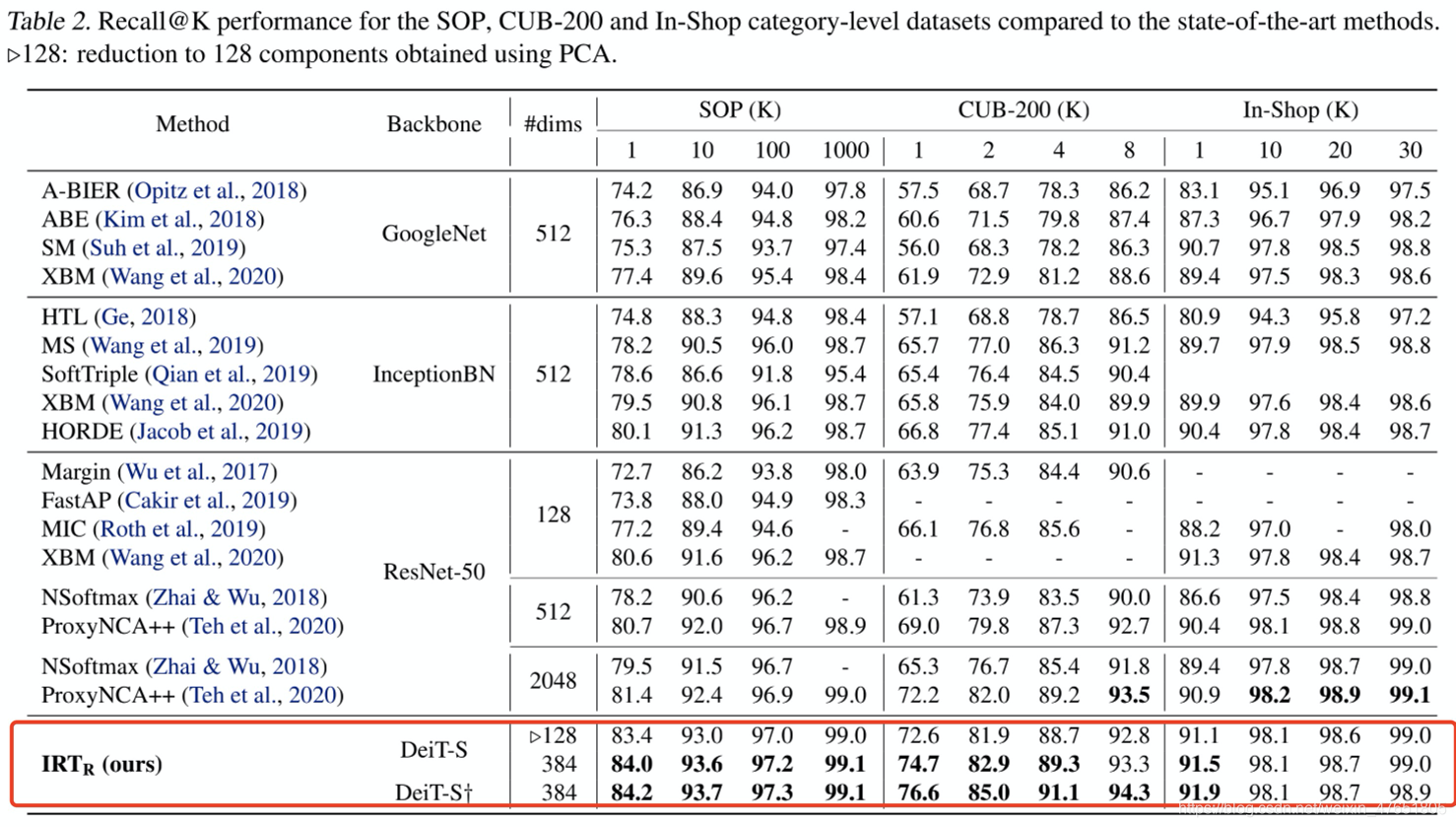
上表可知,本文使用的IRT-R算法在这三个数据集上的实验指标recall@k(k=1,10,100,1000)都取得了较好的结果。Top1上均取得了SOTA。尤其是在SOP上,无论k取这四个值的哪一个,指标都达到了SOTA。 -
Particular Object Retrieval:
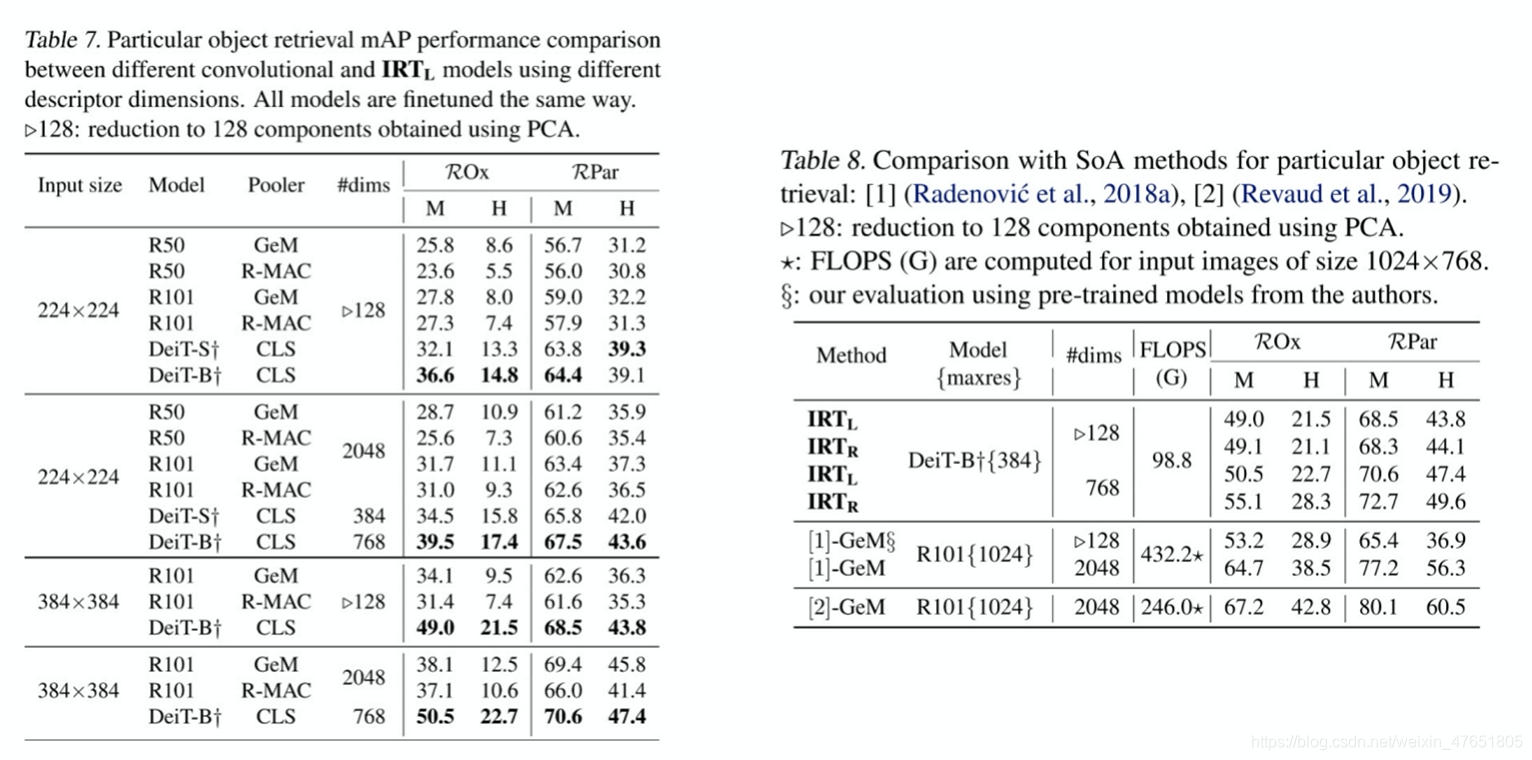
3.4 消融实验
-
不同的监督方法
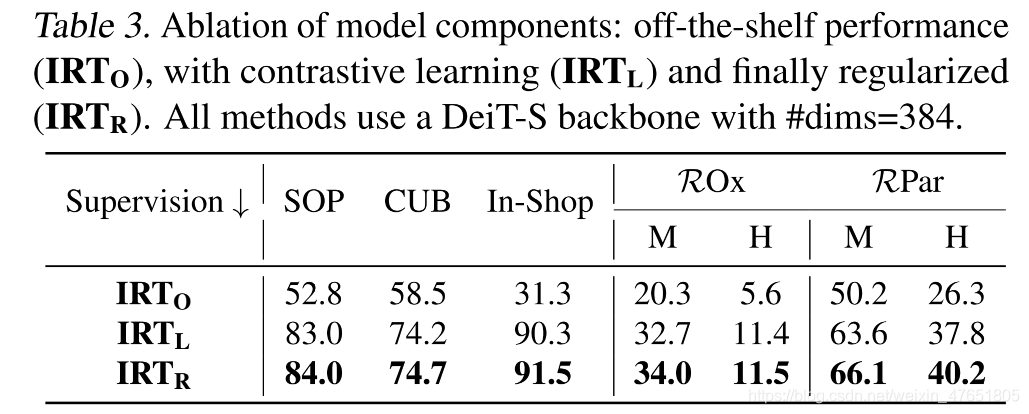
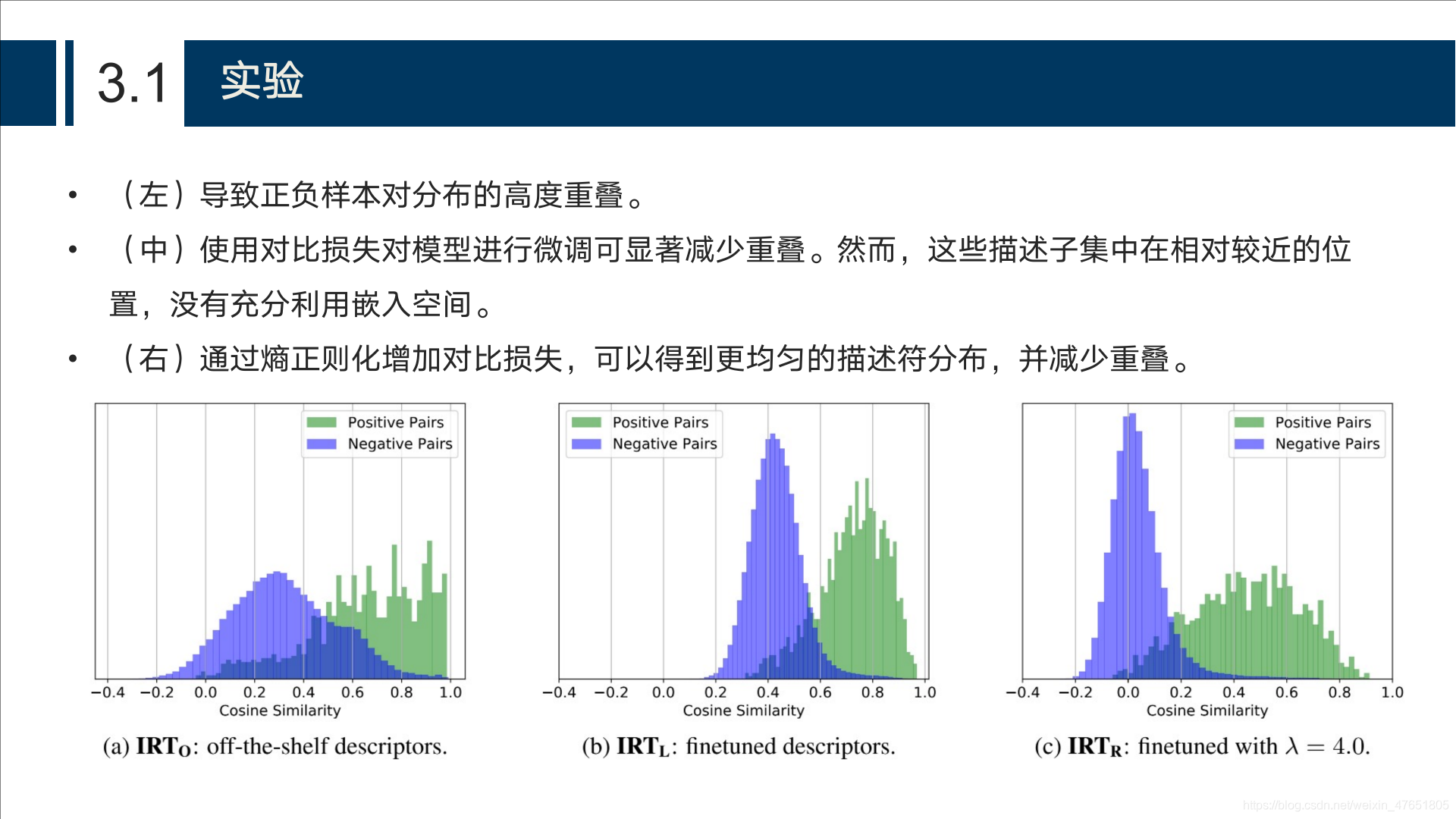
-
特征提取器的选择:池化方法
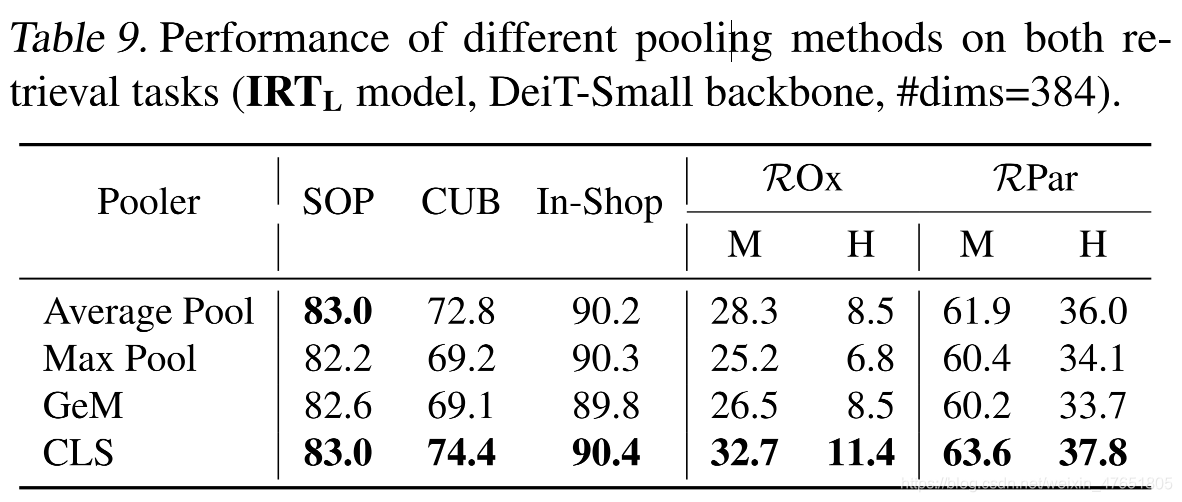
-
跨目标函数的绩效
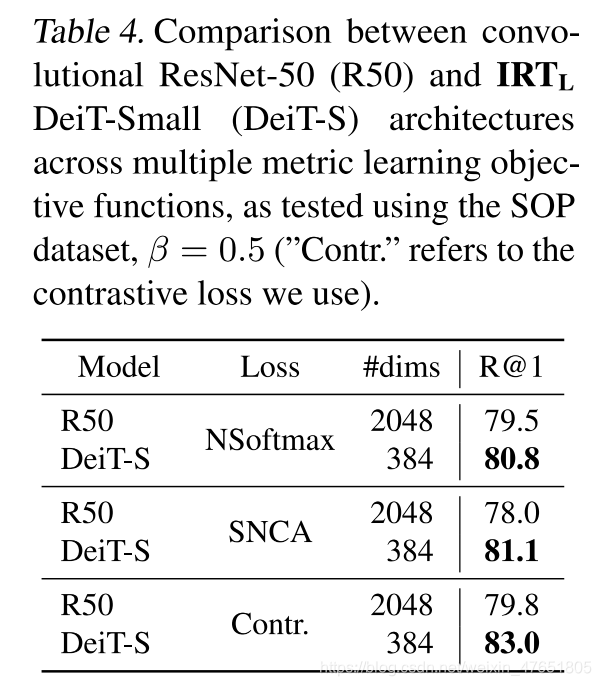
-
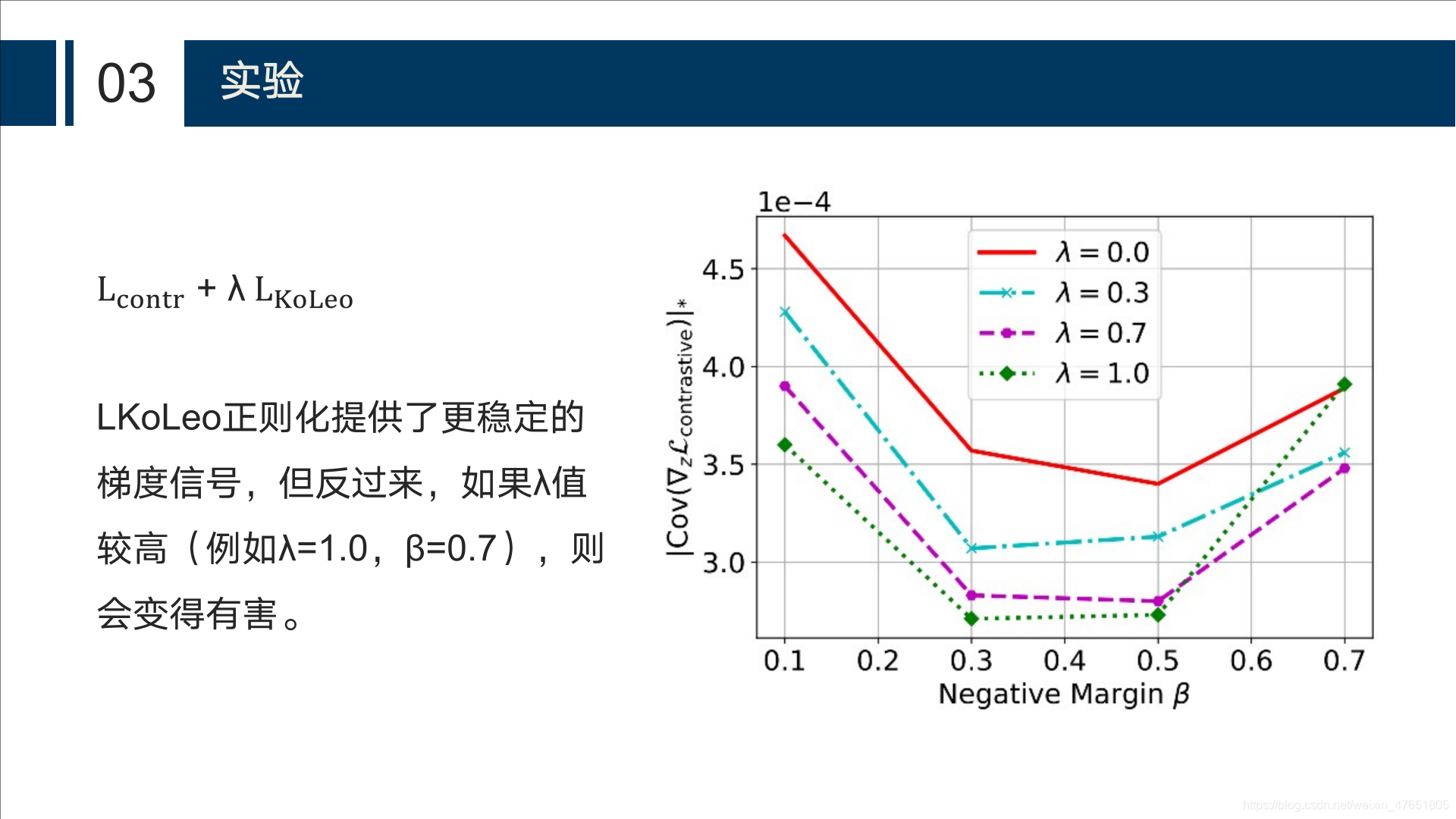
正则化超参数λ
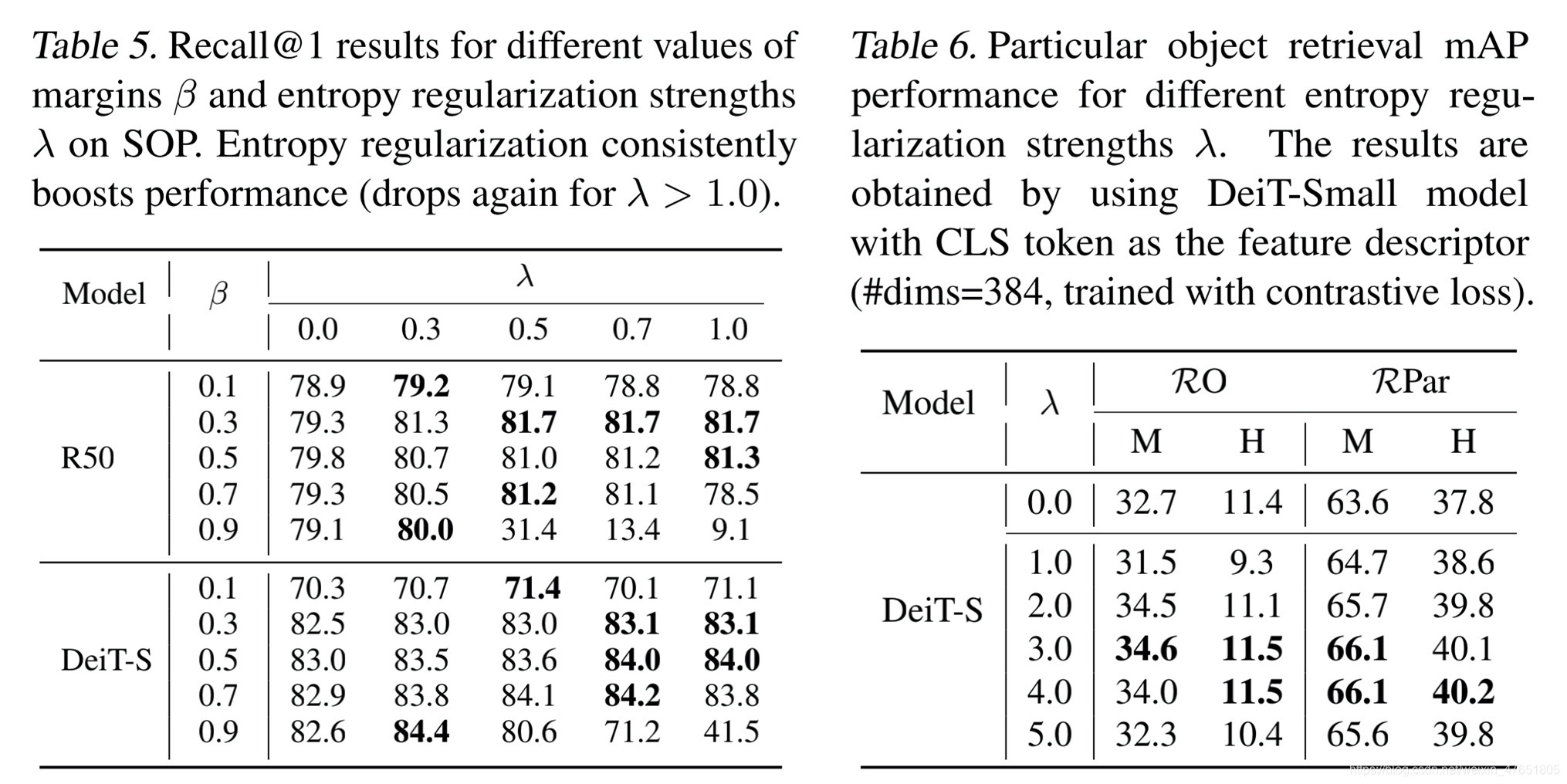
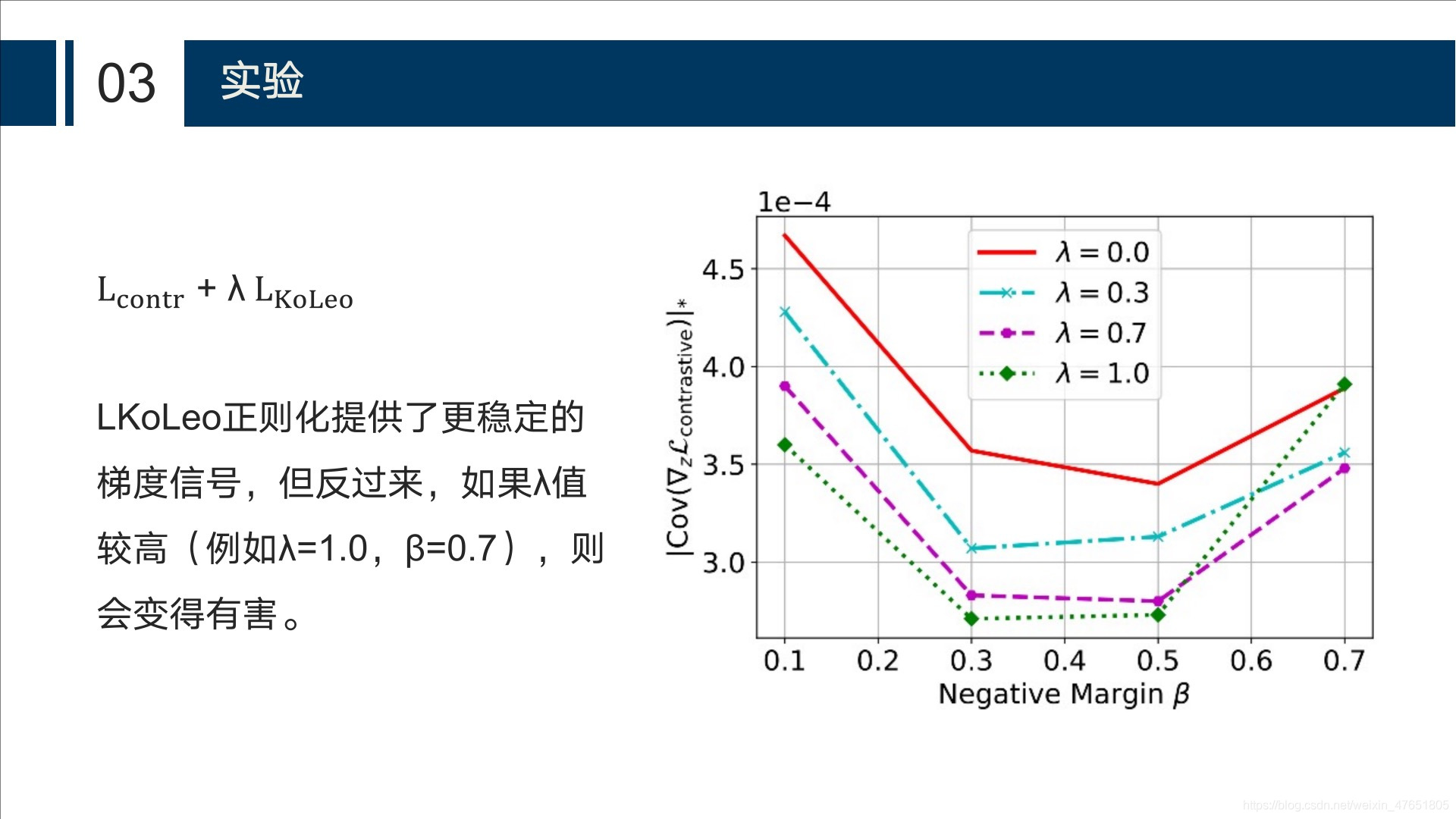
四、结论
本文主要研究的是如何使transformer架构适应度量学习和图像检索。
- 重新讨论了对比损失公式,并表示:与卷积模型类似,
基于单位超球面上/微分熵损失扩展向量的正则化器改善了基于transformer模型的性能。从而开创了分类级图像检索的新局面。 - 证明了
对于特定对象检索,在可用于比较的设定下,基于transformer的模型是卷积主干的一个有效替代方法,特别是对于短向量表示。与复杂度更高的卷积网络相比,它们的性能更具竞争力。