Cross-domain Image Retrieval with a DualAttribute-aware Ranking Network (2015)
######### 总结 ##############
1. 处理跨域数据集,使用两分支网络结构,消除online和offline数据集间的差异。
2. 处理细粒度特征,使用的是树状结构内嵌fc结构语义学习的方式。powerful semantic representation
处理细粒度特征,这一步同时也涉及到关键地标的定位。作者使用了在分支网络中嵌入树状网络结构(Tree-structure layers)组合属性和彼此的关系的方法。Wedesign tree-structure layers to comprehensively capture the attributeinformation and their full relations
|||||||||||||||||| 作者有话说(*观点*) |||||||||||||||||||||||||||||||||||||||
1. retrieval featurerepresentations are driven by semantic attribute learning. We show that thisattribute-guided learning is a key factor for retrieval accuracy improvement.
即,属性检索识别不仅是有用的,而且是必要的
2. to further align with thenature of the retrieval problem, we impose a triplet visual similarityconstraint for learning to rank across the two sub- networks.
即,triplet在本文中是用于消弭不同数据集间特征差异,抓住关键特征
3. 这一点更多是应该是观察,其效果不太确定,Similar to[A deep convolutional activation feature for generic visual recognition], wefound that the response of FC1 layer, i.e., the first fully connected layer,achieves the best retrieval result.
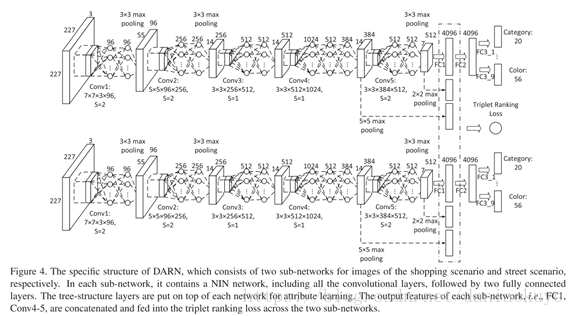
总体的网络结构
1) 总体上是两个分支,一个分支接收一个数据集,在分支顶部会产生可以比较的信息。
2) 然后分支中主要是卷积结构,第四个卷积层后面跟NIN中介绍的MLPConv,就是卷积模板跟堆叠的FC。然后总体上再跟两个FC。
3) 再在分支结构的顶部,加入树结构的FC层,对语义信息进行编码
4) Triplet-based ranking loss 可以增加特征的可区分度,去除并非真正起作用的特征,separates the dissimilar images with a fixed margin——这个总体类似于SVM的目标函数,事实上也确实是这样:Loss(a, b, c)= max(0,m+dist(a, b)−dist(a, c)),其中a:offline,b:online same,c:onlinedissimilar。
5) 此外,FC1编码的更多是全局的特征,会丢失小的局部特征。作者的方法是除FC1外同时考虑卷积层,使用max-pooling对靠前的卷积特征层下采样,类似于roi-pooling的形式。然后结果与全局特征组合在一起。
6) DARN是衣物检索的网络,在应用该网络之前,需要把人体衣物检测并裁剪出来。使用的是Rcnn,用来识别并将衣物裁剪出来
结果:
Online的图片检索效果好于offline的图片。