用于跨语言传输的可组合稀疏微调
Abstract
对大型预训练模型的整个参数进行微调已成为迁移学习的主流方法。为了提高效率并防止灾难性的遗忘和干扰,已经开发了适配器和稀疏微调等技术。适配器是模块化的,因为它们可以组合以使模型适应知识的不同方面(例如,专用语言和/或任务适配器)。(每一个模块负责一个功能,然后组合起来)。稀疏微调具有表现力,因为它控制所有模型组件的行为。
在这项工作中,我们介绍了一种具有这两种理想特性的新微调方法。特别是,我们学习了基于Lottery Ticket Hypothesis的一个简单变体的稀疏实值掩码。特定于任务的掩码来自源语言中的注释数据,特定于语言的掩码来自目标语言中的掩码语言建模。然后,这两个掩码都可以与预训练模型组成。与基于适配器的微调不同,这种方法既不会增加推理时的参数数量,也不会改变原始模型架构。
最重要的是,在包括 Universal Dependencies、MasakhaNER 和 AmericasNLI 在内的一系列多语言基准测试中,它在零样本跨语言迁移方面的表现大大优于适配器。基于深入分析,我们还发现稀疏性对于防止 1)要组合的微调之间的干扰和 2)过拟合至关重要。
我们在发布代码和模型 https://github.com/cambridgeltl/composable-sft.
1 简介
预训练模型的微调(Howard和Ruder,2018;Devlin等人,2019)可以说是目前NLP的主导范式。最初,“微调”涉及在未标记文本上预训练模型的所有参数的监督学习。然而,鉴于基于 Transformer 的架构的规模,这种方法通常在时间和资源上效率低下,并且可能在多次适应期间导致灾难性的遗忘和干扰(Wang 等人,2020)。为了克服这些限制,出现了两种主要的替代方案:1)通过适配器,可以将新参数以额外中间层的形式添加到预训练模型中(Rebuffi 等人,2017;Houlsby 等人,2019)和精细在保持所有预训练参数固定的同时进行调整; 2) 一小部分预训练模型参数的稀疏微调 (SFT)(Guo 等人,2021;Zaken 等人,2021;Xu 等人,2021b 等)。
适配器已被证明在多语言 NLP 中特别有用(Bapna 和 Firat,2019;Üstün 等人,2020;Pfeiffer 等人,2020b;Vidoni 等人,2020;Pfeiffer 等人,2021b;Ansell 等人,2021)因为它们表现出惊人的模块化程度。这种以原始方式分离和重组知识正交方面的能力(Ponti 等人,2021;Ponti,2021)允许从源语言中的标记数据中分别学习任务适配器,并从源语言中的未标记数据中学习专用语言适配器和目标语言。 (标记的学习针对任务的适配特征,未标记的学习针对语言的专用特征)
通过堆叠这些组件,可以执行zero-shot跨语言迁移。与在任务和目标语言上依次微调完整模型相比,这产生了更好的性能和效率(Pfeiffer等人,2020b)。值得注意的是,使用顺序方法来实现覆盖NL目标语言中的NT任务需要训练NT*NL模型,而适配器的模块化将这减少到NT + NL。(也就是传统的方法需要的训练数据量大,适配器模块化比较少,很容易理解)
同时,与适配器相比,SFTs(稀疏微调) 的优势在于它们的表达能力:它们可以直接操作预先训练的模型的嵌入层和注意层,而不是对Transformer层的输出进行非线性转换(例如,与适配器一样使用浅MLP)。因此,寻找一种既模块化又富有表现力的参数高效的微调方法似乎是很自然的。
为此,我们提出了Lottery Ticket Sparse Fine-Tuning (LT-SFT),这是一种受彩票假设(LTH;Frankle and Carbin,2019;Malach et al.,2020)启发的简单而通用的自适应技术,最初是为了修剪大型神经网络而设计的。特别是,在为特定任务或语言微调预训练模型后,我们选择变化最大的参数子集。然后,我们将模型倒回到其预训练的初始化状态(与原来的LTH算法相反,没有将任何值设置为零)。通过仅重新调整选定的参数子集,我们可以获得相对于预训练模型的以差异向量形式进行的稀疏微调。只需将多个SFT与预训练模型相加,即可组成Multiple SFTs。我们在图1中提供了方法的图形表示。
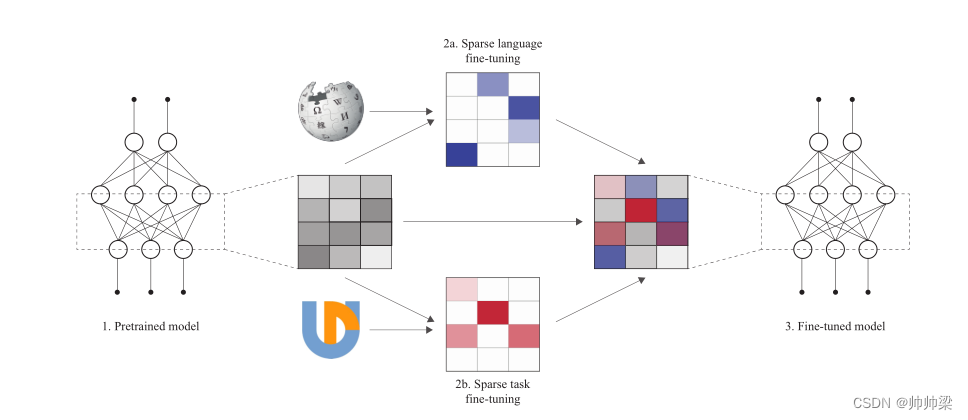
图1:彩票稀疏微调的图形表示:根据预训练模型的参数(灰色,左侧),我们生成任务和语言知识的稀疏微调(蓝色和红色,中间)。最后,我们将这三个组成部分(右)相加,以获得经过调整/微调的模型。以彩色显示效果最佳。
我们在一系列多语言数据集上对 LT-SFT 进行了基准测试,包括用于词性标注和依赖解析的 Universal Dependencies (Zeman et al., 2020)、用于命名实体识别的 MasakhaNER (Adelani et al., 2021) 和 AmericasNLI (Ebrahimi et al., 2021) 用于自然语言推理。我们在 35 种类型和地理上不同的语言的零样本跨语言迁移设置中对其进行评估,其中包括在预训练模型的掩码语言建模期间看到和未看到的语言。所有迁移任务的结果表明,与当前最先进的基于适配器的跨语言迁移方法 MAD-X(Pfeiffer 等人,2020b)相比,LT-SFT 始终取得可观的收益。
除了其卓越的性能、模块化和表达性之外,LT-SFT 还提供了一系列优于适配器的额外优势:1)参数数量保持不变,这可以防止添加适配器层时观察到的推理速度下降; 2) 神经架构与预训练模型保持一致,这使得代码开发模型独立于模型,而不需要对每种可能的架构进行特殊修改(Pfeiffer 等人,2020a)。最后,3) 我们凭经验证明 LT-SFT 的性能峰值始终存在于相同百分比的可调参数下,而 MAD-X 的最佳缩减因子取决于任务。这使得我们的方法对超参数的选择更加稳健。
此外,我们发现语言和任务微调的高度稀疏性有利于性能,因为这使得重叠的可能性降低,并且在它们包含的知识之间产生干扰的风险较低。此外,由于容量受限,它使微调不太容易过度拟合。因此,稀疏性是实现模块化和可组合性的基本要素。这些属性反过来允许以零样本方式系统地泛化到任务和语言的新组合。
2 Background
为了为我们的研究建立一个更广泛的背景,我们首先简要概述了当前高效微调的方法,如适配器和SFT。然后,我们重述彩票假设,我们新提出的方法就是在此基础上构建的。
适配器和组成 :适配器是插入Transformer模型的组件,其目的是针对特定的语言、任务、领域或形态对其进行专门化(Houlsby等人,2019年)。(感觉这里的意思就是专家的意思) 以前在多语言 NLP 方面的工作主要采用了 Pfeiffer 等人的轻量级但有效的适配器变体。 (2021a)。在此设置中,在前馈子层之后,每个 Transformer 层仅注入一个适配器模块,由连续的向下投影和向上投影组成。第 b 个 Transformer 层的适配器 A b A_b Ab 执行以下操作:
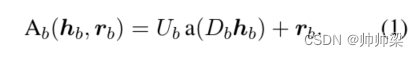
h b h_b hb 和 r b r_b rb 分别是 Transformer 隐藏状态和 b 层的残差。
D b ∈ R m × h D_b ∈ R^{m×h} Db∈Rm×h 和 U b ∈ R h × m U_b ∈ R^{h×m} Ub∈Rh×m 分别是向下和向上投影(h 是 Transformer 的隐藏层大小,m 是适配器的维度),a(·) 是非线性激活函数。残差连接 r b r_b rb 是 Transformer 前馈层的输出,而 h b h_b hb 是后续层归一化的输出。在使用适配器对预训练模型进行微调期间,只有适配器参数 U 和 D 被修改,而预训练模型的参数保持固定。
在用于跨语言迁移的 MAD-X 适配器组合框架(Pfeiffer 等人,2020b)中,通过掩码语言建模(MLM)为每种源语言和目标语言学习用于大规模多语言 Transformer(MMT)的语言适配器(LA) ),并且为每个目标任务学习一个任务适配器 (TA),其中源语言的 LA 在 TA 训练期间插入。(意思就是 一个学习语言无关的知识,并且每一种语言有一个专家,在每种语言单独训练时,插入之前训练的总语言无关的适配器LA,学习两种语言的迁移??)
在推理时,任务适配器和目标语言适配器是通过将一个堆叠在另一个之上而组成的。这种适配器组合方法已被证明对跨语言迁移非常有效(Pfeiffer et al., 2020b, 2021b; Ansell et al., 2021),特别是对于 MMT 预训练期间看不到的低资源语言和目标语言。(堆叠拼接而成的)
Sparse Fine-Tuning.(稀疏微调): 如果 φ 是稀疏的,我们将 F ′ = F ( ⋅ ; θ + φ ) F' = F (·; θ + φ) F′=F(⋅;θ+φ) 称为预训练神经模型 F (·; θ) 的稀疏微调 (SFT)。我们有时将 φ 本身称为 SFT,或称为 SFT 的差异向量。
先前提出的 SFT 方法包括 DiffPruning (Guo et al., 2021)、BitFit (Zaken et al., 2021) 和 ChildTuning (Xu et al., 2021b)。DiffPruning 通过对其应用二进制掩码的连续松弛来模拟训练期间差异向量的稀疏性。另一方面,BitFit 仅允许偏差参数的非零差异。ChildTuning 通过使用 Fisher 信息来选择微调参数的子集,以测量每个参数与任务的相关性。尽管差异向量 φ 的非零值少于 0.5%,但这些方法已被证明与 GLUE 上的完全微调具有竞争力(Wang 等人,2019 年)。
Lottery Ticket Hypothesis.(彩票假说): (LTH; Frankle and Carbin, 2019; Malach et al., 2020) 指出,每个神经模型都包含一个子网络(“中奖券”),如果再次单独训练,可以匹配甚至超过原始模型。为了实现这一点,在根据某些标准(例如,权重大小)对某些参数进行零掩码和冻结的修剪阶段之后,将剩余参数恢复到其原始值,然后重新调整。这个修剪和重新训练的过程可以重复多次。
迄今为止,LTH 主要用于通过网络修剪进行模型压缩;据我们所知,我们是第一个将它用于预训练模型适应的人。
Multi-Source Task Training.(多源任务训练): .安塞尔等人。 (2021) 表明,即使训练示例的总数保持不变,使用来自多种源语言的数据训练任务适配器也可以显着提高下游零样本传输性能。在他们的训练设置中,每个批次都包含来自单一、随机选择的源语言的示例,该语言适配器在训练步骤期间被激活。
3 方法论
3.1 Lottery Ticket Sparse Fine-Tuning(彩票稀疏微调)
训练。在这项工作中,我们提出彩票稀疏微调(LT-SFT)。与 Frankle 和 Carbin (2019) 的 Lottery Ticket 算法类似,我们的 LT-SFT 方法包括两个阶段:
(阶段 1)预训练模型参数 θ ( 0 ) θ^{(0)} θ(0) 在目标语言或任务数据 D 上进行完全微调,产生 θ ( 1 ) θ^{(1)} θ(1)。参数根据一些标准进行排序,在我们的例子中,最大绝对差 ∣ θ i ( 1 ) − θ i ( 0 ) ∣ |θ_i^{(1)}-θ_i^{(0)} | ∣θi(1)−θi(0)∣,并且前 K 被选择用于下一阶段的调整:二进制掩码 μ 设置为 1在与这些参数对应的位置,在其他位置为 0。(相当于那个mask)
这里对变化比较大的参数进行下一阶段的调整,我们认为他们变化越大,越是核心的,当然实际情况可能并不是这样,因为可能有些参数一开始的落点就很棒,这些也是我们不需要改动的,可能有些改动很微小,但是却很重要,当然这里没法控制这些参数。
(第 2 阶段)在将参数重置为其原始值 θ ( 0 ) θ^{(0)} θ(0) 后,再次对模型进行微调,但这一次只有 K 个选定的参数是可训练的,而其他参数保持冻结。在实践中,我们通过传递掩码梯度 μ ◉ ∇ θ L ( F ( ⋅ ; θ ) , D ) μ ◉∇_θL(F (·; θ), D) μ◉∇θL(F(⋅;θ),D)(其中 ◉表示逐元素乘法,L 是损失函数)在每一步发送给优化器。从得到的微调参数 θ ( 2 ) θ^{(2)} θ(2) 我们可以得到差异的稀疏向量 φ = θ ( 2 ) − θ ( 0 ) φ = θ^{(2)} - θ^{(0)} φ=θ(2)−θ(0)。(上面相关工作有介绍这个公式)
此外,我们尝试应用正则化项来阻止参数偏离其预训练值 θ ( 0 ) θ^{(0)} θ(0)。具体来说,我们使用
J ( θ ) = λ N ∑ i ∣ θ i − θ i ( 0 ) ∣ J(θ) =\frac{\lambda }{N}\sum\nolimits_i {\left| {
{\theta _i} - \theta _i^{(0)}} \right|} J(θ)=Nλ∑i∣∣∣θi−θi(0)∣∣∣
形式的 L1 正则化。
成分构成 : 尽管我们经常使用术语“稀疏微调”来指代差分向量 φ 本身,但 SFT 最准确地概念化为一个函数,它将参数化函数作为其参数并返回一个新函数,其中一些稀疏差分向量 φ已添加到原始参数向量中。假设我们有一个语言 SFT S L S_L SL 和一个任务 SFT S T S_T ST 定义为
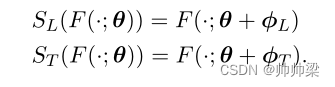
然后有:
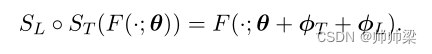
3.2 Zero-Shot Transfer with LT-SFT(使用 LT-SFT 的零样本传输)
我们采用了与 MAD-X 类似的跨语言迁移设置(Pfeiffer 等人,2020b,另见 §2)。我们从具有预训练参数 θ 的 MMT F 开始,该参数通过多种语言的掩码语言建模学习,例如 mBERT(Devlin 等人,2019)或 XLM-R(Conneau 等人,2020)。
对于每种感兴趣的语言 l l l,我们通过 LT-SFT(也具有 MLM 目标)对来自语言 l l l的文本学习语言 SFT φ ( l ) L ( l ) φ(l)^{(l)}_L φ(l)L(l)。
对于每个感兴趣的任务 t,我们通过 LT-SFT 对来自某些源语言 s 的注释数据学习任务 SFT φ T ( t ) φ^{(t)}_T φT(t)。在学习任务 SFT 时,我们首先通过对 s 应用语言 SFT 来适应源语言。训练后再次去除语言 SFT。
也就是说,我们对 F (·; θ + φ(s) L ) 执行 LT-SFT 以获得微调的参数向量 θ ′ θ' θ′。然后我们计算 φ T ( t ) φ^{(t)}_T φT(t) = θ ′ − ( θ + φ T ( s ) ) θ'-(θ+φ^{(s)}_T) θ′−(θ+φT(s))。请注意,在任务训练期间,我们还学习了一个分类器头,它在 LT-SFT 适应的两个阶段都进行了完全微调,在每个阶段的开始都应用了相同的随机初始化。
我们通过组合语言和任务 SFT 对任务 t 执行 F 到目标语言 l 的零样本适应以获得
F t , l = F ( ⋅ ; θ + φ T ( t ) + φ L ( l ) ) {F_{t,l}} = F( \cdot ;\theta {\text{ + }}\varphi _T^{(t)} + \varphi _L^{(l)}) Ft,l=F(⋅;θ + φT(t)+φL(l))
在此之上,我们堆叠为 t 学习的分类器头。关于 LT-SFT 的形式化算法和传输过程,我们参考附录 A。
4 Experimental Setup
为了广泛评估我们的新方法,我们在四个不同的任务上对其零样本跨语言性能进行了基准测试:词性标注 (POS)、依赖解析 (DP)、命名实体识别 (NER) 和自然语言推理。 NLI)。表 1 总结了我们的实验设置,包括我们实验中考虑的数据集和语言。我们强调低资源语言和 MMT 预训练期间未见的语言,尽管我们也评估了一些高资源语言。总的来说,我们涵盖了一组 35 种类型和地理上不同的语言,这使得它们代表了跨语言的变化(Ponti et al., 2019, 2020)。
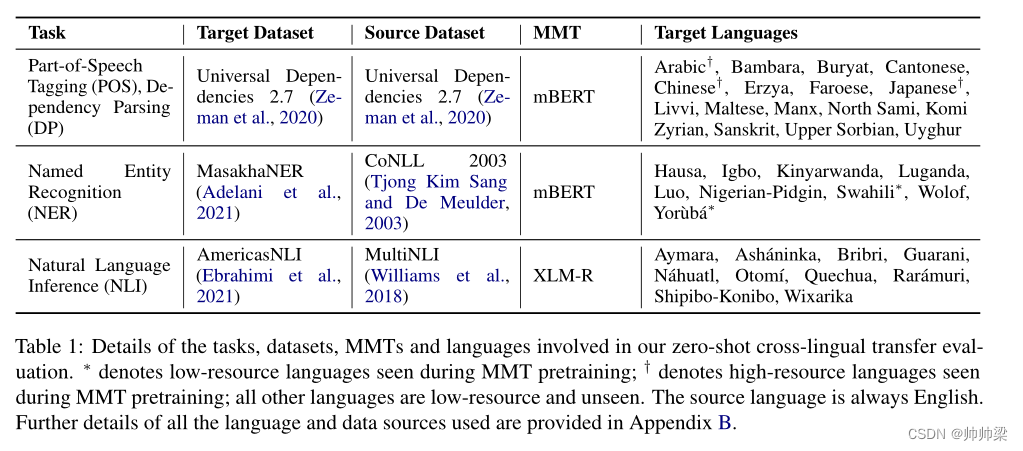
表 1:我们的零样本跨语言迁移评估中涉及的任务、数据集、MMT 和语言的详细信息。 ∗ 表示在 MMT 预训练期间看到的低资源语言; † 表示在 MMT 预训练期间看到的高资源语言;所有其他语言都是低资源且看不见的。源语言始终为英语。附录 B 中提供了所有使用的语言和数据源的详细信息。
4.1 Baselines and Model Variants(基线和模型变体)
主要基线是 MAD-X,它是最先进的基于适配器的跨语言迁移框架(Pfeiffer 等人,2020b)。我们使用“MADX 2.0”变体,其中最后一个适配器层被删除。菲佛等人。 (2021b) 发现这提高了性能,我们可以在初步实验中证实这一点。由于具有 Pfeiffer 等人使用的配置的适配器。 (2020b) 在我们的评估中不适用于许多语言,我们为所有语言训练自己的语言。在附录 D 中,我们还提供了来自 AdapterHub(Pfeiffer 等人,2020a)的可比较语言适配器的评估(如果可用)。
我们还使用 BITFIT (Zaken et al., 2021) 进行实验,为现有的 SFT 技术建立基线。除了主要的 LT-SFT 模型变体之外,在 POS 和 DP 上,我们测试了一个 RANDSFT 变体作为消融,其中要微调的 K 参数是随机选择的,而不是基于知情标准。
对于 LT-SFT 和 MAD-X,我们还评估了仅任务适应 (TA) 配置,其中仅应用任务 SFT/适配器,而没有目标语言 SFT/适配器。
4.2 Language SFT/Adapter Training Setup(语言 SFT/适配器训练设置)
MLM Training Data. 对于我们 POS 和 DP 评估中的所有语言,我们在 Wikipedia 语料库上执行 MLM 语言 SFT/适配器培训。如果可用,我们还在 NER 评估中使用所有语言的 Wikipedia。如果不是这种情况,我们使用 Luo 新闻数据集 (Adelani et al., 2021) 和尼日利亚 Pidgin 的 JW300 语料库 (Agi´c and Vuli´c, 2019)。我们 NLI 评估中语言的主要语料库是数据集创建者用来训练其基线模型的语料库(Ebrahimi 等人,2021 年);然而,由于这些语料库的大小由于仅包含并行数据而受到限制,我们使用来自维基百科的数据和 Bustamante 等人的秘鲁土著语言语料库来扩充它们。 (2020)在可用的情况下。附录 B 中提供了有关数据源的更多详细信息。
Training Setup and Hyper-parameters. 对于 SFT 和适配器,我们训练 100 个 epoch 或 100,000 个步骤,批量大小为 8,最大序列长度为 256,绝对最小值为 30,000 个步骤,因为 100 个 epoch 对于某些语料库非常小的语言来说似乎是不够的。模型检查点每 1,000 步(高资源语言为 5,000)在 5% 的语料库(高资源语言为 1%)的保留集上进行评估,并在训练结束时选择损失最小的一个。我们使用 AdamW 优化器(Loshchilov 和 Hutter,2019),初始学习率为 5e-5,在训练过程中线性降低到 0。
继 Pfeiffer 等人之后。 (2020b),适配器基线的缩减因子(即模型隐藏大小与适配器大小之间的比率)设置为 2,总共有 760 万个可训练参数。为了可比性,我们为我们的语言 LT-SFT 设置了相同数量的可训练参数 K。这导致语言 SFT 的 mBERT 稀疏度为 4.3%,XLM-R 为 2.8%。由于 BITFIT 专门调整偏差参数,因此其语言 SFT 的固定稀疏度对于 mBERT 为 0.047%,对于 XLM-R 为 0.030%。
重要的是,在语言稀疏微调期间,我们将输入和输出嵌入矩阵解耦并固定输出矩阵的参数;否则,我们发现在完全微调期间变化最大的 K 个参数中的绝大多数都属于嵌入矩阵,这似乎是因为它靠近模型输出,这会损害下游性能。我们还修复了层归一化参数;所有其他参数都是可训练的。对于语言适应,我们应用第 3.1 节中描述的 L1 正则化,λ = 0.1。请注意,指定的训练机制在 LT-SFT 的两个阶段以相同的方式应用。
对于 MAD-X 基线中的语言适配器训练,我们使用带有可逆适配器的 Pfeiffer 配置 (Pfeiffer et al., 2021a),这是为适应目标语言词汇而设计的特殊附加子组件,可产生一致的收益。
4.3 Task SFT/Adapter Training Setup( 任务 SFT/适配器训练设置)
对于 POS 标记、DP 和 NER,2 我们在表 1 中指示的数据集上训练任务 SFT/适配器 10 个 epoch,批大小为 8,除了在 LT-SFT 训练的第一阶段,我们只训练 3 个 epoch。3每 250 步在验证集上评估模型检查点,并在训练结束时采用最佳检查点,选择指标是 POS 的准确性,DP 的标记附件分数和 NER 的 F1 分数。与语言微调类似,我们使用 5e-5 的初始学习率,在训练过程中线性降低到 0。对于 POS 和 NER,我们使用标准的令牌级单层多类模型头。对于 DP,我们使用 Dozat 和 Manning (2017) 的双仿依赖解析器的浅变体 (Glavaš 和 Vuli´c, 2021)。
对于 NLI,我们使用与 Ebrahimi 等人相同的微调超参数。 (2021):5 个 epoch,批大小为 32,每 625 步对验证集进行检查点评估,初始学习率为 2e-5。我们在与 [CLS] 标记对应的 MMT 输出顶部应用了一个两层多类分类头。
我们发现,任务适应期间可训练参数的数量(由 SFT 的 K 和适配器的缩减因子控制)对性能有很大影响:因此,我们尝试了一系列值。具体来说,我们测试了 32、16、8、4、2 和 1 的适配器缩减因子,以及 SFT 的等效 K 4 值。
在任务适应过程中,我们总是按照 Pfeiffer 等人的方法应用源语言适配器。 (2020b),或源语言 SFT(见 §3.2)
4.4 Multi-Source Training
为了验证任务 LT-SFT 训练,如先前工作中的任务适配器训练(Ansell 等人,2021 年),受益于训练数据中存在多种源语言,并突破了零样本跨语言迁移的界限,我们在 DP 和 NLI 上进行多源训练实验。
我们采用与 Ansell 等人类似的设置。 (2021):我们通过连接所有源语言的训练数据来获得训练集。我们像在单源情况下一样随机打乱训练集和训练,除了每个批次由来自单一源语言的示例组成,其语言 SFT 在训练步骤中应用。
我们优先考虑最大化性能,而不是提供与单一来源案例的公平比较,因此与 Ansell 等人不同。 (2021),我们使用了整个训练集。违背这一原则,我们为 DP 设置了每种语言最多 15K 的示例,以更好地平衡我们的样本。
对于 DP,我们在 11 种不同的高资源语言的 UD 树库上训练我们的模型。对于 NLI,我们在 MultiNLI(Williams 等人,2018 年)以及 XNLI 数据集中所有 14 种非英语语言的数据(Conneau 等人,2018 年)上进行训练。
我们还评估了关于抽取式问答 (QA) 的多源任务 SFT 训练,因为有相对大量的多语言数据可用于该任务。具体来说,我们使用来自 SQuAD 版本 1(Rajpurkar 等人,2016 年)的英语数据、来自 MLQA 的所有语言(Lewis 等人,2020 年)以及来自 XQuAD 的那些语言(Artetxe 等人,2020 年)进行训练,这些语言也出现在MLQA。我们评估 XQuAD 中存在的语言,而不是 MLQA 中的语言。对于 QA,我们训练了 5 个 epoch,批量大小为 12,初始学习率为 3e-5。源语言的完整细节可以在附录 B 中找到。
我们对所有任务使用 1 的等效缩减因子,遵循我们单源实验的最强设置。除上述情况外,训练配置和超参数与单源训练相同。
5 Results and Discussion
我们在表 2 中报告了最佳缩减因子(或等效 K)的 zeroshot 跨语言迁移的平均测试性能。在所有四个任务中都出现了一些模式:首先,LT-SFT 始终优于所有基线。特别是,它在所有任务中都超过了最先进的 MAD-X,在词性标注方面的准确度提高了 2.5,在依赖解析方面提高了 2.5 UAS 和 3.7 LAS,在命名实体识别方面提高了 1.8 F1 分数,以及 1.9自然语言推理的准确性。与 RAND-SFT 相比,其卓越的性能证明了选择“中奖彩票”而不是随机参数子集的重要性。其次,结果证明了语言 SFT/适配器对于将预训练模型专门用于看不见的语言的重要性,因为与仅具有任务适应的相应设置(TA-ONLY)相比,它们在 4 个任务中带来了性能的大幅提升。
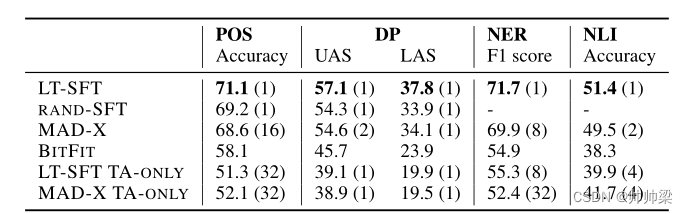
表2:选择最佳等效降低因子(在每个结果之后显示在括号中显示)时,零射击跨语性转移评估的结果平均。
我们注意到 LT-SFT 的零样本性能也超过了 AmericasNLI 任务中基于翻译的基线,达到 51.4% 的平均准确率,而 Ebrahimi 等人的“翻译训练”基线为 48.7%。 (2021 年)。
在图 2 中,我们更详细地概述了在一系列不同缩减因子下的平均跨语言模型性能。随着可训练任务参数数量的增加,LT-SFT 和 RAND-SFT 方法的结果通常会改善或保持稳定。相反,MAD-X 没有这种趋势,因为较低的缩减因子可能会降低其结果。这使得在使用 SFT 时更容易为这个超参数选择一个好的设置。此外,值得再次强调的是,与 MAD-X 不同,此超参数不会影响推理时间。
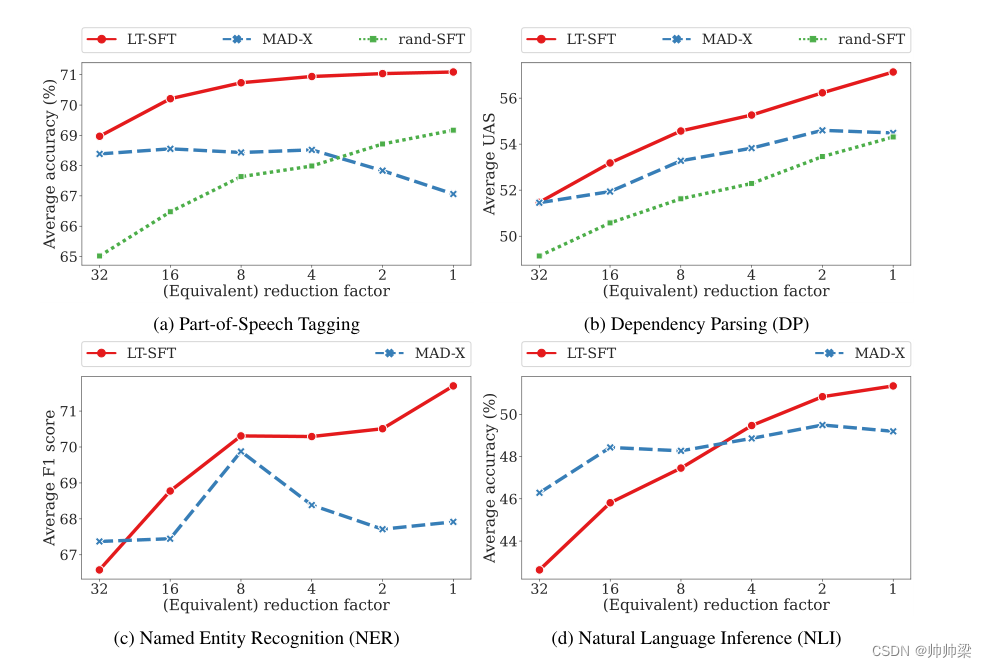
图 2:Lottery-Ticket Sparse Fine-Tuning (LT-SFT)、Random Sparse Fine-Tuning (RAND-SFT) 和基于适配器的 MAD-X 在四个任务上的零样本跨语言迁移评估,具有不同数量的任务适应期间的可训练参数。结果是所有目标语言的平均值。
BITFIT 的性能比在所有任务中执行语言适应的其他方法差得多。考虑到其他 SFT 方法随着 K 的增加而提高性能的强劲趋势,似乎可训练参数少两个数量级的 BITFIT 缺乏学习有效任务和语言 SFT 的能力。
有关单个语言级别的其他结果以及对高资源目标语言与低资源目标语言的语言适应效果的分析,我们请读者参阅附录 C。
5.1 Multi-Source Training
如表 4 所示,多源 LT-SFT 训练在 DP 上带来了零样本跨语言迁移性能的大幅提升,对 NLI 带来了适度的提升。这可能是因为与 DP 训练集相比,NLI 的训练集包含相对较少数量的非英语示例。此外,与 DP 目标语言相比,AmericasNLI 目标语言与源语言的谱系相关性通常较低。
表 3 表明,多源训练也有利于在一系列资源相对较高的语言上进行 QA 的零样本跨语言迁移。特别是,XLM-R Base 的 LT-SFT 多源训练舒适地优于 XLM-R Large(更大的模型)的单源全微调,并且大大优于 XLM-R Base 单源全微调.尽管 6 种非英语源语言中的每一种都比 SQuAD 的英语数据少一个数量级以上的训练数据,但这种改进仍然存在,这一事实说明了多语言源数据的不成比例的优势。
5.2 Benefits of Sparsity(稀疏性的好处)
最后,我们解决以下问题:稀疏性是否负责防止单独微调组合时的干扰?为了用经验证据支持这一假设,我们使用 LT-SFT 来训练具有不同密度水平的语言 5 和任务微调,即非零值的百分比(从 5% 到 100%)。然后我们评估所有可能的密度级别组合。结果在图 3 中以等高线图的形式显示,用于选定的任务和语言组合:布里亚特语、粤语、尔兹亚语、马耳他语和上索布语用于 DP,以及豪萨语、伊博语、卢干达语、斯瓦希里语和沃洛夫语用于 NER。
从图 3 可以看出,密度水平大于微调参数的 30% 的 SFT 的性能显着下降。6 我们推测这是由于稀疏微调与与微调参数重叠的风险较低。彼此,从而在它们封装的知识的不同方面之间产生干扰。然而,必须注意的是,替代假设可以解释除了参数重叠之外的性能下降,例如由于容量过大而导致的过度拟合。虽然我们将寻找确凿证据留给未来的工作,但这两个假设都说明了为什么正如我们在方法中提出的那样,在适应中强制执行稀疏性对于实现模块化至关重要
6 Related Work
7 Conclusion and Future Work
我们提出了一种新方法来微调预训练模型,它既是模块化的(如适配器)又是表达性的(如稀疏微调)。该方法基于彩票假设框架下的中奖彩票发现算法的一种变体。对于每种语言(通过对未标记文本建模)和每项任务(通过监督学习),我们推断出相对于原始模型的稀疏差异向量。对语言和任务的适应性可以与预先训练的模型组合,以实现零镜头跨语言迁移。
在几个多语言任务中,将我们的方法与最先进的基线进行比较,结果表明,在预训练期间(包括许多真正的低资源语言),两种语言都取得了显著的进步。在未来的工作中,我们的方法提供了几个潜在的扩展。除了彩票算法的变异调查在§6中,鉴于稀疏的重要性为模块化(§5.2),我们计划尝试附加先前用于修剪算法可以识别和调整模型参数的一个子集,比如DiffPruning(郭et al ., 2021)和ChildTuning(徐et al .,2021 b)。最后,由于它的简单和普遍性,我们的方法适合于跨语言迁移学习的许多其他应用,如多模态学习,去偏和领域适应。代码和模型可以通过https: //github.com/cambridgeltl/composable-sft在线获得。