参考代码:Metric3D
介绍
在如MiDas、LeReS这些文章中对于来源不同的深度数据集使用归一化深度作为学习目标,则在网络学习的过程中就天然失去了对真实深度和物体尺寸的度量能力。而这篇文章比较明确地指出了影响深度估计尺度变化大的因素就是焦距 f f f,则对输入的图像或是GT做对应补偿之后就可以学习到具备scale表达能力的深度预测,这个跟车端视觉感知的泛化是一个道理。需要注意的是这里使用到的训练数据集需要预先知道相机的参数信息,且这里使用的相机模型为针孔模型。
在下图中首先比较了两种不同拍摄设备得到的图片在文章算法下测量物体的效果,可以说相差不大。
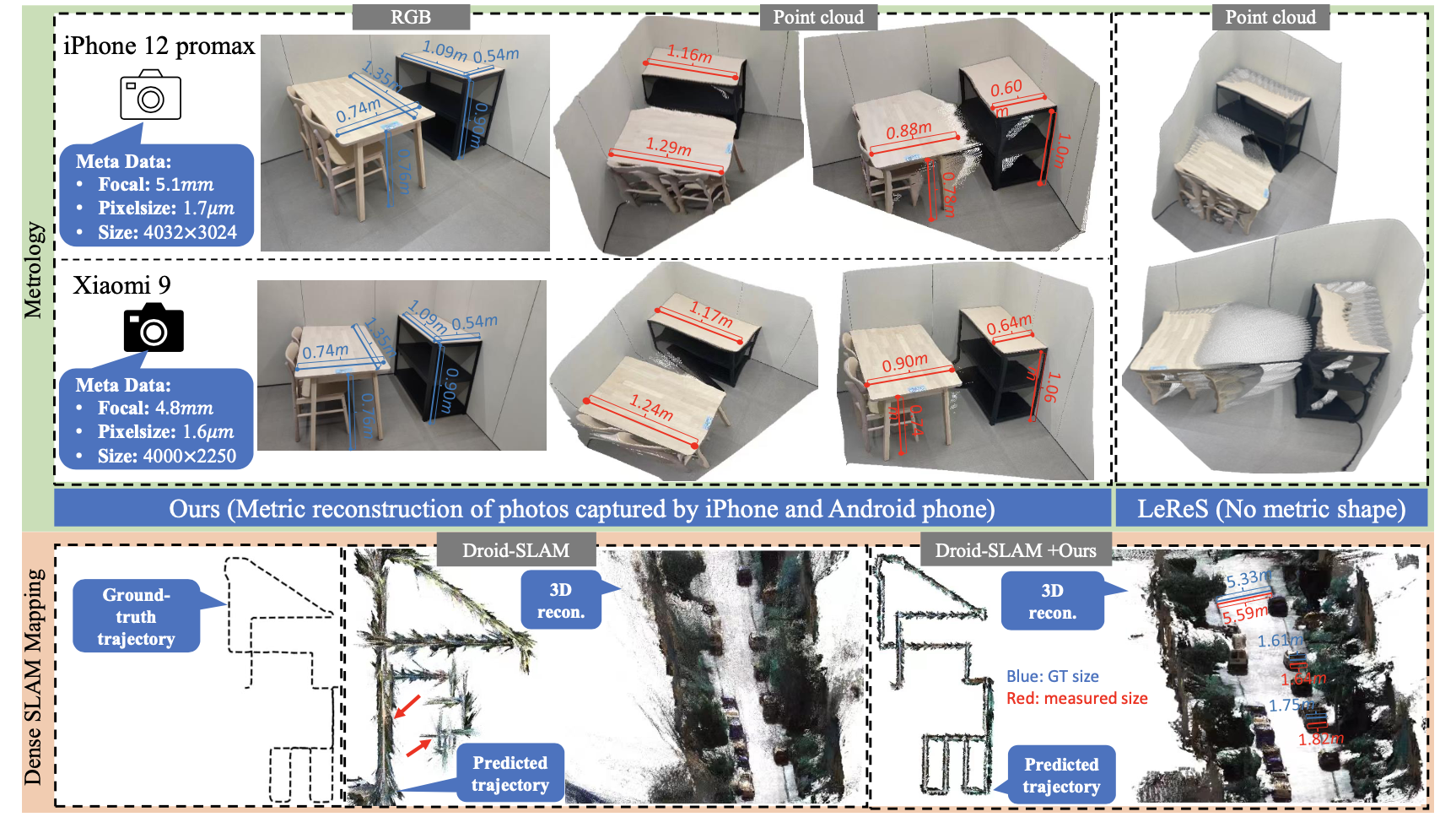
有了较为准确的深度估计结果之后,对应的单目slam、里程记这些都不是问题了。在配上大量的深度估计训练数据,那么泛化能力将会得到巨大提升,届时之前许多病态的问题都将得到解决。
方法设计
明确影响深度scale学习关键因子为焦距 f f f
对于针孔相机其内参主要参数为: f x δ x , f y δ y , u 0 , v 0 \frac{f_x}{\delta_x},\frac{f_y}{\delta_y},u_0,v_0 δxfx,δyfy,u0,v0,其中 f x , f y , δ x , δ y f_x,f_y,\delta_x,\delta_y fx,fy,δx,δy分别代表两个方向的焦距(一般情况下取两者相等)和像素大小,物理单位为微米。在相机中还有一个参数是成像传感器的尺寸,但是这个只影响成像的大小,就好比残画幅单反和全画幅单反的区别。
对于另外一个因素 δ \delta δ代表的是一个像素大小,在单孔成像原理中焦距、深度和成像大小的关系为(使用下图A图做相似三角形计算得到):
d a = S ^ [ f S ^ ′ ] = S ^ ⋅ α , α = [ f S ^ ′ ] d_a=\hat{S}[\frac{f}{\hat{S}^{'}}]=\hat{S}\cdot\alpha,\alpha=[\frac{f}{\hat{S}^{'}}] da=S^[S^′f]=S^⋅α,α=[S^′f]
其中, S ^ , S ^ ′ \hat{S},\hat{S}^{'} S^,S^′分别代表物体真实与成像大小,因而物体的深度大小只与焦距和物体像素下大小组成的比例因子有关系。
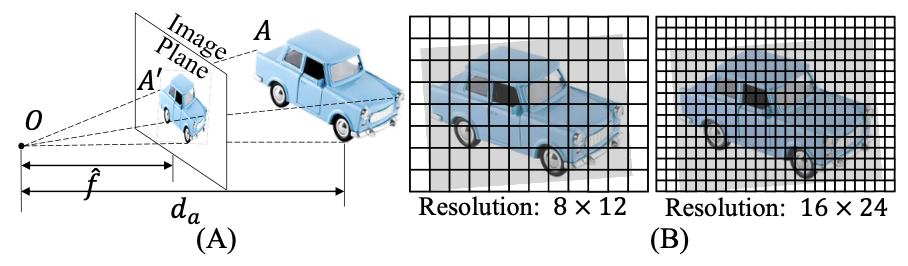
那么其中因素 δ \delta δ代表的是像素大小,在相同焦距情况下不同的因素 δ \delta δ会导致生成等比例的像素表达下的焦距 f ′ f^{'} f′,但是由于不同因素 δ \delta δ它们在图像上呈现出来的分辨率也是不一样的,好比上图中的B图。则经过等比例抵消之后因素 δ \delta δ的影响被消除,剩下产生影响的只有焦距这个变量了。下面对比了不同焦距、不同距离下的成像差异:

训练数据对齐
为了使得网络能够有效利用多种来源数据,这里需要首先假设一个虚拟相机参数,其中的关键参数为 f x c , f y c f_x^c,f_y^c fxc,fyc,一般情况下取两者相等,记为 f c f^c fc。则按照下图所示的两种变换关系便可使得网络在统一的尺度上完成训练。
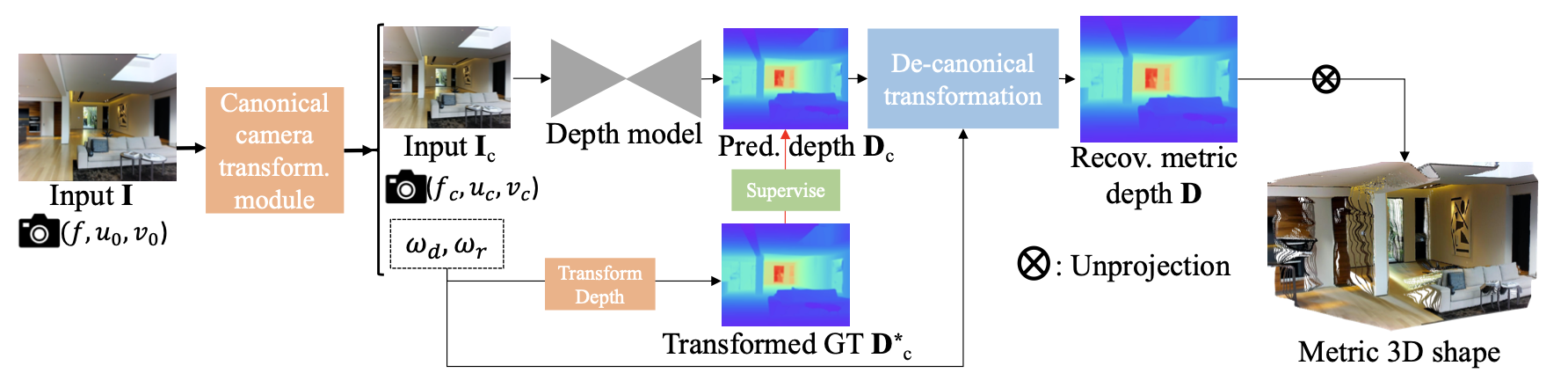
对于对齐的策略可以从两个维度出发:
- 1)深度对齐(CSTM_label):确定当前图片拍摄相机与期望相机的焦距比例 w d = f c f w_d=\frac{f^c}{f} wd=ffc,则这里不需要变换图片只需要修改对应深度GT就可以, D c ∗ = w d ⋅ D ∗ D_c^*=w_d\cdot D^* Dc∗=wd⋅D∗,在预测得到结果之后深度再做一个逆变换就可恢复到真实图像表示的深度下。
- 2)图像对齐(CSTM_image):确定当前图片拍摄相机与期望相机的焦距比例 w r = f c f w_r=\frac{f^c}{f} wr=ffc,用这个比例来确定图像的缩放比例,但是这里需要保持图像原本的图像尺寸不变,将缩放之后的图像会贴在光心所在的位置上,GT也是对应的操作。相当于是人为做了scale对齐。
然后对比俩个对齐方式对性能的影响:

只能说在不同数据集下表现各异,差异也大不到哪里去。反倒是期望焦距的选择对最后性能还有一些影响:
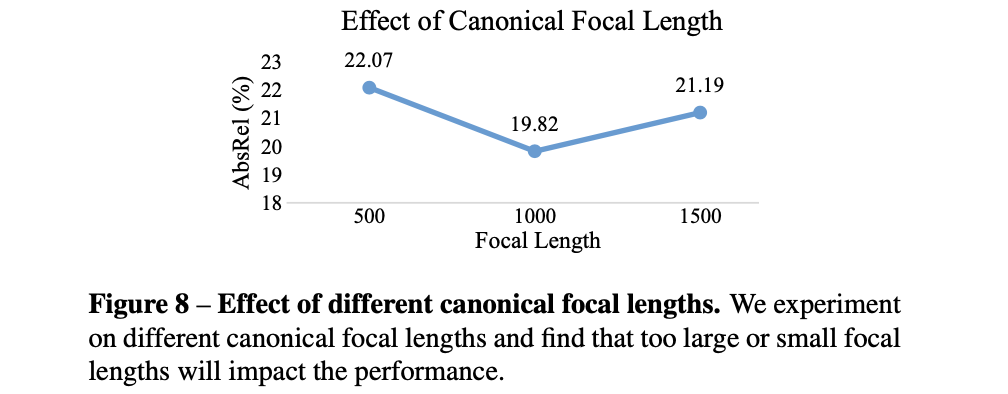
深度监督与约束
参考scale-invariable深度估计中的损失函数设计,这里设计了一个与之类似的损失函数,y也就是在图像上去截取对应区域进行计算,定义为:
L R P N L = 1 M N ∑ p i M ∑ j N ∣ d p i , j ∗ − μ ( d p i , j ∗ ) 1 N ∑ j N ∣ d p i , j ∗ − μ ( d p i , j ∗ ) ∣ − d p i , j − μ ( d p i , j ) 1 N ∑ j N ∣ d p i , j − μ ( d p i , j ) ∣ ∣ L_{RPNL}=\frac{1}{MN}\sum_{p_i}^M\sum_j^N|\frac{d_{p_i,j}^*-\mu(d_{p_i,j}^*)}{\frac{1}{N}\sum_j^N|d_{p_i,j}^*-\mu(d_{p_i,j}^*)|}-\frac{d_{p_i,j}-\mu(d_{p_i,j})}{\frac{1}{N}\sum_j^N|d_{p_i,j}-\mu(d_{p_i,j})|}| LRPNL=MN1pi∑Mj∑N∣N1∑jN∣dpi,j∗−μ(dpi,j∗)∣dpi,j∗−μ(dpi,j∗)−N1∑jN∣dpi,j−μ(dpi,j)∣dpi,j−μ(dpi,j)∣
其中, μ ( ) , M = 32 \mu(),M=32 μ(),M=32分别代表截取区域内的深度取中值操作和取的总块数量,对于块的大小设置为图像尺寸比例倍率,取值区间为 [ 0.125 , 0.5 ] [0.125,0.5] [0.125,0.5]。
总的损失函数描述为(structure ranking + virtual norm + silog):
L = L P W N + L V N L + L s i l o g + L R P N L L=L_{PWN}+L_{VNL}+L_{silog}+L_{RPNL} L=LPWN+LVNL+Lsilog+LRPNL
这些损失函数对于性能的影响:
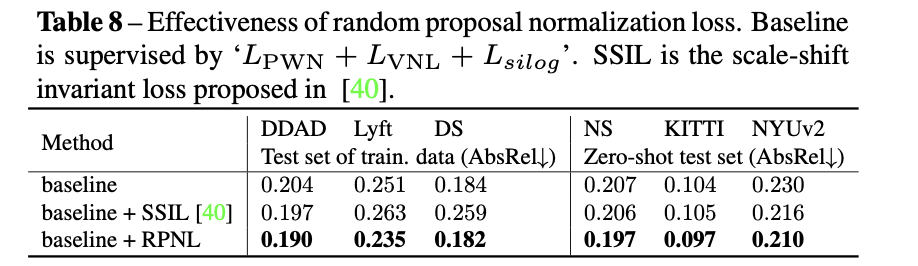
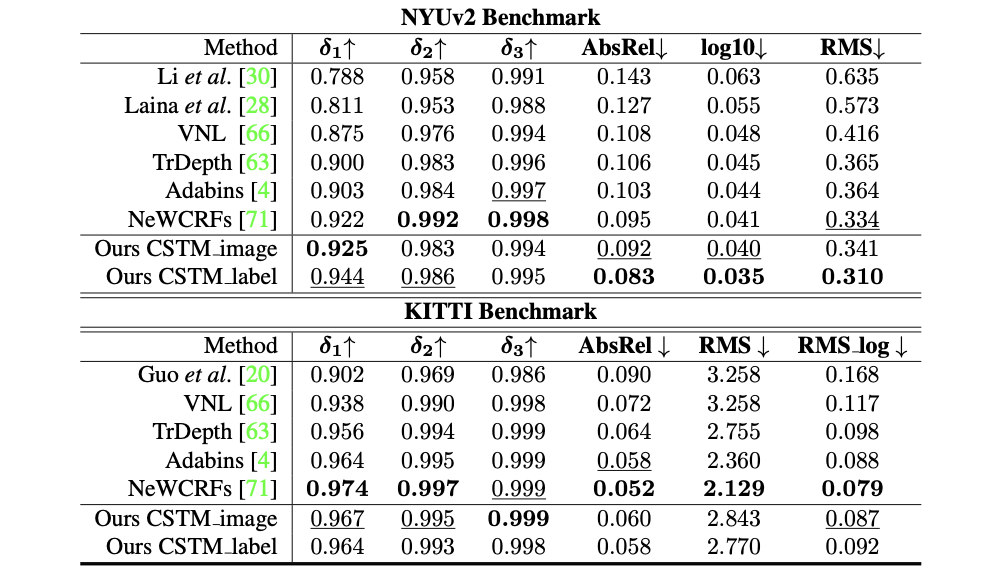
实验结果
KITTI和NYU数据集下的性能比较: