Zero-Shot Learning论文阅读笔记(第二周)
第一篇:DeViSE: A Deep Visual-Semantic Embedding Model
主要贡献
本文解决了“视觉识别系统在对象类别庞大时的处理能力不足”这一问题。对于传统视觉识别系统,对于10000类物体的大型识别应用,可能需要在最后一层添加10000个神经元。而且假如这时候检测出还有一个类别没训练,可能需要添加新的神经元重新训练,这无疑是非常低效冗余的。
摘要
文章提出了DeVISE的概念,即一种深度视觉语义嵌入模型,该模型利用标记图像数据和未标记文本的语义信息来识别视觉对象。文章证明,该模型在处理拥有1000类ImageNet对象识别任务时产生的不合理语义错误大大减少。同时也表明,语义信息可以用来对训练过程中未观察到的数万个图像标签进行预测,语义知识可以将这种零样本学习的预测准确率提高65%,在视觉模型从未见过的数千个新标签中,达到10%的命中率。
简单来说,文章糅合了传统视觉神经网络和词向量(word2vec)处理中的Skip-gram模型,从而实现了一个视觉和语义兼顾的模型。
算法简介
算法思想:
分别预训练一个视觉网络(Visual Model Pre-training)和词向量网络(Language Model Pre-training),再结合两网络进行训练。
Skip-gram算法简介:
在许多自然语言处理任务中,许多单词表达是由他们的tf-idf(词频-逆文本指数)分数决定的。即使这些分数告诉我们一个单词在一个文本中的相对重要性,但是他们并没有告诉我们单词的语义。Word2vec是一类神经网络模型——在给定无标签的语料库的情况下,为语料库中的单词产生一个能表达语义的向量。这些向量通常是有用的,而Skip-gram算法就是Word2vec其中一个模型。
对于skip-gram模型,输入一个单词
,它的输出是
的上下文
,其中上下文的窗口大小为
。举个例子,这里有个句子“I drive my car to the store”。如果把”car”作为训练输入数据,单词组{“I”, “drive”, “my”, “to”, “the”, “store”}就是输出。所有这些单词,需要进行one-hot编码。skip-gram模型图如下所示:
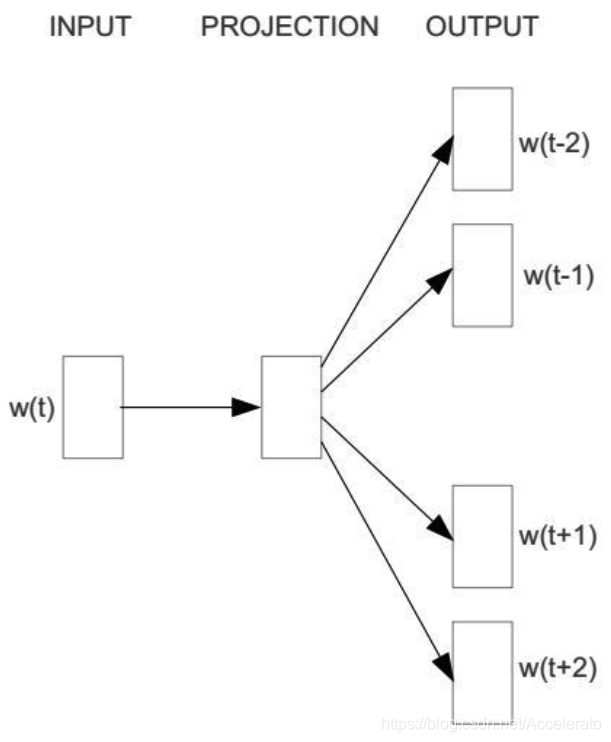
算法核心框架
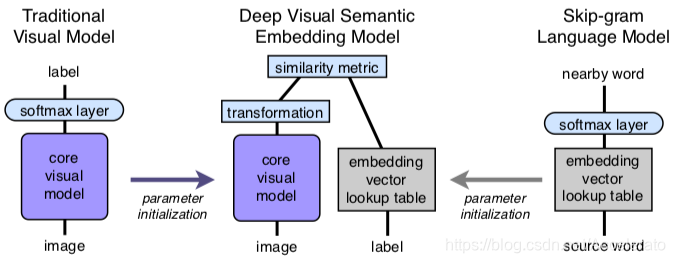
该结构图可以概括论文的核心思想,作者使用word2vec做NLP的向量,将CNN的最后一层softmax 替换为transformation(这里为linear transformation)做图像的特征向量, 这里要保证特征向量和 word2vec产生的向量维度一致,最后做特征向量和标签向量的相似度计算。
论文的另一个亮点是使用了hinge rank loss作为loss得计算,公式如下:
其中,
表示label的vector(word2vec计算得到),
表示image的vector(去除softmax layer的cnn计算),M表示linear transformation,margin为超参数。
实验结果
本文采用的训练集是ImageNet2012,该训练集有1000个类别的数据集,表现对比的是1000层的纯Softmax的视觉神经网络模型和随机嵌入模型。其中随机嵌入模型采用了随机单位范数嵌入向量代替NLP学习到的向量。在类别数增加的情况下,DeViSE表现比传统的zero-shot learning表现要好的多。
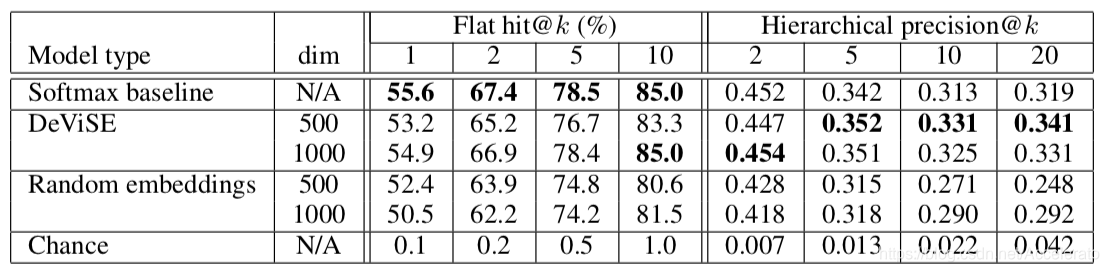

The goals of this work are to develop a vision model that makes semantically relevant predictions even when it makes errors and that generalizes to classes outside of its labeled training set, i.e. zero- shot learning. We compare DeViSE to two models that employ the same high-quality core vision model, but lack the semantic structure imparted by our language model: (1) a softmax baseline model – a state-of-the-art vision model [11] which employs a 1000-way softmax classifier; (2) a random embedding model – a version of our model that uses random unit-norm embedding vectors in place of those learned by the language model. Both use the trained visual model described in Section 3.2.
In order to demonstrate parity with the softmax baseline on the most commonly-reported metric, we compute “flat” hit@k metrics – the percentage of test images for which the model returns the one true label in its top k predictions. To measure the semantic quality of predictions beyond the true label, we employ a hierarchical precision@k metric based on the label hierarchy provided with the ImageNet image repository [7]. In particular, for each true label and value of k, we generate a ground truth list from the semantic hierarchy, and compute a per-example precision equal to the fraction of the model’s k predictions that overlap with the ground truth list. We report mean precision across the test set. Detailed descriptions of the generation of the ground truth lists, the hierarchical scoring metric, and train/validation/test dataset splits are provided in Sections A.1 and A.3.


引用
原文:https://dl.acm.org/citation.cfm?id=2999849
pdf:http://bengio.abracadoudou.com/cv/publications/pdf/frome_2013_nips.pdf
Frome A , Corrado G S , Shlens J , et al. DeViSE: a deep visual-semantic embedding model[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2. Curran Associates Inc. 2013.
第二篇:Zero-shot recognition using dual visualsemantic mapping paths
主要贡献
解决semantic gap问题的简单做法,所谓的semantic gap也就是从图片中提取的低层特征到高层语义之间存在的“语义鸿沟”问题。这也是零次学习方向应用的技术瓶颈问题。
摘要
这篇文章的题目是基于双视觉语义映射的零样本学习,文章的做法是基于流形学习的,对语义进行再表示,并且迭代地调整,以对齐两者的流形。基于此,我们提出了一种新的零次学习识别框架,该框架包含双视觉语义映射路径。分析表明,该框架不仅可以利用先验语义知识推断图像特征空间中潜在的语义流形,而且可以生成优化的语义嵌入空间,提高视觉语义映射到不可见类的传递能力。文章对四个标准数据集的进行了模型检验,取得了很好的效果。
另外值得注意的是这篇文章是直推式的零次学习。
算法简介
直推式学习和纯半监督学习的区别
假设有如下的数据集,其中训练集为 ,测试集为 ,标记样本数目为 ,未标记样本数目为
- 标记样本
- 未标记样本 ,训练时可用
- 测试样本 ,只有在测试时才可以看到
纯半监督学习是一种归纳学习(inductive learning),可以对测试样本 进行预测。也即纯半监督学习是基于“开放世界”的假设。
直推学习是transductive学习,仅仅可以对未标记样本 进行标记,模型不具备对测试样本 进行泛化的能力。直推学习是基于“封闭世界”的假设。
直推学习假设未标记的数据就是最终要用来测试的数据,学习的目的就是在这些数据上取得最佳泛化能力。之后再通过迁移学习的方法,利用测试集数据的到一些测试类别的先验知识。相对应的,纯半监督学习在学习时并不知道最终的测试用例是什么。
核心思想
视觉对象识别通常需要为每个类别收集大量标记图像,并且只能将对象分类为已看到的类别。随着识别任务向大规模和细粒度的类别发展,很难满足这些需求。例如,许多对象类,如临界尾羽鸟和稀有植物类,我们不容易预先收集它们的信息。此外,对大量图像进行细粒度的注释是很费劲的,甚至需要具有专门领域知识的人员进行注释。这些挑战推动了零样本识别(Zero-Shot Recognition)算法的兴起。
在zsr算法中,许多类没有标记图像。当前的zsr算法普遍采用一种有效的方法,在输入图像特征空间 和输出标签空间 之间引入一些中间语义嵌入空间 。该空间 包含许多语义嵌入(简称嵌入),可以是人工定义的属性向量,或从辅助文本中自动提取的字向量。作为对象标签的语义对应,即每个属性向量或词向量对应一个唯一的对象类,嵌入可以建立类间的连接。
与类标签相比,文章嵌入具有一些特殊的属性。
- 它们在空间K中呈现出比一般的标签表示更为复杂的几何结构,例如在空间L中有一个热向量,分布在具有相同边长的超立方体的顶点上。这种特殊的几何结构,即语义流形,可以编码标签空间中缺失的可见类和不可见类之间的关系。
- 不同的嵌入有自己的特征流形结构,这会导致识别性能的明显变化。例如,在同一个数据集awa上,属性向量通常比词向量在看不见的类上获得更好的识别性能。
- 嵌入需要提前构建,并在学习期间保持不变。

上图可以表示文章中的核心思想,模型将待处理的图片分为两类: 和 ,从 通过两条不同的语义映射函数 建立和不同空间的关系,而传统ZSR只有一条映射路径就将 投影到
文章的双映射方法主要包括三步:
(1)学习从 到 空间的映射函数 。
(2)提取 的底层流型特征,生成和 同源的 。
(3)将 和 进行迭代对齐并获得
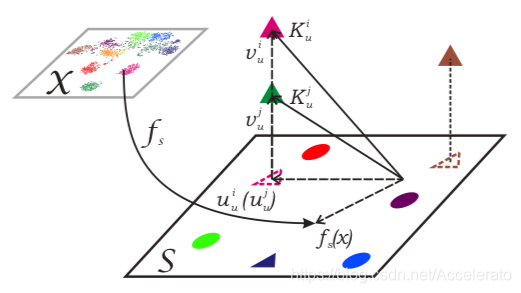
如上图所示,圆和三角形分别表示可见类和不可见类。 表示带标签图像所包含的子空间。在虚线三角形中,文章将不可见类的图像正交投影显示在 上。
文章的贡献如下:
- 文章将语义流形与视觉语义映射fs的传递能力之间的内在关系形式化,揭示了优化语义流形在新的zsr算法开发中的重要性。
- 文章引入了一种新的思想,将zsr问题转化为语义空间k中流形结构和视觉语义映射fs的联合优化。利用这一思想,我们可以通过改进k中流形的结构来弥补fs传递能力的不足。
- 文章提出了一个新的框架,即双视觉语义映射路径(DMAP),以解决这个联合操作优化问题。该算法不仅可以学习一个优化的视觉语义映射fs,还可以学习一个新的与x相关的语义空间。实验结果表明,利用优化后的语义空间可以显著提高fs在不可见类上的迁移能力。
实验结果
数据集
文章在三个小规模的标注数据集和一个大规模数据集上进行模型评估检验:具有属性标签的动物数据集(AWA)、加州理工大学UCSD 的鸟类数据集(CUB)、标准犬类数据集(Dogs)和IM-Agenet ILSVRC 2012(ImageNet)。AWA由50个图像类的30475个图像组成,每个图像类至少包含92个图像,与外部提供的的85个属性标签和相应的类属性关联配对。文章遵循文献中公认的实验方案,即40个训练集和10个测试集。CUB是一个拥有子类别的数据集,有312个属性注释,用于200个不同的鸟类。总共包含11788幅图像。在[2]之后,我们使用相同的零杆分割法,150个训练班和50个测试班。狗包含113种子属性分类共19501张图片,没有人工定义的属性注释。85个班用于培训,其余的用于测试。大型IM-agenet数据集包含1000个类别和120多万个图像。
测试结果
文章在实验中考虑两种不同的zsr设置:传统zsr(czsr)和广义zsr(gzsr)。在czsr中,文章对已见类进行训练,对未见类进行测试,假设测试实例来自未见类(表示为u→u)。在gzsr中,文章假设测试实例来自所有目标类(表示为u→t)。
vgg:Visual Geometry Group Network
att:ATTENTION
goog:GoogLeNet
res:ResNet
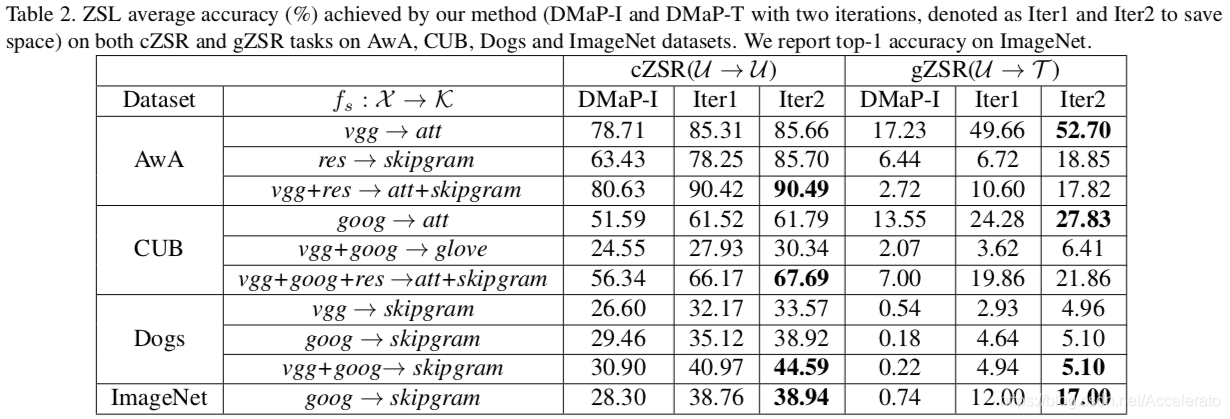
这些结果表明,在所有情况下,文章的流形对准过程都能显著地提高DMAP-I的算法效率,仅使用两种方法,就可以提高10.71%的平均精度。而且即使映射函数
的初始性能相对较低,我们的算法仍然有能力获得良好的性能。换言之,即使k中的初始流形质量较低,它仍将被驱动为与x更一致。例如,在Dogs数据集上,一次迭代可以显著地将精确度从30.90%提高到40.97%。
此外,由于
是线性映射,计算复杂度很低。这些结果再次验证了本文方法的可行性和有效性。
引用
原文:https://arxiv.org/pdf/1703.05002.pdf
Li Y , Wang D , Hu H , et al. Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths[J]. 2017.
