文章目录
论文题目:BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models信息检索模型零样本评估的异构基准
本文提出了文本检索任务的基准,使用了来自不同领域和任务复杂性的 18 个现有数据集,并涵盖了用于展示检索和排名性能的各种模型,尤其是在迁移学习环境中。这项工作的主要贡献是为检索系统的零样本评估提出了一个标准化基准。它在各种任务和领域上测试检索系统。以前的(标准化的)基准测试包括一个狭窄的评估设置,无论是关于他们的任务(例如 MultiReQA 只专注于问答)还是关于他们的检索语料库(例如 KILT 只是从维基百科检索)。BEIR 克服了这个缺点,为新的检索方法提供了一个易于使用的评估框架。
现有的神经信息检索 (IR) 模型通常在同质和狭窄的环境中进行研究,这对其分布外 (OOD) 泛化能力的洞察力相当有限。为了解决这个问题,并促进研究人员广泛评估其模型的有效性,我们引入了 Benchmarking-IR (BEIR),这是一种用于信息检索的强大且异构的评估基准。我们利用来自不同文本检索任务和领域的18个公开可用数据集的精心选择,并在BEIR基准上评估了10个最先进的检索系统,包括词法、稀疏、密集、后期交互和重新排序架构。我们的结果表明 BM25 是一个稳健的基线,基于重新排序和后期交互的模型平均实现了最佳的零样本性能,但是,计算成本很高。相比之下,密集和稀疏检索模型的计算效率更高,但通常表现不及其他方法,突出表明它们的泛化能力还有很大的改进空间。希望这个框架能够让我们更好地评估和理解现有的检索系统,并有助于在未来加速朝着更健壮和通用的系统迈进。
1. 简介
主要的自然语言处理(NLP)问题都依赖于实用和高效的检索部分,作为寻找相关信息的第一步。具有挑战性的问题包括开放领域的问答、断言验证、重复问题检测等等。 传统上,检索一直由词汇方法主导,如TF-IDF或BM25。然而,这些方法存在着词法差距,只能检索到包含查询中的关键词的文档。此外,词法将查询和文档视为词袋,不考虑单词排序。
最近,深度学习,特别是像BERT这样的预训练Transformer模型已经在信息检索中变得很流行。这些神经检索系统可以用许多根本不同的方式来提高检索性能。2.1节中对这些系统进行了简要概述。许多先前的工作在大型数据集上训练神经检索系统,如Natural Questions (NQ)(133k training examples) 或MS MARCO (533k training examples),它们都侧重于给定一个问题或基于关键词的简短查询的段落检索。在以前的工作中,大多数方法都是在同一数据集上进行评估的,在这些数据集上,与BM25这样的词法相比,性能有明显的提高。
然而,创建一个大型的训练语料库往往是耗时和昂贵的,因此许多检索系统被应用于零样本设置中,没有可用的训练数据来训练系统。到目前为止,还不清楚现有的训练有素的神经模型对其他文本领域或文本检索任务的表现如何。更重要的是,目前还不清楚不同的方法,如稀疏嵌入与密集嵌入,对分布外数据的概括程度如何。
在这项工作中,我们提出了一个新的稳健和异质的基准,称为BEIR(Benchmarking IR),由18个检索数据集组成,用于比较和评估模型泛化。之前的检索基准存在评估范围相对狭窄的问题,要么只关注单一任务,如问题回答,要么只关注某个领域。在BEIR中,我们专注于多样性,我们包括九个不同的检索任务。事实核查、引文预测、重复问题检索、论据检索、新闻检索、问题回答、推文检索、生物医学IR以及实体检索。此外,我们还包括来自不同文本领域的数据集,涵盖广泛主题(如维基百科)和专业主题(如COVID-19出版物)的数据集,不同的文本类型(新闻文章与推特),不同规模的数据集(3.6k - 15M文档),以及具有不同查询长度(平均查询长度在3到192个单词之间)和文档长度(平均文档长度在11到635个单词之间)的数据集。
我们使用BEIR来评估来自五大架构的十种不同的检索方法:词法、稀疏、密集、后期交互和重排序。从我们的分析中,我们发现没有任何一种方法在所有的数据集上都能持续胜过其他方法。此外,我们注意到,一个模型的领域内性能与它的泛化能力并不相关:用相同的训练数据进行微调的模型可能会有不同的泛化能力。在效率方面,我们发现性能和计算成本之间的权衡:计算成本高的模型,如重排模型和后期交互模型表现最好。更有效的方法,如基于密集或稀疏嵌入的方法,可以大大低于传统的词汇模型,如BM25的表现。总的来说,BM25仍然是一个强大的零样本文本检索的基线。
最后,我们注意到,在基准中包含的数据集可能存在着强烈的词汇偏见,这可能是因为词汇模型在数据集的注释或创建过程中被优先使用。这可能会给非词汇性方法带来不公平的劣势。我们对TREC-COVID数据集进行分析。我们为被测试的系统手动注释了缺失的相关性判断,并看到非词汇性方法的性能有了显著的提高。因此,未来的工作需要更好的无偏见的数据集,允许对所有类型的检索系统进行公平的比较。
有了BEIR,我们朝着建立一个单一的、统一的基准来评估检索系统的零样本能力迈出了重要一步。它允许研究某些方法何时以及为何表现良好,并希望能将创新引向更强大的检索系统。我们发布了BEIR,并将不同的检索系统和数据集整合到一个记录良好、易于使用和可扩展的开源包中。BEIR与模型无关,欢迎各种方法,也允许轻松整合新任务和数据集。更多细节可在https://github.com/UKPLab/beir
2. 相关工作和背景
据我们所知,BEIR是第一个广泛的、零样本信息检索的基准。现有的工作并没有深入地评估零样本检索的设置,它们要么专注于一个单一的任务、小的语料库或某个领域。这种设置阻碍了对不同领域和任务类型的模型泛化的调查。
MultiReQA由八个问答(QA)数据集组成,评估了给定问题的句子级答案检索。它只测试一个任务,八个数据集中有五个来自维基百科。此外,MultiReQA对相当小的语料库进行了检索评估:8个任务中的6个任务的候选句子少于10万个,这有利于密集检索而不是词法检索。KILT由五个知识密集型任务组成,包括总共11个数据集。这些任务涉及检索,但它不是主要任务。此外,KILT只从维基百科中检索文档。
2.1 神经检索
信息检索是从集合中搜索并返回相关文档以进行查询的过程。本论文专注于文本检索,并使用文档作为给定集合中任何长度的文本的覆盖词,而查询则是用户输入的,也可以是任何长度的。传统上,像TF-IDF和BM25这样的词汇方法在文本信息检索中占主导地位。最近,人们对使用神经网络来改进或取代这些词汇方法。
基于检索器:词法受到词汇间隙的影响。为了克服这个问题,早期技术提出用神经网络来改进词汇检索系统。稀疏的方法,如docT5query使用一个序列到序列的模型来识别文档扩展词,该模型产生可能的查询,而给定的文件将与之相关。DeepCT则使用了BERT模型来学习文档中的相关术语权重,并生成一个伪文档表示。这两种方法都仍然依靠BM25来完成剩余的部分。同样地SPARTA用BERT学习了标记级的上下文表征,并将文档转换为一个有效的反向索引。最近,密集检索方法被提出。它们能够捕捉到语义匹配,并试图克服(潜在的)词汇间隙。密集检索器在一个共享的密集向量空间中映射查询和文档。这使得文件表示法可以被预先计算和索引化。一个基于预训练的Transformers的双编码器神经结构在各种开放领域的问题回答任务中表现出了强大的性能。这种密集的方法最近被混合词汇密集的方法所扩展,其目的是结合两种方法的优势。另一项平行的工作提出了一种无监督的领域适应方法通过生成目标领域的合成查询来训练密集检索器。最后,ColBERT(BERT上的情境化后期交互)在标记层面上为查询和文档计算多个语境化的嵌入,并使用一个最大相似度函数来检索相关文档。
基于重排:神经重排方法使用第一级检索系统的输出,通常是BM25,并对文档进行重新排序,以创造一个更好的检索文档的比较。通过BERT的交叉注意机制,性能得到了明显的改善。然而是在高计算开销的缺点下。
3. BEIR基准
BEIR旨在为所有不同的检索任务提供一个一站式的零样本评估基准。为了构建一个全面的评估基准,选择方法对于收集具有理想属性的任务和数据集至关重要。对于BEIR,该方法是由以下三个因素促成的。
(i) 多样的任务:信息检索是一个多功能的任务,不同任务之间的查询和索引文件的长度可能不同。有时,查询很短,如一个关键词,而在其他情况下,它们可能很长,如一篇新闻文章。同样,索引的文件时长时短。
(ii) 多样的领域:检索系统应该在各种类型的领域中被评估。从广泛的领域如新闻或维基百科,到高度专业化的领域如某一特定领域的科学出版物。因此,我们包括了能够代表现实世界问题的领域,并且从通用到专业的各种领域。
(iii) 任务难度:我们的基准是具有挑战性的,所包括的任务的难度必须是足够的。 如果一个任务很容易被任何算法解决,那么比较用于评估的各种模型就没有用了。我们根据现有的文献对几个任务进行了评估,并选择了一些流行的任务,我们认为这些任务是最近开发的,具有挑战性,而且还没有被现有的方法完全解决。
(iv) 多样的注释策略:创建检索数据集本身就很复杂,而且会受到注释偏差的影响,这阻碍了对各种方法的公平比较。为了减少这种偏见的影响,我们选择了以许多不同方式创建的数据集。有些是由人群中的工作人员注释的,有些是由专家注释的,还有一些是基于大型在线社区的反馈。
总的来说,我们包括了来自9个不同的检索任务的18个英文零样本评价数据集。由于大多数被评估的方法都是在MS MARCO数据集上训练的,所以我们也报告了在这个数据集上的表现,但在我们的零样本比较中不包括这个结果。
表1:BEIR基准中的数据集的统计。少数数据集包含没有标题的文件。相关性表示查询与文档的关系:二进制(相关,不相关)或分为子级别。Avg. D/Q表示每次查询的平均相关文档。
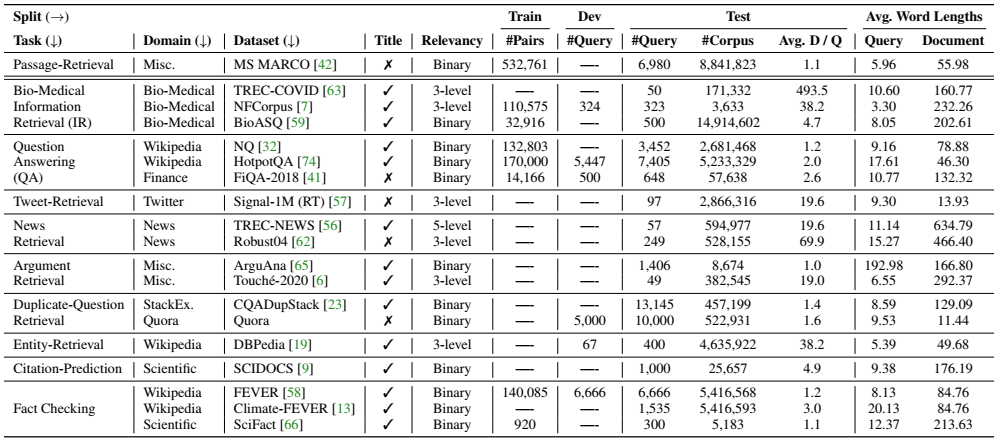
表1总结了BEIR中提供的数据集的统计数据。大多数的数据集包含二元相关性判断,即相关或不相关,少数数据集包含细粒度的相关性判断。一些数据集包含与查询相关的少量文档(<2),而其他数据集像TREC-COVID可以包含多达500个与查询有关的文档。在19个数据集中,只有8个数据集(包括MS MARCO)中只有8个有训练数据,这说明零样本检索基准的实际重要性。除了ArguAna之外,所有的数据集都有简短的查询(要么是一个单句或2-3个关键词)。图1显示了BEIR基准的任务和数据集的概况。
图1:BEIR基准中各种任务和数据集的概述
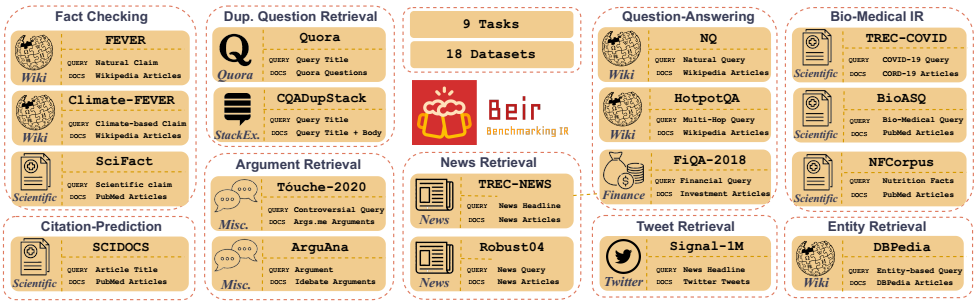
信息检索(IR)是无处不在的,每个任务都有很多数据集,检索任务的甚至更多。然而,将所有的数据集纳入评估基准是不可行的。我们试图将各种任务和数据集平衡地混合在一起并重视不超重的特定任务,如问题回答。未来的数据集可以很容易地集成到BEIR中,而且现有的模型可以在任何新的数据集上快速评估。
3.1 数据集和多样性分析
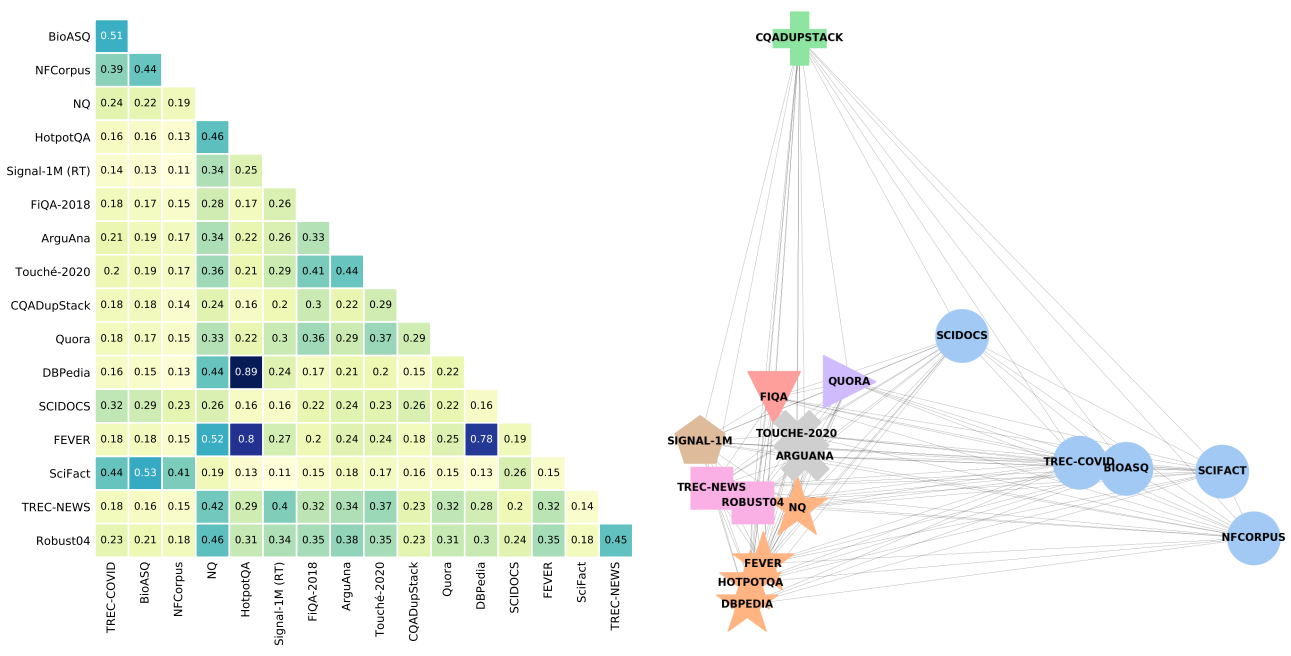
BEIR中的数据集选自不同的领域,从维基百科、科学出版物、Twitter、新闻到在线用户社区等等。为了衡量领域的多样性,我们使用一对加权的Jaccard相似性得分来计算成对的数据集之间的领域重叠度,即所有数据集对之间的单片词重叠。图2显示了表示成对加权jaccard分数的热图和聚类的力导向放置图。该图中距离较近的节点(或数据集)有较高的词语重合度,而图中距离较远的节点重合度较低。从图2中,我们观察到不同领域的加权Jaccard词重合度相当低,这表明BEIR是一个具有挑战性的基准,方法必须能很好地泛化到不同的分布外领域。
图2:BEIR基准中每个成对数据集的领域重叠。热图(左)显示了BEIR数据集之间的成对加权jaccard相似度得分,二维表示(右)使用NetworkX的强制定向放置算法。我们对不同领域的数据集用不同的颜色和标记。
3.2 BEIR软件和框架
BEIR软件提供了一个易于使用的Python框架(pip install beir)用于模型评估。它包含了大量的封装器,用于复制实验和评估来自知名资源库的模型,包括 Sentence-Transformers, Transformers, Anserini, DPR, Elasticsearch, ColBERT和 Universal Sentence Encoder。这使得该软件对学术界和工业界都很有用。该软件还提供了所有基于IR的指标,从精确率、召回率、MAP(平均精确率)、MRR(平均互换率)到nDCG(归一化累积折扣收益)的任何top-k命中。人们可以使用BEIR基准来在新的检索数据集上评估现有模型,并在包括的数据集上评估新模型。
数据集通常分散在网上,并以不同的文件格式提供,这使得在不同的数据集上对模型进行评估变得困难。BEIR引入了一种标准格式(语料库、查询和qrels),并将现有的数据集转换为这种简单的通用数据格式,允许在越来越多的数据集上更快地进行评估。
3.3 评价指标
根据现实世界应用的性质和要求,检索任务可以是以精度或召回率为重点。为了在BEIR中获得不同模型和数据集的可比结果,我们认为利用一个单一的评价指标是很重要的,该指标可以在所有任务中进行比较性计算。诸如精确度和召回率这样的决策支持指标是不合适的,因为它们都不知道等级。二进制等级意识指标,如MRR(平均互换率)和MAP(平均精度)无法评估具有分级相关性判断的任务。我们发现,归一化累积折扣收益(nDCG@k)提供了一个良好的平衡,适用于涉及二元和分级相关性判断的任务。
4. 实验设置
我们使用BEIR来比较不同的、最新的、最先进的检索架构,重点是基于transformer的神经方法。我们在公开可用的预训练检查点上进行评估。 由于基于transformer的网络长度限制,我们在所有神经架构的实验中只使用了所有文档中的前512个单词。

我们根据模型的结构对其进行分组:(i)词汇,(ii)稀疏,(iii)密集,(iv)后期交互和(v)重新排序。除了所包含的模型,BEIR基准是不可知的模型,在未来不同的模型配置可以很容易地纳入该基准。
(i) 词汇检索:
(a) BM25是一个常用的词袋检索函数,基于在两个具有TF-IDF标记权重的高维稀疏向量之间进行标记匹配。我们使用 Anserini的默认Lucene参数(k=0.9和b=0.4)。我们将标题(如果有的话)和段落作为文档的独立字段进行索引。在我们的排行榜上,我们还测试了Elasticsearch BM25和Anserini + RM3扩展,但发现Anserini BM25表现最好。
(ii) 稀疏检索:
(a) DeepCT使用在MS MARCO上训练的基于Bert-base的模型来学习术语权重频率(tf)。它生成了一个伪文件,其中的关键词与学习到的术语频率相乘。我们使用Dai和Callan的原始设置,结合BM25和默认的Anserini参数,我们根据经验发现其性能优于调整后的MS MARCO参数。
(b) SPARTA计算来自BERT的非语境化查询嵌入与语境化文档嵌入之间的相似度分数。这些分数可以为一个给定的文档预先计算,从而产生一个30k维的稀疏向量。我们在MS MARCO数据集上对DistilBERT模型进行了微调,并使用具有2000个非零项的稀疏向量。
© DocT5query是一种流行的文档扩展技术,使用在MS MARCO上训练的T5(base)模型来生成合成查询,并将其附加到原始文档中进行词法搜索。我们复制了Nogueira和Lin的设置,为每个文档生成40个查询,并使用BM25的默认Anserini参数。
(iii) 密集检索:
(a)DPR是一个双塔双编码器,用单一的BM25硬负片和批内负片训练。我们发现在我们的环境中,开源的Multi模型比单一的NQ模型表现更好。Multi-DPR模型是一个在四个QA数据集(包括标题)上训练的基于Bert-base的模型:NQ, TriviaQA, WebQuestions和 CuratedTREC。(b)ANCE是一个双编码器,从语料库的近似近邻(ANN)索引中构建硬负片,在模型的微调过程中平行更新以选择硬负片训练实例。我们使用公开的RoBERTa模型在MS MARCO上训练了600K步,用于我们的实验。
©TAS-B是一个使用平衡主题感知采样训练的双编码器,使用交叉编码器和ColBERT模型的双重监督。该模型是用成对的Margin-MSE损失和批量内负损失函数的组合来训练的。我们使用公开的DistilBERT模型进行实验。
(d)GenQ:是一种无监督的领域适应方法,通过对综合生成的数据进行训练来建立密集的检索模型。首先,我们在MS MARCO上对T5(基础)模型进行2次微调。 然后,对于一个目标数据集,我们使用top-k和nucleus-sampling的组合(top-k:25;top-p:0.95)为每个文档生成5个查询。由于资源的限制,我们将每个数据集中的目标文档的最大数量限定为100K。对于检索,我们继续使用合成查询和文档对数据的批量内否定法来微调TAS-B模型。注意,GenQ为每个任务创建一个独立的模型。
(iv)后期交互:
(a)ColBERT将查询和段落编码并表示为多个语境化的标记嵌入袋。后期交互以最大池化查询词的总和和所有段落词的点乘法进行汇总。 我们使用ColBERT模型作为密集检索器(端到端检索):首先使用ANN与faiss(faiss深度=100)检索前k个候选人,ColBERT通过计算后期聚合的互动重新排序。 我们在MS MARCO数据集上训练了一个基于Bert-base-uncased的模型,最大序列长度为300,步长为300K。
(v)重排模型:
(a)BM25 +CE对第一阶段BM25(Anserini)模型中检索到的前100个点击进行重排。我们评估了HuggingFace模型中心上公开的14种不同的交叉注意力重排模型,发现一个6层、384-h的MiniLM交叉编码器模型在MS MARCO上提供最佳性能。该模型是按照Hofstätter等人的设置在MS MARCO上使用知识蒸馏设置与三个教师模型的集合:BERT-base,BERT-large和ALBERT-large模型进行训练的。
训练设置:包括用于零样本评估的模型最初是以不同方式训练的。 DocT5query和DeepCT是为文档扩展和词语重新加权而训练的。交叉编码器(MiniLM)和SPARTA都是用排名数据训练的。所有密集检索模型(DPR、ANCE和TAS-B)和ColBERT是用混合训练的:排名数据和随机批内negatives。 另一个重要的区别在于硬negatives,少数模型是在更好的优化的硬negatives上训练的,而其他模型使用更简单的硬negatives,这可能意味着不公平的比较。DPR使用mined BM25硬negatives进行训练,ColBERT使用原始MS MARCO提供的硬negatives,ANCE使用mined近似硬negatives,而TAS-B使用交叉编码器和ColBERT模型以及BM25硬negatives进行交叉模型提炼。
5. 结果和分析
本节评估和分析了检索模型在BEIR基准上的表现。表2报告了所有被评估的系统在选定的基准数据集上的结果。以BM25为基准,将我们的检索系统与其进行了比较。图3显示,在多少个数据集上,各自的模型能够比BM25表现得更好或更差。
表2:在BEIR基准上的域内和零样本性能。所有分数表示nDCG@10。在一个给定的数据集上的最好成绩用粗体字标出,第二好的成绩用下划线标出。Z表示域内表现。
图3:与BM25进行的零样本神经检索性能比较。基于重排序的模型,即BM25+CE和稀疏模型:docT5query在超过一半的BEIR评估数据集上的性能优于BM25。
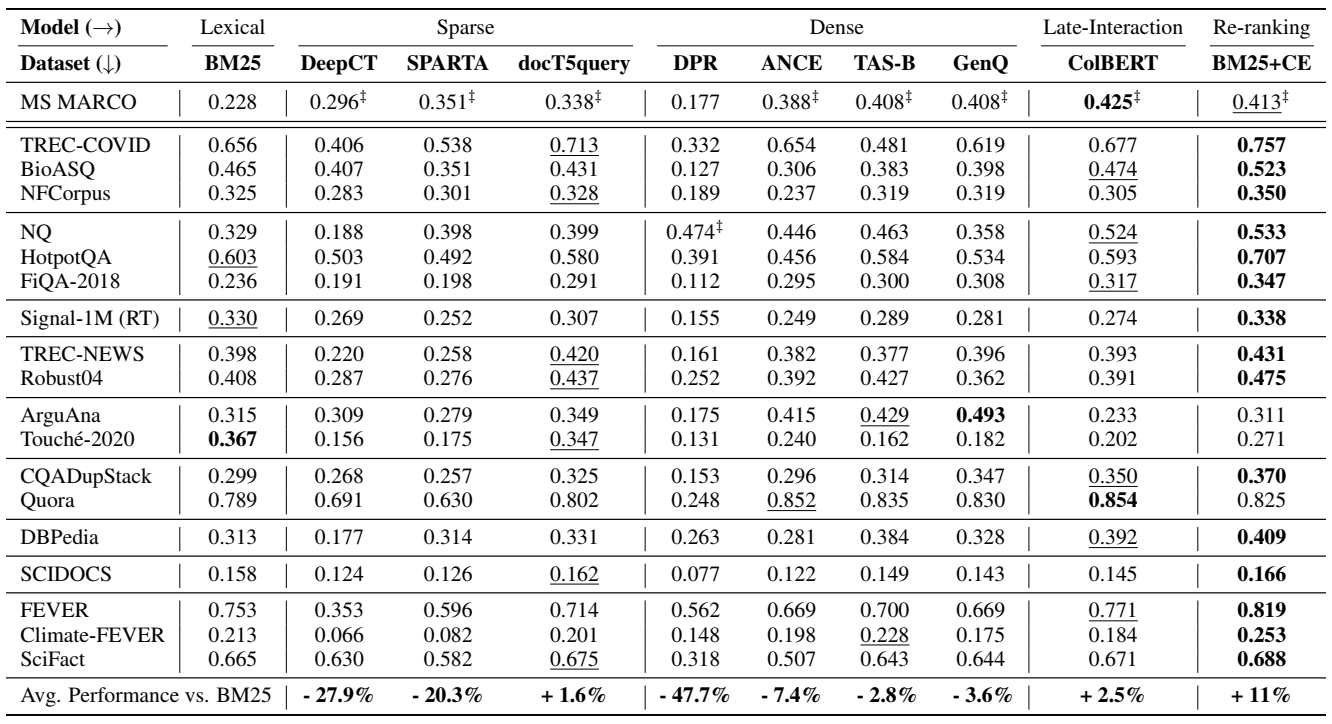
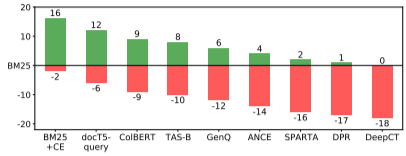
1.域内性能不是域外泛化的一个很好的指标。我们观察到BM25在域内MS MARCO上严重低于神经方法7-18分。然而,BEIR显示它是一个强大的泛化基线,并普遍优于许多其他更复杂的方法。这强调了这一点,即检索方法必须在广泛的数据集上进行评估。
2. 术语加权失败,文档扩展捕获域外关键字词汇表。 DeepCT和SPARTA都使用transformer网络来学习术语加权。虽然这两种方法在MS MARCO上的域内表现良好,但它们在几乎所有数据集上的表现都不如BM25。 相比之下,基于文档扩展的docT5query能够为文档添加新的相关关键词,并在BEIR数据集上表现出色。它在11/18个数据集上的表现优于BM25,而在其余数据集上的表现则具有竞争力。
3.带有分布外数据问题的密集检索模型。密集检索模型(尤其是ANCE和TAS-B)将查询和文档独立映射到矢量空间,在某些数据集上表现强劲,而在其他许多数据集上的表现明显不如BM25。例如,密集检索器被观察到在与它们被训练的数据集相比有很大的领域转移,如BioASQ,或像Touché-2020那样的任务转移。DPR,唯一的非MSMARCO训练的数据集,在基准上的泛化表现最差。
4.重排模型和晚期交互模型对分布外数据的泛化效果很好。交叉注意力重排模型(BM25+CE)表现最好,在几乎所有(16/18)数据集上都能超过BM25。它只在ArguAna和Touché-2020上失败,这两个检索任务与MS MARCO训练数据集极为不同。 晚期交互模型ColBERT为查询和文档独立计算标记嵌入,并通过类似MaxSim的交叉注意力操作对(查询,文档)进行评分。它的表现比交叉注意力重排模型稍弱,但仍能在9/18个数据集上超过BM25。看来交叉注意和交叉注意类操作对于良好的分布外泛化很重要。
5.密集检索的强训练损失导致了更好的分布外性能。TAS-B在其密集的同行中提供了最好的零点泛化性能,它分别在14/18和17/18数据集上超过了ANCE和DPR。我们推测原因在于TAS-B模型的域内批量否定和Margin-MSE损失相结合的强训练设置。TAS-B模型更倾向于检索长度较短的文档。这个训练损失函数(在知识蒸馏设置中具有强大的集成教师)显示出强大的泛化性能。
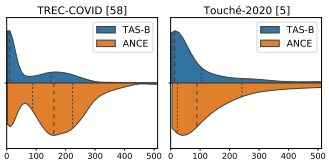
6.TAS-B模型更倾向于检索长度较短的文档。TAS-B在两个数据集上的表现低于ANCE:TREC-COVID为17.3分,Touché-2020为7.8分。我们观察到这些模型检索的文档长度有很大的不同,如图4所示。在 TREC COVID 上,TAS-B 检索文档的中值长度仅为10个单词,而 ANCE 为160个单词。同样,在 Touché-2020上,14个单词对89个单词分别使用 TAS-B 和 ANCE。这种对较短或较长文档的偏爱是由于所使用的损失函数造成的。
图4:使用TAS-B(蓝色,顶部)或ANCE(橙色,底部)检索到的前10个文档长度的分布图。TAS-B在BEIR中更偏向于短的文档。
7.域自适应是否有助于提高密度检索器的泛化?我们对GenQ进行了评估,它在合成查询数据上对TAS-B模型进行了进一步的微调。它在科学出版物、金融或StackExchange等专业领域的表现优于TAS-B模型,而在维基百科等更广泛和更通用的领域,它的表现则弱于原TAS-B模型。
5.1 效率:检索延迟和索引大小
模型需要在推理时将单个查询与数百万个文档进行比较,因此,需要一个实时检索结果的高计算速度。除了速度之外,索引大小也是至关重要的,通常完全存储在内存中。我们从DBPedia中随机抽取100万个文档,并评估延迟。对于密集模型,我们使用精确搜索,而对于晚期交互模型ColBERT,我们遵循原始设置并使用近似的近邻搜索。CPU上的性能是用8核Intel Xeon Platinum 8168 CPU @2.70GHz测量的,GPU上使用单个Nvidia Tesla V100, CUDA 11.0。
表3:DBPedia中单个查询的平均检索延迟和索引大小的估计。在零样本BEIR上从最佳到最差排名。希望延迟或内存更低。
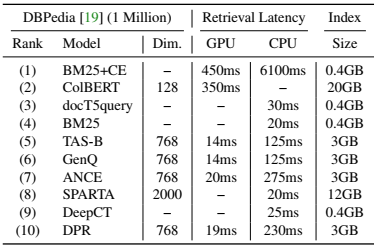
性能和检索延迟之间的权衡:通过重新排列前100名的BM25文档和使用晚期交互模型的最佳分布外泛化性能是以高延迟(>350毫秒)为代价的,在推理时最慢。相反,密集检索器与重新排列模型相比,速度快20-30倍(<20毫秒),并遵循低延迟模式。在CPU上,稀疏模型在速度方面占优势(20-25毫秒)。
性能和索引大小之间的权衡:词汇、重新排序和密集方法的索引大小最小(<3GB),以存储来自DBPedia的100万个文档。SPARTA需要第二大索引来存储30k dim的稀疏向量,而ColBERT需要最大的索引,因为它为一个文档存储多个128 dim的密集向量。索引大小在文档规模扩大时尤其相关:ColBERT需要约900GB来存储BioASQ(约15M文档)索引,而BM25只需要18GB。
6. 注释选择偏见的影响
创建一个完全无偏见的检索评估数据集本身就很复杂,而且会受到以下因素的影响:(i)注释指南,(ii)注释设置,以及(iii)人类注释者。此外,不可能对所有的(查询,文档)对的相关性进行手工注释。相反,现有的检索方法被用来获得一个候选文档库,然后对其相关性进行标记。所有其他未见过的文档都被认为是不相关的。这是选择偏差的来源:一个新的检索系统可能会检索到与用于注释的系统大不相同的结果。这些命中自动被认为是无关紧要的。
许多BEIR数据集被发现受到词汇偏差的影响,即基于词汇的检索系统,如TF-IDF或BM25被用来检索用于注释的候选词。例如,在BioASQ中,通过带有提升标签的术语匹配来检索候选词进行注释。创建Signal-1M(RT)涉及检索查询的推文,这8种技术中的7种都依赖于词汇术语匹配信号。这种词汇偏见不利于不依赖于词汇匹配的方法,如密集检索方法,因为检索到的没有词汇重叠的命中会自动被认为是不相关的,即使这些命中可能与查询有关。
为了研究这种特殊偏见的影响,我们对最近的TREC-COVID数据集进行了研究。TREC-COVID使用了一种池化方法来减少上述偏见的影响:注释集是通过使用参加挑战赛的各个系统的搜索结果构建的。表4显示了被测系统的Hole@10率,即每个系统检索到的前10名中有多少没有被注释者看到。
表4:对TREC-COVID的Hole@10分析。注释的分数显示了在每个模型中去除Hole@10(注释者未见过的前10个点击中的文件)后的性能改进。

结果显示了不同方法之间的巨大差异:像BM25和docT5query这样的词汇方法的Hole@10值相当低,分别为6.4%和2.8%,表明注释池中包含来自词汇检索系统的热门命中。相比之下,ANCE 和 TAS-B 等密集检索系统的 Hole@10分别为14.4% 和31.8% ,这表明这些系统发现的大部分命中没有被注释者判断。接下来,我们对所有的系统进行了手工添加,按照最初的注释指南添加了缺失的注释(或漏洞)。在注释过程中,我们不知道是哪个系统检索了缺失的注释,以避免偏好偏差。 我们在TREC-COVID中总共注释了980个查询文档对。然后,我们用这些额外的注释重新计算了所有系统的nDCG@10。
如表4所示,我们观察到词法仅有轻微的改善,例如,对于docT5query,在增加了缺失的相关性判断后,仅从0.713提高到0.714。 相反,对于密集检索系统ANCE来说,性能从0.654(略低于BM25)提高到0.735,比BM25的性能高6.7分。ColBERT 也有类似的改进(5.8分)。尽管许多系统为 TREC-COVID 注释池做出了贡献,但是注释池仍然偏向于词法方法。
7. 结论和未来工作
在这项工作中,我们提出了BEIR:一个用于信息检索的异质性基准。我们提供了更广泛的目标任务选择,从狭窄的专家领域到开放的领域数据集。我们包括9个不同的检索任务,跨越18个不同的数据集。
通过开源BEIR,并为许多不同的检索策略提供标准化的数据形式和易于适应的代码示例,我们向统一的基准迈出了重要的一步,以评估检索系统的零样本能力。希望它能引导创新,实现更强大的检索系统,并对哪些检索架构在不同任务和领域中表现良好有新的认识。
我们研究了十种不同的检索模型的有效性,并证明域内性能不能预测一种方法在零样本设置中的通用性。许多在MS MARCO的域内评估中表现优于BM25的方法,在BEIR数据集上表现不佳。交叉注意力重排、晚期交互ColBERT和文档扩展技术docT5query在所评估的任务中总体表现良好。
我们对注释选择偏差的研究突出了在现有数据集上评估新模型的挑战:即使TREC-COVID是基于许多系统的预测,由不同的团队贡献,我们发现测试系统的Hole@10率大不相同,对非词汇方法有负面影响。为了对检索方法进行公平的评估,需要更好的数据集,使用不同的集合策略。通过将大量不同的检索系统整合到BEIR中,创建这种不同的集合变得非常简单。
8. BEIR基准的局限性
尽管我们在BEIR中涵盖了广泛的任务和领域,但没有一个基准是完美的,有其局限性。明确这些是理解基准结果的关键点,也是为了今后的工作提出更好的基准。
1.多语言任务:虽然我们的目标是建立一个多样化的检索评估基准,但由于多语言检索数据集的可用性有限,目前BEIR基准中涵盖的所有数据集都是英语。作为基准的下一步,值得增加更多的多语言数据集(考虑到选择标准)。 未来的工作可以包括多和跨语言任务和模型。
2.长文档检索:我们的大多数任务的平均文档长度为几百个字,大致相当于几个段落,包括需要检索较长文档的任务将是高度相关的。然而,由于基于转换器的方法通常有512个单词片段的长度限制,因此需要一个根本性不同的设置来比较方法。
3.多因素检索:到目前为止,我们在BEIR中关注的是纯文本检索。在许多现实世界的应用中,进一步的信号被用来估计文档的相关性,如PageRank、recency、authority score或用户互动,如点击率。在已测试的方法中,对这些信号的整合往往不是直接的,是一个有趣的研究方向。
4.多字段检索:检索通常可以在多个字段上进行。例如,对于科学出版物,我们有标题、摘要、文档正文、作者名单和期刊名称。到目前为止,我们只关注有一个或两个字段的数据集。
5.特定任务的模型:在我们的基准中,我们重点评估那些能够对广泛的检索任务进行概括的模型。自然,在现实世界中,对于一些少数的任务或领域,专用的模型可以很容易地胜过通用模型,因为它们专注于一个单一的任务并表现良好,比如在问题回答上。这种特定于任务的模型不一定需要泛化所有不同的任务。