多源跨语言模式迁移:学习分享什么
https://zhuanlan.zhihu.com/p/83257202
摘要
利用神经网络模型,现代NLP应用已经享受了巨大的推动。然而,由于缺乏各种NLP任务的标注训练数据,这种深度神经模型不适用于大多数人类语言。跨语言迁移学习(CLTL)是一种通过利用来自其他(源)语言的标记数据来为低资源目标语言建立NLP模型的可行方法。在这项工作中,我们将重点放在多语言转换设置上,利用多种源语言的训练数据来进一步提高目标语言的性能。
与大多数现有的只依赖于CLTL的语言不变特征的方法不同,我们的方法在实例级连贯地利用了语言不变和语言特定的特征。我们的模型利用对抗性网络来学习语言不变的特征,利用专家混合模型来动态利用目标语言和每种源语言之间的相似性。这使得我们的模型能够有效地学习在多语言环境中不同语言之间共享的内容。
此外,当与无监督的多语言嵌入结合时,我们的模型可以在零资源设置中操作,其中既没有目标语言训练数据也没有跨语言资源。与现有技术相比,我们的模型实现了显著的性能增益,如在包括大规模行业数据集在内的多个文本分类和序列标记任务上的大量实验中所示。
介绍
深度学习的最新进展使各种各样的NLP模型实现了令人印象深刻的性能,这在一定程度上归功于大规模带注释数据集的可用性。然而,这种优势对于世界上大多数语言来说都是不可用的,因为它们中的许多语言缺乏为各种NLP任务训练深度神经网络所必需的标记数据。由于不可能获得所有感兴趣语言的训练数据,跨语言迁移学习(CLTL)提供了利用其他语言(源语言)的注释数据学习目标语言模型的可能性(Yarowsky et al .,2001)。在本文中,我们专注于更具挑战性的无监督CLTL设置,其中没有目标语言标记的数据用于训练。
传统上,大多数关于CLTL的研究都致力于标准的双语转换(BLTL)案例,其中训练数据来自单一的源语言。然而,在实践中,经常会出现这样的情况:我们已经用几种语言标记了数据,并且希望在转换到其他语言时能够利用所有的数据。以前的工作(McDonald等人,2011)确实表明,从多种源语言进行转换可以显著提高性能。因此,在这项工作中,我们将重点放在多源CLTL场景,也被称为多语言迁移学习(MLTL),以进一步提高目标语言的表现。
CLTL采用的一种直接方法是权重共享,即在将两种语言映射到一个公共嵌入空间后,将基于源语言训练的模型直接应用到目标语言。 然而,如之前的工作(Chen等人,2016)所示,由同一神经网络提取的来自不同语言的样本的隐藏特征向量的分布仍然是(divergent) 不同的,因此权重共享对于学习能够很好地跨语言概括的语言不变的特征空间是不够的。。因此,之前的工作探索了使用语言对抗训练(Chen et al., 2016; Kim等人(2017)只使用(非并行的)每种语言中未标记文本,提取与语言变化相关的不变特征。
另一方面,在多种源语言的MLTL环境中,语言对抗训练将只使用在所有源语言和目标语言中通用的特征(学到的东西比较少,大家都有才学),这在许多情况下可能过于严格。例如,当从英语、西班牙语和汉语转换到德语时,语言对抗训练将仅保留在所有四种语言中不变的特征,这可能太稀疏而不能提供信息。此外,德语更类似于英语而不是汉语的事实被忽略了,因为转换的模型不能利用仅在英语和德语之间共享的特征。
为了解决这些缺点,我们提出了一个新的MLTL模型,它不仅利用了语言不变的特性,还允许目标语言通过概率注意风格的专家混合机制,动态地、选择性地利用特定于语言的特征(见§3)。这允许我们的模型有效地学习不同语言之间共享的内容。 本文的另一个贡献是,当与最近的无监督跨语言单词嵌入(Lample等人,2018;Chen和Cardie,2018b)相结合时,我们的模型能够在零资源环境下运行,其中既没有特定任务的目标语言注释,也没有通用跨语言资源(例如平行语料库或机器翻译(MT)系统)。与许多现有的CLTL工作相比,这是一个优势,使我们的模型更广泛地适用于许多低资源语言。
模型利用对抗网络来学习语言不变的特性,并使用专家混合模型来动态地利用目标语言和每个源语言之间的相似性。
我们在多个MLTL任务上评估了我们的模型,从文本分类到命名实体识别和语义槽填充,包括真实世界的行业数据集。我们的模型击败了所有像我们这样没有跨语言资源的基线模型。更引人注目的是,在许多情况下,它可以匹配或优于能够访问强大的跨语言监管的最先进的模型(例如,商业机器翻译系统)。
2 Related Work
人类语言的多样性是自然语言处理的关键挑战。为了减轻获取每种语言中每个任务的注释数据的需要,跨语言迁移学习(CLTL)一直在研究(Yarowsky 等人,2001;Bel 等人,2003 等)。
特别是对于无监督的 CLTL,在没有目标语言训练数据可用的情况下,大多数先前的研究都调查了双语迁移设置。传统上,研究侧重于基于资源的方法,其中使用通用跨语言资源(例如 MT 系统或并行语料库)来替换特定任务的注释数据(Wan,2009;Prettenhofer 和 Stein,2010)。随着深度学习的出现,尤其是对抗性神经网络(Goodfellow 等人,2014 年;Ganin 等人,2016 年),基于模型的 CLTL 方法取得了进展。陈等人。 (2016) 提出了不直接依赖于并行语料库的语言对抗训练,而只需要一组双语词嵌入 (BWE)。
另一方面,虽然对多语言迁移环境的研究较少,但也进行了研究(McDonald等人,2011年;Naseem等人,2012年;Täckström等人,2013年;Hajmohammadi等人,2014年;Zhang和Barzilay,2015年;Guo等人,2016年),与双语迁移中使用来自一种源语言的标记数据相比,表现出了更好的性能。
CLTL的另一个重要方向是学习跨语言单词表征(Klementiev等人,2012年;Zou等人,2013年;Mikolov等人,2013年)。最近,在学习完全无监督的跨语言单词嵌入方面有几项值得注意的工作,包括双语(Zhang等人,2017年;Lample等人,2018年;Artetxe等人,2018年)和多语言案例(Chen和Cardie,2018b)。这些努力为在没有跨语言资源的情况下执行CLTL铺平了道路。
最后,与MLTL相关的一个领域是多源域适配(Mansour等人,2009年),在此之前的大部分工作都依赖于对域不变特征的学习(Zhao等人,2018年;Chen和Cardie,2018a)。Ruder等人(2019年)提出了域间选择性共享的一般框架,但他们的方法在任务级别学习静态权重,而我们的模型可以在实例级别动态选择要共享的内容。最近的一项工作(郭等人,2018年)试图对目标域和每个源域之间的关系进行建模。我们的模型结合了这些方法的优点,能够以一致的方式同时利用领域不变和领域特定的特征 。
3 Model
一种常用的神经跨语言迁移范式是共享-私有模型(Bousmalis et al., 2016),其中特征分为两部分:共享(语言不变)特征和私有(语言特定)特征。如前所述,通过语言对抗训练,通过试图欺骗语言鉴别器,强制共享特征是语言不变的。此外,Chen 和 Cardie (2018a) 提出了一种用于多源设置的通用共享私有模型,其中采用多项对抗网络 (MAN) 来提取所有源语言和目标语言共享的共同特征。另一方面,私有特征由单独的特征提取器学习,每个源语言一个,捕获共享特征之外的剩余特征。在训练期间,来自某种源语言的标记样本通过该特定语言的相应私有特征提取器。
在测试时,目标语言没有私有特征提取器;只有共享特征用于跨语言迁移。
如第 1 节所述,仅使用 MLTL 的共享特征会施加过强的约束,如果它们仅在目标语言和源语言的子集之间共享,许多有用的特征可能会被对抗训练消除。因此,我们建议使用混合专家 (MoE) 模型 (Shazeer et al., 2017; Gu et al., 2018) 来学习私有特征。这个想法是拥有一组语言专家网络,每种源语言一个,每个网络负责在训练期间学习该源语言的语言特定特征。然而,不是在专家之间硬切换,每个样本使用所有专家的凸组合,由专家门决定。因此,在测试时,经过训练的专家门可以基于未知目标语言与源语言的相似性来决定该未知目标语言的最佳专家权重。
图 1 显示了我们用于多语言模型迁移的 MAN-MoE 模型的概述。方框说明了 MAN-MoE 模型的各种组件(第 3.1 节),而箭头描绘了训练流程(第 3.2 节)。
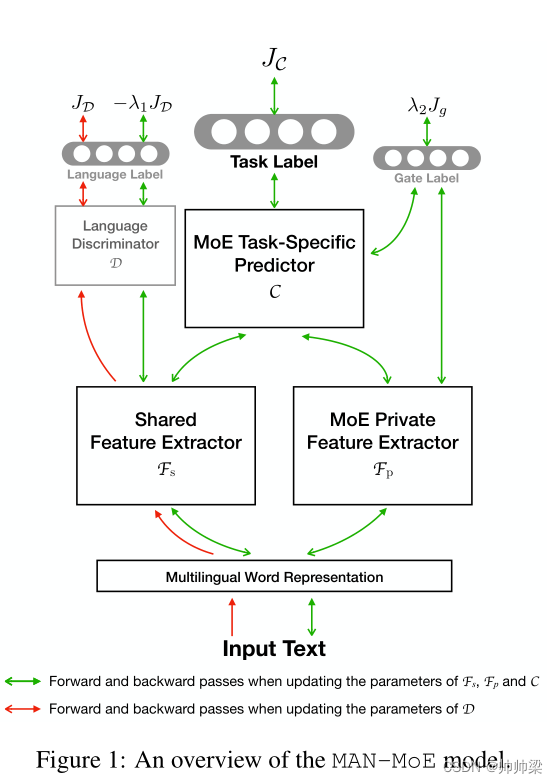
3.1 模型架构
图 1 描绘了 MAN-MoE 模型的抽象视图,包含四个组件:多语言词表示、MAN 共享特征提取器 Fs(连同语言鉴别器 D)、MoE 私有特征提取器 Fp,最后是 MoE 预测器 C。在实际任务中(例如序列标记、文本分类、序列到序列等),可能会采用不同的架构,如下所述。
Multilingual Word Representation : 将来自所有语言的单词嵌入到一个单一的语义空间中,以便具有相似含义的单词彼此接近,而不管语言如何。在这项工作中,我们主要依赖于 MUSE 嵌入(Lample 等人,2018 年),它们以完全无监督的方式进行训练。我们将所有其他语言映射为英语以获得多语言嵌入空间。然而,在某些实验中,MUSE在一个或多个语言对上的准确度为0(Søgaard等人,2018),在这种情况下,使用VecMap嵌入(Artetxe等人,2017)。它使用相同的字符串作为监督,不需要平行语料库或人工注释。
我们进一步实验了最近的无监督多语言单词嵌入(Chen和Cardie,2018b),这提供了改进的性能(4.2)。
此外,对于形态特征很重要的任务,可以添加捕获子词信息的字符级词嵌入(Dos Santos 和 Zadrozny,2014)。(这几句话所表达的意思就是不同的任务,可能会添加其他的结构或方法来扩充)当使用字符嵌入时,我们添加了一个跨所有语言共享的 CharCNN,最终的单词表示是单词嵌入和字符级嵌入的串联。然后可以与模型的其余部分端到端地训练 CharCNN。
MAN Shared Feature Extractor : Fs 是一个多项对抗网络(Chen 和 Cardie,2018a),它是特征提取器(例如 LSTM 或 CNN)和语言鉴别器 D 的对抗性对。D 是文本分类器(Kim,2014)获取输入序列的共享特征(由 Fs 提取)并预测它来自哪种语言。另一方面,Fs 努力欺骗 D,使其无法识别样本的语言。假设是,如果 D 无法识别输入的语言,则共享特征不包含语言信息,因此是语言不变的。请注意,D 仅使用未标记的文本进行训练,因此可以在包括目标语言在内的所有语言上进行训练。
MoE Private Feature Extractor : Fp 与以前的工作有一个关键区别,如图 2 所示。该图显示了具有三种源语言(英语、西班牙语和中文)的 Mixture-of-Experts (Shazeer et al., 2017) 模型。Fp 在底部有一个共享的 BiLSTM,它为输入句子中的每个标记 w 提取上下文化的单词表示。然后将 LSTM 隐藏表示 hw 输入 MoE 模块,其中每种源语言都有一个单独的专家网络(MLP)。
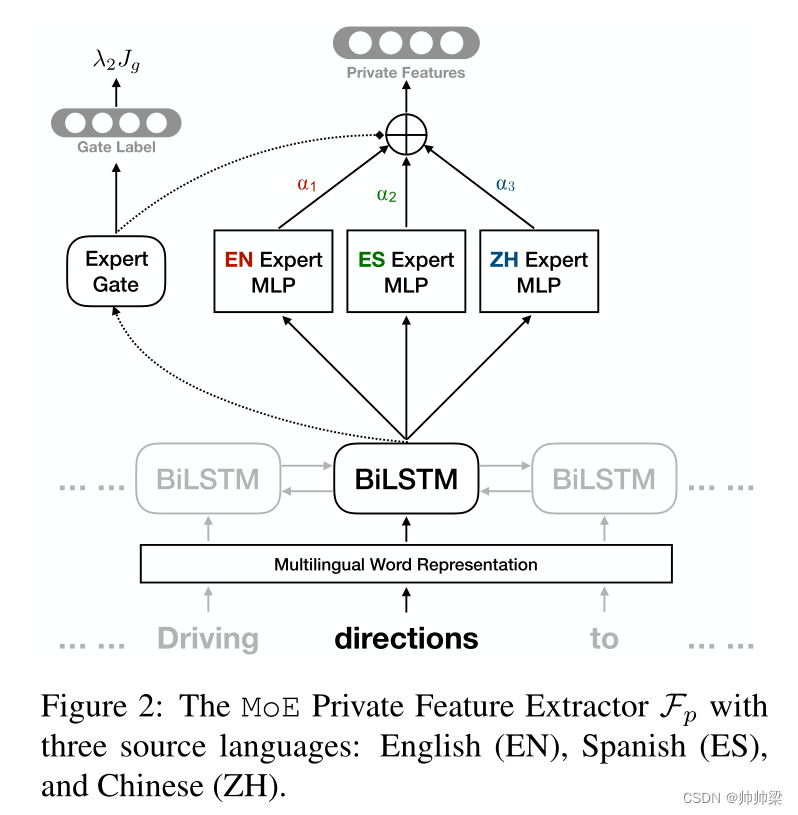
此外,专家门G是一个线性变换,它将hw作为输入,并为每个专家输出一个softmax得分αi。最终的私有特征向量是所有专家输出的混合,由专家门权重α决定。
在训练期间,专家门使用门损失 J g J_g Jg来预测样本的语言,其中专家门输出α被视为预测语言的softmax概率。换句话说,语言预测越准确,使用正确的专家就越多。因此, J g J_g Jg用于鼓励来自某一源语言的样本使用正确的专家,因此每个专家都在学习该语言的特定语言特性。 由于BiLSTM在训练期间暴露于所有源语言,经过训练的专家门将能够检查令牌的隐藏表示,以预测最佳专家权重α,即使是在测试时看不见的目标语言。(使用这个专家的权重来预测得到的正确率更好,那么就会给这个语言的专家网络提供更多的权重,因为最终的结果是所有专家的混合,所以每个专家占多数比例就需要一个东西来控制,也就是我们的权重系数。)
例如,如果德语测试样本与英语训练样本相似,则训练专家门将为英语专家预测更高的α,导致在最终特征向量中更多地使用它。因此,即使对于不可预见的目标语言(例如德语),Fp也能够在标记级别动态地确定使用来自每个单独的源语言的什么知识。
MoE Task-Specific Predictor:C 是对最终任务进行预测的最终模块,并且可以根据任务采取不同的形式。
例如,对于序列标记任务,共享和私有特征首先连接到每个标记,然后通过类似于 F p F_p Fp 的 MoE 模块(如附录中的图 6 所示)。使 C 适应其他任务很简单。例如,对于文本分类,在底部添加了一个池化层,如点积注意力 (Luong et al., 2015),将标记级特征融合为单个句子特征向量。

C 首先将共享特征和私有特征连接起来,为每个标记形成单个特征向量。然后它有另一个 MoE 模块,该模块在每个标记的所有标签上输出一个 softmax 概率。其想法是,对于不同的目标语言,在语言不变量和特定于语言的特征之间设置不同的权重可能是有利的。 再看看英语、德语、西班牙语和汉语的例子。 当从其他三种语言转换为汉语时,源语言彼此相似,但都与汉语相距甚远。因此,在这种情况下,通过敌对方式学习到的共享特性可能更为重要。
另一方面,当转换到德语时,德语更像英语而不是汉语,我们可能要更加注意MoE的私有特性。因此,我们在C中采用了一个MoE模块,这比使用单个MLP提供了更多的灵活性。
3.2 Model Training
将所有 N 种源语言的集合表示为 S,其中 |S| = N 。将目标语言表示为 T ,令Δ = S∪ T 为所有语言的集合。将源语言 l∈ S 的带注释语料库表示为 Xl,其中 (x, y)∼ Xl 是从 Xl 中抽取的样本。此外,所有语言都需要未标记的数据以促进 MAN 训练。因此,我们将来自语言 l0∈Δ 的未标记文本表示为 Ul0。
不同组件的总体训练流程如图1所示,而训练算法在算法1中描述。与MAN类似,有两个单独的优化器来训练MAN-MoE,一个更新D的参数(红色箭头),另一个更新所有其他模块的参数(绿色箭头)。在算法1中,LC、LD和Lg分别是Fp和C中预测器C、语言鉴别器D和专家门的损失函数。

在实践中,我们将NLL损失用于文本分类的LC,以及标记级别的NLL损失用于序列标记:
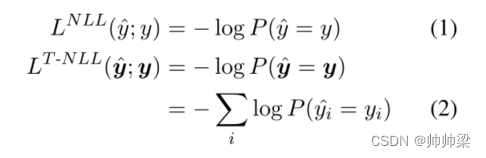
其中 y 是标量类标签,y 是标记标签的向量。因此,LC 被解释为预测正确任务标签的负对数似然。类似地,D 采用(1)中的 NLL 损失来预测样本的正确语言。最后,专家门 G 在 (2) 中使用标记级 NLL 损失,这转化为对样本中的每个标记使用正确语言专家的负对数似然。
因此,C、D 和 G 最小化的目标分别是: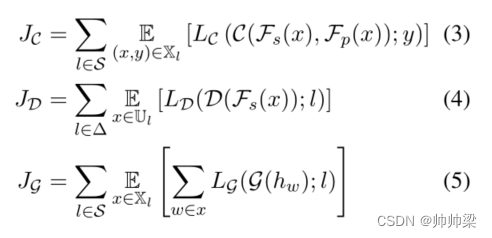
其中 (5) 中的 hw 是 Fp 中的 BiLSTM 隐藏表示,如图 2 所示。此外,请注意,D 是使用所有语言 (Δ) 的未标记语料库训练的,而 Fp 和 C(以及 G)的训练仅发生在源语言 (S) 上。最后,总体目标函数为:
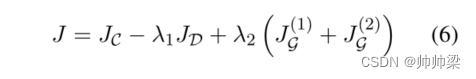
其中 J (1) G 和 J (2) G 分别是 Fp 和 C 中的两个专家门。更多实施细节可以在附录 B 中找到。
4 Experiments
在本节中,我们展示了一组跨三个数据集的广泛实验。第一个实验是在真实世界的多语言槽填充(序列标记)数据集上进行的,其中数据用于商业个人虚拟助理。此外,我们在两个公共学术数据集上进行了实验,即 CoNLL 多语言命名实体识别(序列标记)数据集(Sang,2002;Sang 和 Meulder,2003)和多语言亚马逊评论(文本分类)数据集(Prettenhofer 和 Stein , 2010)。
4.1 Cross-Lingual Semantic Slot Filling
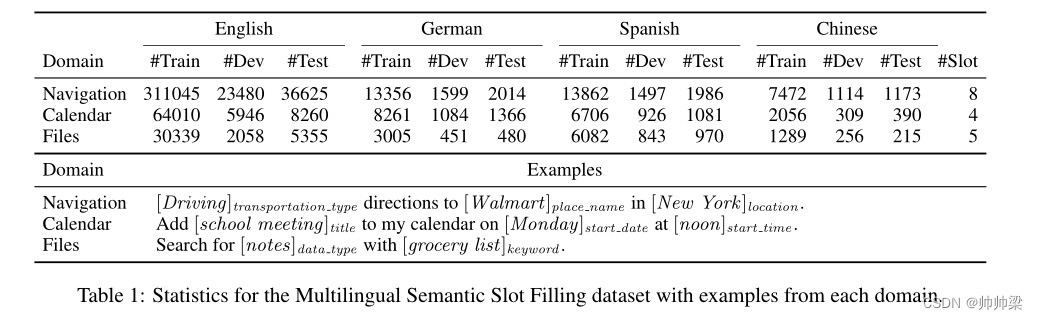
如表1所示,我们收集了四种语言的数据:英语、德语、西班牙语和中文,涉及三个领域:导航、日历和文件。每个域都有一组预先确定的槽(槽在各种语言中是相同的),每种语言和域中的用户话语都由群组工作人员用正确的槽进行注释(参见表1中的示例)。我们采用标准的生物标记方案将槽填充问题公式化为序列标记任务。
对于每个领域和语言,数据被分为训练集、验证集和测试集,表1显示了每个部分中的样本数。在我们的实验中,我们将每个领域视为一个单独的实验,并将德语、西班牙语和汉语中的每一种视为目标语言,而其余三种为源语言,这导致了总共9个实验。
4.1.1 Results
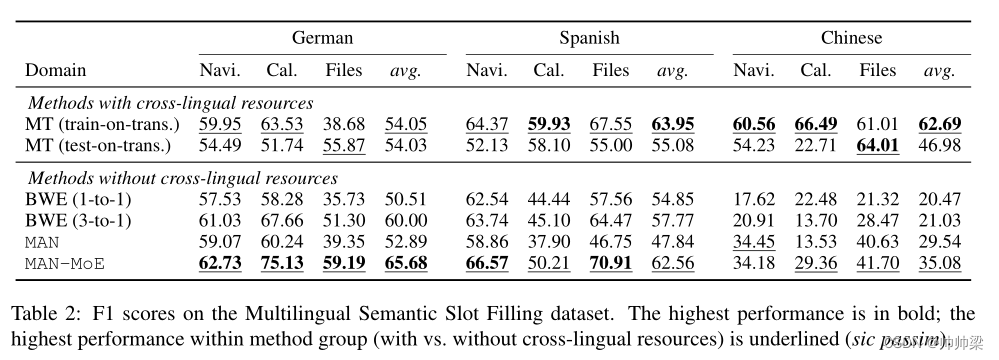
在表2中,我们报告了MAN-MoE与许多基准系统相比的性能。所有系统都采用相同的基础架构,这是一个多层BiLSTM序列标记器(Irsoy和Cardie,2014年),顶部是token级MLP(没有使用CRF)。
MT基线: 使用机器翻译(MT)进行跨语言转换。具体地说,Train-on-Transl(Train-on-Translation)方法将整个英语训练集翻译成每种目标语言,这些目标语言又被用来训练关于目标语言的监督系统。
另一方面,test-on-translation 方法训练一个英语序列标注器,并利用 MT 将每种目标语言的测试集翻译成英语以进行预测。
在这项工作中,我们采用了强大的商业 MT 系统 Microsoft Translator4。请注意,要使 MT 系统用于序列标记任务,必须提供单词对齐信息,以便跨语言投射单词级注释。这排除了许多 MT 系统,例如 Google Translate,因为它们不通过其 API 提供单词对齐信息。
BWE 基线 : 依赖于双语词嵌入 (BWE) 和 CLTL 的权重共享。即,在源语言上训练的序列标注器直接应用于目标语言,希望 BWE 能够弥合语言差距。这种简单的方法已被证明在最近的工作中产生了强大的结果(Upadhyay 等人,2018 年)。本实验中的所有系统都使用 MUSE(Lample 等人,2018)BWE。 1 比 1 表示我们仅从英语进行转换,而 3 比 1 表示利用了所有其他三种语言的训练数据。
最后的基线是 MAN 模型 :(Chen 和 Cardie,2018a),在我们的 MAN-MoE 方法之前提出。如表 2 所示,MAN-MoE 在几乎所有领域和语言上都大大优于所有未采用跨语言监督的基线系统。另一个有趣的观察结果是,与 BWE 基线相比,MAN 在中文方面表现出色,而在德语和西班牙语方面表现较差。这证实了我们的假设,即 MAN 仅利用在所有语言中不变的特征用于 CLTL,并且它比权重共享更好地学习这些特征。因此,当转移到类似于源语言子集的德语或西班牙语时,MAN 的性能会显着下降。
另一方面,当中文作为目标语言时,所有源语言都与其相距甚远,MAN在提取可以泛化到中文的语言不变特征方面有其优点。然而,对于 MAN-MoE,MAN 和 MoE 的组合很好地解决了远近语言对之间的这种权衡。通过利用语言不变和语言特定的特征进行迁移,MAN-MoE 在所有语言上都优于所有跨语言无监督基线。
此外,即使与可以访问数亿个并行句子的 MT 基线相比,MAN-MoE 在德语和西班牙语上的表现也具有竞争力。它甚至在德语上明显优于两个 MT 系统,因为 MT 有时无法为德语提供准确的单词对齐。在中文上,无监督 BWE 的准确度要低得多(BWE 基线仅达到 20% F1),MAN-MoE 能够大大提高 BWE 和 MAN 基线,并且即使在远距离语言对之间也显示出有希望的零资源 CLTL 结果。
4.1.2 Feature Ablation
在本节中,我们将仔细研究 MAN-MoE 的各个模块及其对性能的影响(表 3)。当 C 中的 MoE 被移除时,所有语言都观察到适度的下降。
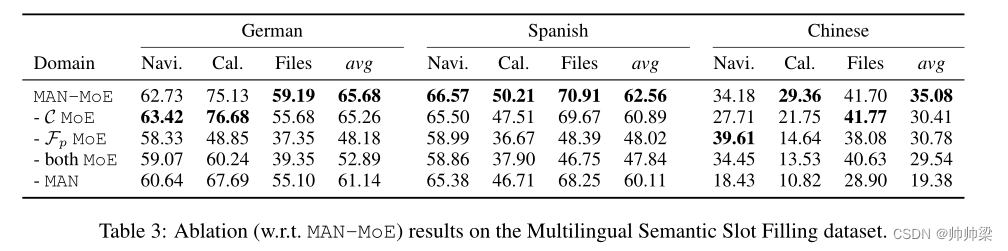
中文的性能下降最多,这表明当目标语言与源语言不相似时,在 C 中使用单个 MLP 并不理想。(没懂)当移除私有 MoE 时,C 中的 MoE 不再有意义,因为 C 只能访问共享特性,而且性能甚至比移除两个 MoE 稍差。 去掉两个 MoE 模块后,它就变成了 MAN 模型,我们看到德语和西班牙语显着下降。最后,在保留 MoE 的同时删除 MAN 时,共享特征只是通过权重共享来学习的,我们看到德语和西班牙语略有下降,但中文则相当不错。消融结果支持我们的假设并验证了 MAN-MoE 的优点。(没太懂啊)
4.2 Cross-Lingual Named Entity Recognition
在本节中,我们将介绍 CoNLL 2002 和 2003 多语言命名实体识别 (NER) 数据集(Sang,2002;Sang 和 Meulder,2003)的实验,其中包含四种语言:英语、德语、西班牙语和荷兰语。该任务也被表述为一个序列标记问题,有四种类型的标记:PER、LOC、ORG 和 MISC。
结果总结在表 4 中。我们观察到仅使用词嵌入并不能产生令人满意的结果,因为词汇表外的问题相当严重,而大写等形态特征对于 NER 至关重要。因此,我们为此任务(第 3.1 节)添加了字符级词嵌入,以捕获子词特征并缓解 OOV 问题。然而,对于德语,所有名词都是大写的,而在其他三种语言上学到的大写特征会导致结果不佳。因此,仅对于德语,我们将采用 CharCNN 的系统中的所有字符小写。
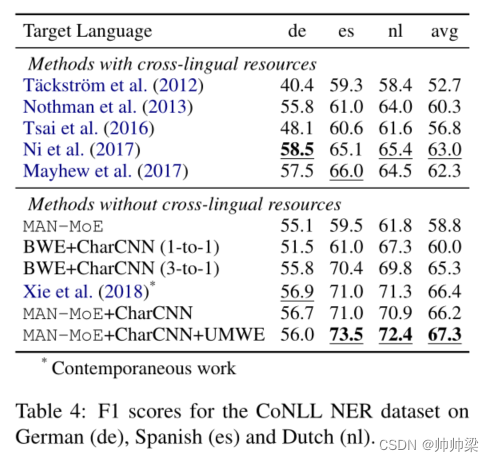
表 4 还显示了文献中几种最先进模型的性能,请注意,这些系统中的大多数都是专门为 NER 任务设计的,并利用许多特定于任务的资源,例如多语言地名词典,或 Freebase 或 Wikipedia 中的元数据(例如实体类别)。其中,Täckström 等人。 (2012)依靠并行语料库来学习作为特征的跨语言词簇。诺斯曼等人。 (2013);蔡等人。 (2016)都利用外部知识库(如维基百科)中的信息来学习跨语言 NER 的有用特征。使用嘈杂的平行语料库(对齐的句子对,但并不总是翻译)和双语词典(每个语言对 5k 个单词)进行模型迁移。他们进一步添加了外部功能,例如从 Wikipedia 学习的实体类型以提高性能。最后,Mayhew 等人。 (2017)提出了一个利用大型跨语言词汇的多源框架。尽管没有使用这些一般或特定任务的资源,MAN-MoE 仍然优于所有这些方法。唯一的例外是德语,由于其独特的大写规则和高 OOV 率,特定于任务的资源仍然有用。
在 (Xie et al., 2018) 的同时期工作中,他们提出了一种使用 Bi-LSTM-CRF 的跨语言 NER 模型,该模型与 MAN-MoE+CharCNN 相比具有相似的性能。但是,我们的架构不是专门针对 NER 任务的,我们没有添加特定于任务的模块,例如 CRF 解码层等。
最后但同样重要的是,我们将 MUSE 嵌入替换为最近提出的无监督多语言词嵌入(Chen 和 Cardie,2018b),这进一步提高了性能,实现了新的最先进的性能,如表 4 所示(最后排)。
4.3 Cross-Lingual Text Classification on Amazon Reviews
最后,我们报告了多语言文本分类数据集的结果(Prettenhofer 和 Stein,2010)。该数据集是一个二元分类数据集,其中每条评论都被分类为正面或负面情绪。它有四种语言:英语、德语、法语和日语。如表 5 所示,MT-BOW 使用机器翻译将目标句子的词袋翻译成源语言,而 CL-SCL 通过结构对应学习学习跨语言特征空间(Prettenhofer 和 Stein,2010)。 CR-RL (Xiao and Guo, 2013) 学习双语词表示,其中部分词向量在语言之间共享。Bi-PV (Pham et al., 2015) 通过在并行文档之间共享表示来提取双语段落向量。 UMM (Xu and Wan, 2017) 是一个多语言框架,可以在多个语言对之间利用并行语料库,并在特定源-目标对无法使用直接双文本时根据需要进行调整。最后,CLDFA (Xu and Yang, 2017) 提出了针对 CLTL 的并行语料库的跨语言蒸馏。然而,与列出的其他作品不同,它们采用了在实践中难以获得的特定任务并行语料库(翻译的亚马逊评论),使得数字无法与其他作品直接比较。
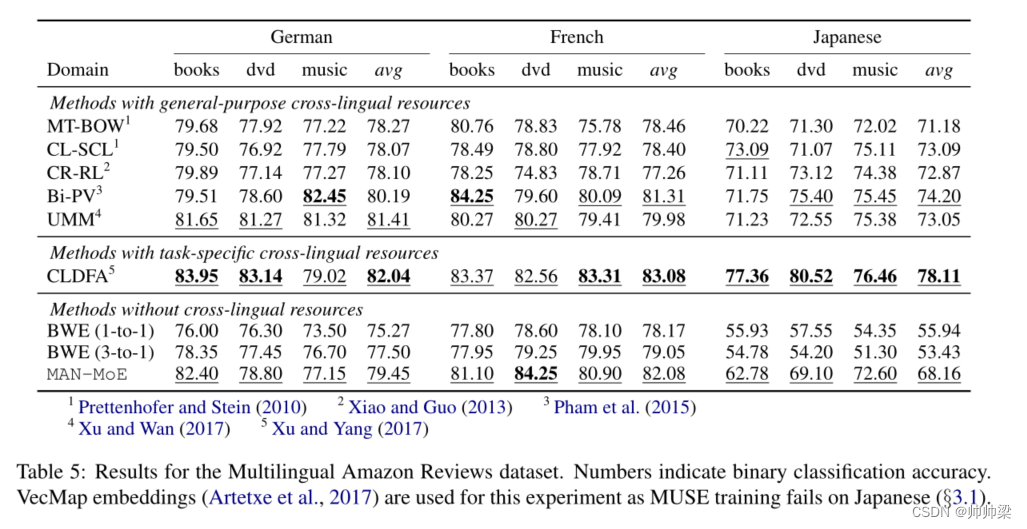
在这些方法中,UMM 是唯一一种不需要所有源-目标对之间直接并行语料库的方法。它可以改为使用中枢语言(例如英语)来连接多种语言。然而,MAN-MoE 又向前迈出了一大步,完全消除了平行语料库的必要性,同时在德语和法语上取得了与 UMM 相似的结果。在日语方面,MAN-MoE 的性能再次受到 BWE 质量的限制。 (BWE 基线仅比随机性好。)尽管如此,MAN-MoE 仍然非常有效,其性能仅比大多数具有跨语言监督的 SoTA 方法低几个点。
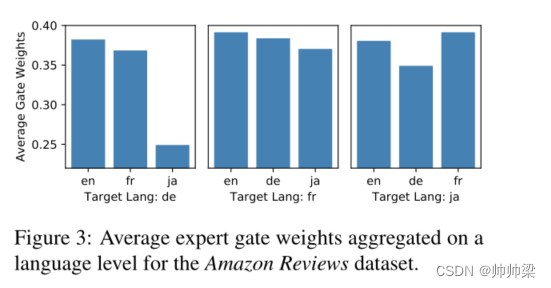
为了更好地理解模型行为,图 3 可视化了专家在转换到不同语言时的权重,这证实了我们的模型假设和第 4.1.2 节中的发现(有关更多详细信息,请参见附录 A)。
5 Conclusion
在本文中,我们提出了MAN-MoE,这是一种多语言模型转换方法,它利用了语言不变(共享)特征和语言特定(私有)特征,这与以前大多数只能使用共享特征的模型不同。根据早期的研究,共有特征是通过语言对抗训练习得的(陈等,2016)。另一方面,私有特征由混合专家(MoE)模块提取,该模块能够动态捕捉目标语言和每种源语言之间的关系。 当目标语言与源语言的子集相似时,这是非常有用的,在这种情况下,仅仅依赖于共享特性的传统模型将表现不佳。此外,MAN-MoE是一种纯粹基于模型的转移方法,它不需要用于训练的并行数据,当与无监督的跨语言单词嵌入相结合时,能够实现完全零资源的MLTL。这使得MAN-MoE更广泛地适用于资源较少的语言。
我们的主张得到了多个文本分类和序列标记任务的广泛实验的支持,包括一个大型行业数据集。 无论任务或语言如何,MAN-MoE都明显优于所有跨语言无监督基线。此外,即使考虑具有强跨语言监督的方法,MAN-MoE也能够在更接近的语言对上匹配或超越这些模型。当转换到诸如汉语或日语(来自欧洲语言)之类的远距离语言时,跨语言单词嵌入的质量不令人满意,MAN-MoE仍然非常有效,并且大大减轻了由跨语言监督引入的性能差距。
对于未来的工作,我们计划将 MAN-MoE 应用到更具挑战性的语言中,例如存在多语言数据的句法解析(Nivre et al., 2017)。此外,我们想尝试多语言上下文嵌入,例如多语言 BERT (Devlin et al., 2018)。