原文链接
A Gentle Introduction to Graph Neural Networks (distill.pub) https://distill.pub/2021/gnn-intro/
https://distill.pub/2021/gnn-intro/
内容简介:本文是“A Gentle Introduction to Graph Neural Networks”的阅读笔记,因为第一次接触GNN,很多深奥的概念不懂,因此没有读完全,maybe后续会补上。
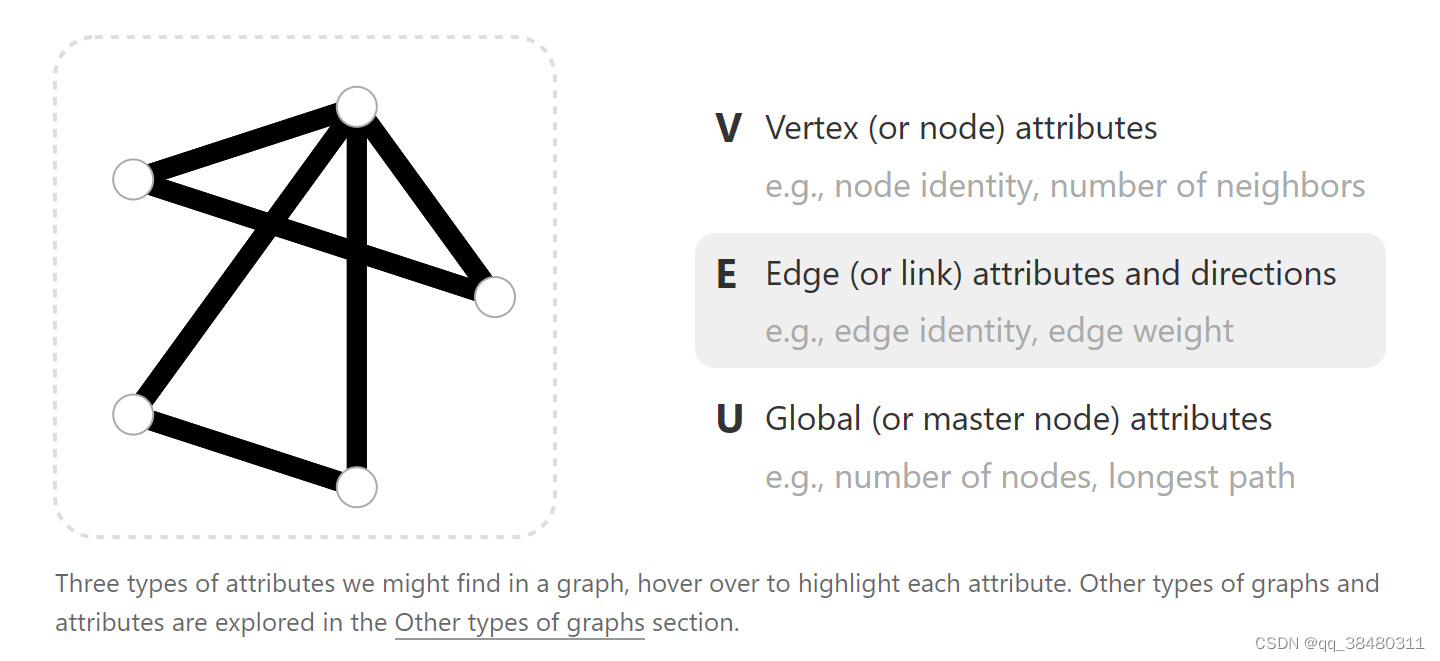
Graph 是什么? Graph 实际上 就是 三个要素,vertex是节点,Edge边,Attribute是图的特征。
Graph问题用来做什么?可以分为三类,一是根据graph级别,比如找出拓扑里有环形的图;二是 根据edge的关系给vertex聚类;三是根据vertex特点找到edge的feature。
Graph之间的信息如何传递聚合? GNN中的新信息传递是Information pooling,即节点之间传递信息,然后进行信息聚合。信息的聚合可以使用 平均,最大或者相加等方式。
设计GNN的规则? 设计GNN时,GNN的表现并不是层数越深越好,层数多会增强最差和平均解表现,不能增强最好解表现。想要性能更好,一是设计更好的传播机制,二是增加图的属性。
训练GNN时采样? 因为GNN每个节点的邻居和连的边都不一样,不像传统神经网络可以取固定的size进行训练,有不同的方法可以采样去训练,比如随机采样 ,随机游走。
GNN的扩展模式? GNN 调整为更复杂的图结构,例如,我们可以考虑多边图或多图,如一对节点共享多条性质不同的边。
尚未理解的问题,Graph之间的信息传递机制都有哪些?以及是如何传递的?
Graph是如何训练的?采样的有哪些技术?需要更深的了解
1.什么样的数据可以转化为Graph
graph实际上就是 vertex edge 和他们的attribute 组成的图。
2.哪一类的问题可以转化为图图结构问题?
一共有三类 :
In a graph-level task, we predict a single property for a whole graph. For a node-level task, we predict some property for each node in a graph. For an edge-level task, we want to predict the property or presence of edges in a graph.
Graph-level task
比如从一堆拓扑图里找出具有两个环形的图

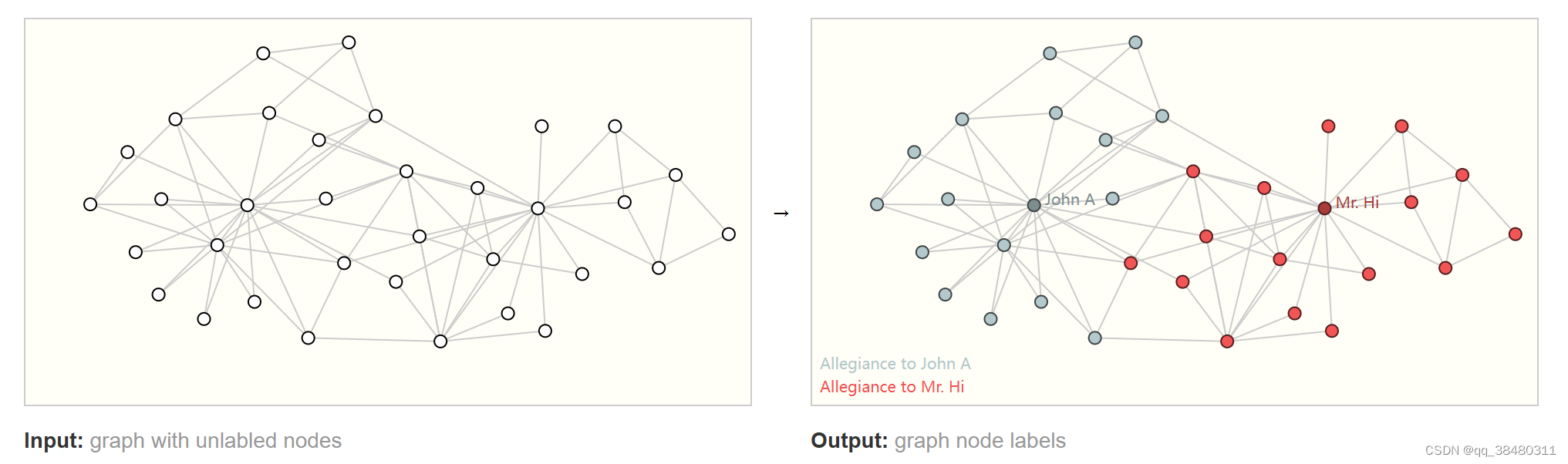
Node-level task
类似于给节点聚类
Edge-level task
找出节点间的关系

用邻接矩阵表示图很消耗内存,特别是当邻接矩阵是稀疏矩阵时, 如何把图表示得更加节省内存?

GNN Predictions by Pooling Information
构建了GNN之后,如何完成任务or做预测 ??
汇集工作分两步进行:
1.对于要汇集的每个项目,收集它们的每个嵌入,并将它们连接成一个矩阵。
2. 然后,通常通过求和操作对收集到的嵌入式数据进行汇总
根据edge信息去预测node

根据node的信息去预测edge
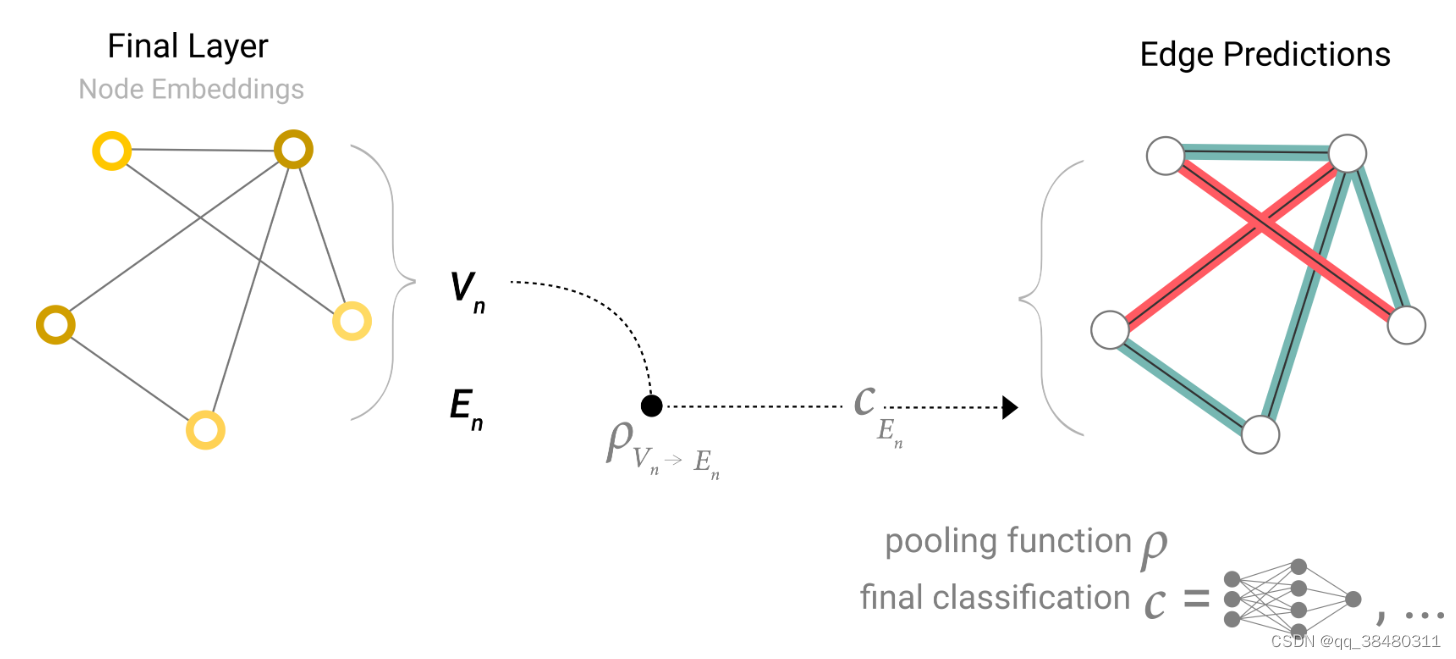
根据 node 和 edge的信息去预测global信息

Passing messages between parts of the graph
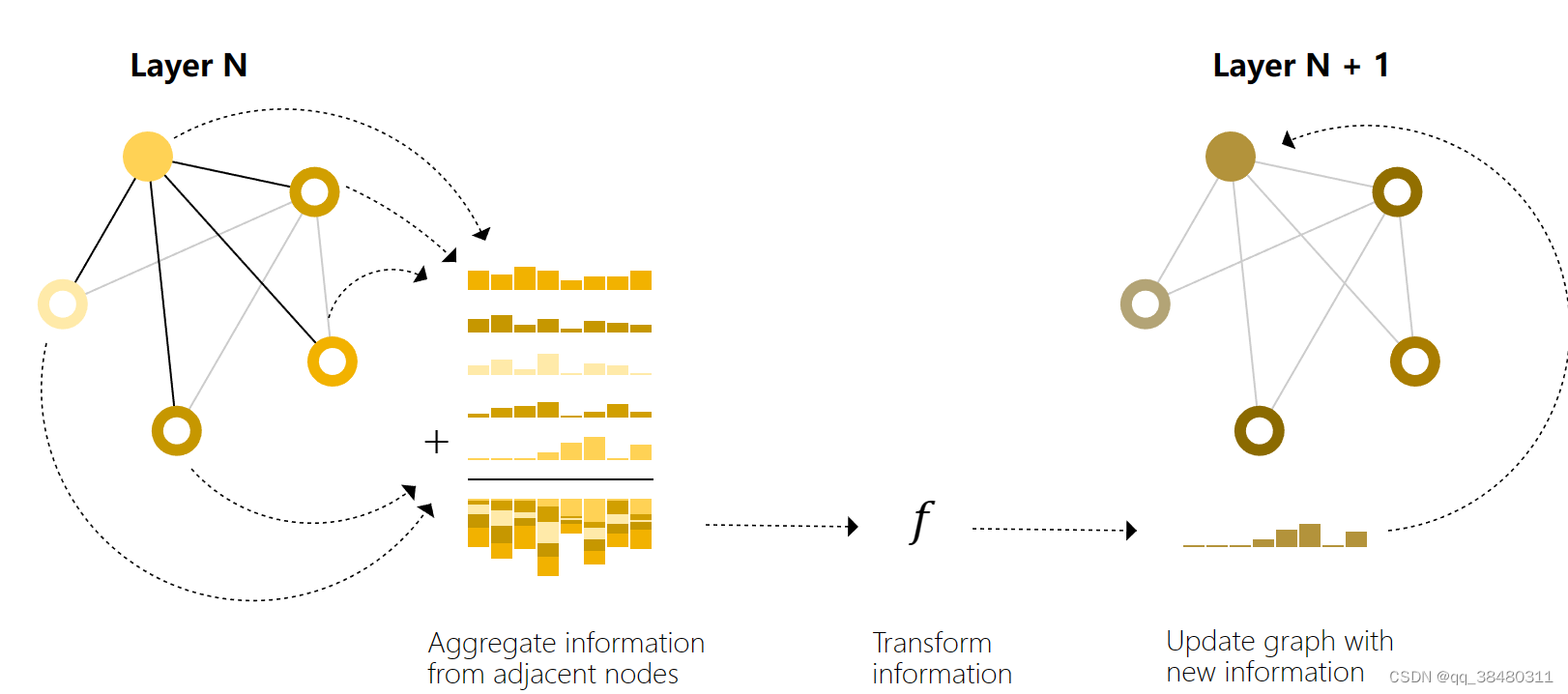
我们可以通过在 GNN 层中使用池化技术来进行更复杂的预测,从而使我们学习到的嵌入信息能够感知图的连通性。我们可以通过信息传递来实现这一点,即相邻节点或边缘交换信息,并影响彼此更新的嵌入。
消息传递分为三个步骤:
1. 对于图中的每个节点,收集所有相邻节点的嵌入(或信息),即上文所述的 g函数。
2. 通过聚合函数(如 sum)汇总所有信息。
3. 所有汇集的信息将通过一个更新函数(通常是一个学习的神经网络)进行传递。
从本质上讲,信息传递和卷积都是汇总和处理元素邻域信息以更新元素值的操作。在图中,元素是一个节点,而在图像中,元素是一个像素。然而,图中相邻节点的数量可以是可变的,这与图像中每个像素都有固定数量的相邻元素不同。
通过将消息传递 GNN 层堆叠在一起,一个节点最终可以整合来自整个图的信息:经过三层之后,一个节点就可以获得离它三步远的节点的信息。
一般建模模板先使用连续的 GNN 层,然后再用一个带有 sigmoid 激活的线性模型来进行分类。GNN 的设计空间有许多可以定制模型的杠杆:
1.GNN层数,也称为深度。
2.更新每个属性的维数。更新函数是一个带有relu激活函数和层规范化的1层MLP。
3.汇聚函数在汇聚中使用:最大值、平均值或总和。
4。更新的图属性或消息传递样式:节点、边缘和全局表示。我们通过布尔切换(开或关)来控制这些。基线模型将是独立于图形的GNN(所有消息传递关闭),它在最后将所有数据聚合到单个全局属性中。打开所有消息传递函数会产生GraphNets架构。
数据汇总到一个单一的全局属性中。切换所有消息传递功能可产生一个 GraphNets 架构。
由于这些是高维向量,我们通过主成分分析(PCA)将它们降至2D。一个完美的模型应该能够清晰地分离标记数据,但由于我们正在降维并且也有不完美的模型,这个边界可能会更难看到。
Some empirical GNN design lessons
1.越深的网络层并不能表现越好。
2,表现主要和以下相关:消息传递的类型,映射的维度,层数和汇聚操作类型。
平均性能和最差性能随着GNN层数的增多而性能上升,但是最好的性能并不会随层数增加而上升。这种效应可能是因为层数越多的 GNN 传播信息的距离就越远,其节点表征可能会因多次连续迭代而被 "稀释"。
交流的图形属性越多,平均模型的性能就越好。我们的任务以全局表示为中心,因此明确学习这一属性也往往会提高性能。我们的节点表征似乎也比边缘表征更有用,这是有道理的,因为这些属性中加载了更多的信息。
要想获得更好的性能,有很多方向可以选择。我们希望强调两个大方向,一个与更复杂的图算法有关,另一个则与图本身有关。
到目前为止,GNN 基于邻域的池化操作。有些图概念比较难用这种方式表达,例如线性图路径(节点的连接链)。设计新的机制,以便在 GNN 中提取、执行和传播图信息,是当前的一个研究领域 。
GNN 研究的一个前沿领域不是建立新的模型和架构,而是 "如何构建图",更准确地说,是为图添加可以利用的附加结构或关系。正如我们所看到的,图的属性越多,我们就越能建立更好的模型。在这种特殊情况下,我们可以考虑通过增加节点之间的空间关系、增加非键的边或明确子图之间的可学习关系,使分子图的特征更加丰富。
与GNN相关的graph
虽然我们只描述了每个属性都有矢量化信息的图形,但图形结构更加灵活,可以容纳其他类型的信息。幸运的是,消息传递框架足够灵活,通常情况下,将 GNN 调整为更复杂的图结构,只需定义信息如何通过新的图属性传递和更新即可。
例如,我们可以考虑多边图或多图,其中一对节点可以共享多种类型的边。例如,在社交网络中,我们可以根据关系类型(熟人、朋友、家人)指定边的类型。通过为每种边缘类型设置不同类型的信息传递步骤,可以对 GNN 进行调整。我们还可以考虑嵌套图,例如一个节点代表一个图,也称为超节点图。嵌套图对于表示层次信息非常有用。例如,我们可以考虑分子网络,其中一个节点代表一个分子,如果我们有将一个分子转化为另一个分子的方法(反应),则两个分子之间共享一条边。在这种情况下,我们可以在嵌套图上学习,方法是让一个 GNN 在分子层面学习表示法,另一个在反应网络层面学习表示法,并在训练过程中交替使用。
另一种图是超图,在超图中,一条边可以连接多个节点,而不仅仅是两个节点。对于给定的图,我们可以通过识别节点群落来构建超图,并分配一条与群落中所有节点相连的超边。

Sampling Graphs and Batching in GNNs
通常对于神经网络的训练来说 ,我们取一个 固定 size 的mini-batch,可是对GNN网络不可这样,因为GNN网络中每个node连接的edge不是固定的,没有一个恒定的size。对图进行分批处理的思路就是构建子图。构建子图就会涉及到图采样。
如何对图进行采样是一个尚未解决的研究问题。
如果我们希望保留邻域级别的结构,一种方法是随机抽取一定数量的节点,即我们的节点集。然后添加与节点集相邻的距离为 k 的邻接节点,包括它们的边。每个邻域可视为一个单独的图,GNN 可在这些子图的批次上进行训练。由于所有相邻节点的邻域都不完整,因此可以掩盖损失,只考虑节点集。
更有效的策略可能是先随机抽样一个节点,将其邻域扩大到距离 k,然后在扩大的集合中挑选其他节点。一旦构建了一定数量的节点、边或子图,就可以终止这些操作。如果情况允许,我们可以通过选取一个初始节点集,然后对一定数量的节点进行子采样(例如随机采样,或通过随机漫步或 Metropolis 算法)来构建恒定大小的邻域。
Comparing aggregation operations
汇集相邻节点和边的信息是 GNN 关键步骤。每个节点的邻居数量不固定,需要一种差别化的方法来汇集这些信息,因此汇集操作应该有平滑性,对节点排序和节点数量具有不变性。
选择和设计最佳聚合操作是一个尚未解决的研究课题。聚合操作的一个理想特性是相似的输入提供相似的聚合输出,反之亦然。一些非常简单的候选包络不变操作包括总和、平均值和最大值。方差等汇总统计也可以使用。所有这些运算都采用数量可变的输入,无论输入排序如何,都能提供相同的输出。
没有哪种操作是一成不变的最佳选择。当节点的邻居数量变化很大,或者需要对局部邻域的特征进行归一化处理时,平均值操作可能会很有用。当你想突出本地邻域中的单个突出特征时,最大值运算可能会很有用。求和则在这两者之间取得了平衡,它提供了局部特征分布的快照,但由于没有进行归一化处理,因此也会突出异常值。在实践中,求和是常用的方法。