目录
0.1、针对于图神经网络的分类问题主要有两种,即图分类、节点分类。具体如下:
1、简介(含背景知识)
0、先验知识
0.1、针对于图神经网络的分类问题主要有两种,即图分类、节点分类。具体如下:
1、图分类(Graph classification):指将由节点和边构成的图结构数据进行分类,具体的场景诸如判断由原子构成的化学分子是否具有某种性质,某种物质是否具有抗癌性,某个蛋白质分子是否属于酶这样的问题。
2、节点分类(Node classification):指的是在给定的图网络当中(节点关系已知,各点特征已知),在一些节点的标签一致的情况下,对其余未知标签节点的标签进行预测分类。举一个具体的例子,比如要通过人物之间的关系网来预测一个人的政治立场。人物关系构成用下面的图结构描述:

每一个节点(个人)拥有一些属性,比如在分类政治立场的例子中,每个人有一些影响个人政治立场的因素,比如政治学习、母校、邮政编码、家庭成员等。其实到这里每个人的一些信息可能已经能够对他所属的类别大致做出判断,但是利用图的结构,会让预测更加强大精准。
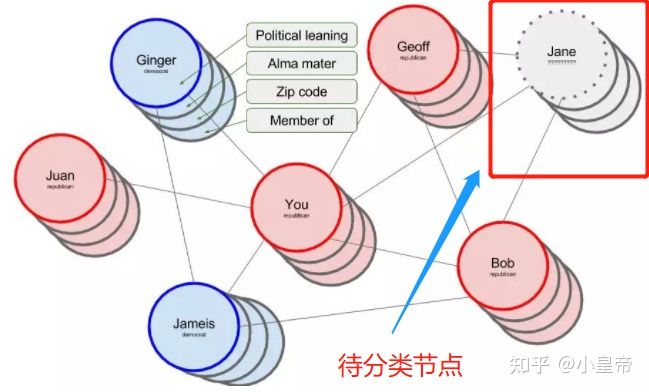
节点分类的任务,就是根据其余已知标记节点的信息,利用图的结构完成对未标记节点的分类预测。利用图卷积神经网络(GCN)完成节点分类任务,每层之间按照如下传播公式传播:
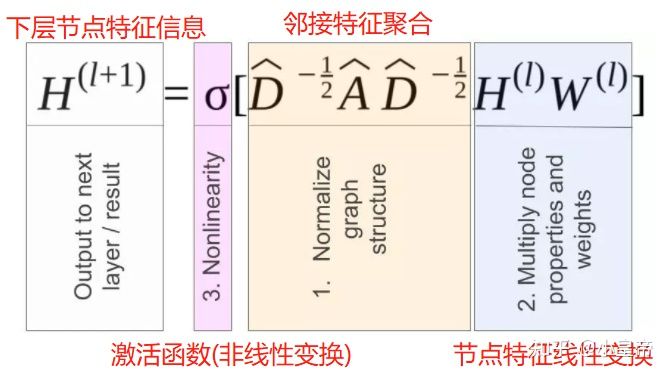
类比卷积神经网络(CNN),这里的W,也就是对节点特征H进行线性变换的W,是一个类似CNN中卷积核的一样的东西,也就是GCN中的可学习参数。其实回想每一个CNN中的卷积核,不也是对一个固定区域进行了线性操作吗。
0.2、攻击方式分类

逃逸攻击(Evasion Attacks)是指攻击者在不改变目标机器学习系统的情况下,通过构造特定输入样本以完成欺骗目标系统的攻击。
中毒攻击(Poison Attacks)是指攻击者在训练的时候送入坏样本,使得模型训练效果变差,影响模型本身功能。
0.3、机器学习类别
机器学习按照学习数据经验的不同,即训练数据的标签信息的差异,可以分为:
监督学习(supervised learning)、非监督学习(unsupervised learning)、半监督学习(semi-supervised learning)、强化学习(reinforcement learning),具体解释为:
1、监督学习:监督学习是用有标签的数据样本(x,y),学习从如何关联x到y。就像是模型在给定题目的已知条件下(特征x),参考着答案(标签y)学习,借助标签y的监督纠正,模型通过算法不断调整自身参数以达到学习目的。监督学习常见的模型有:线性回归、朴素贝叶斯、k最近邻、逻辑回归、支持向量机、神经网络、决策树、集成学习。按照应用的场景,以模型预测结果y的取值有限或者无限,可进一步再分为分类或者回归模型。分类模型是处理预测结果取值有限的分类任务,比如通过多个因素(日照、湿度、温度等)判断是否会下雨;回归是处理预测结果取值无限的回归任务,比如通过一系列因素(温度、风力、下雨等)预测温度。
2、非监督学习:非监督学习是从无标注的数据(x)中,学习数据内在的规律,这个过程就像模型再没有人提供答案(标签y)的情况下。完全通过自己琢磨题目的知识点,对知识点进行归纳总结。按照应用场景,非监督学习可以分为:聚类、特征降维和关联分析等方法。Kemans为无监督学习的典型方法,其原理是初始化k个簇类中心,通过迭代算法更新各簇类样本,实现样本与其归属的簇类中心距离最小。其原理步骤如下:
- step1:随机选择k个样本作为初始簇类中心(可凭先验知识、验证发确定k的取值)。
- step2:针对数据集中的每个样本,计算它到k个簇类中心的距离,并将其归属到距离最小的簇类中心所对应的类中。
- step3:针对每个簇类,重新计算它的簇类中心位置。
- step4:重复step2、step3直到达到某个终止条件(如迭代次数、簇类中心位置不变等)。
3、半监督学习:半监督学习其思想是在有标签样本数量较少的情况下,以一定的假设前提在模型训练中引入无标签样本,已充分捕捉数据整体潜在分布,改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致学习效果不佳的问题。按照应用场景,半监督学习可分为聚类、分类及回归等方法。具体解释一种基于图的半监督算法---标签传播算法(LPA)。
Label propagation algorithm是基于图的半监督学习分类算法,基本思路是在所有的样本组成的图网络中,从已标记的节点标签来预测未标记的节点标签。
- step1:首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
- step2:向图中加入已标记的标签信息。
- step3:将一个节点的标签设置为该节点的相邻节点中出现频率最高的标签(物以类聚、人以群分),重复迭代,直到标签不变即算法收敛。
How to understand semi-supervised learning?
这个要在了解了图结构、图神经网络是什么之后才能理解,推理预测的测试点,经历了训练过程,并在最后一层获取最终的预测结果。半监督的感觉就是将模型对测试集的预测结果用于训练。

这个地方我暂时的理解是,修改网络参数是需要依据损失的,那这个损失是通过哪些节点计算得到的就很关键,我认为是通过已有标签的节点计算得到的,对网络可训练参数修改有指导作用的是通过有标签节点计算得到的损失。半监督是指你在训练整个网络的过程中用到了有标签数据的同时,也用到了无标记的数据。有标签的数据就是你计算Loss的那些,无标记的数据虽然没有标签,但是在Message Passing的过程中你也用到了他们的信息。但是由于Message Passing,无标签节点的特征也被传递到有标签节点上了,算是有间接作用。
4、强化学习:强化学习从某种程度上可以看作是有延迟标签信息的监督学习,是指智能体Agent在环境Environment中采取一种行为action,环境将其转换为一次回报reward和一种状态表示state,随后反馈给智能体的学习过程。

inductive learning和transductive learning的区别:


question:
What is node embeddings?
三、其他
节点分类任务的定义如下:

生成对抗样本的本质是:

图神经网络节点分类任务对抗样本的研究和以往对抗样本研究的假设区别:

数据是独立和连续的假设不再成立。
2、正文
一、Introduction
图中节点分类的目的概括为:给定一个图结构、图中节点的属性信息、图中一部分(少数)节点的标签信息,来推测未知标签的节点的标签。

出色完成图中节点分类任务的原因在于,并没有单独考虑每个节点的信息,而且是考虑了他们彼此之间的相关信息和联系。
图神经网络是否容易收到攻击的研究的不可预见性主要有两个原因,纠结的点在于图网络的结果究竟会使得网络鲁棒性变好还是变坏:
1、the relational effect:预测不只来自一个节点,而是来自很多节点的联合,因此可能会提高鲁棒性。
2、the cascading effect:节点信息在图中有传播性,一点扰动可能会影响很多后续结果。
因为上述两点效应,给我们对图的攻击提出了机遇和挑战:
opportunities:有机会攻击估计成功。
节点分类攻击的过程如下,我们可以操纵的节点叫attacker node,我们希望通过攻击改变分类结果的点叫target node。

challenges:(1)与图像连续性的数据特征不同,图结构、节点特征是离散的,因此基于梯度来寻找对抗样本的方式不可行。(2)图像unnoticeable changes的概念可以用例如最大扰动的概念来度量,在图中unnoticeable changes的概念应该如何度量。(后面论文会解释,见后文4.1部分解释)(3)半监督的学习方式,训练数据和测试数据在训练的时候都用了,在图像中那种模型参数不变去寻找对抗样本的方式不可行(原文如下所述)。

本文的处理对象:
基于图卷积的GCN、Column Network (CLN)的半监督分类模型,无监督模型Deepwalk。
本文假设前提:
攻击者有全图的节点信息和图结构信息、但只能操纵其中一部分。(即使只掌握部分信息,攻击方法在实验中也表现成功了)
二、Preliminary
图神经网络各层间的传递函数的一般型式下图片描述的很清楚了:

下面建立一个具体的GCN模型,相关定义如下:

注意,所有计算损失的样本都是来自于训练集合的,他们有已知的确定标签,这样才能计算交叉熵损失函数。
三、Related work
请看原论文。
四、attack method
4.0 问题定义
先说明一下用到的符号定义与一些名词定义:
攻击目的:

target node:我们希望攻击的点,攻击成功的标志是该节点被分错类。
attacker node:很多时候我们并不能直接修改到target node,而是通过我们能修改的一些其他节点,间接影响对于target node的分类。
特征扰动和结构扰动的数学描述:
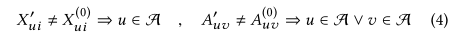
直接攻击和间接攻击:

攻击程度的约束表述(限制扰动的大小):
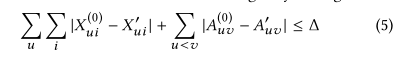
可见约束体现在两方面:对特征的修改、对图结构的修改。
定义一个满足上述(4)、(5)的所有图的集合。
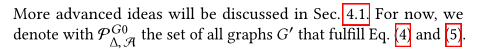
那攻击问题可以描述为:
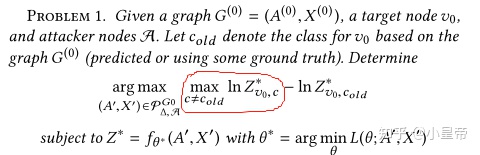
注意上式中:

也就是说,我们希望在所有符合扰动限制的图集合中,找到一个图,它对于target node的最大分类结果与原图对同一target node的分类结果之间的差值最大化。
4.1 unnoticebale perturbation
图结构、数据的unnoticebale perturbation不好定义的原因:
1、图结构是离散的,具体理解为:不像图片数据那样,你想把梯度作为扰动的时候,想加多少都行(0.01,0.1,1...),图结构不一样,比如你想修改节点的连接关系,不会出现小数,只能是把0改为1,将1改为0这样的。
2、将图结构可视化出来,大的图中节点相互之间会有很多连接线进行连接,错综复杂的结构人眼是难以分辨的(乱七八糟的线导致不能将其作为观察的依据)。
对于符合上述公式(5)的扰动预算的子图集合是有很多的,为了保证扰动看起来真实,作者是这样取舍的(数学描述见下面部分):
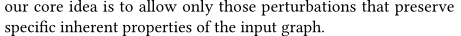
可以理解为,对于一个很大的图,如果将所有的扰动预算都集中在少数节点上,那么就很不真实,比如本来一个节点有很多连接对象,一下子全给它取消了(依然满足约束),就很不真实。
因为扰动从两方面加入,改变节点的连接(图结构扰动)、改变节点特征(特征数据扰动),因此分别从这两方面定义,经过一下小节的学习,要清楚如何定义两个图结构、两个图的特征不可分。
1、图结构扰动:
关于power-law distributions幂律分布:



图结构的扰动不可分定义为:扰动前后,图节点度满足同一个分布。现实生活中对于一个图的幂律分布参数可以用下式近似:
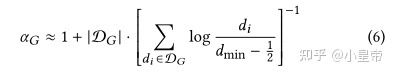

就是说到这一步,上面式子计算得到的这个参数,可以用来描述两个图是否来自同样的分布特征。接下来定义log-likelihood score,只有满足一定条件的图结构扰动才被认为可行。



当满足上述条件时,我们认为图的度分布的改变是不可分辨的。
2、特征扰动
对于节点特征来说,如果两个特征从未共同出现过,而扰动使得他们共现了,那对我们来说应该是比较容易观察到的;相反,如果两个特征经常一起出现,而某个节点特征中他们没有共现,扰动以后他们共现了,这对我们来说是不容易分辨的。举个例子,一篇关于深度学习的文章很可能同时出现“深度学习”和“神经网络”,如果某个深度学习文章这两个单词没有共同出现,而我们只需要稍微修改就可以使得他们共现,并且不会使得文章很突兀;相反如果我们想加入“氢氧化钠”这种词汇,会使得文章很突兀。
度量特征间的共生特征,要考虑一个问题:

不同特征不同时出现很正常不易察觉,忽然同时出现不正常且易于发觉。关键在于如何修改后(0->1)使他们同时出现却不容易察觉。如果将一个节点特征由0修改为1,应满足以下条件。

综上,将特征扰动限制在:
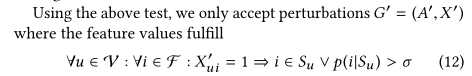
由此,从结构和特征两方面对扰动做出不可分辨的限制之后,攻击的问题就变为:

也就是加了限定条件之后,搜索的子图空间变小了。
五、产生对抗图
代理模型surrogate model:
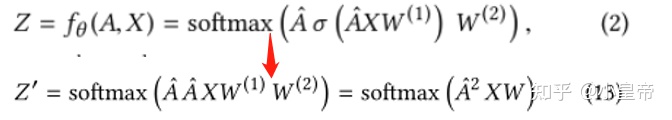

优化的目标,在满足条件的子图集合中搜索,使得模型对target node的识别结果和正确识别结果差异最大(softmax操作不影响结果,故省略):
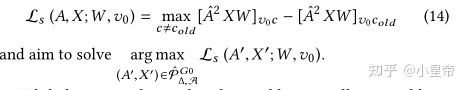
由于离散域的限制,上述损失函数的优化过程依然难以实现,因此作者定义了一个替代方法。用这个代替的方式去近似评估公式(14)的损失。


合理的计算结构和特征的分数函数以及计算之后对于符合条件的解的判别是很重要的,接下来具体来说这两个分数是如何计算的。
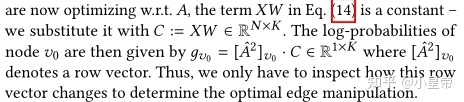
XW不变是因为GCN是训练好的,所以可训练参数W自然是固定的,又因为目前研究的是图结构扰动,所以输入特征X是不变的。属于同一个节点的输出自然就是1*k的行向量。g(v0)记录的是target node和其他nodes的连接情况。
作者提供了一种快速计算结构变换后的邻接矩阵的方法,因为不可能每变动一次就重新计算一下,计算量太大。



计算特征扰动分数:

总的扰动算法:

还要验证一下改动过后的图是否和原图符合同样的分布,原因上面说过,为了能实现快速计算,作者还是提供了一种快速计算的方式。

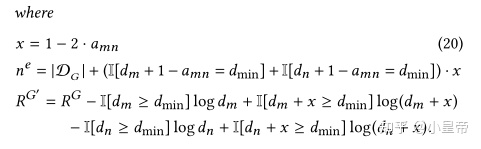
证明过程见原文。
六、实验部分
所用的数据集:
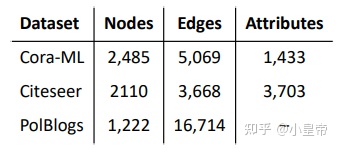

实验过程以及结果分析原文写的很清楚,请见原文第6章节。
3、参考
Adversarial Attacks on Neural Networks for Graph Data(KDD 2018)