Domain Adaptation and Graph Neural Networks
Student : Wenxuan Zeng
School : University of Electronic Science and Technology of China
Date : 2022.4.21 - 2022.4.23
文章目录
- Domain Adaptation and Graph Neural Networks
-
- 1 Domain Adaptation
- 2 Domain Adaptation in Computer Vision
- 3 Domain Adaptation in Graph Neural Networks (Understanding of Four Important Papers)
-
- 3.1 DANE: Domain Adaptive Network Embedding (IJCAI '19)
- 3.2 GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation (CVPR '19)
- 3.3 Unsupervised Domain Adaptive Graph Convolutional Networks (WWW '20)
- 3.4 Adaptive Trajectory Prediction via Transferable GNN
- 3.5 Curriculum Graph Co-Teaching for Multi-Target Domain Adaptation (CVPR '21)
- 4 Conclusion
1 Domain Adaptation
1.1 Background
首先来考虑如下的场景:我们已经在training set上训练好了模型,现在开始在testing set上进行测试。如果testing data和training data的来自于同分布的,那么预测结果好较好,而testing data与training data差距较大时,预测结果就会很差。如下图所示,这种现象被称作“Domain shift”,也就是说training data和testing data有不同的分布。

这种现象广泛出现在机器学习领域,当大家兴奋于机器学习所取得的惊人效果时,殊不知当模型部署到实际环境中时,结果的好坏却是一个未知数。那么解决这个问题的方式就是Domain adaption,这也是Transfer learning的一种(将domain A上训练的知识迁移到domain B上)。
1.2 Domain shift
主要存在3种不同形式的domain shift:一种是training data和testing data的分布不同,一种是输出标签分布不同,还有一种是数据和标签的关系不同。
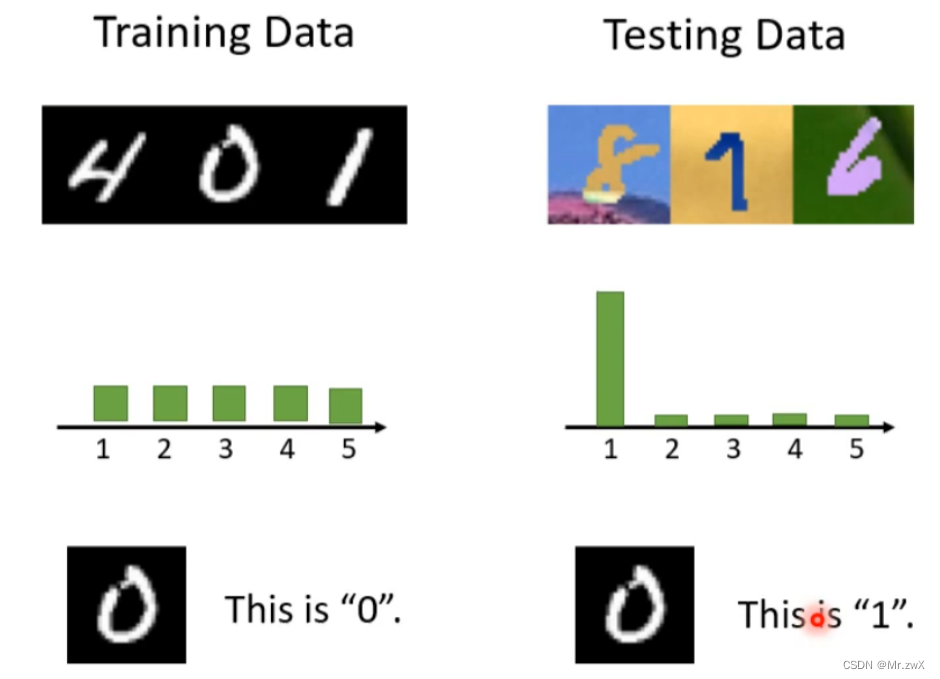
本次学习的主要内容是针对数据分布不同的domain shift,我们定义training data为source domain,testing data为target domain。
1.3 Domain Adaptation
做领域自适应时,需要考虑到target domain上拥有知识的情况。
① 当target domain上拥有大量的labeled data,那么就不用做domain adaptation了,因为我们可以直接在target domain上进行训练。
② 当target domain上拥有少量labeled data,那么可以用source data训练一个模型,然后在target data上做fine-tune。存在的问题是,容易出现over fitting(调小learning rate,调小epoch…)
③ 当target domain上拥有大量的unlabeled data,是现在最常见的情况。现在开始学习这种情况的解决方法。一种比较基础的idea就是用一个feature extractor去提图片的特征,虽然source data和target data是不同分布的,但是提出来的feature是同分布的,这样做的好处就是能顺利进行不同领域的适应。
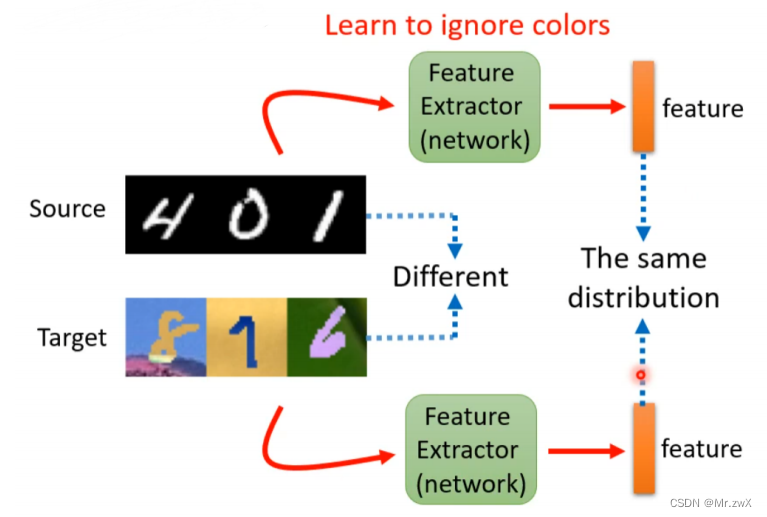
那如何去设计这样的feature extractor? 如下图,通过feature extractor可以提取出图片的深度表征(feature extractor可以人为地定义为3层4层5层…),我们要求source data和target data所得到的feature是分不出差距的(或者说是同分布的)。
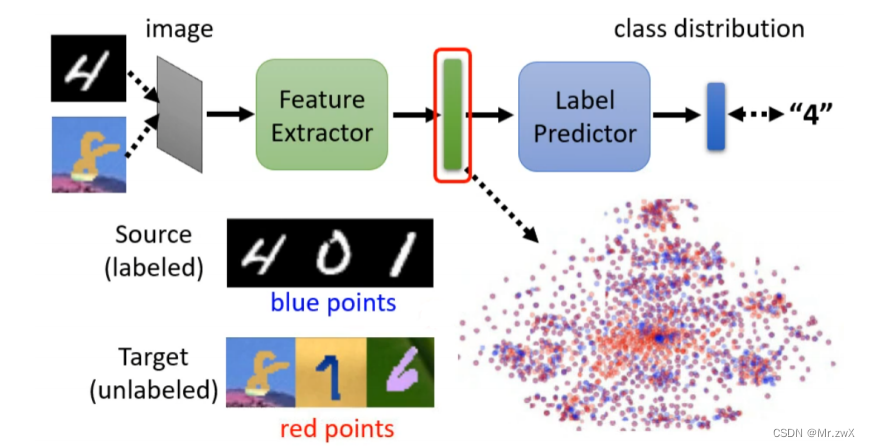
现在考虑如何得到一个可以输出同分布的feature extractor,这里可以采用domain adversarial training的技术来实现。在输出feature的层之后街上一个domain classifier(二分类器)去判断图片的来源是source data还是target data,如果feature extractor生成的feature能顺利骗过domain classifier,则说明实现了上述想法。
Domain-Adversarial Training of Neural Networks
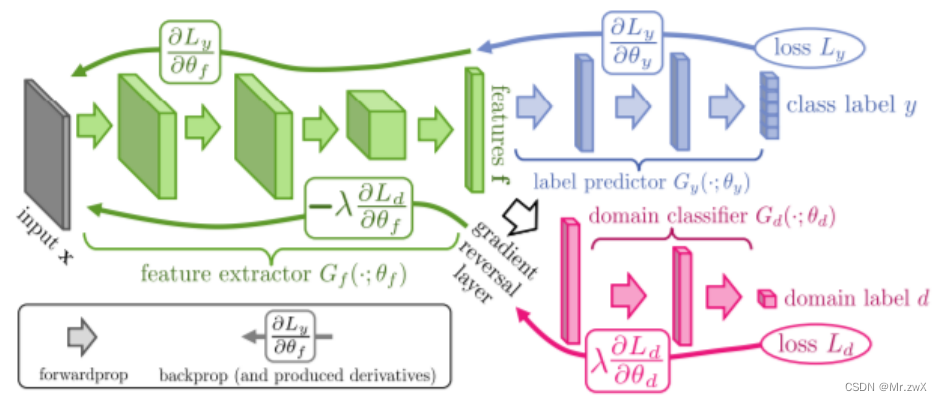
简化上图:

这很容易被类比成GAN,把feature extractor看作是generator,domain classifier看作是discriminator。事实上,domain adversarial training这篇文字和GAN是同时期的作品(2015),有着异曲同工之妙。
试想一下,feature extractor会不会太强大了,因为如果它全部输出zero vector,也能骗过domain classifier!会不会出现这样的情况?其实不会,因为label predictor是需要这个feature去做预测的。
但是这样做也未必很好,domain classifier要最小化二分类的loss,而feature extractor要骗过domain classifier就需要最大化这个loss,所以这样做并不是最好的。
刚刚学习到了让target分布尽可能接近于source,也会存在下面这两种情况,我们期望出现的是第二种情况。一种比较直觉的想法就是让得到的feature能尽可能远离分界线(decision boundariy)。
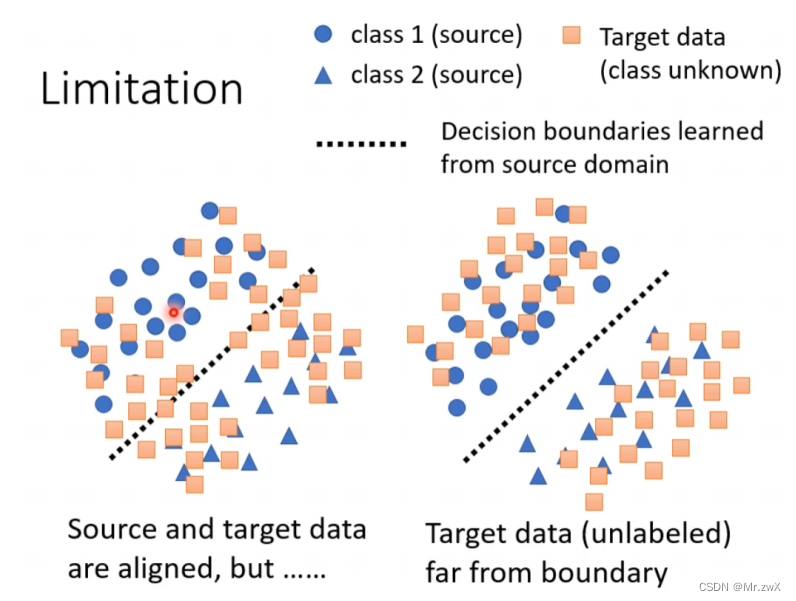
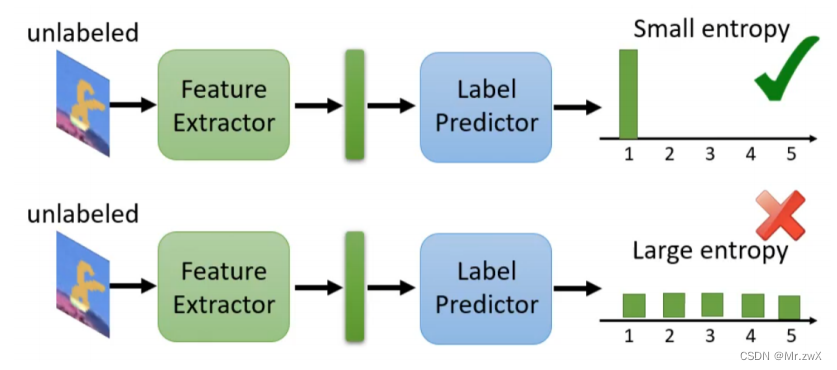
一种做法是将target中的unlabeled data输入feature extractor也输入label predictor中,最终得到预测结果。如果预测的分布是非常集中的,那就代表small entropy,反之则是large entropy。
当然还有更多关于decision boundary的工作:
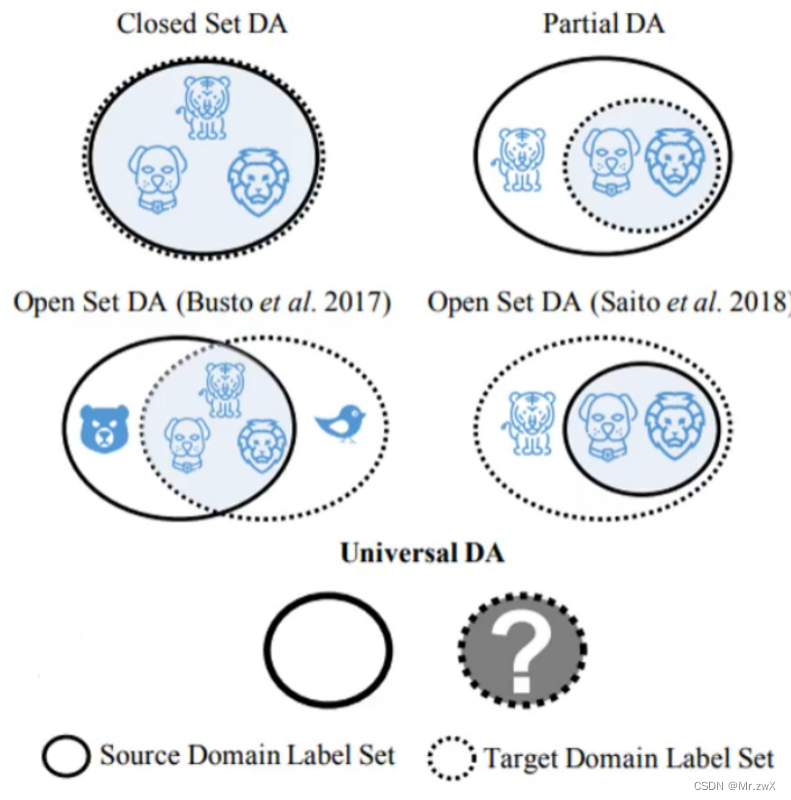
再思考一个问题,如果说source domain中的类别和target domain中的类别不完全相同,上面的方法就出现了问题。比如,target domain中出现了source domain中没有出现过的lion动物类别,我们仍然让target中的feature和source符合同分布,那不就是把lion硬说成了其他动物吗?显然是不合理的!那么在CVPR2019上就出现了这样一篇文章:Universal Domain Adaptation
④ 当target domain上拥有少量unlabeled data,也是有办法解决的,参考:Test-Time Training with Self-Supervision for Generalization under Distribution Shifts
⑤ 当target domain是完全未知的,这就不叫domain adaptation任务了,而叫做domain generalization。目标就是希望模型能够在未知的场景中具有很好的泛化性。参考:Domain Generalization with Adversarial Feature Learning。还有一种情况,是source domain上只有少量数据,而需要在多种不同的target domain上进行应用,参考:Learning to Learn Single Domain Generalization
2 Domain Adaptation in Computer Vision
在计算机视觉领域,领域自适应被广泛应用,比如自动驾驶。数据集上的图片可能与真实情况存在较大的差距,如何做领域自适应,是非常重要的一环。比如下图中,实际场景中可能会是大雾、阴雨、大雪等天气,那在这样的环境中,能否很好地实现目标检测、语义分割、物体分类等任务呢?

下面是几种实现领域自适应的方式:
-
数据生成与连续域
-
扩充数据集可以解决这样的问题,但是要收集大量的各种环境的数据(以及打标签)会耗费很高的成本,通常是不可行的。所以通常采用的方法是对各种condition的数据进行仿真,生成大量的数据以扩充数据集。
通过深度估计去生成不同能见度的foggy场景:Curriculum Model Adaptation with Synthetic and Real Data for Semantic Foggy Scene Understanding

通过统计模型(如CycleGAN)去生成nighttime场景:Map-Guided Curriculum Domain Adaptation and Uncertainty-Aware Evaluation for Semantic Nighttime Image Segmentation

在这篇论文中也用域流实现连续域的迁移过程:
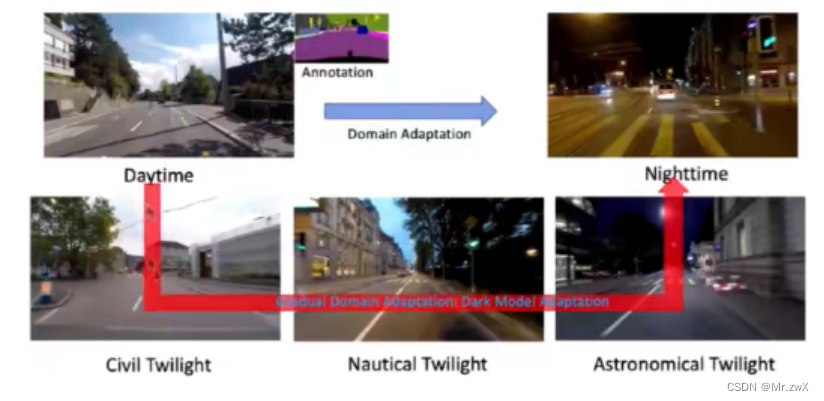
建立起生成图像和原图之间的map关系:

如果搜集不到数据,那就用生成的方式:DLOW: Domain Flow and Applications

-
Test-time的领域自适应,让模型在实际场景中自己学习进行适应
-
多任务学习的领域自适应
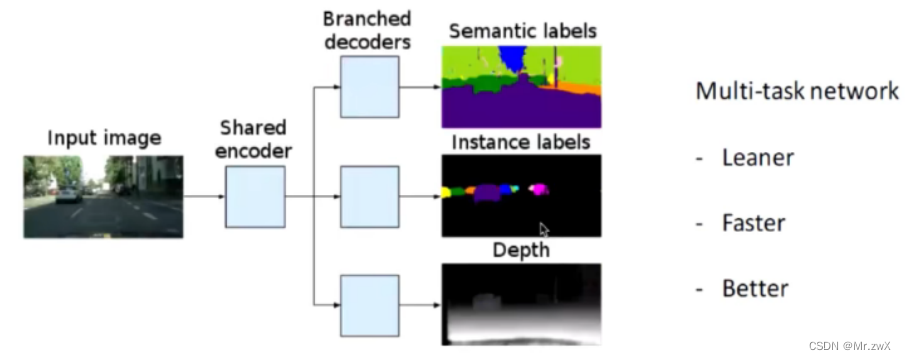
用自监督学习的深度估计来辅助语义分割任务:Three Ways To Improve Semantic Segmentation With Self-Supervised Depth Estimation。语义分割的标签标注成本非常高,所以采用自监督的深度估计任务来辅助语义分割。
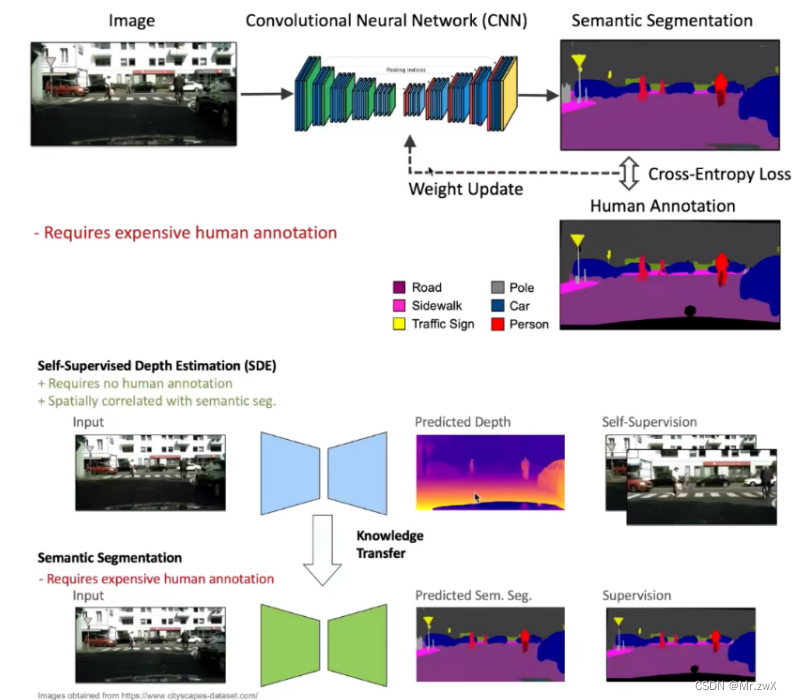
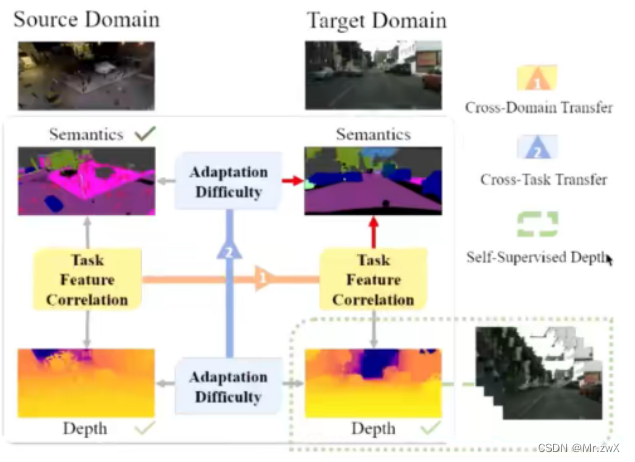
Domain Adaptive Semantic Segmentation with Self-Supervised Depth Estimation 这篇文章就通过自监督的深度估计来辅助语义分割任务的完成。source domain中的task之间的相关性是可以迁移到target domain中的,source domain和target domain中对于深度估计的难度是可以迁移到语义分析中。
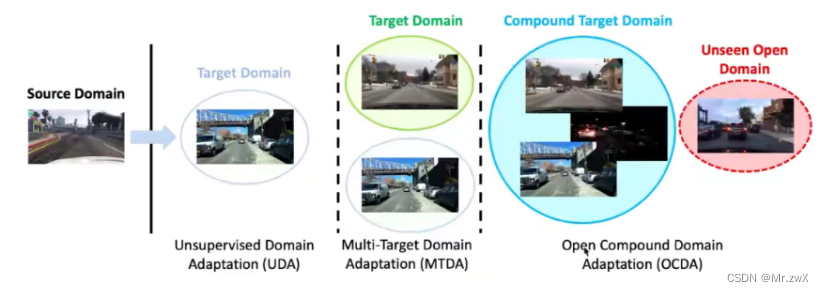
对于存在多种混合的target domain的情况,也有相应的文章:Cluster, Split, Fuse, and Update: Meta-Learning for Open Compound Domain Adaptive Semantic Segmentation
-
多传感器融合
这里不展开讲,偏device方面。
3 Domain Adaptation in Graph Neural Networks (Understanding of Four Important Papers)
3.1 DANE: Domain Adaptive Network Embedding (IJCAI '19)
链接:DANE: Domain Adaptive Network Embedding
-
特点: Embedding领域自适应、图神经网络、对抗学习
-
动机: 以前的工作只考虑为单一的网络学习embedding,无法迁移到多个网络上。所以作者想设计一种embedding算法,支持下游任务迁移到不同的网络上进行训练,这就是domain adaptation。
-
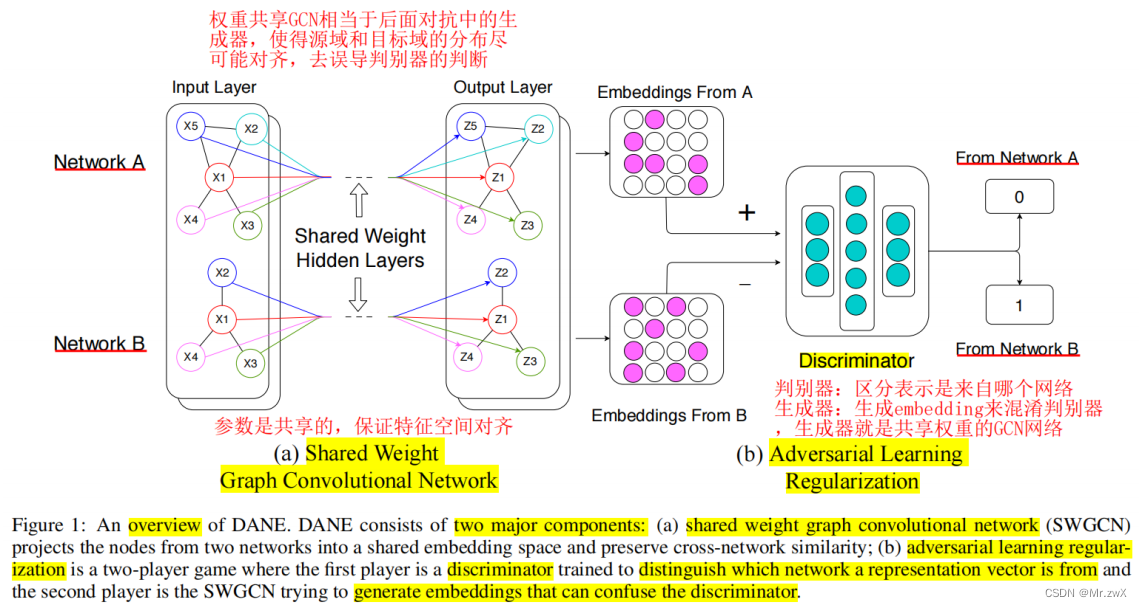
贡献: ① 最早提出cross multiple graph networks上的domain adaptation;② 两种对齐方式:特征空间对齐——结构上相似的节点具有相似的表示向量,即使它们来自不同的网络,方法是节点表示由两个参数共享的网络得到;分布对齐——方法是节点表示分布由对抗学习进行正则化;③ 构造了两个数据集。
-
方法: 分为如下两个部分:
-
共享权重的GCN网络
采用两个相同的GCN网络,分别得到embedding:

为了学习到源域和目标域都兼容的参数,采用多任务loss function来保存两个网络的性质:
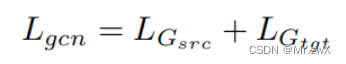
-
对抗学习正则化
和GAN思想类似,训练一个discriminator来判别embedding来自哪个网络(源/目标域),训练一个权重共享的GCN作为generator。对于discriminator有如下的loss:

为实现双向的领域自适应,设计了如下的对抗训练loss:
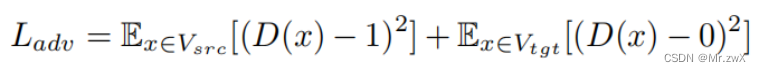
最后结合两个步骤中的loss:
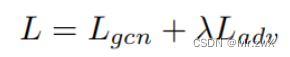
-
3.2 GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation (CVPR '19)
链接:GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation
-
特点: 图神经网络、无监督学习、领域自适应、对抗网络
-
动机: 作者认为领域自适应中要搭建源域和目的域之间的桥梁,有三种最重要的信息:数据结构(反映了数据集的固有属性,包括边际或条件数据分布、数据统计信息、几何数据结构等)、领域标签(用于对抗性域自适应方法,并可以帮助训练一个域分类器来建模源域和目标域的全局分布)、类别标签(特别是目标伪标签,通常采用强制语义对齐,这可以保证来自具有相同类标签的不同域的样本将被映射到特征空间附近)。
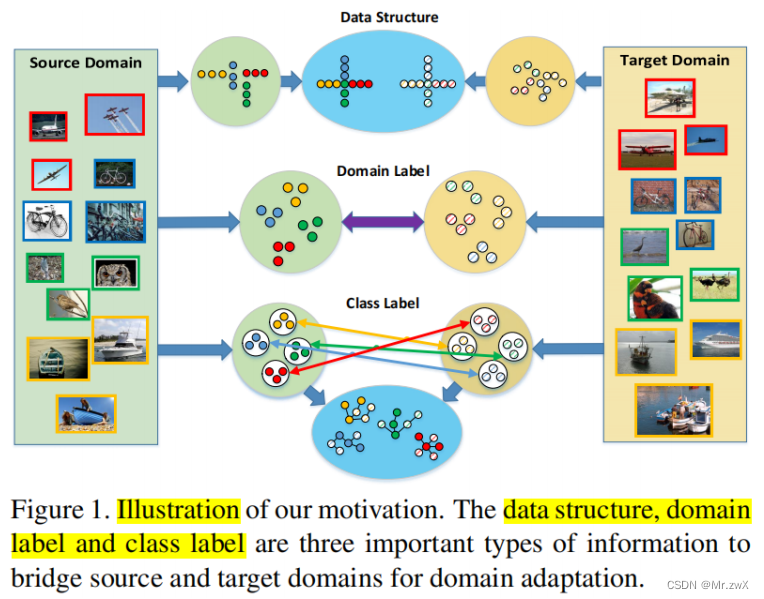
-
贡献: ① 第一次在无监督领域自适应中联合建模三种信息(数据结构、领域标签、类别标签);② 为了更鲁棒地匹配源域和目的域的分布,提出三种对齐机制(结构感知对齐、领域对齐、类中心对齐)有效地学习领域不变表示和语义表示,以减少领域自适应的领域差异。
-
方法:
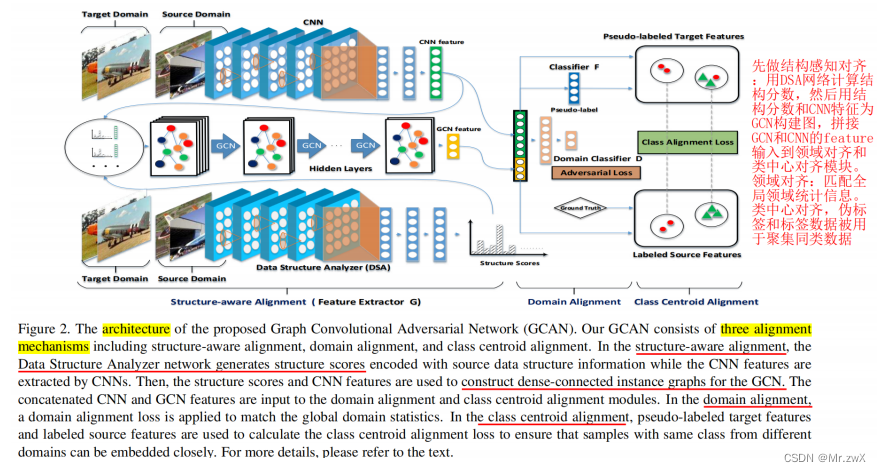
-
优化的目标函数

-
领域对齐
加入了一个领域分类器(提取的feature来自源域/目的域二分类),采用领域对抗相似度作为损失函数:
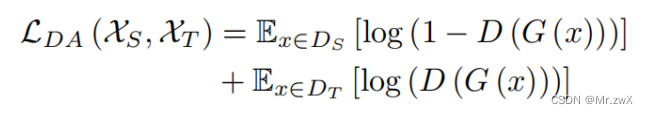
Feature extractor用于欺骗分类器,分类器用于判别来源,以对抗方式帮助训练一个域分类器来建模源域和目标域的全局分布。
-
结构感知对齐
领域对齐强制执行了全局域信息的对齐,但是忽略了小样本的结构信息。首先,用数据结构分析器 (DSA) 网络,为一个mini-batch样本生成结构分数,然后,利用得到的结构分数和学习到的样本CNN特征来构造密集连接的实例图。之后,GCN对实例图进行操作,以学习使用数据结构信息编码的GCN特征。下面学习如何构建密集连接示例图:
图的信息表示为CNN提取的feature:
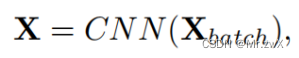
为了构建邻接矩阵,将这个mini-batch样本喂入数据结构分析器 (DSA) 网络中,生成结构分数,有了这个结构分数就可以构造邻接矩阵:

用Triplet loss来限制结构分数的生成:
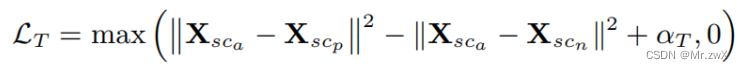
-
类别标签对齐
特征具有领域不变性(Domain Invariance)与结构一致性(Structure Consistency)并不意味着其具有判别性(Discriminability),所以提出类别标签中心对齐。
首先,用目标分类器来分配伪标签,得到目标域上的伪标签数据。然后,被标记的样本和伪标记的样本一起用于计算每个类的质心。
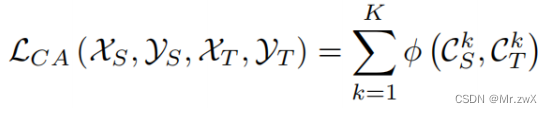
-
3.3 Unsupervised Domain Adaptive Graph Convolutional Networks (WWW '20)
链接:Unsupervised Domain Adaptive Graph Convolutional Networks
-
特点: 无监督学习、图神经网络、领域自适应
-
动机: 大多数GCN只能在单个域(图)中工作,无法将知识从其他域(图)转移,这是由于图表示学习和图结构上的域适应方面的挑战。
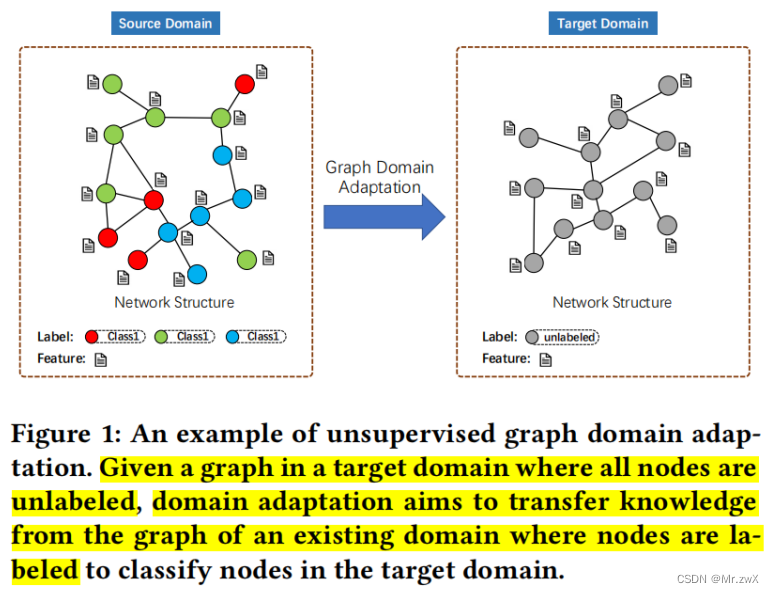
-
贡献: ① 提出了一种新的无监督图域自适应问题,并提出了一种双重图卷积网络算法;② 将局部和全局一致性与注意机制相结合,以学习跨网络的有效节点embedding;③ 利用具有不同损失函数的源信息和目标信息,可以有效地学习域不变表示和语义表示,从而减少跨域节点分类中的域差异。
-
**方法: ** 为了实现有效的图表示学习,首先开发了一个双重图卷积网络组件,它联合利用局部和全局一致性进行特征聚合。进一步使用注意机制为不同图中的每个节点生成统一的表示。为了便于图之间的知识转移,提出了一个领域自适应学习模块来优化三种不同的损失函数(源分类器loss、领域分类器loss、目标分类器loss),因此,模型可以分别区分源域中的类标签、不同域中的样本、目标域中的类标签。
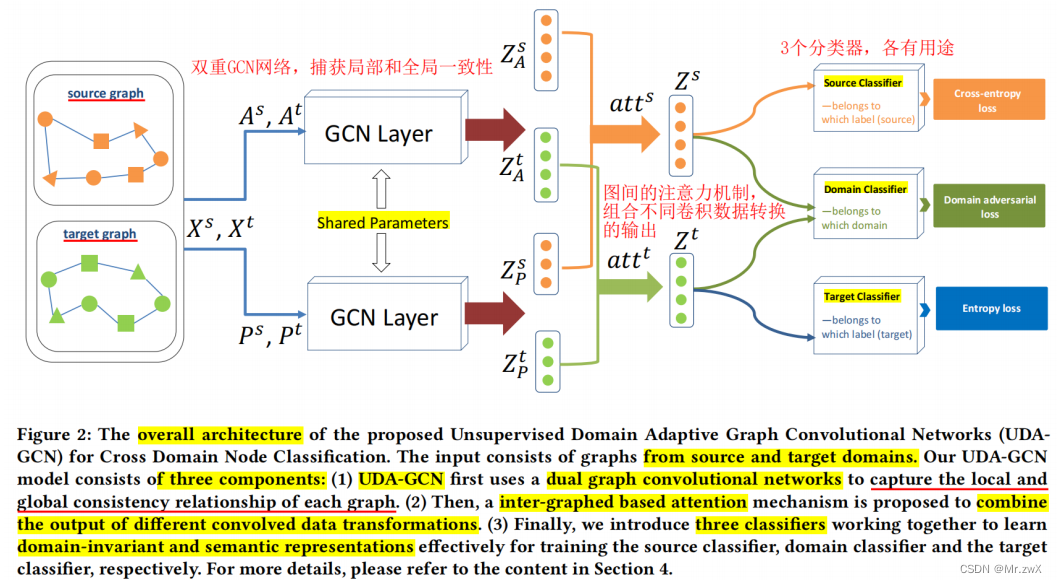
-
节点表示学习
用双重图卷积网络捕获每个图的局部和全局一致性关系。对于局部一致性,直接将邻接矩阵A输入到GCN;对于全局一致性,提出另一种基于随机游走的卷积方法。
局部一致性:简单的GCN,输入A和X

全局一致性:引入PPMI(点级互信息矩阵)的卷积方法来编码全局信息。首先通过随机游走计算频率矩阵F(随机游走能计算节点间的语义相似性)

可以看到,全局和局部一致性的区别在在于输入GCN的“邻接矩阵”在不同的。
-
图间注意力
我们需要聚合来自不同图的嵌入来生成一个统一的表示,分别从局部和全局GCN层中自动确定源图表示和目标图表示之间的权重。

-
跨域节点分类中的领域自适应学习
训练了三个分类器:① 源分类器;② 域分类器;③ 目标分类器
总体训练目标:

源分类器loss就是交叉熵损失函数:

域分类器和之前的工作一样,还是用了对抗学习的思想,既要让网络去判别开两个来源,也要让两个来源生成的feature相似,让分类器难以判断出来。

目标分类损失函数用entropy loss(cross-entropy是不行的,因为target domain无标签):
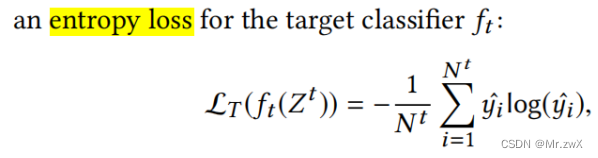
-
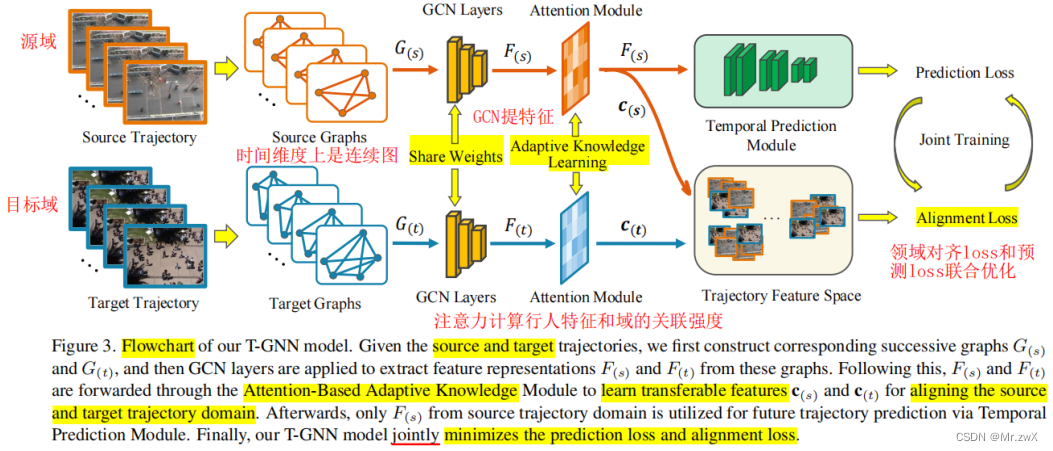
3.4 Adaptive Trajectory Prediction via Transferable GNN
链接:Adaptive Trajectory Prediction via Transferable GNN
-
特点: 图神经网络、行人轨迹预测、领域自适应
-
动机: 现有工作大多没考虑训练集和测试集的运动遵循相同的模式,忽略了潜在的分布差异。所以提出领域对齐的框架实现领域自适应。
-
贡献: ① 深入研究不同轨迹域的域迁移问题,并提出统一的T-GNN方法,用于联合预测未来轨迹和自适应学习域不变知识;② 提出了一个专门设计的图神经网络来提取全面的时空特征表示,还开发了一个有效的基于注意力的自适应知识学习模块,以探索细粒度的个体水平的可转移特征表示;③ 引入了一种全新的行人轨迹预测问题设定,在这种域迁移设置下为行人轨迹预测建立了强基线。
-
方法: 提出了一种领域不变的GNN来探索领域特定知识减少的结构运动知识,此外还提出了一个基于注意力的自适应知识学习模块来探索用于知识转移的细粒度个体级特征表示。
-
时空特征表示
简单来说,就是三层GCN网络:
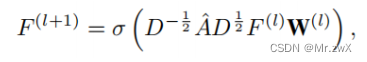
-
基于注意力的自适应学习
这一部分的目的是解决源域和目标域之间的差距。虽然特征向量保留了一个行人的时空信息,但我们不能确定该行人的特征向量在一个域中的代表性。因此,引入了一个注意模块来学习特征向量与轨迹域之间的相对相关性。
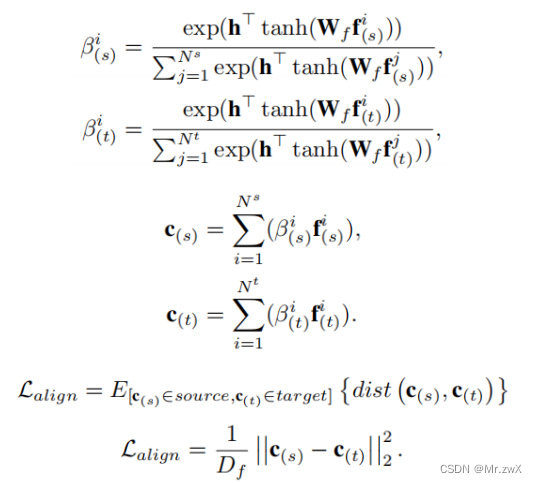
-
时间预测模块
简单来说,用的时间卷积TCN做时间维度的预测:
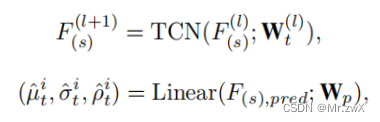
-
训练目标
对于轨迹的预测,用负对数似然估计:
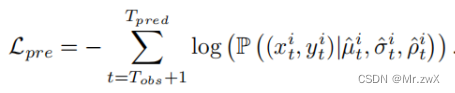
最终的训练目标综合了前面的对齐损失和预测损失:
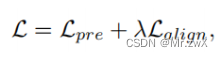
-
3.5 Curriculum Graph Co-Teaching for Multi-Target Domain Adaptation (CVPR '21)
-
特点: 单源域-多目标源域、课程学习、伪标签生成
-
动机: 解决多领域迁移的问题。
-
贡献: ① 提出了MTDA的课程图协同教学 (CGCT),它利用与双分类器头的协同教学策略、课程学习方式,来学习跨多个目标领域的更鲁棒的表示;② 为了更好地利用领域标签,提出了一种领域感知课程学习 (DCL)策略,使特征对齐过程更平滑
-
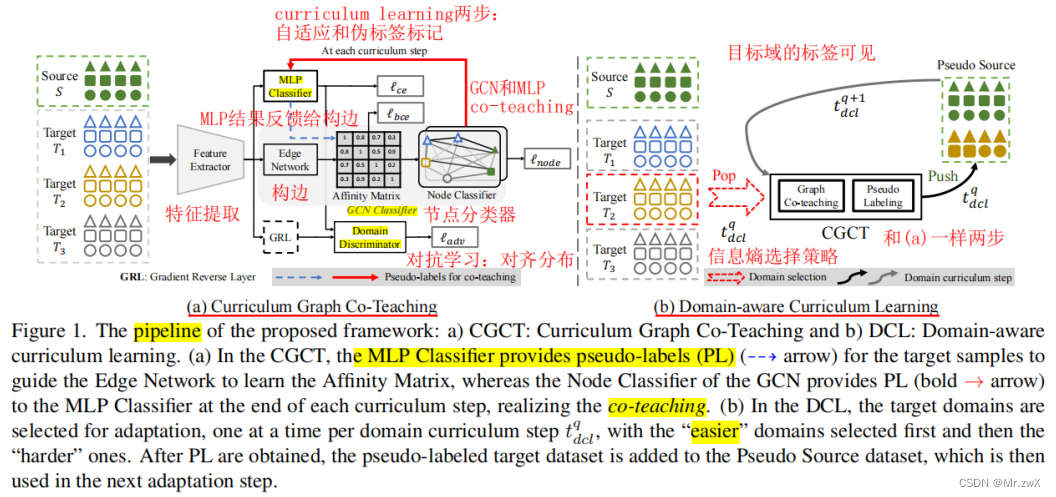
方法: 两个角度减轻多领域迁移的问题,特征聚合和课程学习。提出课程图协同学习,用的双分类器头,其中一个是GCN聚合了来自于跨域的类似样本的特征。防止分类器对其自身的噪声伪标签进行过拟合。防止分类器对其自身的噪声伪标签进行过拟合,开发一种与双分类器头的协同教学策略,并辅以课程学习,以获得更可靠的伪标签。另外,当领域标签可用时,提出领域感知课程学习(DCL),这是一种顺序适应策略,首先适应更容易的目标领域,然后是更难的目标领域。
-
(a) Curriculum Graph Co-Teaching
STEP 1:领域自适应
用 f e d g e f_{edge} fedge来生成邻接矩阵,其监督信息是MLP给的,MLP对节点之间的边进行标注(两个节点的标签一致,则它们之间的相似度为1,否则为0):

则生成邻接矩阵的loss:
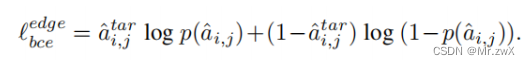
GCN和MLP在源域上的loss:
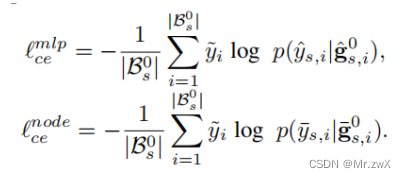
最终优化的目标为:

STEP 2:伪标签标注
用GCN对无标签数据进行标注,小于某个阈值则不参与训练。为什么选GCN的输出进行标注?作者说考虑到GCN进行特征的聚合,相比MLP更具有鲁棒性。然后数据变为:
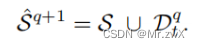
-
(b) Domain-aware Curriculum Learning
作者考虑了目标域带标签的情形。不同目标域与源领域的数据分布的shift程度是不一样的,因此自适应的难度不一样。这里采用了Easy-to-Hard Domain Selection (EHDS) 策略,先适应easy的domain,再适应hard的领域,原因就是模型适应shift较小的领域明显比shift较大的领域容易。
如何衡量哪个domain更容易?作者用信息熵衡量了这个指标:
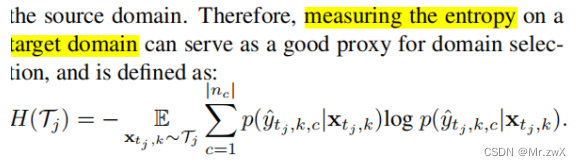
STEP 1:领域选择
根据上述信息熵选择相对简单的领域:
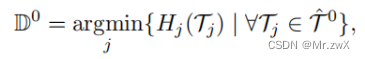
STEP 2:领域自适应
与Curriculum Graph Co-Teaching相同,不过目标域的数据采用选择的域数据。
STEP 3:伪标签标记
与Curriculum Graph Co-Teaching相同,不过目标域的数据采用选择的域数据。
-
4 Conclusion
- 在前面这三篇工作中,第一篇在学习可迁移的Embedding representation方法,第二篇、第三篇和第四篇(行人轨迹预测)、第五篇(多领域自适应)都是将模型自适应地迁移到不同的domain上。除此之外,GNN在Domain adaptation领域还有更多的应用,比如:Graph-Relational Domain Adaptation (ICLR ‘22’) 认为不同域之间的关系并不是等同的,他们之间存在拓扑关系,所以从图的角度去思考域之间的relation。Unsupervised Multi-Source Domain Adaptation for Person Re-Identifification (CVPR '21) 这篇文章将多源领域自适应引进行人重识别问题。
- 我认为Domain adaptation是一个非常有前景的方向,因为在大多数实际场景中,数据都是和训练时有差距的,甚至是完全未知的。那么,如何让模型在实际情景中发挥最大的价值,就是领域自适应需要不断解决的问题。
- AutoEval也是在解决测试场景数据未知的问题,但是从另一个切入点去考虑问题,用“估分”的手段去评估模型在未知环境的效果,属于一种“对自身学习能力的评价”的学习范式。