目录
1. User-item Collaborative Filtering:协同滤波
1.1. Graph Construction
1.2. Neighbor Aggregation
2. Sequential Recommendation:序列推荐
2.1. Graph Construction
2.2. Sequential Preference
3. Social Recommendation:社交推荐
3.1. Influence of Friends
3.2. Preference Integration
4. Knowledge Graph based Recommendation:基于知识图谱的推荐
4.1. Graph Construction
4.2. Relation-aware Aggregation
5. Other tasks:一些小众的方向
5.1. Points-of-interest (POI) recommendation
5.2. Group recommendation
5.3. Bundle recommendation
5.4. Click-through rate (CTR) prediction
5.5. Multimedia Recommendation
6. Future research directions and open issues:展望未来研究方向
1. User-item Collaborative Filtering:协同滤波
给定 user-item 交互数据,user-item collaborative filtering 的目标是利用 items 来加强 user representations、利用 users 来加强 item representation。下图演示了如何使用 GNN 做Collaborative Filtering。

目前工作集中于解决以下四个问题:
- Graph Construction。使用异构的 user-item bipartite graph 还是使用两阶(two-hop)邻的同质图?考虑到效率,如何采样邻居?
- Neighbor Aggregation。如何从邻居汇聚信息?是否区分邻居的重要程度?
- Information Update。如何合并 central node 的 representation 和从邻居那儿汇聚的 representation?
- Final Node Representation。使用最后一层特征还是合并所有层?
1.1. Graph Construction
大量工作直接在原始 user-item bipartite graph 上使用 GNN,这样可能存在两个问题:
- 原始图可能不足以学习 user/item representations
- 从全部的邻居(neighbors)处汇聚信息计算量太大,尤其是在大规模图上
针对问题一,一种方法是在图上增加边,比如在二阶邻居之间加边以及 hyperedges。例如 Multi-GCCF[2] 和 DGCF[3] 通过在二阶邻居之间加边构造了 user-user 和 item-item graph;DHCF[4] 引入了 hyperedge 来构造 hypergraph。另一种方法是引入 virtual nodes 来丰富 user-item interactions。例如 DGCF[5] 引入虚拟的 intent nodes 来将原始图拆解成子图,获得更好的表达能力;HiGNN[6] 通过合并相似的 user/item 来构建粗略图,将合并后的 centers 作为 virtual nodes,这样可以更好的捕捉层级关系。
针对问题二,可以利用采样策略来让 GNN 更加有效。PinSage[7] 设计了一个基于 random-walk 的采样方法,来获得固定数量的(最多访问次数的)邻居。这样,没有和 central node 直接相邻的 node 也可能成为邻居;Multi-GCCF[2] 和 NIA-GCN[8] 随机采样固定数量的邻居。采样是一个在精度和效率之间折衷的做法。
1.2. Neighbor Aggregation
Mean-pooling 是最直接的汇聚策略,它对所有邻居一视同仁。
Mean-pooling 操作简单,但是不同邻居的重要程度可能是不同的。因此在传统 GCN 基础上,一些工作采用 degree normalization,即根据图结构来决定权重。
2. Sequential Recommendation:序列推荐
序列推荐是基于用户的近期活动预测用户下一个偏好,因此需要建模序列特征。下图演示了如何使用 GNN 做序列推荐。

三个主要的问题:
- Graph Construction。为了使用 GNN,序列数据需要转化为图。是否为每一个序列建立子图?是否在多个连续 items 上添加边(比只在连续的两个 items 上加边)更好?
- Information Propagation。哪一种 propagation 机制更好?是否有必要区分序列的顺序?
- Sequential Preference。为了获取用户时间上的偏好,需要集成序列中的 item representation。是否简单使用 pooling 或者使用 RNN 结构来加强这种时间上连续的特征?
2.1. Graph Construction
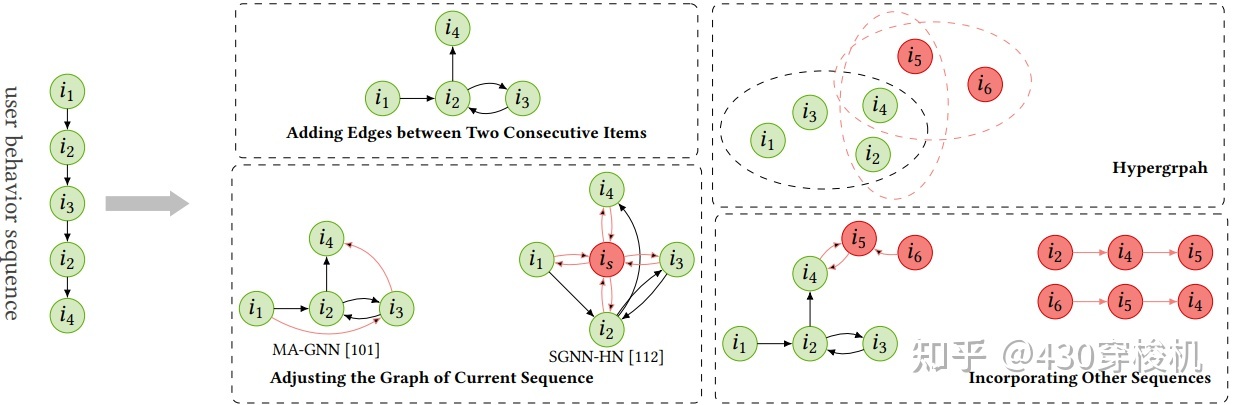
上图展示了将序列数据表示为 graph 的几种策略。一个直观的方式是将每一个 item 看作一个 node,然后连接连续点击的两个 items。然而大部分场景下由于序列较短,这样构造出来的图包含的 node 和 edge 都很少,一些 node 只有一个邻居。这样导致图包含的信息过少,并且不利于 GNN 的学习。因此出现了一些新的构图策略。
一种主流策略是使用额外的序列来丰富 item-item transitions。额外的序列包括其他类型的行为序列[23]、同一个用户的历史序列[24]、整个数据集的部分或全部序列[25][26][27][28]。例如 HetGNN[23] 使用所有行为序列,为连续的两个 items 添加边,边的类型标记为行为的类型。A-PGNN[24] 引入用户历史序列。GCE-GNN[26] 和 DAT-MDI[25] 引入所有 sessions 中的 transitions,同时利用了局部和全局的上下文。这两种方法没有对 transitions 的重要程度做区分,TASRec[28] 则为刚刚发生的 transition 赋予更高权重。除了引入全部 sessions,DGTN[27] 尝试只引入相似的session。
另一个策略是对现有的结构进行调整。例如假定当前 node 不仅对连续的 item 有直接影响,MA-GNN[29] 提取了连续三个 items 并且添加了 edges。为了捕捉远距离 item 的影响,SGNN-HN[30] 引入虚拟的 star node 作为序列的中心,连接所有 items,每个 node 都能从 star node 那儿得到不直接相连的 items 的信息。LESSR[31] 给一个序列建立两张图,一个区分邻居的顺序,一个允许 item 到所有其他 item 的 short-cut path。
此外,SHARE[32] 为每一个 session 构建 hypergraph,hyperedges 通过不同尺寸的滑动窗口定义。DHCN[33] 将每个 session 定义为 hyperedges,然后集成所有 sessions 成为一个 hypergraph。DHCN 和 COTREC[34] 建立 session-to-session graph,每个 session 都是一个 node,根据共享 items 决定权重。
2.2. Sequential Preference
因为 GNN 不能有效捕捉长距离依赖[31],因此在最后一个 item 处输出的 representation 不能充分反映用户的连续偏好。另外很多建图方法也会丢失一部分连续信息[31]。因此有一些工作致力于集成在序列中的 item representation。
首先是注意力机制,一些工作[30][39][40][27] 计算序列中其他 item 与 last item 之间的 attention weight,然后聚合成全局 preference,最终 preference 结合全局 preference 和局部 preference。在序列模型中多层 self-attention 取得很好效果,受此启发,GC-SAN[41] 对 items representation 使用多层 self-attention。
此外,也有工作显式地将序列信号加入聚合过程。NISER[42] 和 GCE-GNN[26] 加入 positional embeddings 来获得 position-aware item representations。为了平衡 consecutive time 和 flexible transition pattern(这两者为何要平衡?),FGNN[37] 使用有 attention 的 GRU 来迭代更新 user preference。
最后,还有工作 DHCN[33] 和 COTREC[34] 使用 session-to-session graph 来丰富 sequence graph,这样模型结合了从 session-to-session graph 以及 items 中学习的 sequential representations。
3. Social Recommendation:社交推荐
随着在线社交网络的出现,使用用户的 local neighbors' preference 提升 user modeling 的 social recommender systems 被提出。这些工作基于同一个假设,即具有社会关系的用户,其 representation 符合 social influence theory:相互联系的人会相互影响。一部分工作[43][44][45][46] 将此作为正则项来约束最终的 user representation,另一部分工作[47][48] 则用这些关系来优化最初的 user representation。
同样的,这些方法只考虑了一阶邻,其实朋友的朋友也会产生影响,这时候又是 GNN 的优势所在。
在 social recommendation 中使用 GNN 会面临两方面问题:
- Influence of Friends
- Preference Integration
3.1. Influence of Friends
通常 social graph 只包含用户之间是否有朋友关系,而并不知道关系的紧密程度。DiffNet[49] 没有区分朋友的影响,直接使用 mean-pooling 操作。接着,一部分工作[50][51][52][53][54][55] 引入 attention。DGRec[53] 根据用户兴趣动态加权 neighbors。这些使用了 attention 的工作,取得了性能提升。
此外,近期一个工作 ESRF[56],认为社交关系不总是可靠。一方面我们看到的社交关系不一定真的有影响力,另一方面社交关系不一定完整。ESRF 使用 autoencoder 来筛除无关 relations 并且建立新的 neighbors。同样的,DiffNetLG[57] 引入隐式的局部影响来预测没被观察到的社交关系,然后利用显式的和隐式的社交关系做推荐。
3.2. Preference Integration
如何结合社交信息和 user-item interaction?目前有两种策略:
第一种策略的优势有两个,一个是两个网络的深度可以设置为不同,另一个是现有的方法可以直接使用。基于这种结构,主要有两种聚合的机制,线性和非线性。线性的工作:DiffNet[49] 将来自两个空间的 user representation 同等看待,使用 sum-pooling 结合两者。DANSER[55] 使用动态权重,根据 user-item paired features 计算。非线性的工作:常见做法是将两个 vector concatenate 起来,然后经过 MLP。
第二个策略的优势是会同时捕捉 high-order 社交关系的影响和 user-item 中体现的用户兴趣,这两种信息是持续地一致地反映用户偏好。DiffNet++[54] 设计了一个 two-level attention network 在每一层更新 user nodes。它首先在两张图上分别使用 GAT 汇聚 neighbors 信息,然后再使用另一个 attention 网络融合两个 hidden states of neighbors。同样地,SEFrame[58] 使用异质(heterogeneous)图来融合社交关系中的知识、user-item interactions、item transitions,然后使用一个 two-level attention network 做聚合。
目前来看,没有明显证据说明哪一种策略更好。
4. Knowledge Graph based Recommendation:基于知识图谱的推荐
相比于社交网络,Knowledge Graph 表达的是 items 之间的关系,可以用来增强 item representation。另外它还连接了用户历史喜好 items 和被推荐 items,能有助于提升模型可解释性[59](即我是根据你以前喜欢什么从而推荐你什么)。
同时,知识图谱也存在结构复杂的问题,实例(entities)和关系(relations)都有多个种类。早期工作[60][61][62][63] 直接使用 knowledge graph embedding (KGE) 方法学习 entities 和 relations 的 embedding,但这些 KGE 方法并不是为推荐任务设计的。
目前高效的基于知识图谱的推荐系统有两大主要问题:
- Graph Construction。如何聚合 user-item interactions 和知识图谱中的语义信息?是否显式地将 user nodes 放入知识图谱或是隐式地使用 user nodes 来区分不同 relations 的重要程度?
- Relation-aware Aggregation。知识图谱中的 relation 有很多种,如何设计一个聚合函数聚合这些信息?
4.1. Graph Construction
一个方向是将 user nodes 放入知识图谱。KGAT[64]、MKGAT[65]、CKAN[66] 使用统一的网络来处理两张图(user-item bipartite graph 和 knowledge graph),他们将 user nodes 视作一种实体,user-item interaction 则作为一种关系。另一些工作关注和 user-item 样本对相关的 entities 或 relations。例如用户发生过交互的 items 或者知识图谱中相关的语义信息[67][68]。还有一些工作基于一个假设:两个 nodes 之间的最短路径反映了更值得依赖的连接。AKGE[68] 这样建立子图:使用 TransR[69] 预训练知识图谱中 entities 的 embeddings;计算相连 entities 之间的最短路;保留 K 条由目标 user 到 item node 之间的最短路。当然,这种做法会受限于预训练的模型好坏以及距离度量函数的选择。ATBRG[67] 遍历(exhaustively)搜索目标 item 以及用户历史行为中的 items 的多层实体邻居,并且通过重叠的实体来恢复用户行为和 target item 之间连接。为了强调信息量大的实体,ATBRG 对只有一个 link 的 entities 进行剪枝。这样的好处是获得与 user-item pair 更相关的子图,那是也是低效的。
另一个方向是隐式地使用 user nodes 来区分不同 relations 的重要程度。KGCN[70] 和 KGNN-LS[71] 将 user nodes 作为 queries,来给不同 relations 加权。这一系列工作重点在于从 relations 角度研究用户偏好,而不是 collaborative signal in user-item interactions。
4.2. Relation-aware Aggregation
从推荐系统角度来说,user 也是一个影响因素。一些工作改进 GAT 来对连接的实体加权,加权后用于更新 central node,这个权重则是通过一个打分函数 a(ei,ej,rei,ej,u) 给定。所以挑战在于如何设计这个打分函数。
对于那些将 user 看作知识图谱中实体的工作[67][65][64],他们并不显式地在 relations 中建模用户偏好,而是利用连接的 nodes 以及他们的 relations 来区分不同实体的影响程度。KGAT[64] 依据连接的实体在 relation space 中的距离来赋予权值:

5. Other tasks:一些小众的方向
5.1. Points-of-interest (POI) recommendation
基于位置的推荐,每个位置点有各种属性,如店名、经纬度、机构类型,也有用户的历史消费记录SGRec[72] 利用同一 POIs 的其他订单(check-ins)来丰富当前订单序列(check-in sequence)。Cheng et al.[73] 认为如果用户频繁地连续到访两个 POIs,那么这两个 POIs 之间的 geographical influence 就越强。同时,为了捕捉地理分布信息,这篇工作还依据 POIs 之间的距离赋予 edge weights。
5.2. Group recommendation
目标是对群组(group)进行推荐,这个任务中存在 user-item、user-group、group-item 三种关系。可以说 group 是连系 user 和 item 之间的桥梁。挑战在于最大化每个组成员的满意度同时还要最小化他们之间的不公平。
根据 group 是否作为 node 出现在图中,可以将相关工作分为两类。分别介绍这两类的代表工作。GAME[74] 引入 group node,然后使用 GAT 赋予权重。Group representation 不停迭代更新。但是,这种做法无法应对组成员变动或者新组成立的情况,即是种 transudative method。GLS-GRL[75] 则通过一种 inductive 方式学习 group representation,它为每一个组建立对应的图,group representation 根据组内 user representations 生成。
5.3. Bundle recommendation
捆绑推荐,旨在推荐一组商品供用户整体消费,这个任务中存在 user-item、user-bundle、bundle-item 三种关系。BGCN[76] 将三种关系统一在一个网络中,设计了基于 user 角度的两个层面(item level and bundle level)的 propagation。HFGN[77] 建立 hierarchical structure,user 与 bundle 交互,bundle 与 item 相互映射,并且捕捉 bundle 中的 item-item interactions。
5.4. Click-through rate (CTR) prediction
根据不同 features 预测点击率。Fi-GNN[78] 使用 GNN 捕捉 features 之间的 high-order interaction。建图的过程中,每个 node 对应一个 feature field,不同 fields 之间通过 edges 连接。这样通过 propagate node information 来实现 feature interaction。Fi-GNN 没有考虑用户行为中隐含的 collaborative signals,DG-ENN[79] 同时建 attribute graph 和 user-item collaborative graph,并且使用用户之间的相似关系和 item-item transitions 来丰富 user-item interaction 信息。
5.5. Multimedia Recommendation
主要是结合文本、图片或视频进行推荐。MMGCN[80] 为每一个模态(modality)建立 user-item graph,最终的 user/item representations 是不同模态中 user/item representations 之和。GRCN[81] 使用多模态信息修正 user-item interactions。在每一个 propagation layer,GRCN 取不同模态中 user-item 相似度的最大值作为 user-item edges 的权重,再使用这些权重汇聚 neighbors。MKGAT[65] 将 user nodes 和 multi-modal knowledge graph 统一到一张图中,然后使用 relation-aware GAT 传播信息。
6. Future research directions and open issues:展望未来研究方向
Scalability of GNN in Recommendation。直接使用 GNN,在工业界的大规模数据上效率很低。一种思路是使用采样策略降低图的大小,另一种思路是设计可扩展的高效的 GNN。
Dynamic Graphs in Recommendation。实际场景中 users、items 以及他们之间的关系都是动态变化的,为了能做到 up-to-date recommendation,模型需要能够迭代更新。
Reception Field of GNN in Recommendation。GNN 有多个隐藏层,那么最终 representation 的感受野是多大?而且,一些边缘的 nodes 的感受野会远小于中心的 nodes,太小的感受野无法捕获全局信息,太大的感受野会出现 over-smoothing 问题。一个代表工作是 ICML'18 - Representation Learning on Graphs with Jumping Knowledge Networks - 知乎 (zhihu.com)
Privacy Preserving。由于法律对用户隐私的保护,社交网络和历史订单可能无法获得。此外,还有一个新问题,如何在不上传用户数据的情况下,使用本地数据进行推荐。此外,对于一些 cross-domain 问题(IJCAI'21 - Cross-Domain Recommendation-Challenges, Progress, and Prospects - 知乎 (zhihu.com)),也存在用户身份无法获得的问题。