本讲将介绍分类模型。对于而分类模型,我们将介绍逻辑回归(logistic regression)和Fisher线性判别分析两种分类算法;对于多分类模型,我们将简单介绍Spss中的多分类线性判别分析和多分类逻辑回归的操作步骤下。
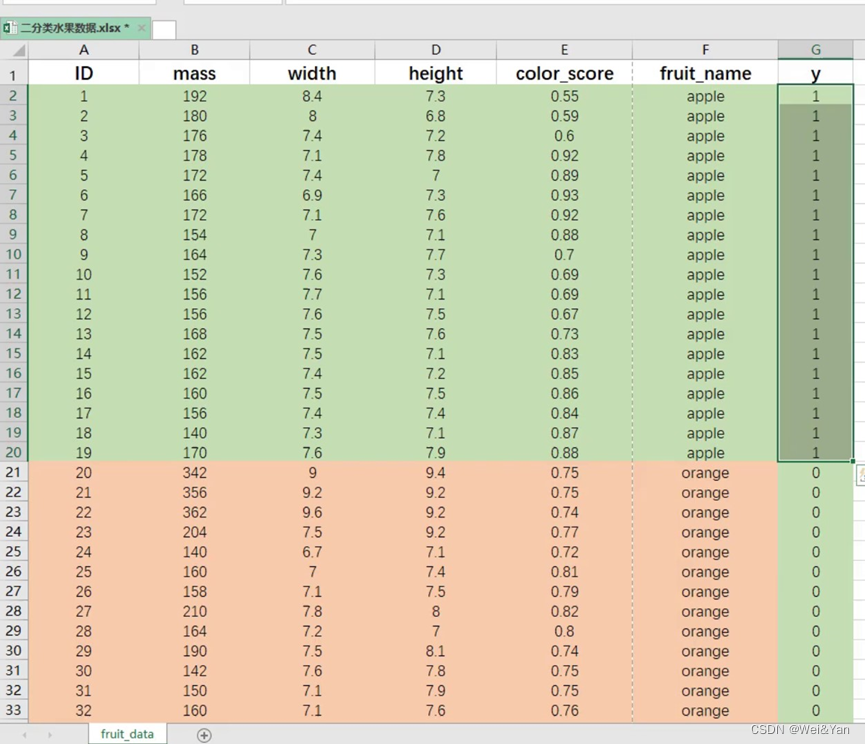
本题按水果分类的例子

思路:逻辑回归原始现象
- 设置虚拟变量y
- 进行回归,估计出来的y-hat于虚拟变量中哪个更接近则分类为那个。
Eg:设1苹果,2橙子 若y与1接近为苹果,与0近为橙子
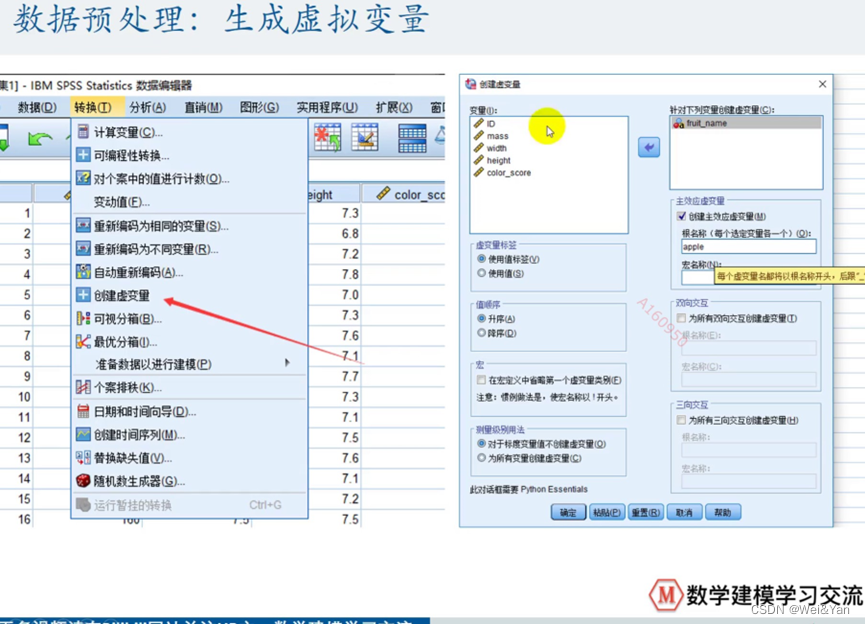
数据预处理生成虚拟变量
自变量mass重量,width水果宽度,height水果高度,color_score颜色(0-1)
因变量:fruit_name水果名
生成虚拟变量操作:转换->创建虚拟变量
3.逻辑回归: 
4.建立模型:
不难看出u与x有相关性所以存在内生性,导致得到的数据不准确,所以需要进行改进。
解决内生性的方法:两点分布

连接函数的取法 
这两个公式由图得出两个模型都符合x属于(-∞,+∞)y属于(0,1) 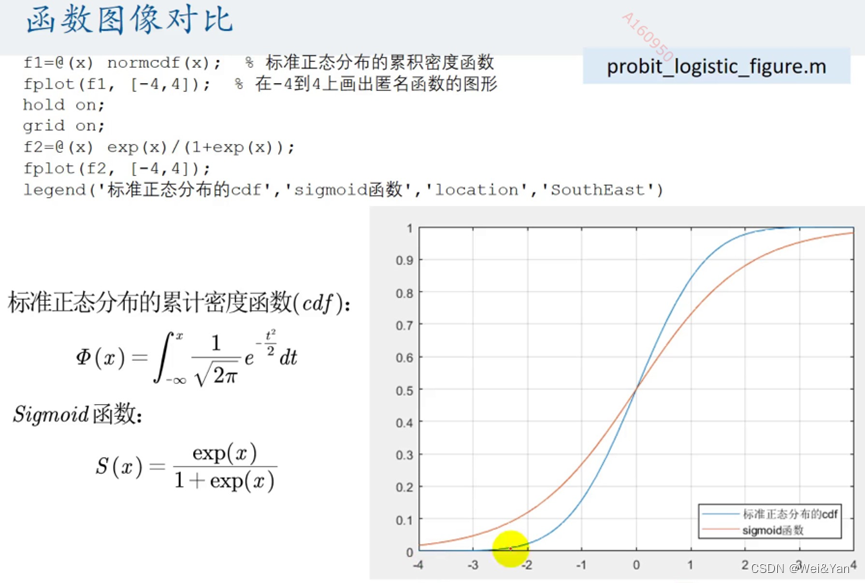
如何求解?
将自变量代入式子得到y与0.5对比(本题按0.5对比是水果案例)
极大似然估计能够估计粗B_hat再推出y_hat最后预测。
怎么用于分类?
这里我们选择第二个方程e^X/1+e^x 
SPSS求解二元逻辑回归: 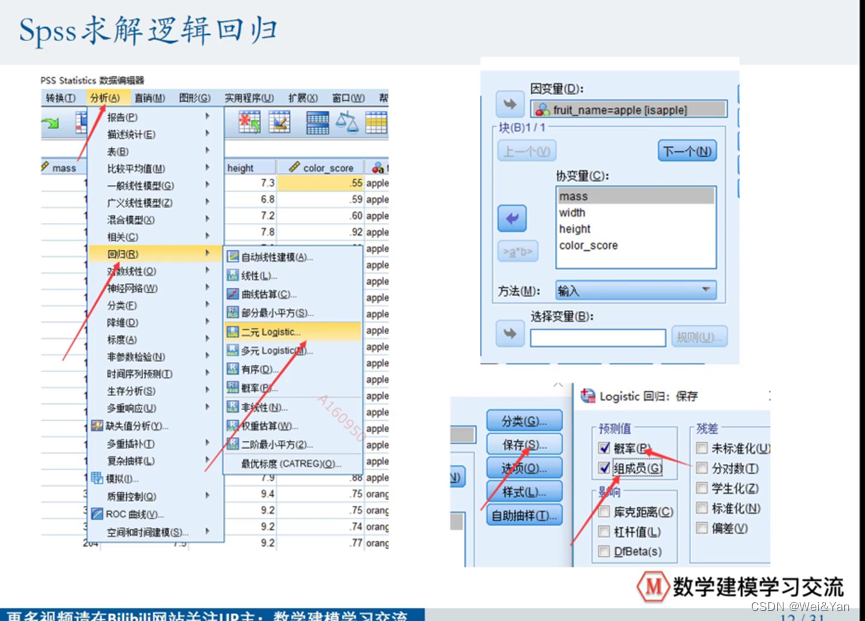

逻辑回归系数表: 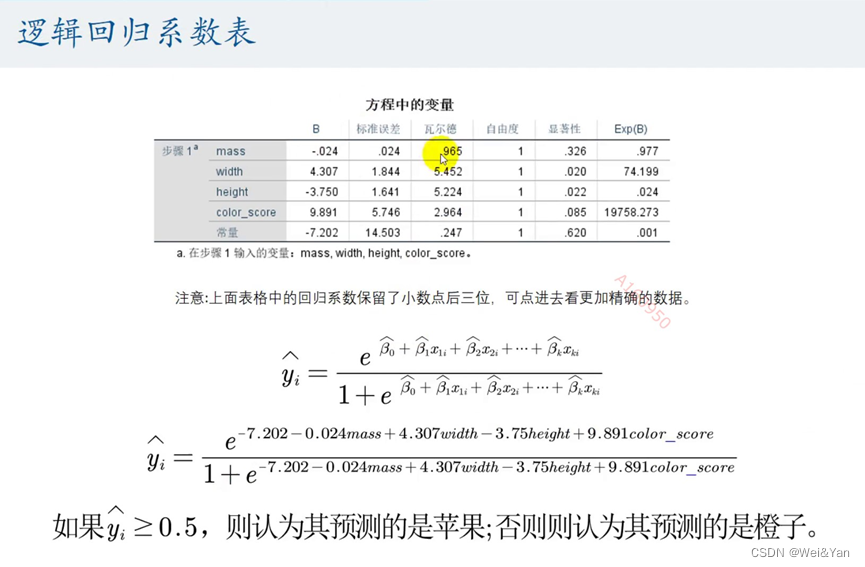
假如自变量有分类变量怎么办?

预测结果较差怎么办?
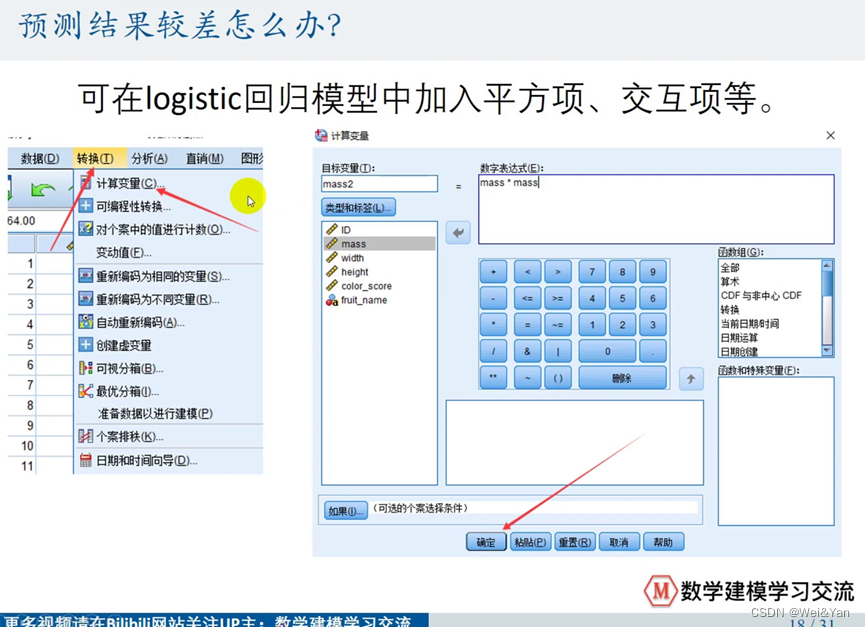
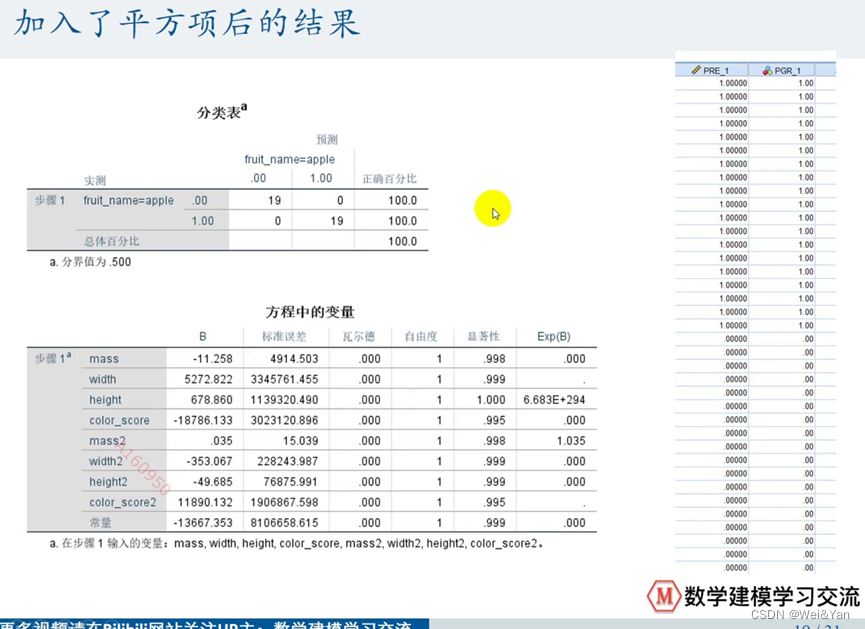
负面影响:
增加平方自变量过于让拟合线完全贴近样本数据,导致预测数据不吻合。
如何确定合适的模型?(既使得样本数据符合,也使得预测数据更加可靠) 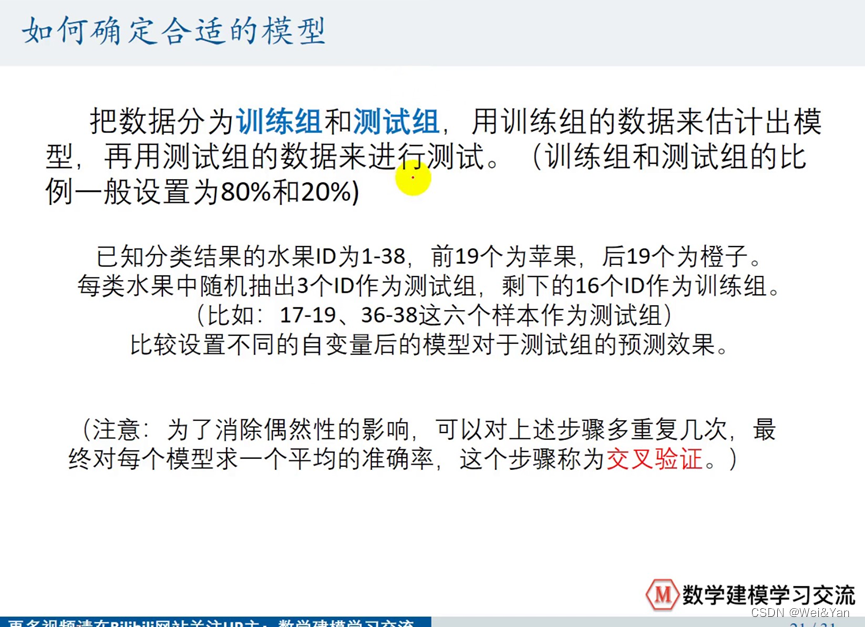
这里我们把苹果和橙子都剔除三个再对比
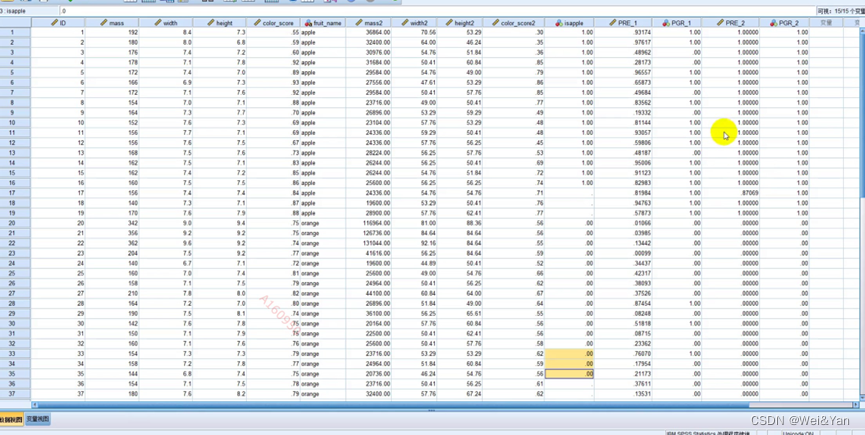
Fisher线性判断别分析 
核心问题:找到系数向量w 
SPSS操作:
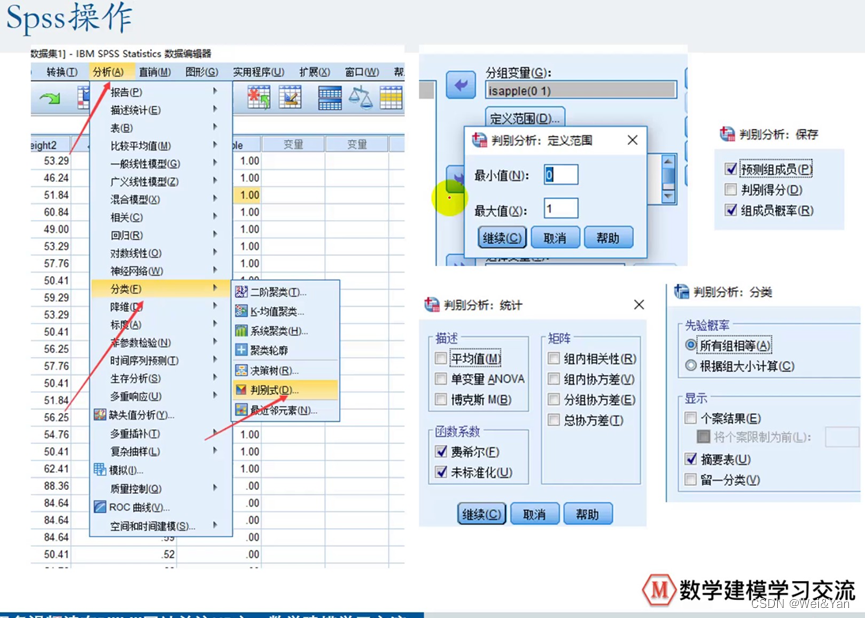


多分类问题:

Fisher判断多分类
1.设置好分类数量
2.摘要表
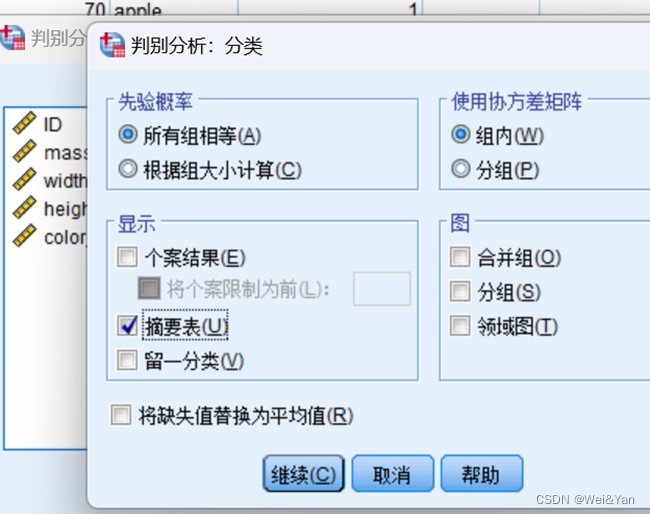
3.保存中:预测组成员+组员概率

Fisher多分类判别结果结果:

Logistic多分类判别:
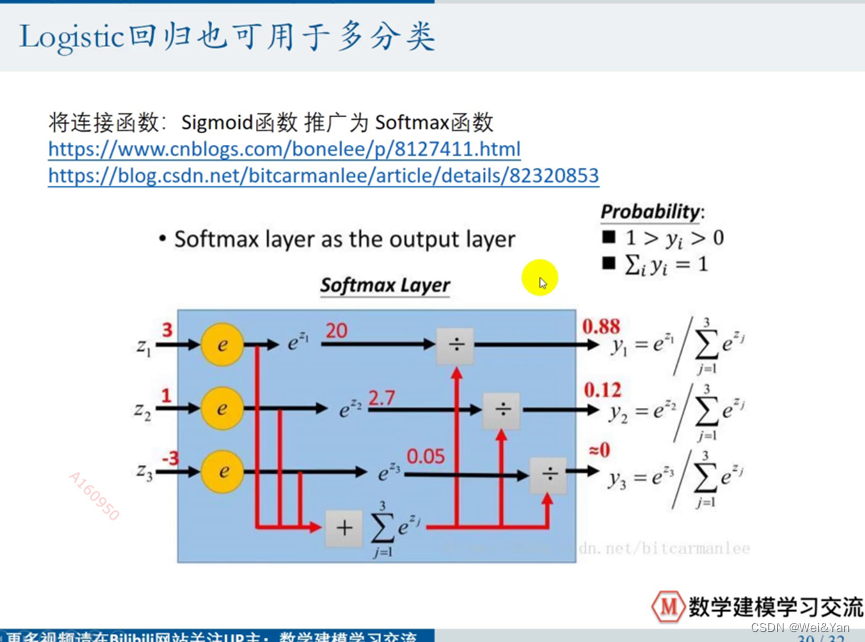
Spss操作:
分析->回归->多元Logistic
统计中:选择分类其余可看自己是否需要选择
保存中选择:估算响应概率,预测类。

结果: 
课后作业:

解答:
为了方便能进行多元分类,我们需要自定义类别的名称,如将变色鸢尾为1,山鸢尾为2,维吉尼亚鸢尾为3.
博主选择了Logistic多元分类:
但是为了防止样本数据或预测数据的不准确性,我们将数据分为训练组和测试组,最后得到的分类结果。

预测结果:
