第1部分_逻辑回归求解二分类问题(spss)
详情参考pdf
保留一列:苹果为1,橙子为0.删除想要预测的值
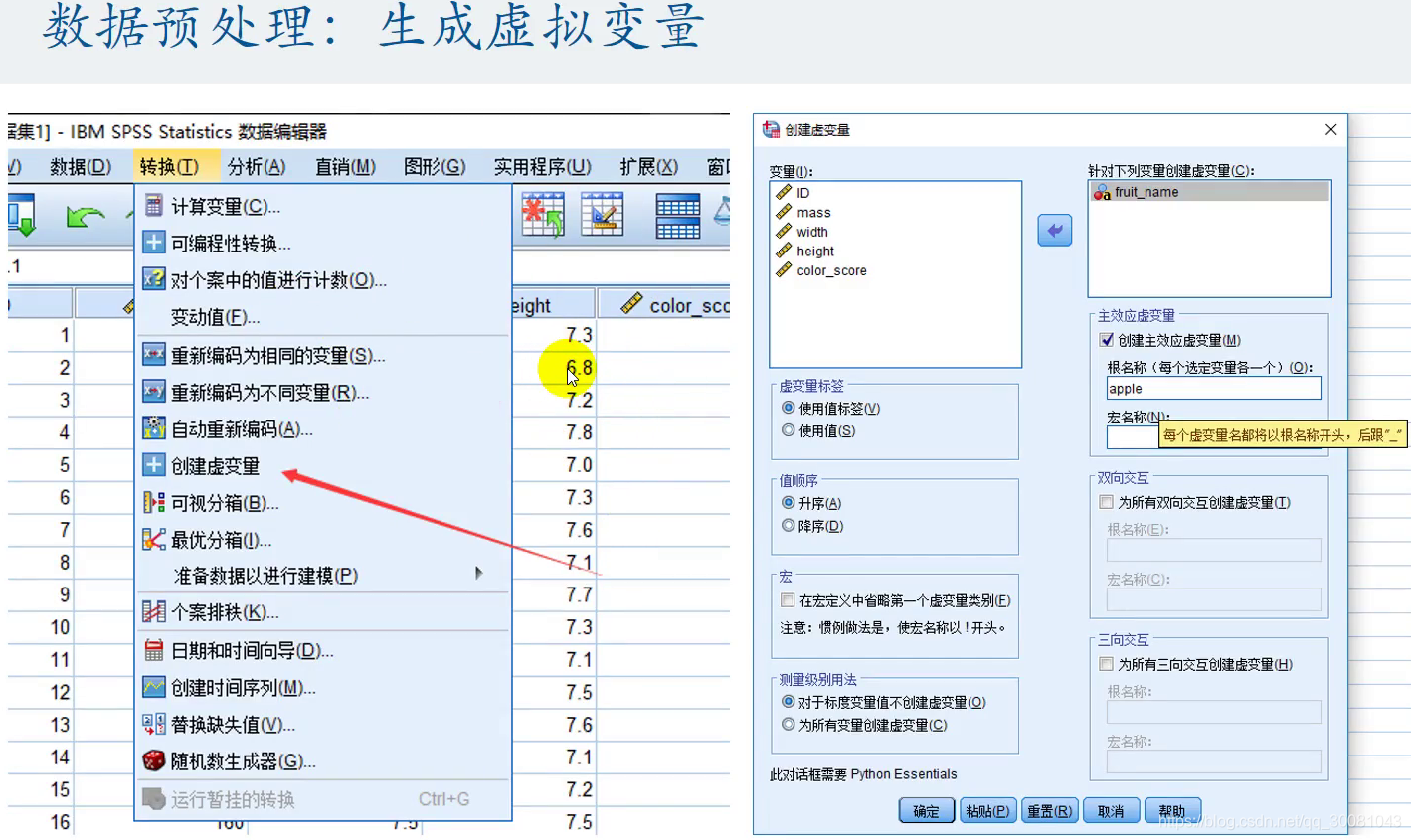
越接近1,我们越有理由相信它是苹果。

内生性:扰动项和自变量相不相关

连接函数,保证定义在0到1.


论文: 我们通过极大似然估计,可以估计出β,记为β-hat,有了它就可以算出yi-hat,然后就可以进行预测

spss操作
分析-回归-二元逻辑回归
把虚拟变量移到因变量。
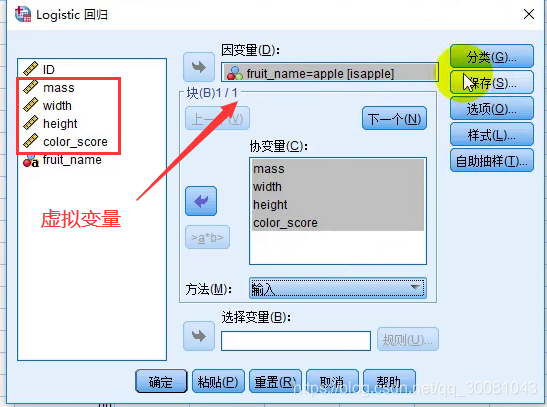
如果有定型变量,如男和女
点击选项,移到分类协变量,
参考类别决定了把谁设置为对照组。
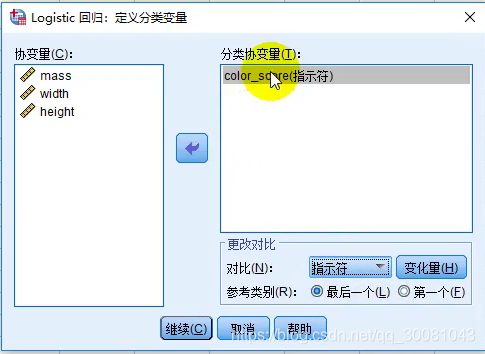

取3个作为测试组(就是把isapple清除3组),然后预测

第2部分_Fisher线性判别分析(LDA)和多分类问题探究
Fisher线性判别分析
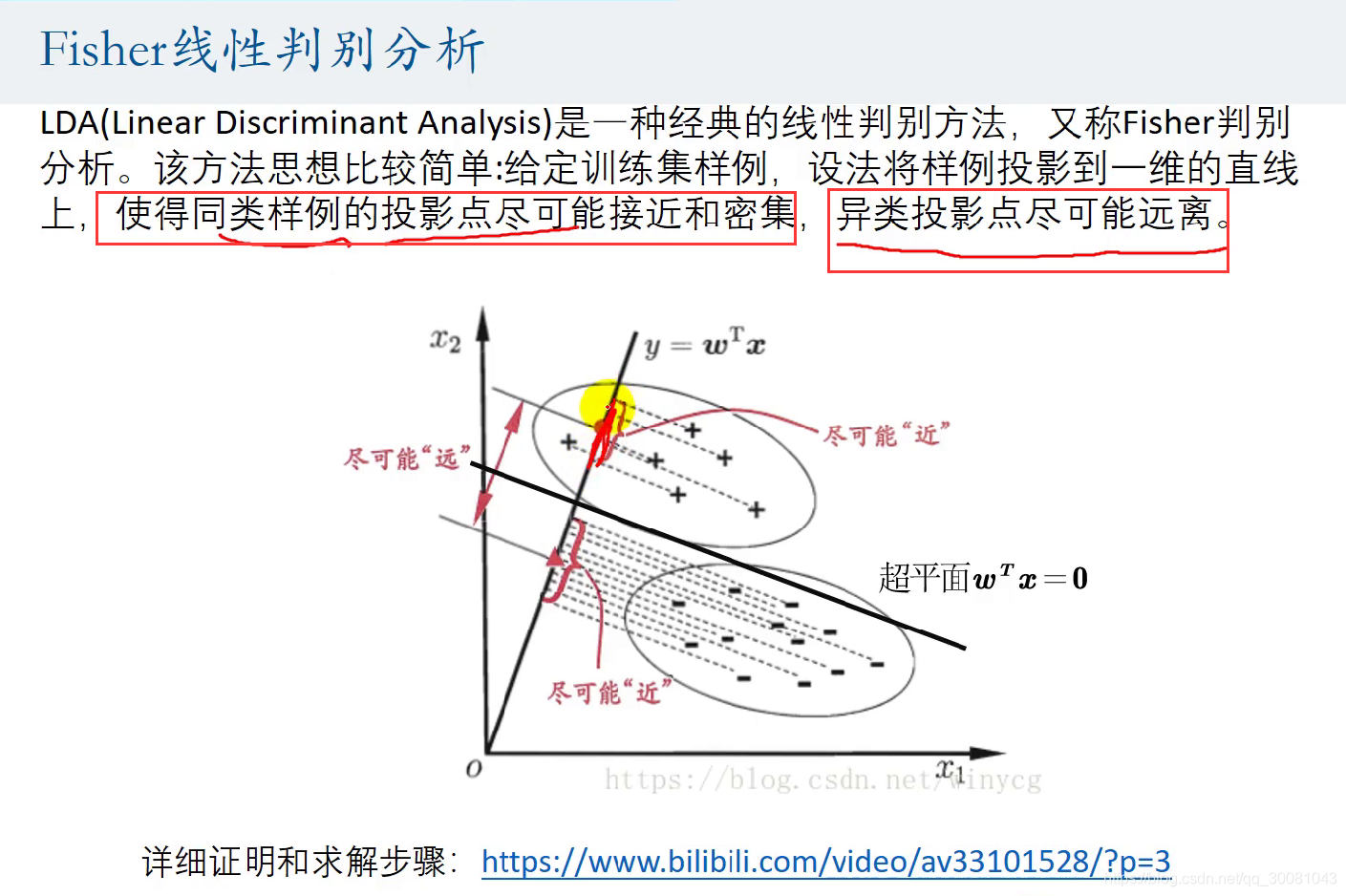
Fisher线性判别分析原理:同类投影点尽量密集,不同类则尽可能远离。
就是方差要小,就是投影点密集。
SPSS-Fisher线性判别分析
spass
分析-分类-判别式
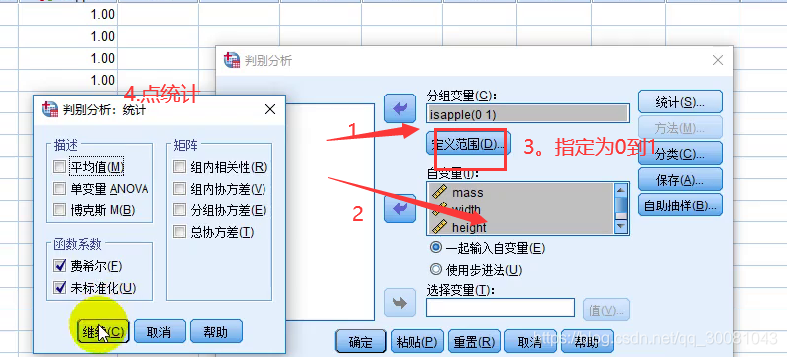
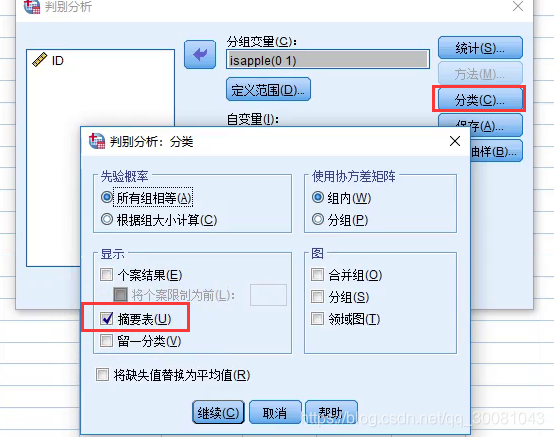
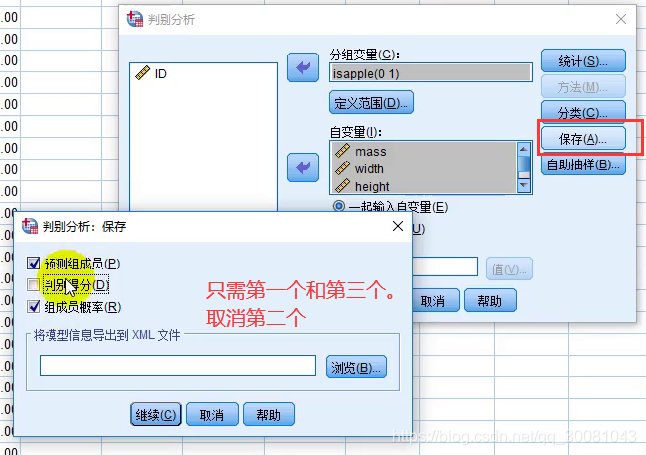
重点关注
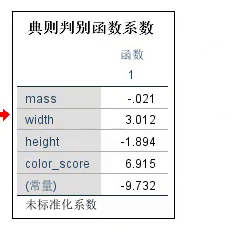
Omega (ω)即,未标准化系数
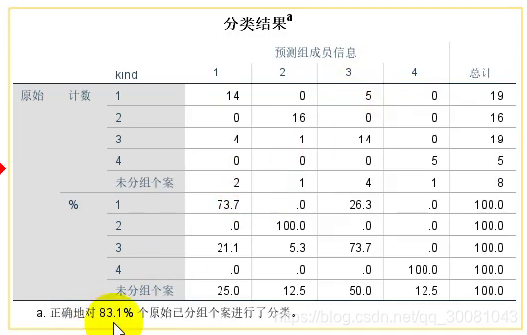
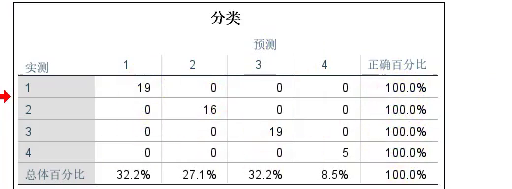
分类的结果,即代表着预测的准确率

把参数代入2个叶贝丝判别函数,比较大小,较大的就归哪一类。
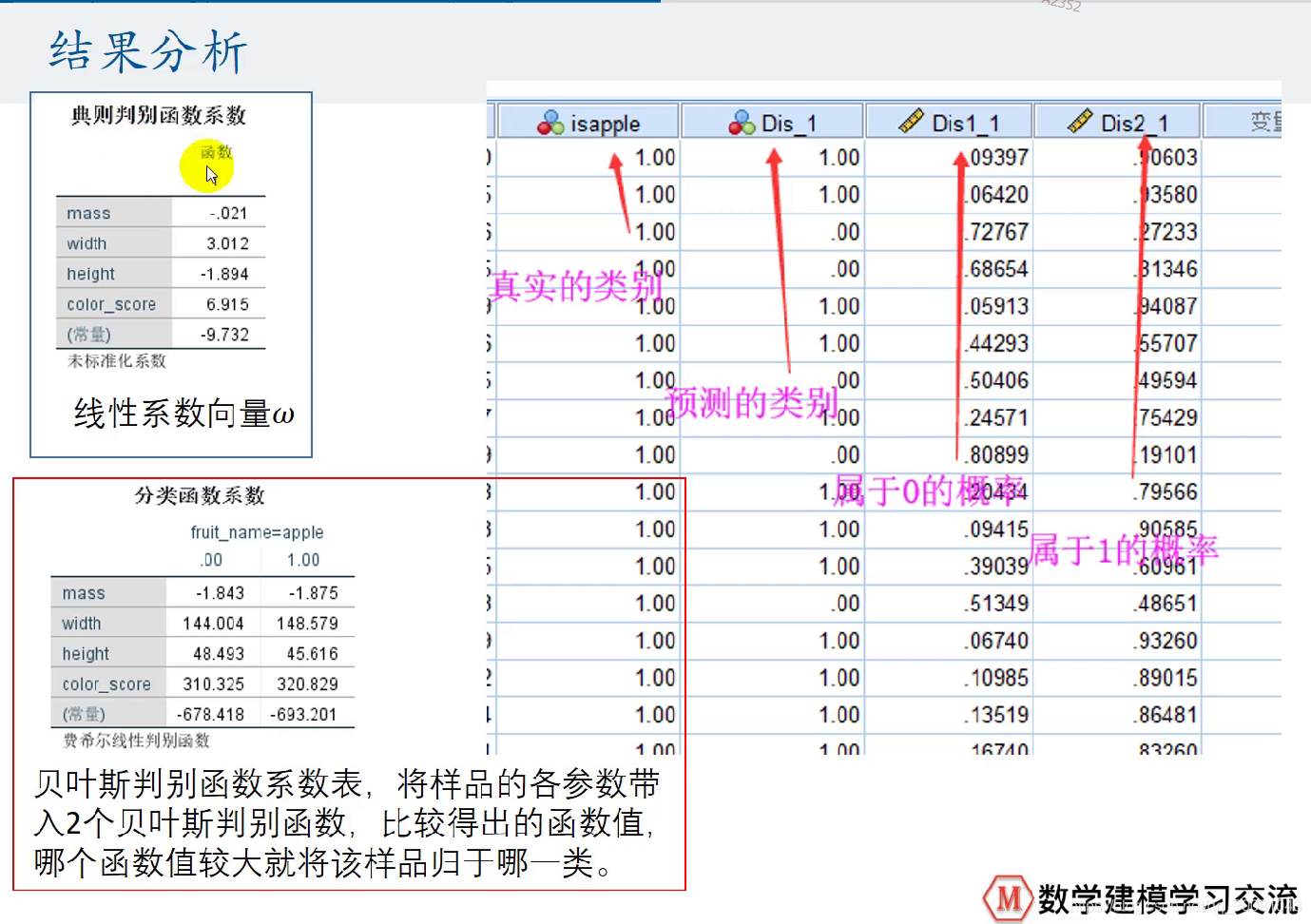
论文中:判别函数系数、预测的结果、分类的成功率
多分类的问题
- 导入数据
- 分析-分类-判别式
- 分组变量,自变量,定义范围(1,4)
- 统计 - 费希尔,半标准化

- 分类-摘要表
- 保存-预测组成员,组成员概率
(logistic)逻辑回归也可以用于多分类
spss
1.分析-回归-多远logistic
因变量:kind(最后一个)
因子:4个指标
2.保存
存在过拟合问题。可以用训练组和测试组来解决。
作业
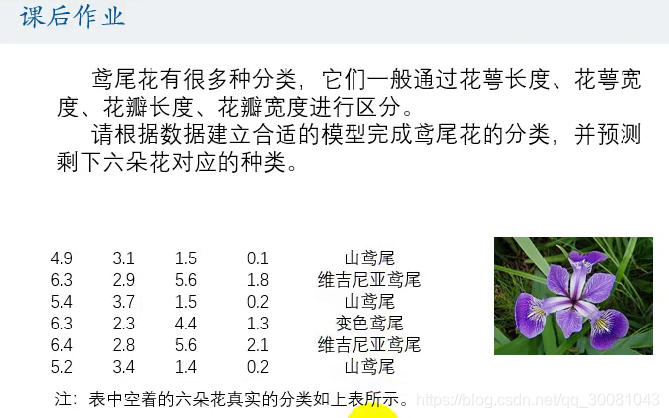
- 先把原来的文字,转为数字的分类
https://jingyan.baidu.com/article/495ba8410d8f4f38b30edeff.html
2.然后就根据以上的分析-分类-判别式(*,推荐),或者多元logistic 逻辑回归来做。

第1部分_Kmeans聚类算法
分类与聚类
分类与聚类的区别: 分类是已经类别的,而聚类是未知的。

聚类:将样本划分为由类似的对象组成的多个类的过程。
作用:更加准确估计、分析和预测。探究相关性和差异。
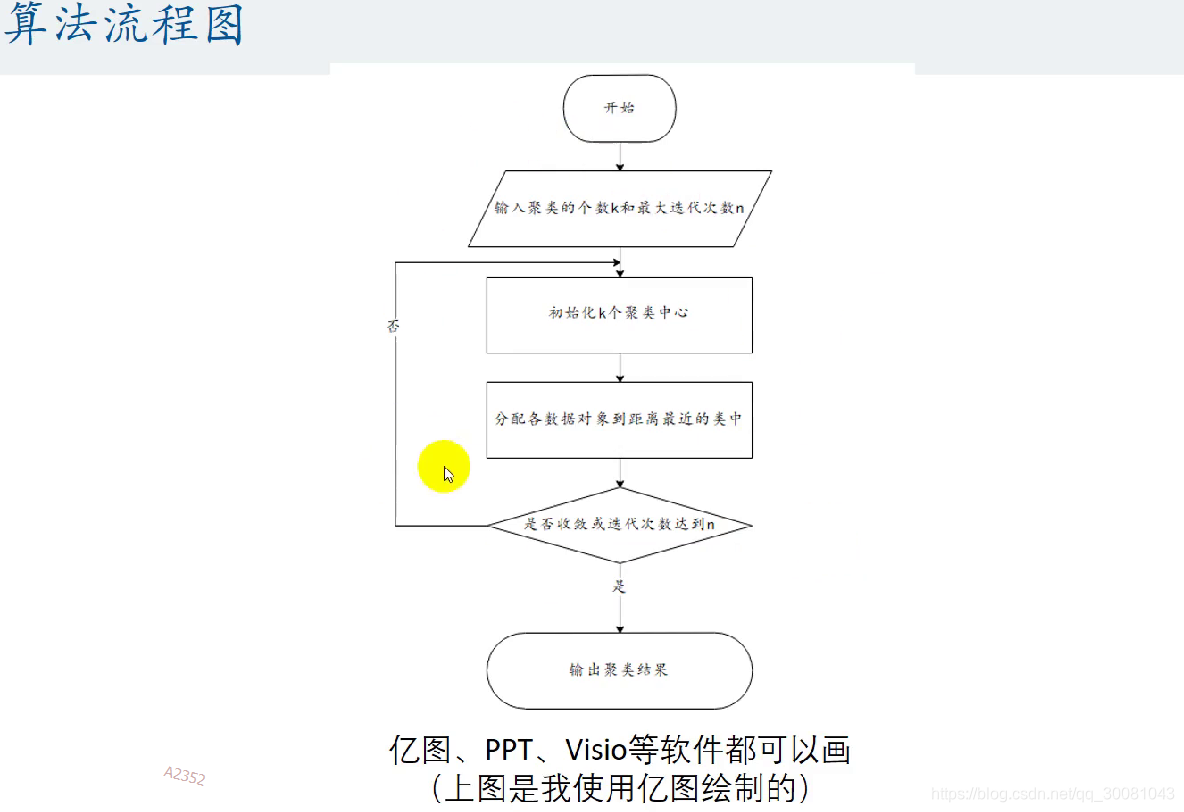
K-means算法流程
1.指定类的个数K
2.初始化K个聚类的中心,不一定是样本点,也可以是平面上的任意一点
3.计算其余的各个数据对象到这k个初始聚类中心的距离,将比较近的划分到那个聚类中心
4.调整新类,重新计算出新类的中心
5.重复步骤3和4,看中心是否收敛(不变),一般重复10次就停止循环。

K-means优缺点
聚类中心容易受到异常点的影响,即对缺点3 的解释。

K-means ++ 算法

算法概述

spss操作
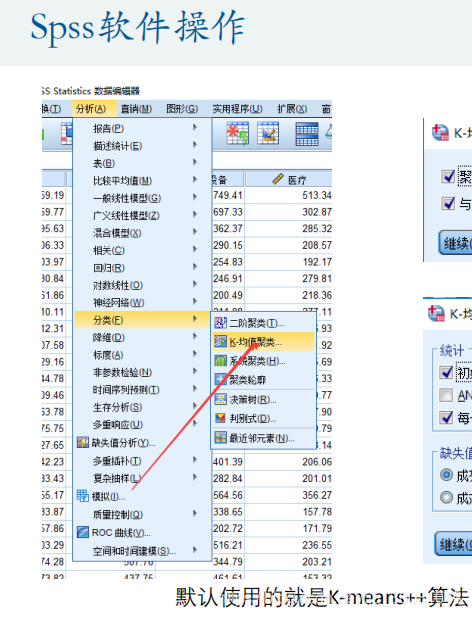
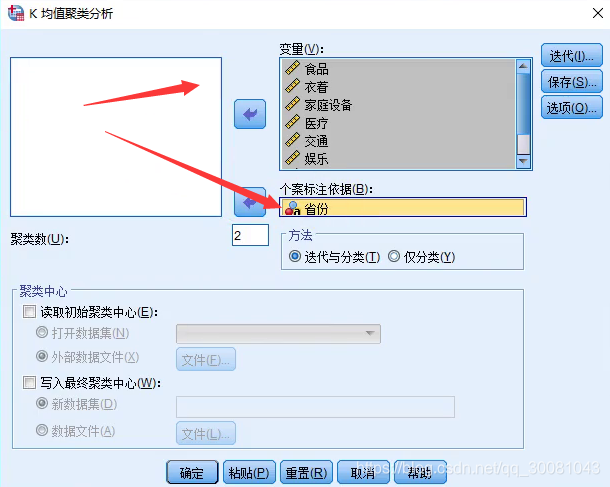
聚类数:即K,分类的个数,这里取2.

一般取10,不改这个选项也可以。默认10
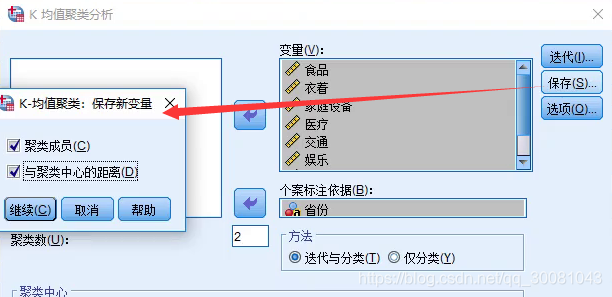

spss结果
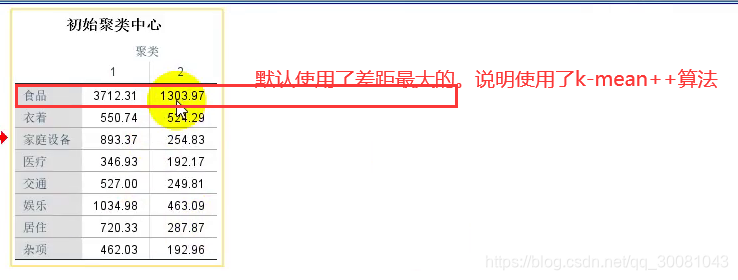
分类代表着各省份的消费水平的差距
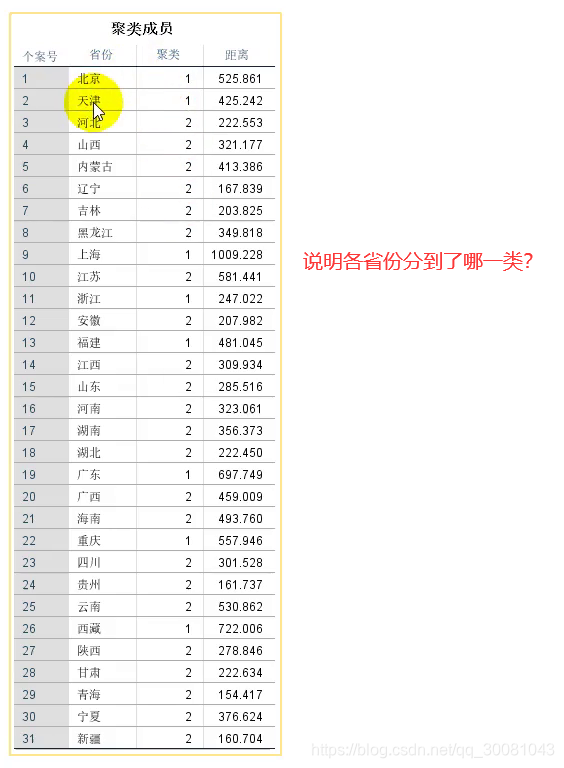
距离表示对应的省份与最终聚类中心的距离
关于算法的讨论
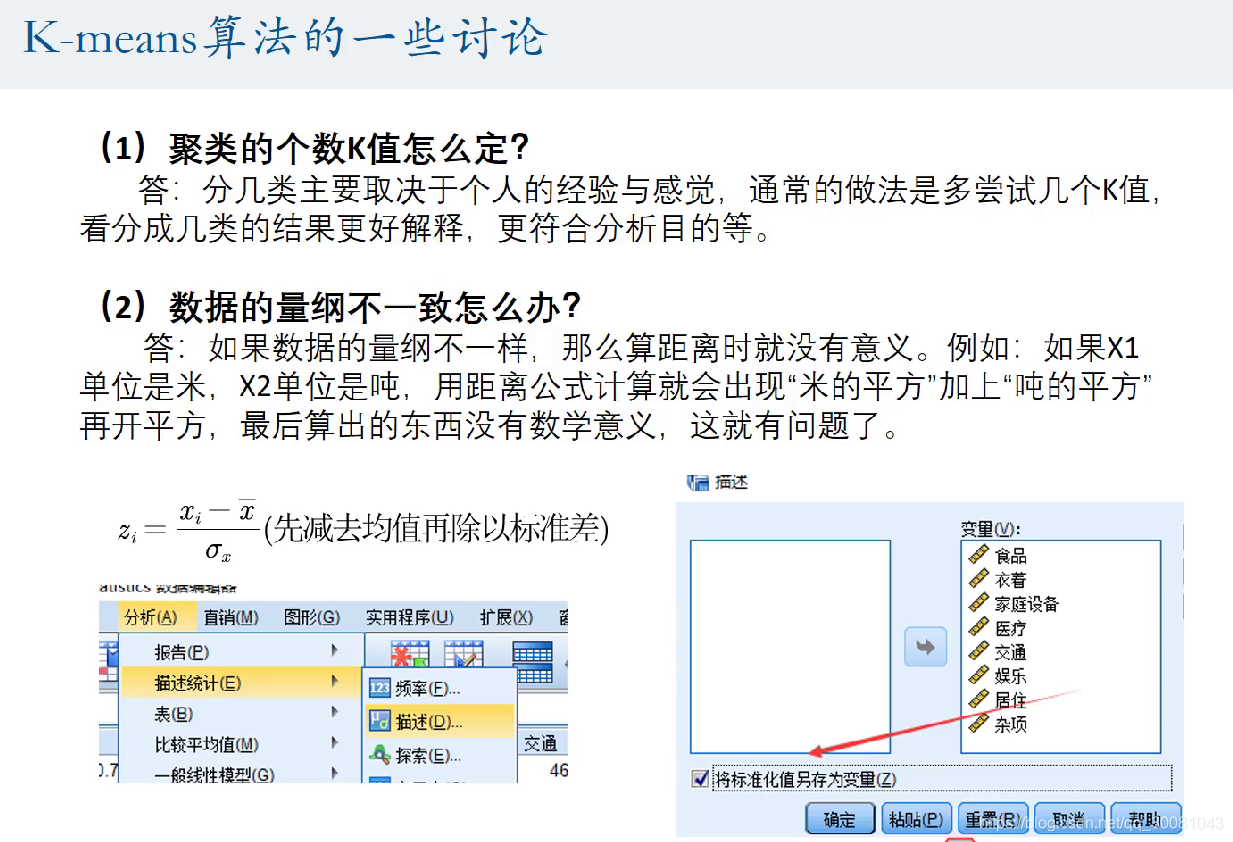
K值由经验而定。
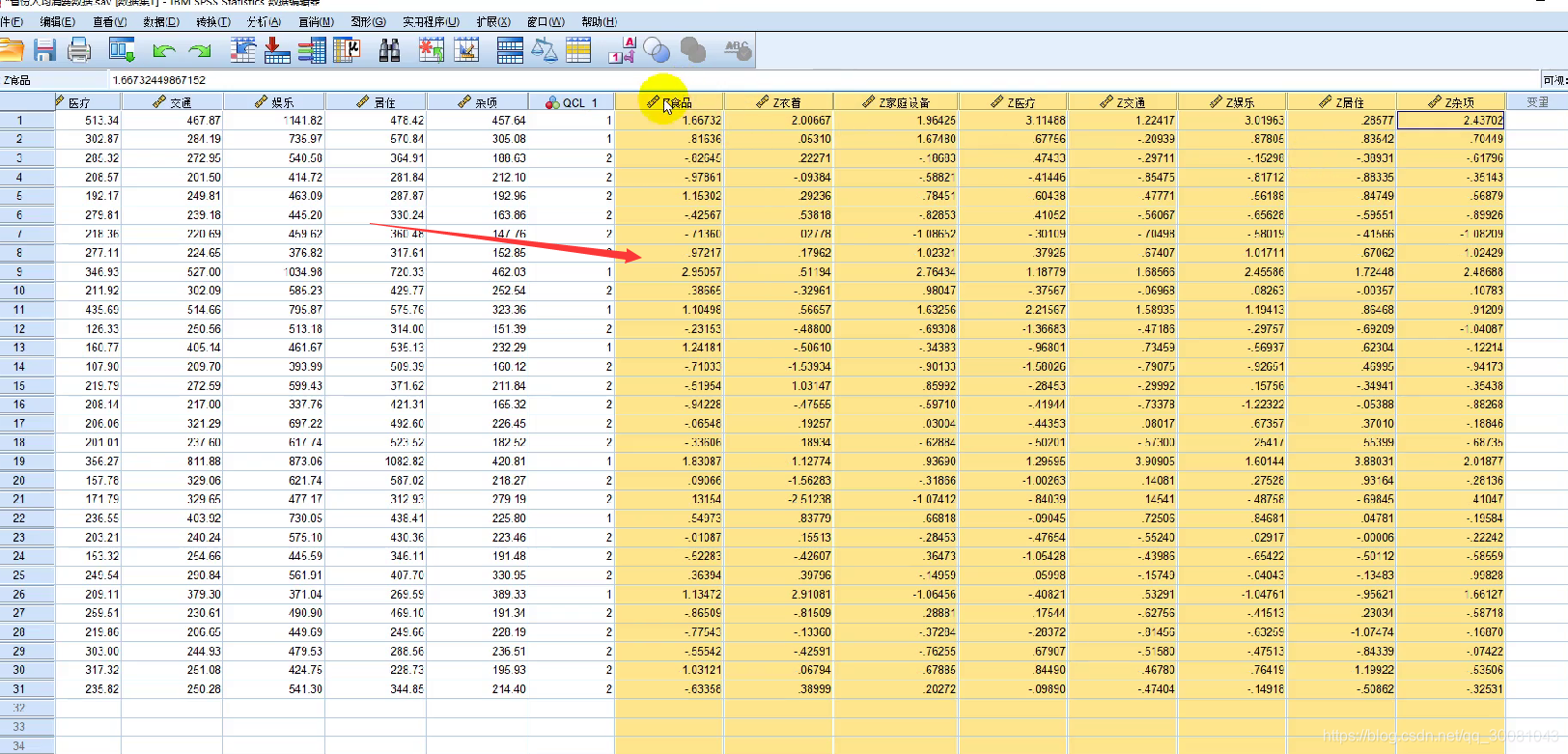
量纲不一致可以使用spss来同一量纲。
选中数据-分析-描述统计-描述-移动到变量-确定。
第2部分_系统层次聚类算法和聚类效果图的绘制(不指定K)
系统层次聚类写论文参考:https://www.bilibili.com/video/BV1i7411k7fB?p=38
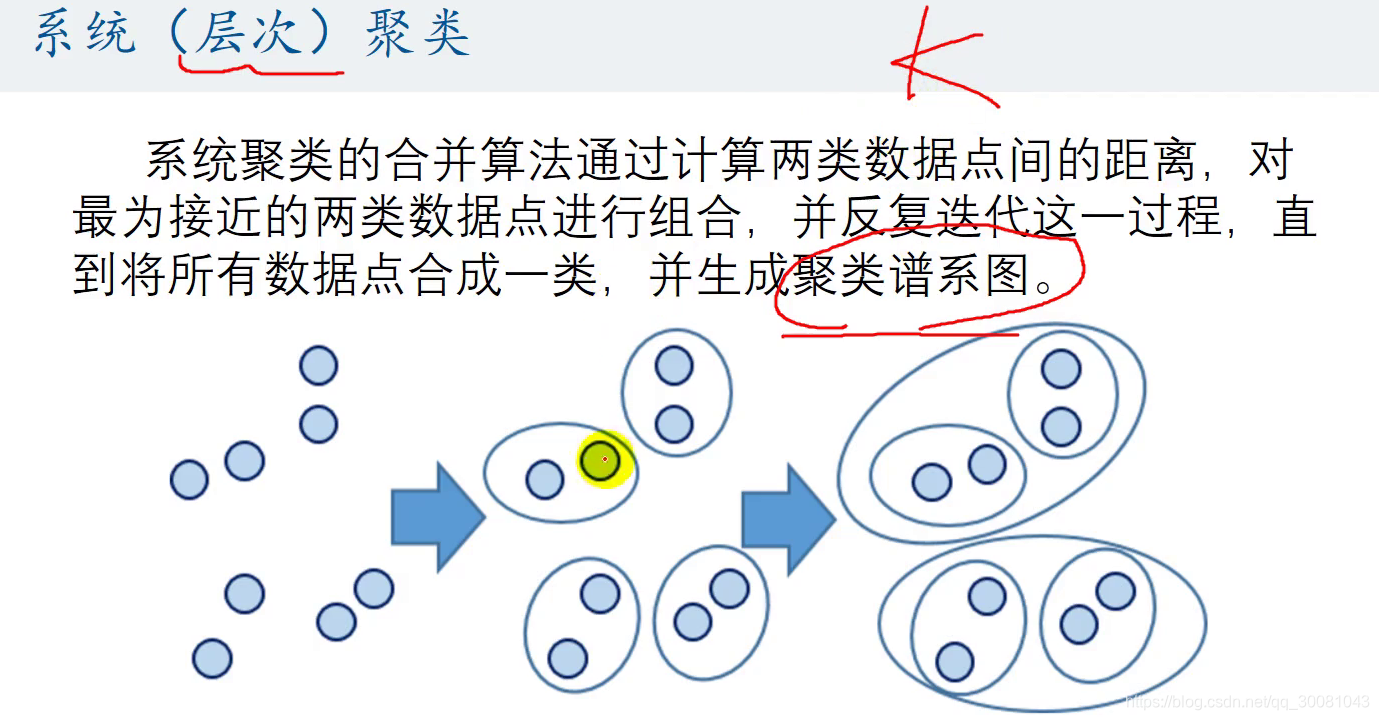
系统层次聚类算法
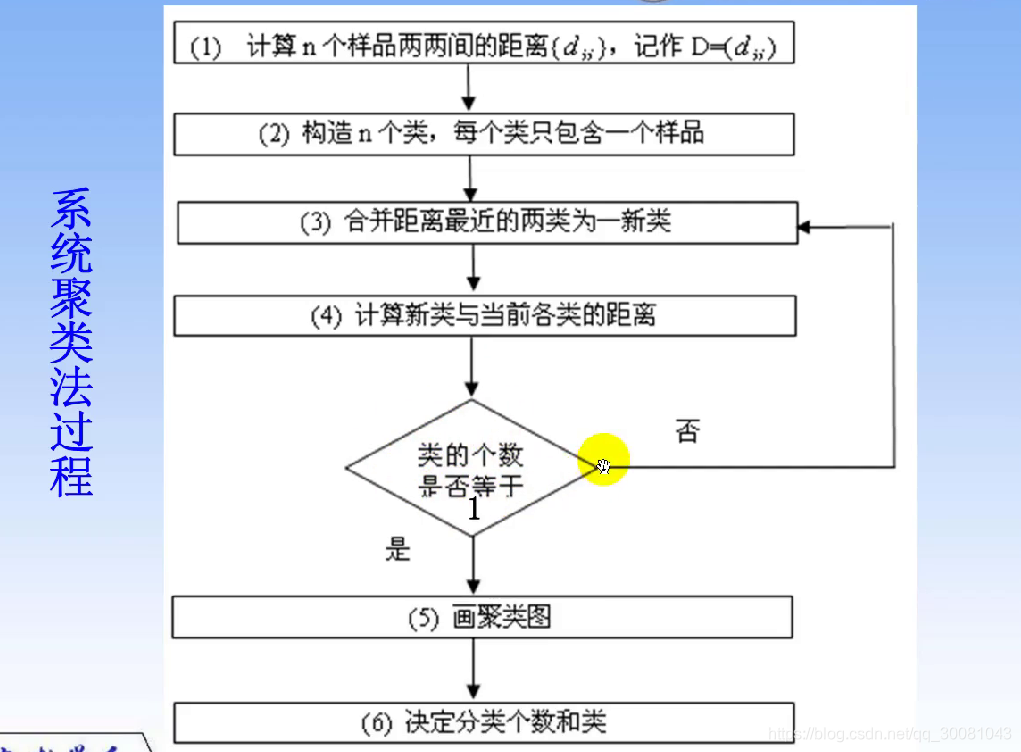

spss实现系统聚类
分析-分类-系统聚类
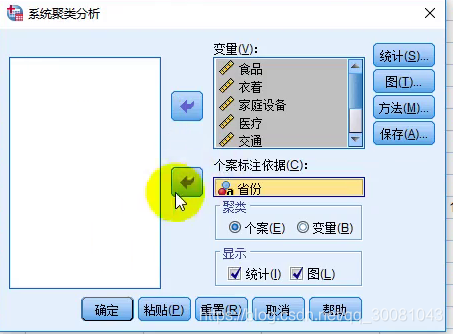
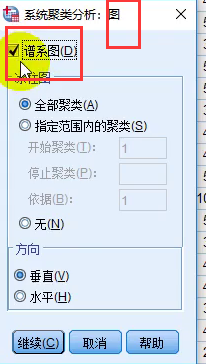
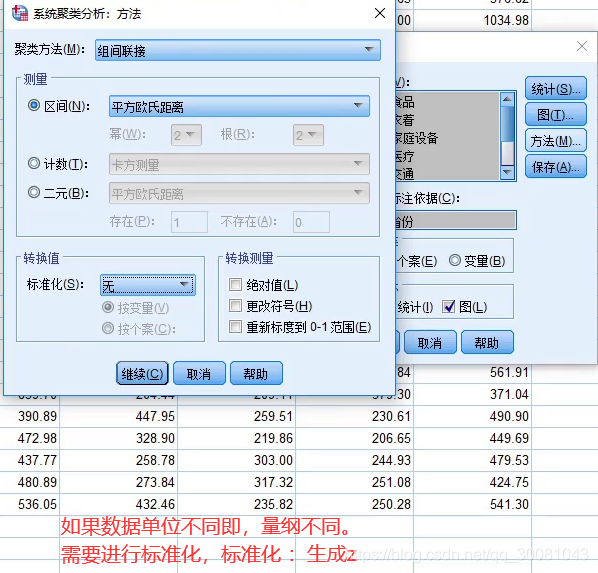
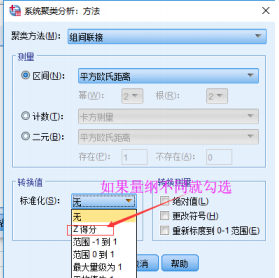
SPSS结果

用图形估计聚类的数量
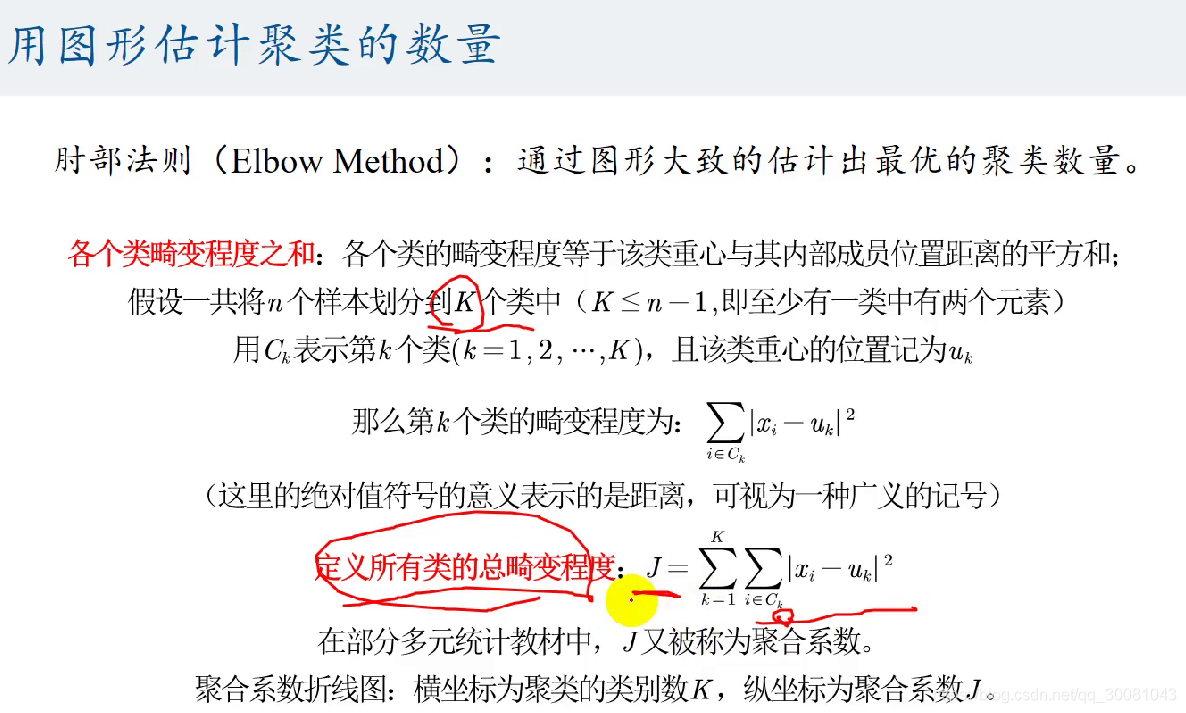
聚合系数折线图的画法
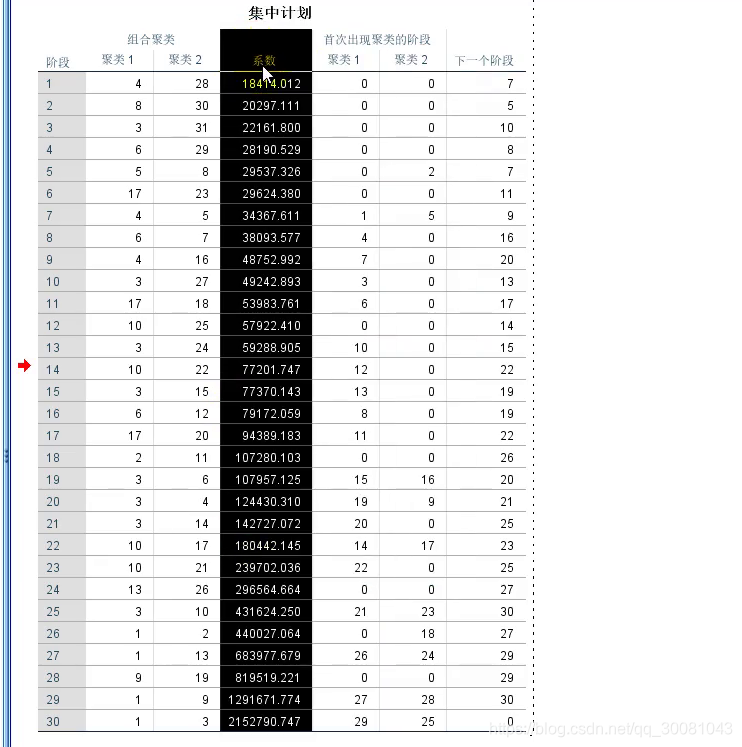
粘贴数据,复制到excel表,匹配目标格式。
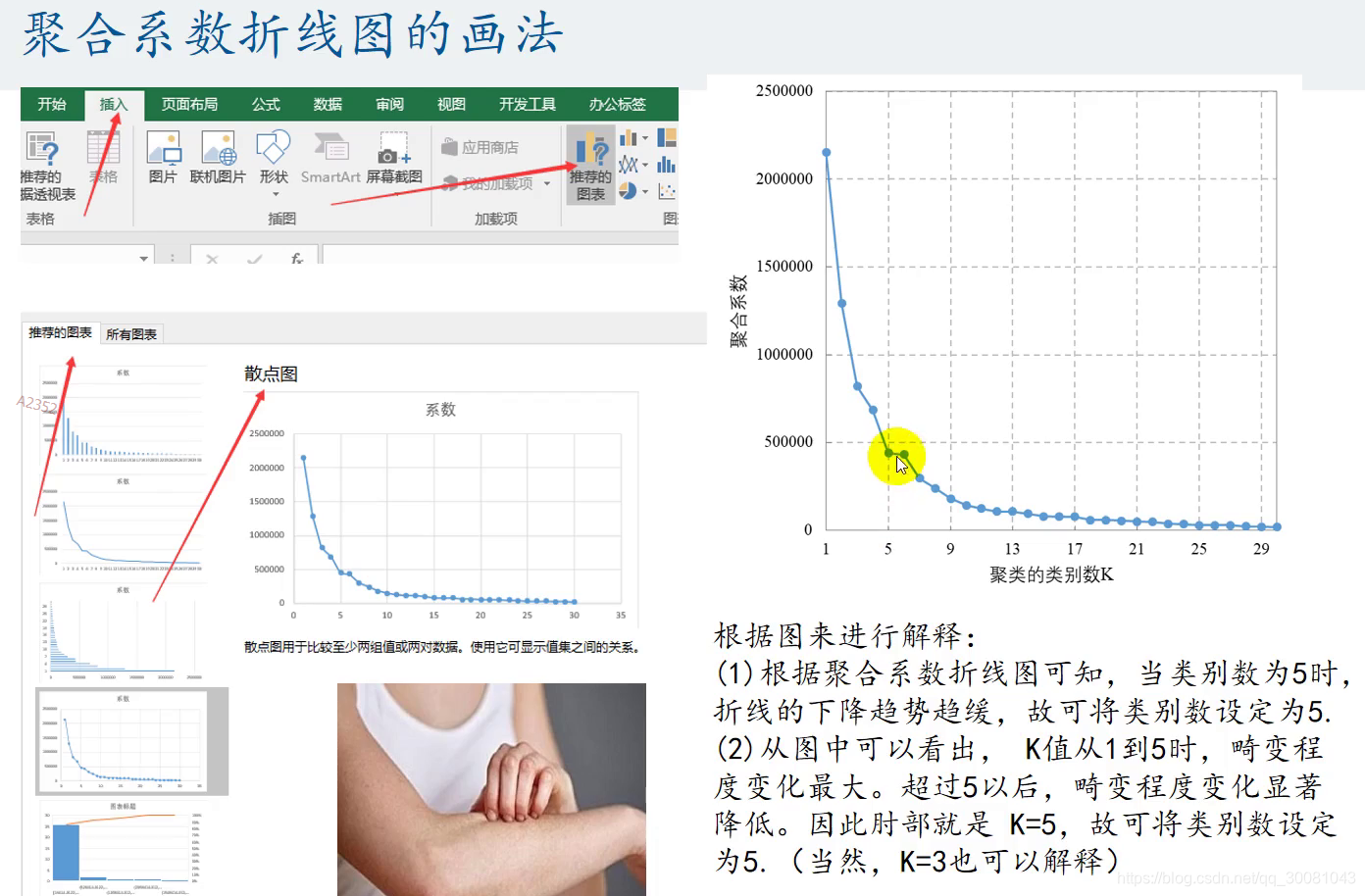
论文图表说明。辅助我们确定K。

示意图-作图
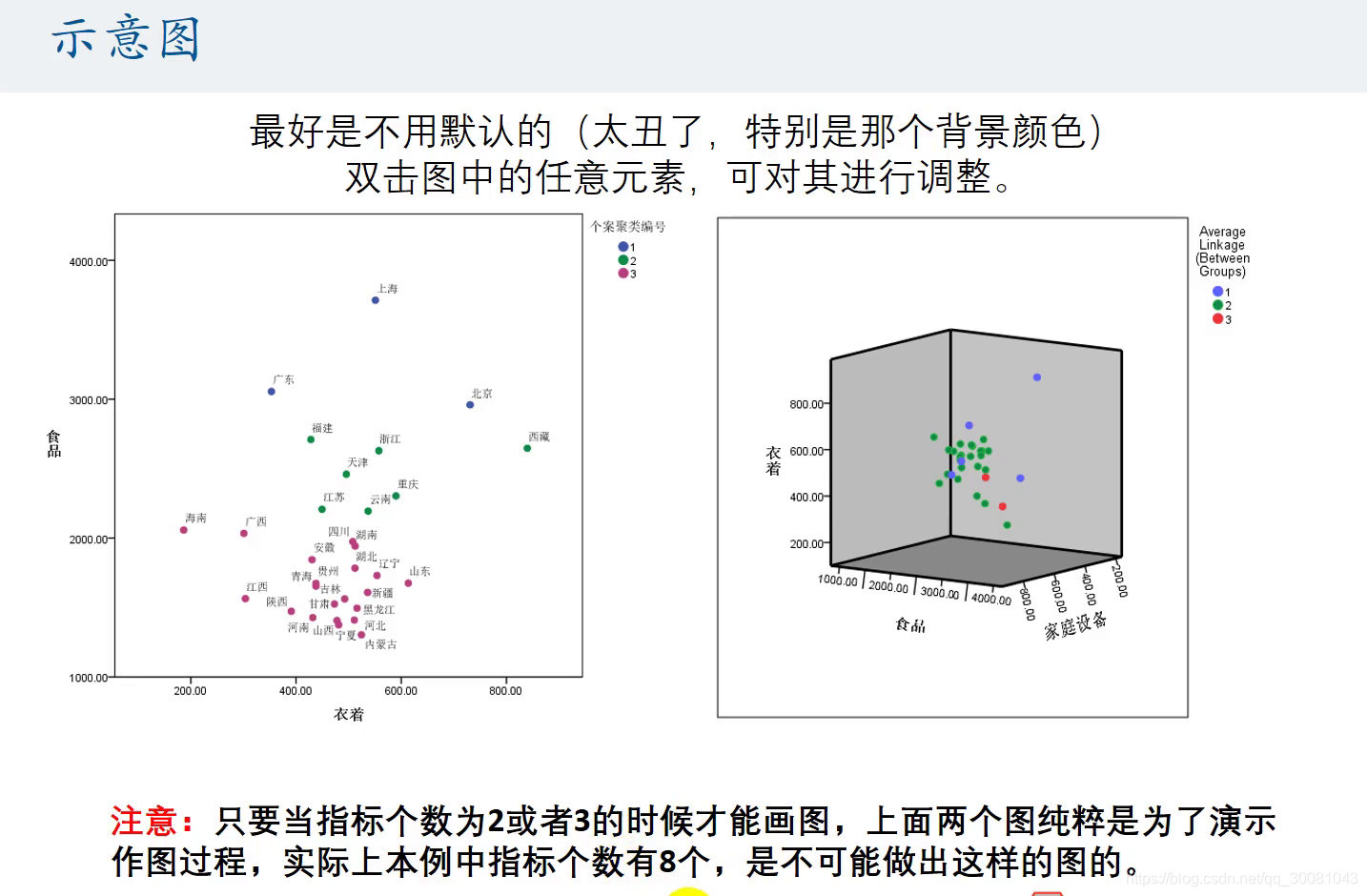
1.确定分类。分析-分类-系统聚类分析-保存-单个解,聚类数为3.分为三类。
2.图形-图标构造
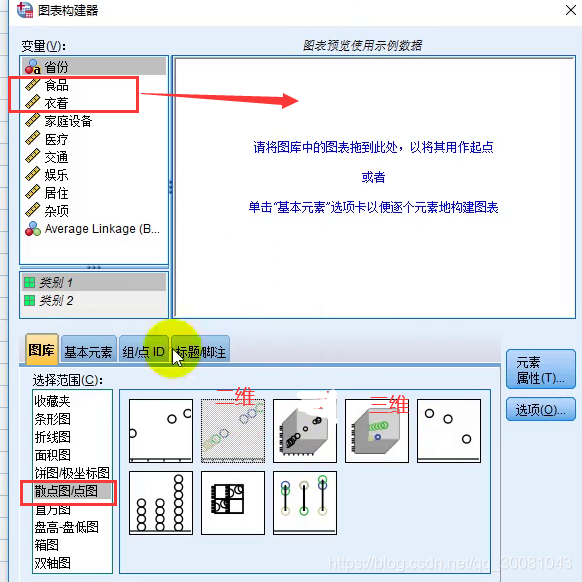
先拖图标类型,再拖变量!
然后根据聚类的结果来设置颜色。即分类。所以拖动average linkage。然后就会有颜色区分了
然后点击组/点ID,勾选 点ID标签。然后就会有省份的名字了
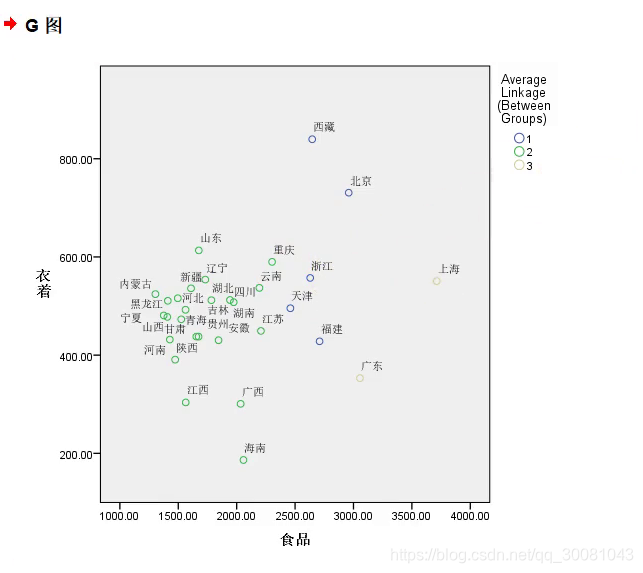
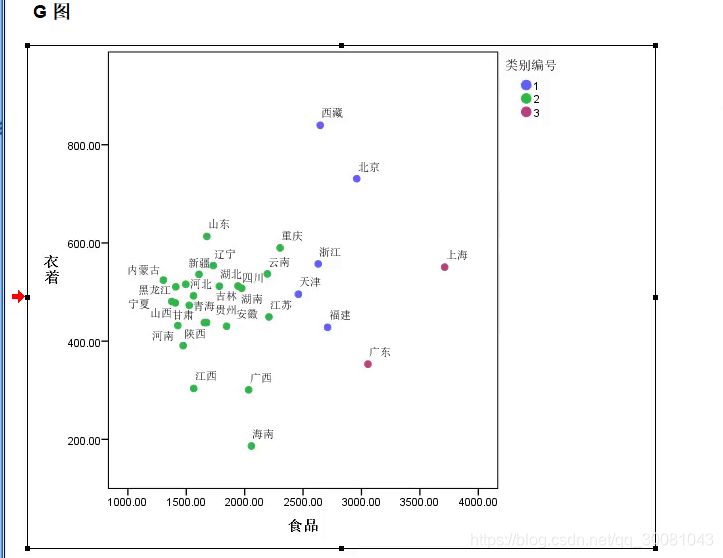
双击进去,可以对图进行修改。
点击点。可以对点进行填充。
双击背景,把背景设置为白色。
边框设置为黑色。
双击average linkage,修改文字为类别编号
第3部分_基于密度的聚类算法DBSCAN算法
之前额算法时基于距离来的。




DBSCAN算法–main.m

优缺点
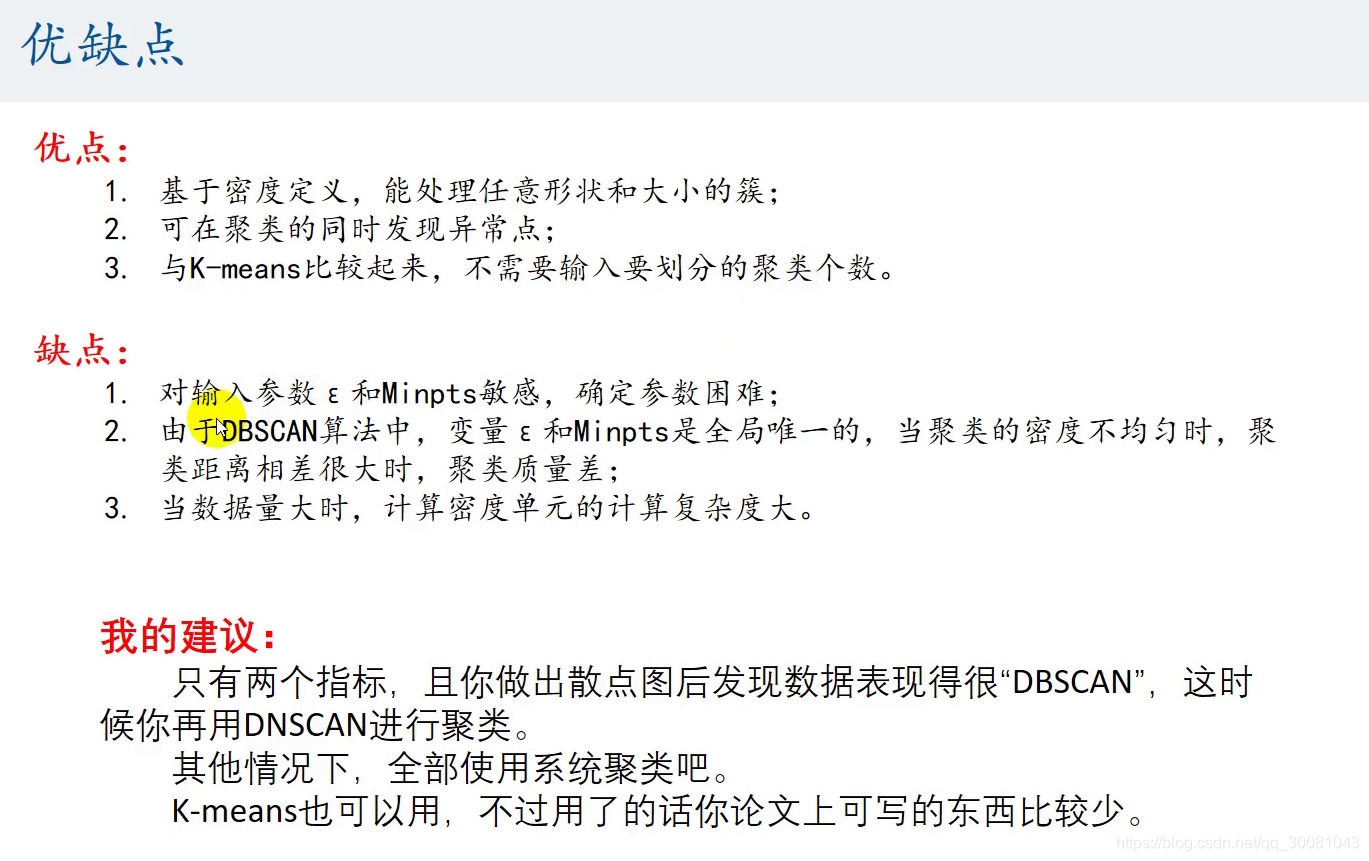
散点图很聚集,很DBSCAN,有形状,就用DNSCAN进行聚类。
其他情况都使用系统聚类。K-means也可以用,但是论文上可写的东西比较少。