目录
1.水果分类问题
根据水果的属性,判断该水果的种类。
mass: 水果重量width: 水果的宽度
height: 水果的高度
color_score: 水果的颜色数值,范围0‐1
fruit_name:水果类别
前19个样本是苹果 后19个样本是橙子 用这38个样本预测后四个样本对应的水果种类。
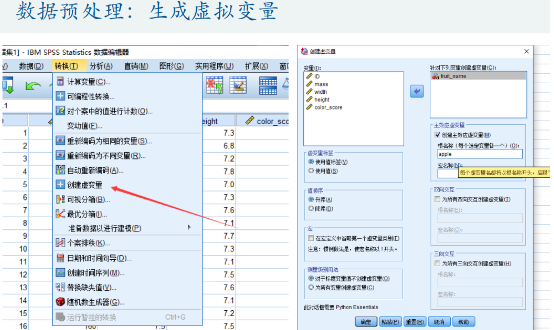
应用逻辑回归的操作,先进行数据预处理,生成虚拟变量。
2.逻辑回归(Logistic regression)

逻辑回归本质还是回归分析的一种,对于因变量为分类变量的情况,我们可以把y看成事件发生的概率,y ≥ 0.5 表示发生;y < 0.5 表示不发生
3.线性概率模型(LPM)
针对以上的思路可以用线性概率回归模型进行回归。

线性概率模型存在一定的问题:
问题1:
应用线性概率模型必然会讨论扰动项 ui 与其他自变量是否存相关,如果存在那么就会产生 内生性问题,即回归系数估计出来不一致且有偏。因为二分类估计出来的 y i 只能是 0 或者 1。因此扰动项可以转换成以下形式:
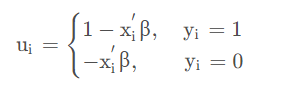
![]()
问题2:
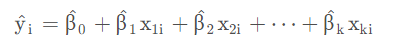
预测值可能会出现 y i>1 或者 y i<0,因为 yi 代表的是概率,因此这种预测值不现实。
两点分布对于线性模型的修正:
| 事件 | 1 | 0 |
|---|---|---|
| 概率 | p | 1-p |
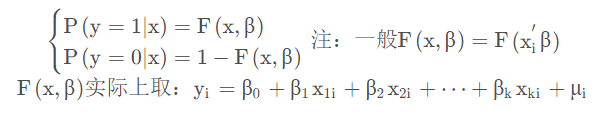
F ( x , β )成为连接函数,它将解释变量 x xx 与被解释变量 y yy 连接起来。那么需要保证 F (x , β )是定义在区间 [0, 1] 之间,即可保证: 0 ≤ y ^ ≤ 1。![]()
连接函数的两种取法:

由于后者有解析表达式(而标准正态分布的cdf没有),所以计算logistic模型比 probit模型更为方便。
f1=@(x) normcdf(x); % 标准正态分布的累积密度函数
fplot(f1, [-4,4]); % 在-4到4上画出函数f1的图形
hold on; % 不关闭作图窗口
grid on; % 显示网格线
f2=@(x) exp(x)/(1+exp(x)); % Sigmoid函数
fplot(f2, [-4,4]); % 在-4到4上画出函数f2的图形
legend('标准正态分布的cdf','sigmoid函数','location','SouthEast')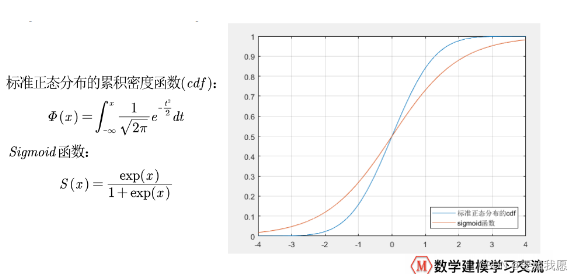
求解:
因为 Sigmoid 是一个非线性的模型,因此使用极大似然估计(MLE) 进行估计。

写成更加紧凑的形式:
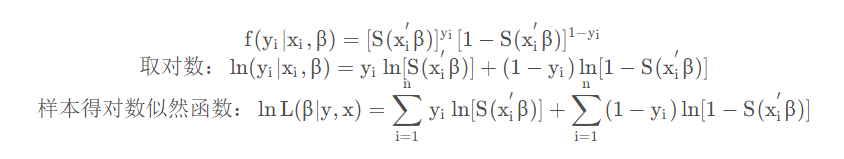
最终可以使用数值方法(梯度下降)求解这个非线性最大化的问题。
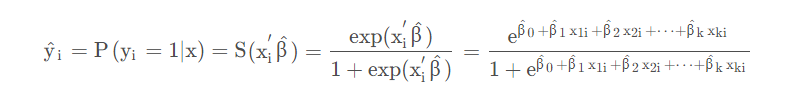
如果 y ≥0.5,则认为其预测的 y =1;否则则认为其预测的 y =0
4.Spss求逻辑回归
例:题目中给出了部分水果的相应属性与结果,根据已知水果的属性特征对未知水果进行分类。(题目截取了部分数据,实际数据苹果橙子各19条)
- mass: 水果重量
- width: 水果的宽度
- height: 水果的高度
- color_score: 水果的颜色数值,范围0‐1
- fruit_name:水果类别

数据预处理:定性变量转换成定量变量
定性变量就是取值不是数值,是指定字符串的。如:生病、未生病。那么对数据进行分析就要将定性变量转换成定量变量。转换的方法就是生成虚拟变量,这个虚拟值就代表着样本属性的一种状态。如:生病为1,未生病为0。
生成虚拟变量的方式有如下两种:
第一种:Spss生成虚拟变量
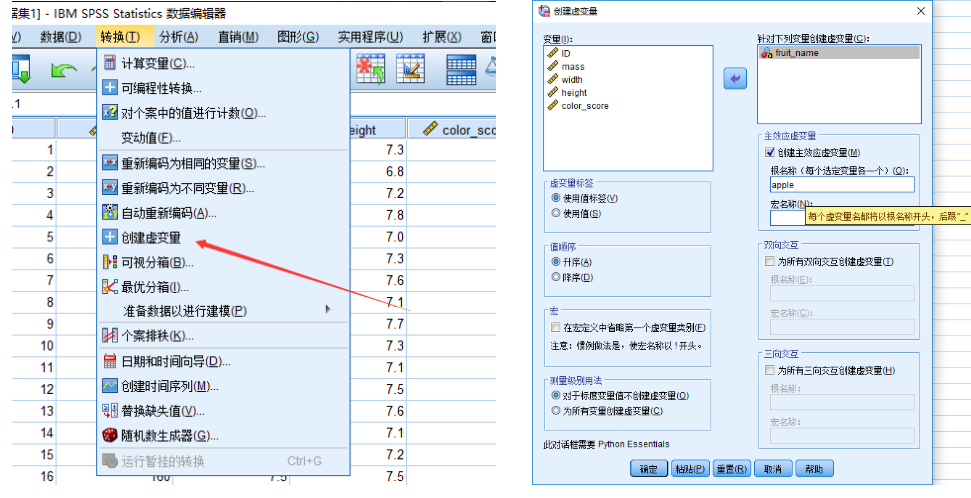
当然这会根据定性变量属性值的数量生成对应的列数,如:本题判断水果是苹果还是橙子,那么设置虚拟变量苹果为 1,橙子为 0,反过来也可以,因此 Spss 会生成两列数据,只需留一列就可以。
若 Spss 中没有可以去扩展中心扩展,如果扩展不了可以用第二种方法进行手动生成虚拟变量。
第二种:Excel生成虚拟变量
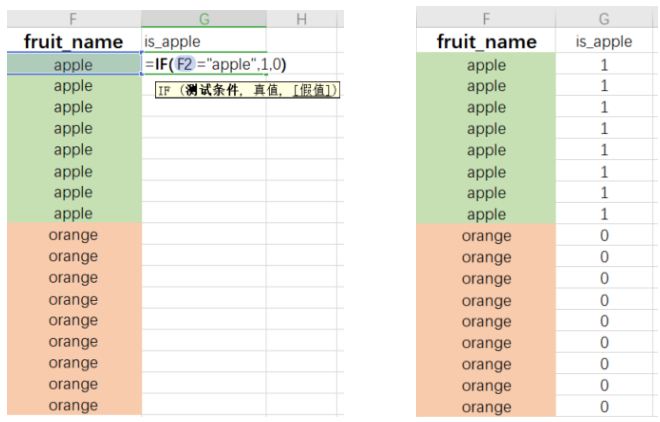
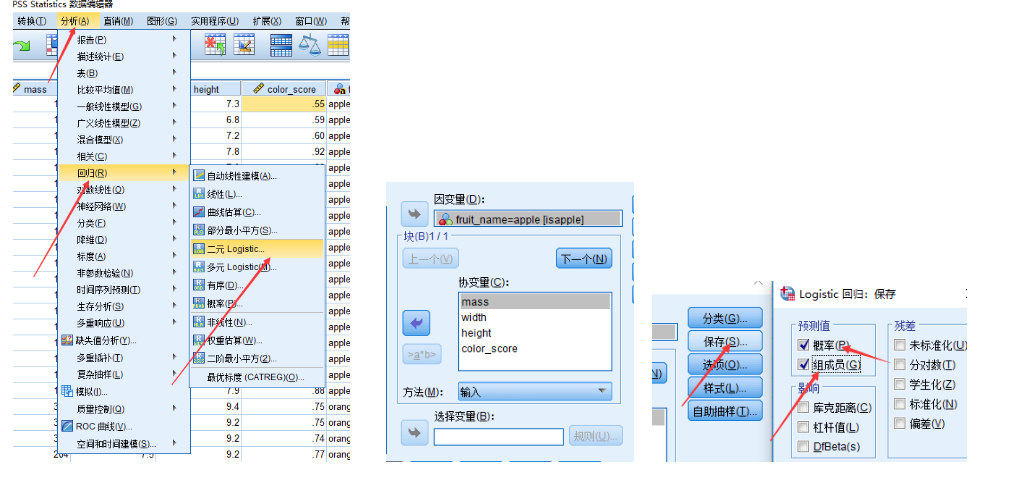
求解逻辑回归:
分析 => 回归 => 二元Logistic => 选择因变量与自变量(这里如果是定性变量,那么就需要选择对应的虚拟变量)=> 选择保存,并勾选概率与组成员
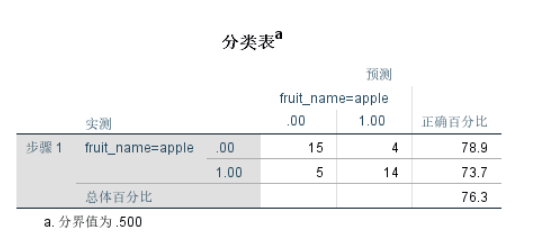
结果分析:
- 19个苹果样本中,预测出来为苹果的有14个,预测出来的正确率为73.7%;
- 19个橙子样本中,预测出来为橙子的有15个,预测出来的正确率为78.9%;
- 对于整个样本,逻辑回归的预测成功率为76.3%.
- B 代表着估计出来的相关系数,显著性实际对应着 P 值。
- 在 95% 的置信水平下,P值小于0.05的属性,就代表着该属性显著。
- 对显著性水平进行解释:对一个回归结果的好坏需要进行假设检验。设置联合显著性检验 H 0 : β 1 = β 2 = . . . = β k = 0
- 检验 k 个自变量的系数是否为 0。假如没有拒绝 H 0 即 P 值求出值>0.05,就是说无法拒绝H 0(95%的置信水平下这种假设存在概率超过5%),因此最终下结论,这个联合性检验无法拒绝原假设,此时回归无任何意义。当然这是评判整体回归的结果的标准,也可以设置90%的置信水平。如果要查看单个自变量的显著程度只需要查看显著性小于0.05即可(95%置信水平)。
- 从表中可以看出 width、height 在95%的置信水平下显著。如果是90%的置信水平显著变量还要添加 color_score。

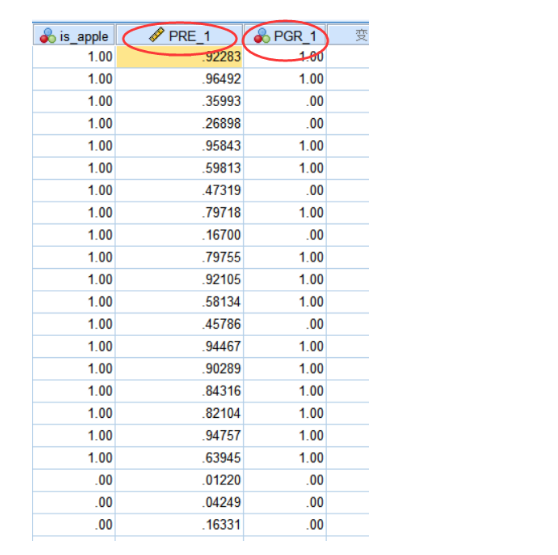
- 第一列代表的是 y ^即预测值,说明有多大的概率为苹果。
- 第二列代表的是回归的结果,1代表是苹果,0代表是橙子。当然这里 y^ 对应的概率分别是大于0.5,小于0.5。
5.Fisher线性判别分析
LDA(Linear Discriminant Analysis)是一种经典的线性判别方法,又称Fisher判别分析。该方法思想比较简单:给定训练集样例,设法将样例投影到一维的直线 上,使得同类样例的投影点尽可能接近和密集,异类投影点尽可能远离。
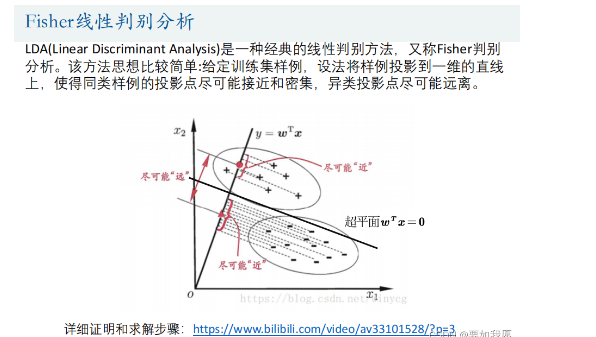
核心问题:找到线性系数向量w.

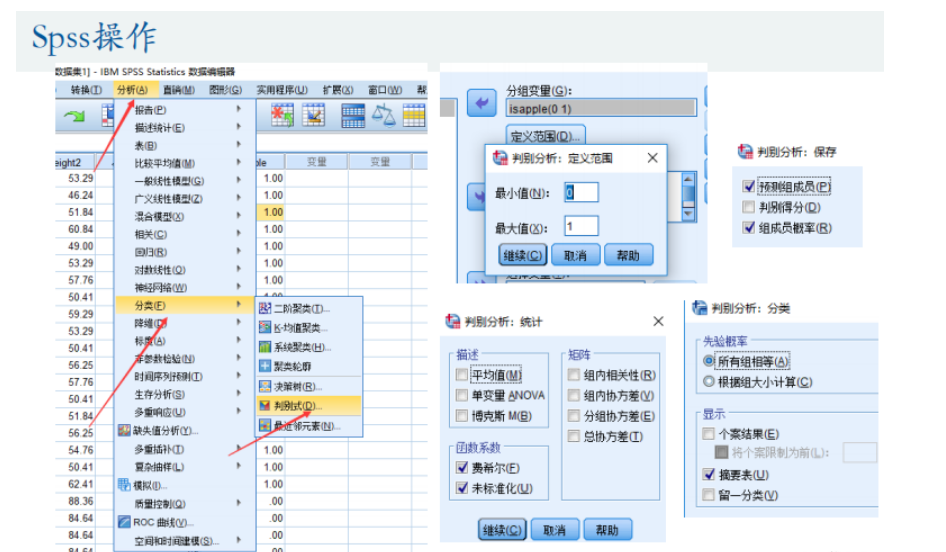
SPss操作
多分类问题:
现在水果种类有四种,指标平均值如下:
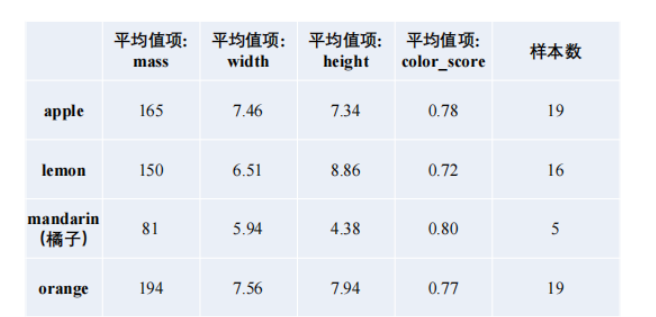
问题:如何对60-67的水果分类。
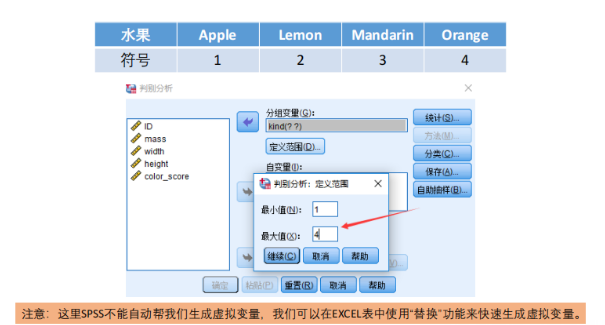
在SPSS中进行Fisher线性判别分析:
- 步骤:分析->分类->判别式->添加分组变量(y)->定义范围(种类)->添加自变量->统计(费希尔、未标准化)->分类(摘要表)->保存(预判组成员、组成员概率)
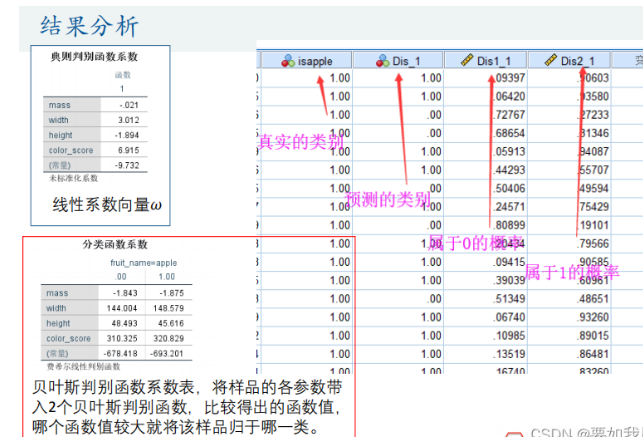
- 关注点:未标准化系数(线性系数ω)、分类结果

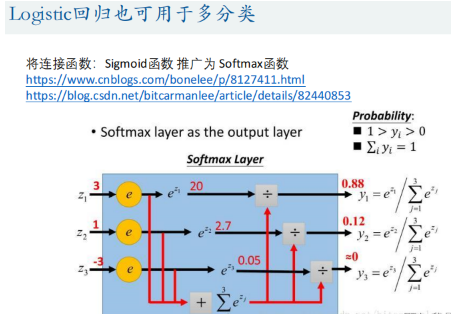
6.Logistic回归多分类
将连接函数:Sigmoid函数 推广为 Softmax函数
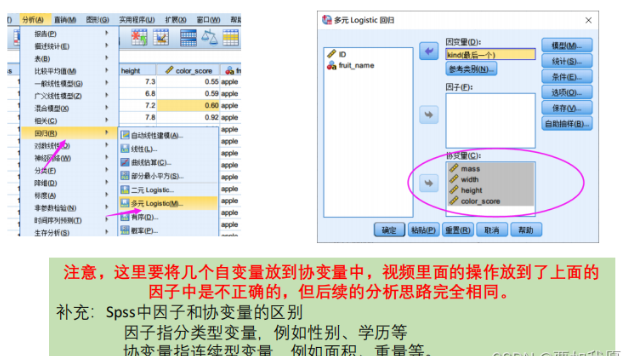
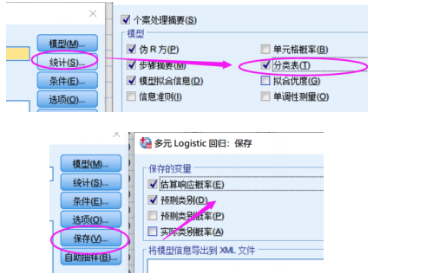
结果说明:
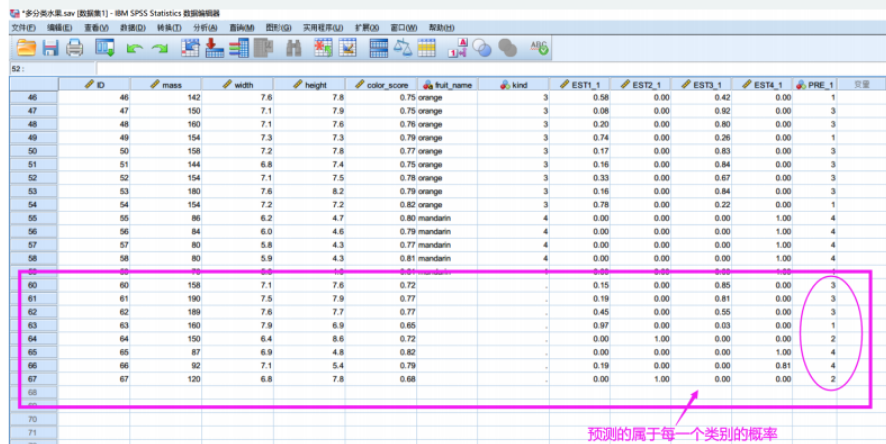
返回我们的数据列表,可以看到输出了属于每一类的概率,并且将概率最大的作为我们的预测结果。
7.课后作业

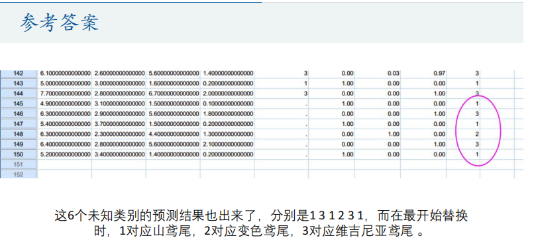
参考答案:
先进行定量处理:
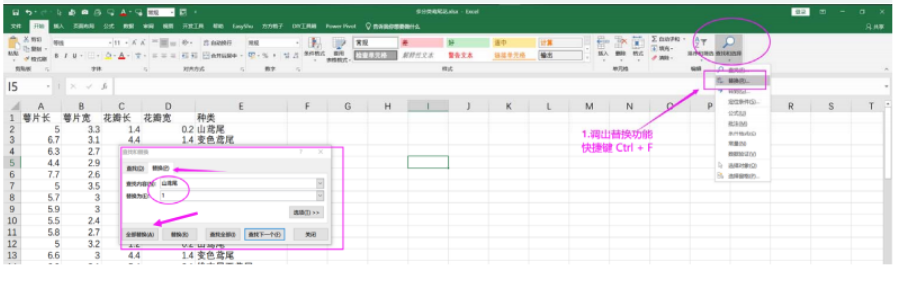
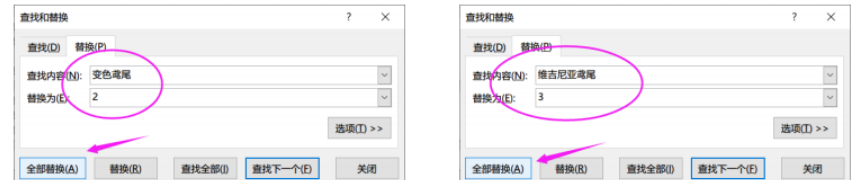

Spss中导入数据:
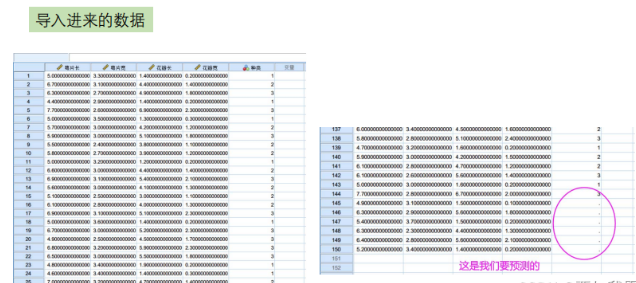
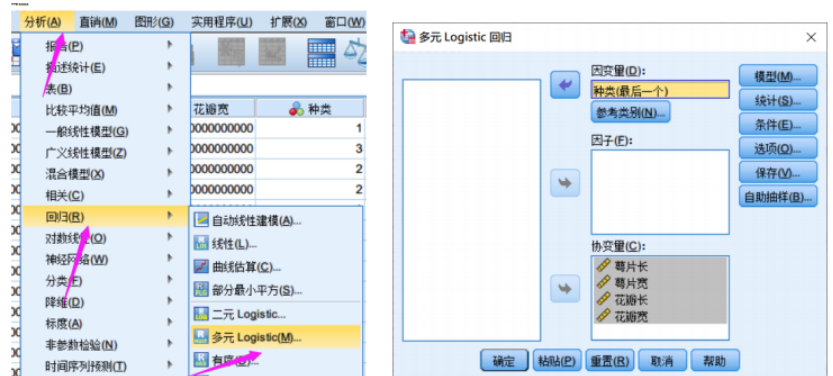
构建多元回归模型

查看预测结果: