参考博客:
word2vec原理(一) CBOW与Skip-Gram模型基础(写的非常棒)
CS224n学习笔记:Lecture1 & 2
1.怎样去表示word的含义
- (1)用分类资源来表示词义,如Wordnet
- 问题:需要很多的人力;无法对词语的相似性做出精确的定义
- (2) one hot:其他所有的表示方法均用了原子符号来表示,会使得词汇的表示非常的长
- 问题:没有天然的相似性,相似向量点积为0
- (3)
distribution similarity:可以通过观察一个词出现的上下文来表示某个词汇含义的值。使用上下文词语的含义来表示该词的含义。
- 怎样去定义向量
对于每个词使用一个密集型的向量(distribution representation)去表示它,让它可以预测目标单词所在文本的其他词汇
- 怎样去定义向量

2.什么是word2vec
定义一个模型,中心词汇预测它上下文的词汇,定义损失函数去评价预测的准确性、我们的目标是调整词汇表示,从而使损失最小化。
skip gram
- 每次都
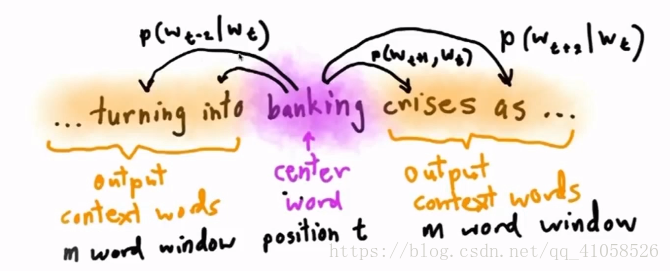
选择一个词作为中心词,尝试去预测它一定范围内的上下文的词汇。 故此模型为计算一个概率分布,即
给定一个中心词汇,某个单词在它上下文中出现的概率。我们会选择上下文的词汇,使得概率分布值最大化。此处的模型只有一个概率分布,并不是左右两边均有概率。足够大的文本,然后遍历文本中的所有位置,对于每个位置,取2m大小的窗口,即中心词前后各m个单词,这样就得到了一个概率分布,可以根据中心词汇给出其上下文词汇出现的概率。
- 此模型只关心
出现在window中的词,不关心它的位置,距离中心词的距离(这对于单词的意思而言已经够了) 具体公式推导:
-
为唯一的参数,最大化实际是解决对数分布问题,故取对数
- 加上归一化
- 把最大化转变为最小化,取负号
- 此即为我们的损失函数,这个负的损失函数其实就是
交叉熵损失函数 -
v为中心词,u为context,那么最简单的计算 的方法即为
- 因为我们只有one-hot,所以诀窍就是只预测一个当前的单词
点乘是一种粗略的相似度计算,相似性越大,点积越大- 转成softmax形式,得到概率分布,为了保证结果为正数,采用指数形式
- softmax有一个特性,那就是平移不变性(我也不知道专业的说法是这个),数学表示就是
softmax(x) = softmax(x + c),其中c为一个常数或常向量,x是一个向量。这个很好证。实际利用这个特性时,c普遍取-max x(i),就是x向量中的最大值。为啥要费劲减去这么个值呢?还要从softmax函数本身定义着手。 softmax函数用指数来进行”规范化“操作,指数操作会把大数继续放大,如exp(1000)时,直接算是会上溢出的,得到inf,对于exp(-1000),还是不行,会下溢出,得到0,下溢出这个事情是因为,浮点数只有64位,太小的数字也是表示不出来的。减去x(i)的最大值,可以保证指数最大不会超过0,不会发生上溢出,即使下溢出了,也能得到一个相对合理的值。这个softmax函数很重要很重要很重要!!!!! - 关于
:
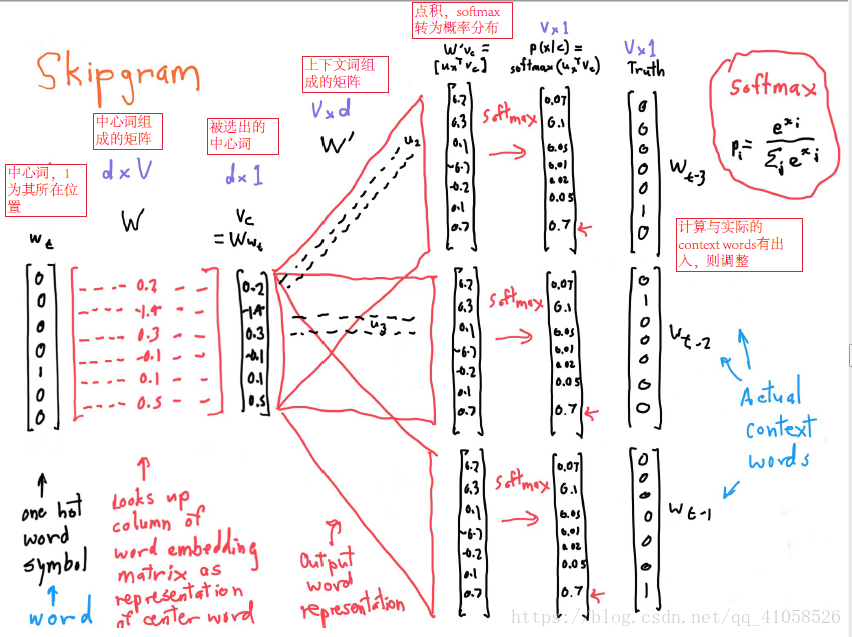
是一个 大小的向量,V是词典大小,它包含了所以模型的参数(除了窗口大小之类的超参),为了方便我们的理解,每个词都有两个向量表示,一个为中心词,一个为背景词。 - 对于整个SG模型的执行过程,用如下scratch表示很清楚:
- 最左边 的是用one-hot编码表示的中心词,是一个V维向量,V表示的是词典的大小(输入其实是一个pair,每一个pair为(中心词,context词1)),乘以W矩阵,该矩阵为d行V列矩阵,每列表示一个词向量,这个词向量用d维列向量表示,这个操作其实就是一个映射table,揪出对应的词向量。
再将该向量与W’矩阵相乘,对得到的结果再进行softmax转换得到概率,经过softmax转换过得列向量中的值加和为1,值最大的那个对应的就是预测出来的该中心词在窗口中该位应该出现的词,与真实情况进行对比来计算损失,然后反过来更新W和W’矩阵。?????最终的词向量就是W矩阵,这个不清楚。
对于模型的训练,用梯度下降法。模型的参数就是W和W’矩阵。求导即可得到梯度,使用SGD而非BGD来减少训练时间,这些都是老生常谈了。比较特别的一点是提到了一句,NN喜欢嘈杂的算法。?????这个是为什么,需要仔细思考一下
至此得到SG模型训练的整体流程,针对softmax函数,还有优化的空间,后边会提到一些trick,这个不是lecture1 中主要提到的问题了,后边再继续总结。