预感lecture2会学很久,不会的东西太多了,emmm………..
课程大纲
1. 词义
2. Word2vec介绍
3. 突出的研究
4. Word2vec目标函数梯度
5. 优化复习
1. 词义
1.1 计算机如何处理词语的意思
过去几个世纪里一直用的是分类词典。计算语言学中常见的方式是WordNet那样的词库。比如NLTK中可以通过WordNet查询熊猫的hypernyms (is-a,上位词),得到“食肉动物”“动物”之类的上位词。也可以查询“good”的同义词——“just品格好”“ripe熟了”。
这种离散表示存在的问题
- 作为一种资源很好但缺少细微差别,例如,同义词:adept,expert,good,practiced, proficient, skillful?
- 缺少新词(不可能保持最新):wicked,badass,nifty,crack,ace,wizard, genius,ninja
- 主观
- 需要人工来创造和适应
- 难以计算准确的单词相似度
1.2 one-hot representation
绝大多数基于规则和统计的NLP工作都将单词视为原子符号:hotel,conference,walk
在向量空间术语中,这是一个带有1和大量零的向量[0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
维度:20K(语音)-50K(PTB)-500K(大词汇)-13M(谷歌1T)
我们称之为词的one-hot representation
词语在符号表示上体现不出意义的相似性,比如Dell notebook battery size和Dell laptop battery capacity。而one-hot向量是正交的,无法通过任何运算得到相似度。

one-hot representation相当于给每个词分配一个id,这就导致这种表示方式不能展示词与词之间的关系。另外,one-hot representation将会导致特征空间非常大,但也带来一个好处,就是在高维空间中,很多应用任务线性可分。
1.3 Distributed Representation
通过调整一个单词及其上下文单词的向量,使得根据两个向量可以推测两个词语的相似度;或根据向量可以预测词语的上下文。这种手法也是递归的,根据向量来调整向量,与词典中意项的定义相似。
word embedding指的是将词转化成一种分布式表示,又称词向量。分布
式表示将词表示成一个定长的连续的稠密向量。

分布式表示优点:
(1)词之间存在相似关系:
是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2)包含更多信息:
词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
学习神经网络词嵌入的基本思想
我们定义了一个模型,旨在根据单词向量预测中心单词w
的上下文单词
p(context | w
) =…
它有一个损失函数:J=1−p(w
| w
)
这里的w
表示w
的上下文(负号通常表示除了某某之外),如果完美预测,损失函数为零。然后在一个大型语料库中的不同位置得到训练实例,调整词向量,最小化损失函数。
2. word2vec的主要思路
通过单词和上下文彼此预测。
两个算法:
- Skip-grams (SG):给定input word来预测上下文
- Continuous Bag of Words (CBOW):给定上下文,来预测input word
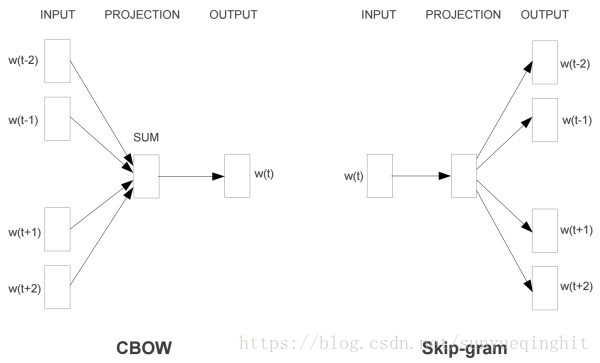
两种稍微高效一些的训练方法:
- Hierarchical softmax
- Negative sampling
为了降低复杂度,Word2Vec使用了Hierarchical Softmax和Negative
Sampling两种求解策略。普遍认为Hierarchical Softmax对低频词效果较好;Negative
Sampling对高频词效果较好,向量维度较低时效果更好。
2.1 Continuous Bag of Words (CBOW)
2.1.1单个词的上下文
我们假设每个上下文只考虑一个单词,这意味着模型将在给定一个上下文单词的情况下预测一个目标单词,这就像一个二元模型。
下图显示了简化上下文定义下的网络模型。
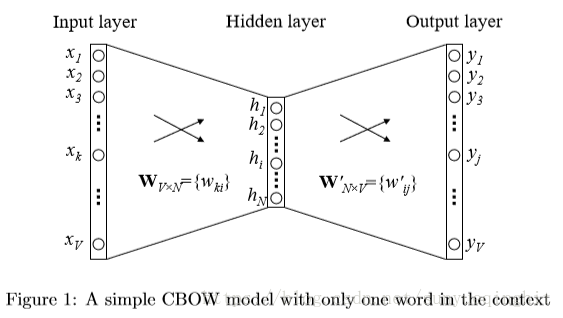
在我们的设置中,词汇量大小为V,隐藏层大小为N。相邻层上的单元完全连接。 输入是one-hot编码向量,这意味着对于给定的输入上下文字,{x1,…,xV}只有一个为1,而所有其他为0。
输入层和输出层之间的权重可以由V×N矩阵W表示。W的每一行是输入层的相关字的N维矢量表示v
。 形式上,W的第i行是v
。 给定一个上下文(一个单词),假设x
= 1而对任意k’
k ,x
= 0,我们有
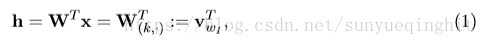
W 是NxV,x是Vx1,所以h是Nx1
这本质上是将W的第k行复制到h。v
是输入字w
的向量表示。 这意味着隐藏层的链接(激活)函数是简单线性的(即直接将其加权的输入和传递到下一层)。
从隐藏层到输出层,存在不同的权重矩阵W‘ = {w’
},它是N×V矩阵。 使用这些权重,我们可以计算词汇表中每个单词的分数u
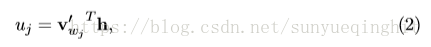
其中v’
是矩阵W’的第j列
v’ 是Nx1,v’ 是1xN,h是Nx1,所以u 是1x1
然后我们可以使用对数线性分类模型softmax来获得单词的后验分布,这是一个多项分布。
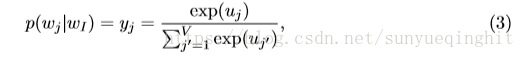
其中y
是输出层中第j个单元的输出.
把(1)和(2)带入3得:
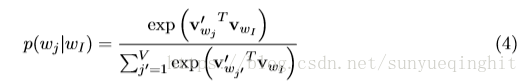
注意,v
和v’
是单词w的两个表示。v
来自矩阵W的行,即输入→隐藏权重矩阵,v’
来自矩阵W’的列,即隐藏→输出矩阵。我们将v
称为“输入向量”,并将v’
称为单词w的“输出向量”。
更新隐藏→输出权重的等式
训练目标(对于一个训练样本)是在给定关于权重的输入上下文字w
的情况下最大化(4),观察实际输出字w
(在输出层中将其下标表示为j *)的条件概率。
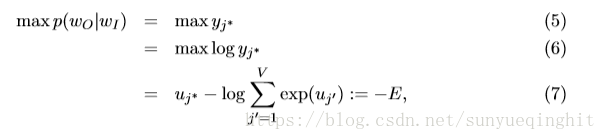
这里E=-log p(w
|w
)是损失函数(我们想要最小化E).j *是输出层中实际输出字的索引。注意,该损失函数可以被理解为两个概率分布之间的交叉熵测量的特殊情况。
现在我们推导出隐藏层和输出层之间权重的更新方程。我们得到了关于第j个单位的净输入u
的E的导数
其中t
= 1(j = j *),即,当第j个单位是实际输出字时,t
将仅为1,否则t
= 0.注意,该导数仅仅是输出层的预测误差ej。
接下来,我们在w’
上得到导数,以获得隐藏→输出权重的梯度。
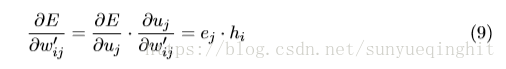
因此,使用随机梯度下降,我们得到隐藏→输出权重的权重更新方程:
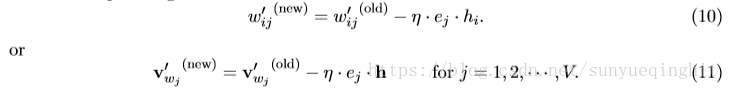
其中η> 0是学习率,e
= y
-t
,h
是隐藏层中的第i个单位; v’
是w
的输出向量。 注意,此更新等式意味着我们必须遍历词汇表中的每个可能的单词,检查其输出概率y
,并将y
与其预期输出t
(0或1)进行比较。
- 如果y > t (“过高估计”),则我们从v’ 中减去隐藏向量h(即v )的一部分,从而使v’ 远离v
- 如果y < t (“低估”,仅当t = 1时才为真,即w = w ),我们向v’ 添加一些h,从而使v’ 更接近v 。
- 如果y 非常接近t ,那么根据更新方程,将对权重进行非常小的改变。
更新输入→隐藏权重的等式
获得W’的更新方程后,我们现在可以转到W.我们在隐藏层的输出上取E的导数,得
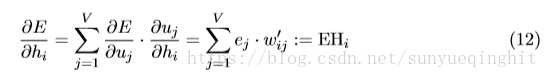
其中h
是隐藏层的第i个单元的输出; u
在(2)中定义,输出层中第j个单元的净输入; 并且e
= y
-t
是输出层中第j个字的预测误差。 EH是一个N-dim向量,是词汇表中所有单词的输出向量的总和,由它们的预测误差加权。
接下来我们应该在W上取E的导数。首先,回想一下隐藏层对输入层的值进行线性计算。 扩展(1)中的向量符号我们得到

现在我们可以得到关于W的每个元素的E的导数:
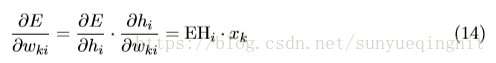
这相当于x和EH的张量积,即

从中我们获得V×N矩阵。 由于x的仅一个分量是非零的,因此只有一行∂E/∂W是非零的,并且该行的值是EH
,即N维向量。 我们得到W的更新方程为:
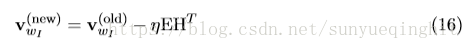
其中v
是W的一行,是唯一上下文字的“输入向量”,并且是W的唯一行,其导数是非零的。 在此迭代之后,W的所有其他行将保持不变,因为它们的导数为零。
2.1.2 多字的上下文
下图显示了具有多字上下文设置的CBOW模型。
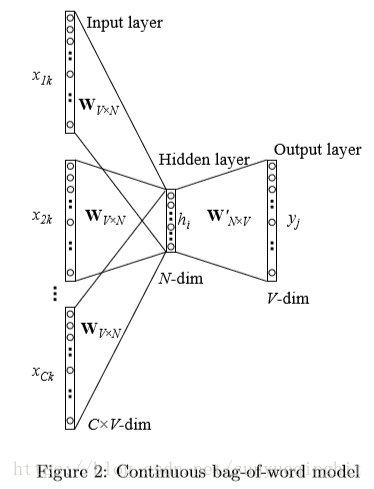
在计算隐藏层输出时,CBOW模型不是直接复制输入上下文字的输入向量,而是取输入上下文字的向量的平均值,并使用输入→隐藏权重矩阵和平均向量的乘积作为输出。
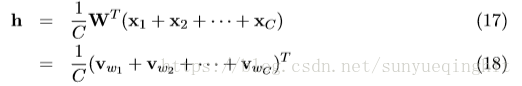
其中C是上下文中的单词数,w
,…,w
是上下文中的单词,v
是单词w的输入向量。 损失函数是
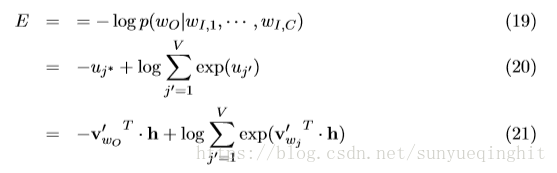
这与单字上下文模型的目标相同,除了h是不同的,如(18)中的定义而不是(1)。
隐藏→输出权重的更新等式保持与单字上下文模型(11)的更新等式相同
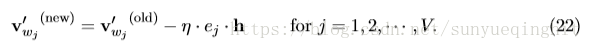
注意,我们需要将此应用于每个训练实例的隐藏→输出权重矩阵的每个元素。
输入→隐藏权重的更新方程类似于(16),除了现在我们需要对上下文中的每个单词w
应用以下等式:

2.2 Skip-gram prediction
skip-gram模型的输入是一个单词w
,它的输出是w
的上下文w
,…,w
,上下文的窗口大小为C。举个例子,这里有个句子“I drive my car to the store”。我们如果把”car”作为训练输入数据,单词组{“I”, “drive”, “my”, “to”, “the”, “store”}就是输出。所有这些单词,我们会进行one-hot编码。
skip-gram模型图如下所示:
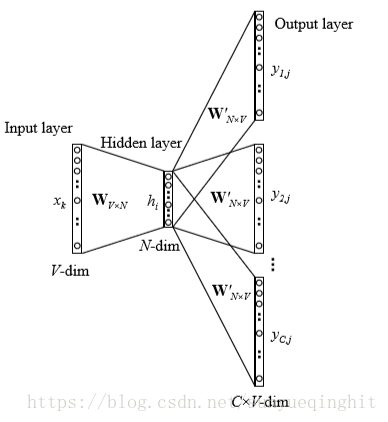
明天再补,去备托福了……………
参考:
[1] http://www.hankcs.com/nlp/word-vector-representations-word2vec.html
[2] https://blog.csdn.net/qwe11002698_ling/article/details/53888284
[3] https://www.leiphone.com/news/201706/PamWKpfRFEI42McI.html
[4] http://qiancy.com/2016/08/17/word2vec-hierarchical-softmax/
[5] https://blog.csdn.net/u010665216/article/details/78721354