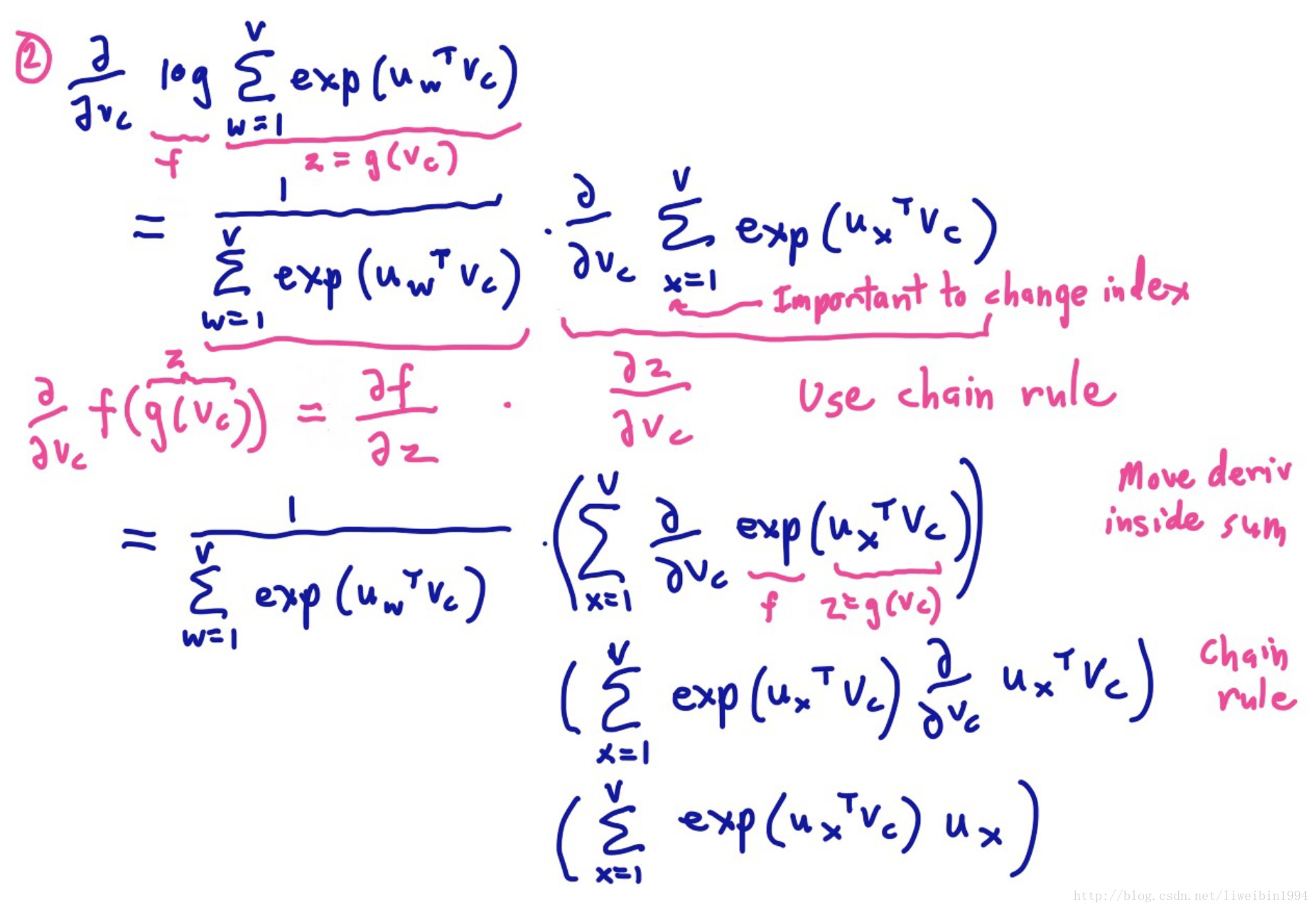版权声明:本文为博主原创文章,未经许可,请勿转载 https://blog.csdn.net/liweibin1994/article/details/78154336
最近刚刚开始看斯坦福CS224n系列视频,主要讲的是自然语言处理与深度学习的结合。笔者怕自己看完视频就忘了,因此想记录下学习过程中的笔记。当然笔者发现了网上已经有人也发了一些CS224n的学习笔记。笔者主要学习了视频和参考了这篇笔记,再加上一些自己觉得难懂的地方的理解。笔者也是刚刚入门,水平有限,如有错漏,还望指出。
如何在电脑中表示一个词的意义?
用电脑表示一个词的问题

词向量的主要思路
- 通过单词和单词的上下文预测彼此。
- 两个算法:
- Skip-gram:通过目标单词来预测它的上下文
- Continuous Bag of Words(CBOW):通过上下文预测目标单词
- 两种训练方法:
- Hierarchical softmax
- Negative sampling
Skip-gram模型
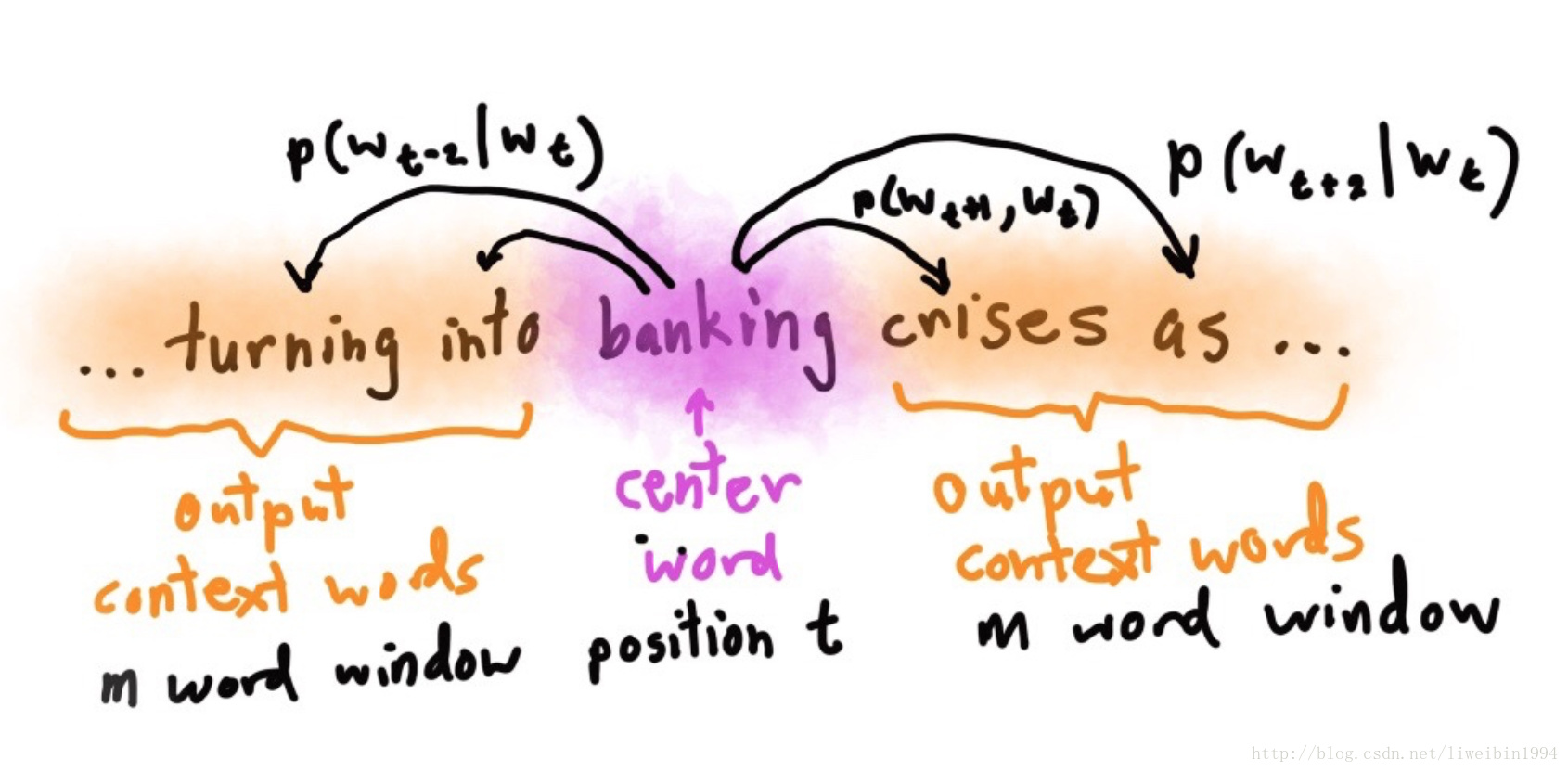
- 上图的意思就是在已知banking的情况下,预测turning,into,cnises,as的概率,即:
。所以我们的目标函数就是:
- 我们要的是让概率最大化,也就是最大化这个目标函数,但是这里是连乘的形式,一般我们会取负对数,让乘法变成加法,让最大化变最小化。即:
这个条件概率要怎么表示。
预测某个上下文条件概率 可以由softmax来计算:
首先,公式中的u和v都是词向量,所以 是向量内积,如果两个词向量比较接近,他们的内积会比较大。V是整个词典词的个数,所以其实分母部分就是所有词的词向量与目标词向量(即上面图中的示例banking的词向量)的内积之和。而使用指数是为了将实数(有负有正)映射成整数,然后分母部分是为了归一化变成概率。
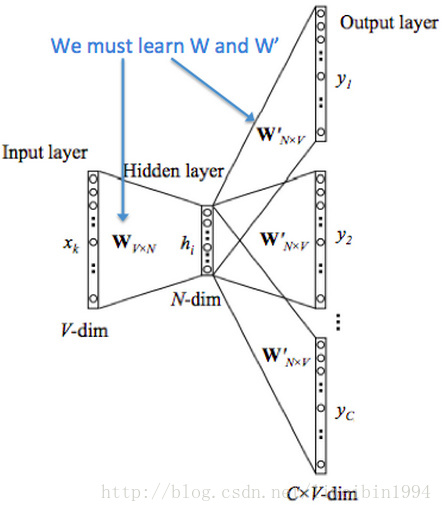
skip-gram

- 上图很清晰地展示了skip-gram模型的整个流程。
- 最左边是当前词的one-hot向量( )。
- 第二个矩阵W(图中W矩阵是dxV,实际应该是Vxd,下同),矩阵的每一列其实就是一个词的分布式词向量。V是词典的词的个数,所以这个矩阵包含了词库中每个词的词向量。
- 的one-hot向量与W相乘得到 ,也就是相当于从W矩阵中提取了词 的词向量。
- W矩阵包含了所有词的词向量,所以第三步是 与W矩阵的转置相乘,其实就是让 与词库中的所有词的词向量作内积。
- 得到内积之后,利用softmax将内积的结果映射成概率,就可以得到在 的条件下,上下文中出现最大概率的词是哪一个,然后和标签(就是上图中最后一行)对比,接下来可以得到loss函数。然后利用梯度下降来更新W矩阵,让它的结果更接近标签的结果。
- 官方笔记有非手写版的图:
- 这个图的W矩阵的行与列才是对的。
训练模型:计算参数向量的梯度
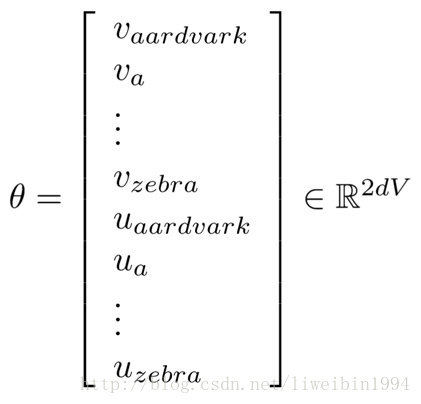
- 我们的目标是训练出矩阵W,所以我们把所有参数写进向量
:
- 其中,每一行都是一个词向量, 是当词作为center word的时候的词向量, 是当词作为上下文的时候的词向量,所以有2V个。
梯度下降的具体推导如下:
导数的后一项刚好就是均值(期望)。p为概率,乘以u。然后加和,不就是均值的定义吗?计算出了梯度之后,就可以更新参数 了。即: