课程介绍
这门课主要学习什么
- An understanding of the effective modern methods for deep learning
- A big picture understanding of human languages and the difficulties in understanding and producing them
- An understanding of and ability to build systems (in PyTorch) for some of the major problems in NLP:
- Word meaning, dependency parsing, machine translation, question answering
2019Winter与之前的课程有什么区别
- 新材料:character models,transformers, safety/fairness,multitask learn
- 实验:由之前的3个两周的实验改为5个一周的实验(占比6% + 4 x 12%)
- 实验中包含新材料:NMT with attention, ConvNets, subword modeling
- 由tensorflow改用Pytorch
五个实验的介绍
- HW1 is hopefully an easy on ramp –an IPythonNotebook
- HW2 is pure Python (numpy) but expects you to do (multivariate) calculus so you really understand the basics
- HW3 introduces PyTorch
- HW4 and HW5 use PyTorchon a GPU (Microsoft Azure)
- Libraries like PyTorch, Tensorflow(and Chainer, MXNet, CNTK, Keras, etc.) are becoming the standard tools of DL
- For FP, you either
- Do the default project, which is SQuADquestion answering
- Open-ended but an easier start; a good choice for most
- Propose a custom final project, which we approve
- You will receive feedback from a mentor(TA/prof/postdoc/PhD)
- Can work in teams of 1–3; can use any language
- Do the default project, which is SQuADquestion answering
lecture 1
如何表示一个单词的含义(meaning of a word)
- 建立所有同义词synonym和下义词hypernym(即“is a"的关系)的词库
- wordnet
- one-hot的向量
- word2vec
- Skip-Gram model
- CBOW
WordNet
- 作为一种资源很好,但缺少细微差别
- 缺少词的新义,不能保持更新
- 主观
- 需要人工
- 不能计算词的相似性
one-hot
- 任何两个词向量都是正交的,无法表示相似性
- 解决:结合WordNet中的同义词,结果失败了。由于不完整等原因
使用上下文(context)来表示词
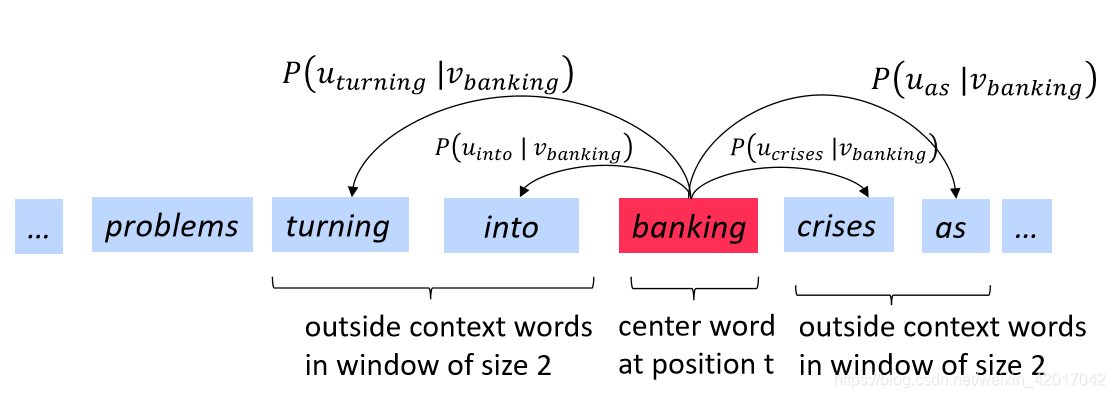
- Distributional semantics: A word’s meaning is given by the words that frequently appear close-by
- 一个词出现在文章中,固定一个window,其上下文指周围出现的词构成的集合
- 使用词w的很多context可以来构造w的表示
Word2vec (Mikolovet al. 2013)
- o为contex words,c为center words
- 使用o和c的词向量来计算 或
- 调整词向量来最大化该概率
- 目标函数,如下图,最小化代价函数就是最大化预测正确的概率
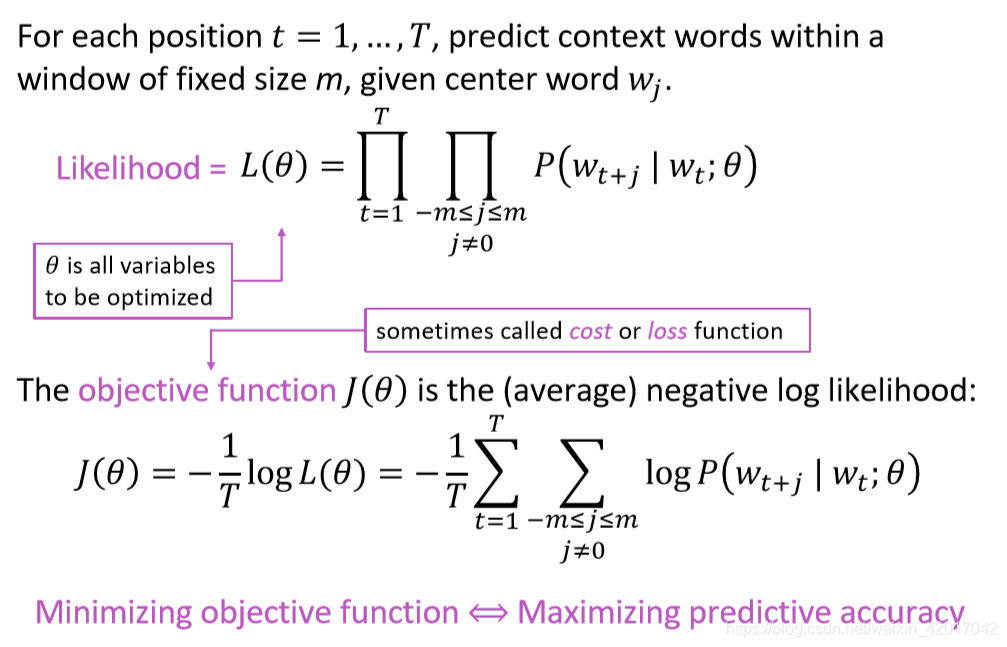
- 计算
- 使用两个向量来表示每个词
- :w是center word
- :w是context word
- 计算
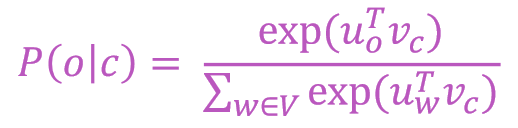
- 上式中使用了softmax,其作用为:
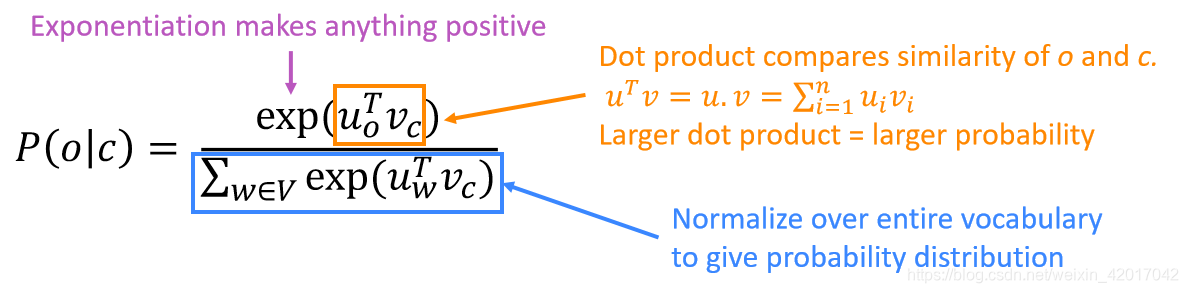
- 使用两个向量来表示每个词
模型的训练
-
代表模型所有参数,即所有词的词向量(每个词有两个词向量)
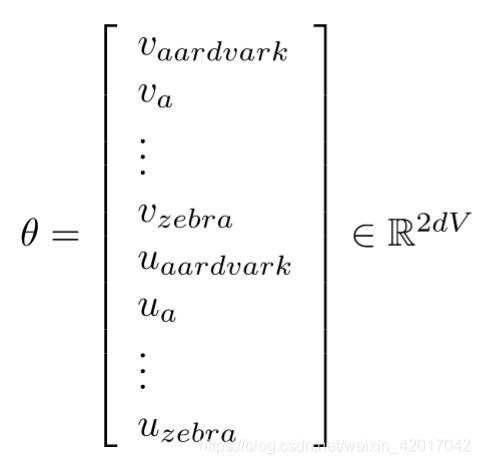
如何计算词向量的梯度
- 一个基础
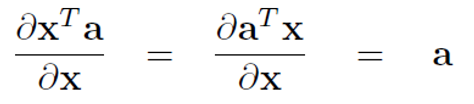
- 链导法则
对于一个window中的一个context word计算代价函数关于 的梯度
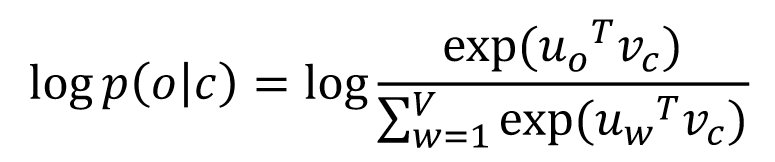
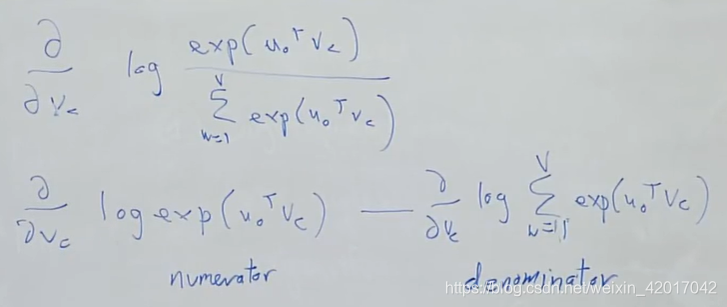
分子求导比较容易,log和exp抵消后,形式就和我们之前所说的一样
分母需要两次链导法则,中间有一步将求导和求和调换顺序:

最终结果为


当前中心词的梯度相当于当前context word o的词向量减去所有context 词向量的期望或者说加权平均值(概率*词向量)
- 如何计算所有的梯度
- 在一个window中需要遍历计算每一个center vector v的梯度,同时也要计算context u的梯度
- 在一个window中需要计算如下参数
为何需要两个向量
容易优化,最后取平均即可
使用一个词向量也可以
两种模型
- Skip-grams(SG):给定中心词预测context words
- Continuous Bag of Words(CBOW):给定context words预测中心词
优化:梯度下降
Gradient Descent is an algorithm to minimize
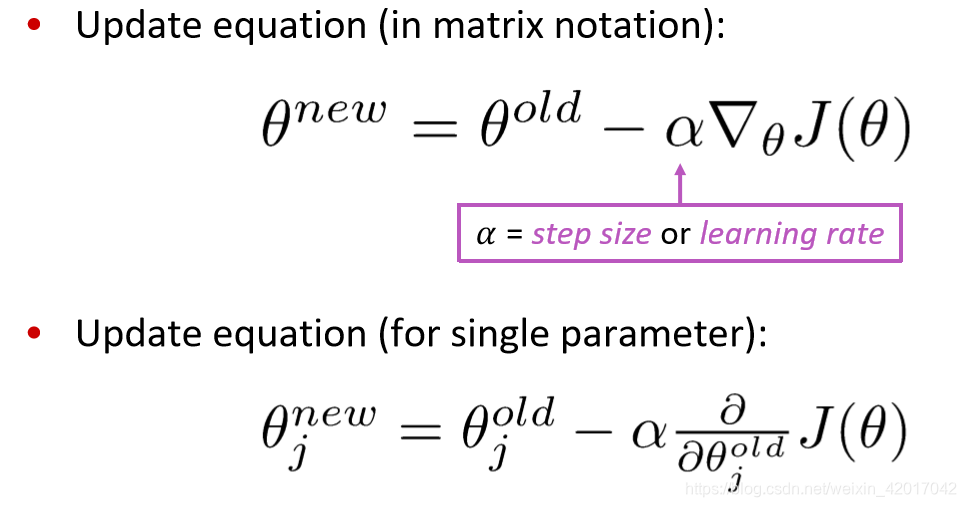

随机梯度下降 (SGD):随机选择一个window来更新词向量

总结
本节课主要讲了词的表示,中心想法是使用一个词的context来表示词,这即是word2vec的思想。word2vec有两种模型,skip-gram是根据中心词预测上下文(本文就是这种,但去掉了负采样),CBOW是根据周围词预测中心词。
