版权声明:本文为博主原创文章,未经许可,请勿转载 https://blog.csdn.net/liweibin1994/article/details/78232300
词向量模型
语言学家J. R. Firth提出,通过一个单词的上下文可以得到它的意思,所以我们可以定义一个以预测某个单词的上下文的模型:
p(context|wt)= ... 我们的目标当然是希望概率p越大越好,所以我们可以定义一个目标函数:
J′(θ)=∏t=1T∏−m≤j≤m, j≠0P(wt+j|wt;θ) 我们的目的就是最大化上面这个目标函数。但一般来说,我们都是想最小化目标函数的,所以我们可以改写目标函数为:
J(θ)=−1T∑t=1T∑−m≤j≤m,j≠0log P(wt+j|wt;θ) 所以我们接下来的目标就是如何计算
P(wt+j|wt;θ) ,或者说如何定义P(wt+j|wt;θ) 。
定义
P(wt+j|wt;θ)
- 其中,
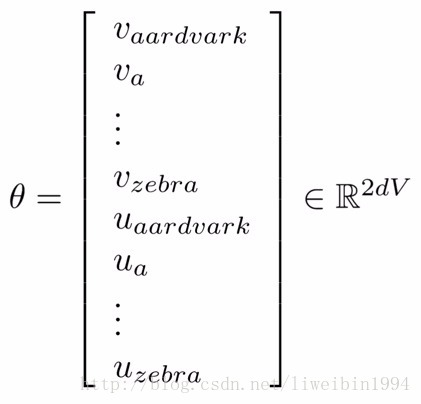
vc 就是中心词wt 的词向量,uo 就是wt+j 的词向量,这就是softmax。所以我们的目标就是不断调整词库中每个词的词向量,使得这个P最大。所以我们的参数就是词库中的这些词向量,并且每个词都有两个词向量,一个是作为中心词的时候(即v ),一个是作为上下文的时候(即u )。所以参数θ 如下:
计算梯度
- 在对上式进行求梯度时,其实只对
2m+1 个词向量进行了求导(一个vc ,2m个uo ),所以∇θJt(θ) 是非常稀疏的。即:
- 视频中只是演示了对
vc 的求导,其实还需要对uo 求导,因为θ 里面包含有v,u两部分向量,当然都需要求导啦。

GloVe
GloVe模型的目标函数是:
J(θ)=12∑i,j=1Wf(Pij)(uTivj−logPij)2 其中,
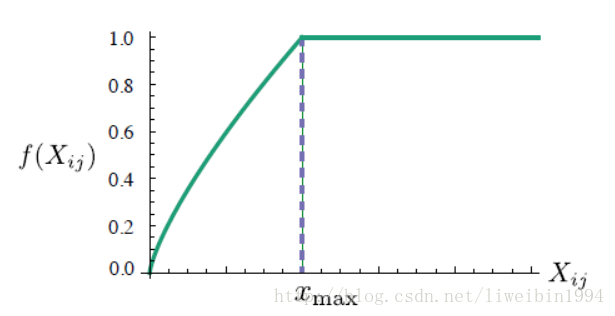
Pij 是两个词的共现频次,也就是两个词同时出现的次数(在拿到数据的时候就可以统计出来了)。f是一个max函数,如下所示:
- 从图中可以看出,频次
Pij 越高,f(Pij) 的值一开始也会越大,达到xmax 之后,即使频次再高,f(Pij) 值也不会再增加了,这在一定程度上对共现频次太高的词起到了抑制作用。 - 前面说到的
θ 包含了v和u两部分向量,也就是每个词都有两个词向量的,那么最后究竟要选哪一个作为最终的词向量呢?最佳方案是将它们相加作为最终的词向量:
Xfinal=U+V