本次梳理基于Datawhale 第12期组队学习 -CS224n-预训练模块
详细课程内容参考(2019)斯坦福CS224n深度学习自然语言处理课程
1. 写在前面
自然语言处理( NLP )是信息时代最重要的技术之一,也是人工智能的重要组成部分。NLP的应用无处不在,因为人们几乎用语言交流一切:网络搜索、广告、电子邮件、客户服务、语言翻译、医疗报告等。近年来,深度学习方法在许多不同的NLP任务中获得了非常高的性能,使用了不需要传统的、任务特定的特征工程的单个端到端神经模型。 而【NLP CS224N】是入门NLP的经典课程, 所以这次借着Datawhale组织的NLP学习的机会学习这门课程, 并从细节层面重新梳理NLP的知识。
今天是课程的第一篇引言和词向量部分, 原课程在这里面介绍了NLP的研究对象, 单词表示和Word2Vec方法的基本原理, 而这篇文章主要是对后面的两者进行整理, 分为词向量基础和Word2Vec基本原理, 在词向量基础部分, 会简单的串一下单词表示的发展过程, 从discrete symbols -> word-embedding(词向量的表示方法), 然后会介绍Word2Vec的基本原理(我理解的这是一个求解单词向量的框架), 通过Word2Vec的方式, 我们就可以得到单词的词向量表示, 那么究竟是如何得到单词的词向量表示的呢? 在这篇文章中我从宏观的层面解释了Word2Vec的工作原理, 而这次是从底层的数学层面补充更多的细节, 所以这次更多的会是公式的推导, 如果感觉有压力的话, 建议先从吴恩达老师的深度学习课程学起!
大纲如下:
- 词向量基础
- Word2Vec的基本原理
Ok, let’s go!
2. 词向量基础
自然语言处理是研究语言的, 而语言是用一个个的词语表示的,所以能够找到一种让计算机看到的表示词语的方式是非常重要的。
首先,我们先来聊一聊在计算机中是如何表示一个词的。 比如下面一句话
““John likes to watch movies. Mary likes too.””
这句话如果想让计算机看明白,我们应该怎么表示呢? 首先,我们会有一个词典,这个词典,就类似下面这样子:

词典包含10个单词,每个单词有唯一的索引。 开始的时候,我们使用one-hot的方式表示每个词的,就是建立一个和词典一样大的向量,然后词典位置用1,然后其他位置用0. 比如单词John,因为在词典中的位置是1, 所以表示成[1, 0, 0, …0], 其他的词也一样。其他的词类似表示出来。

这么这句话就是这些向量放在一块了。 这就是一开始我们表示每一个词的方式,这是一种离散表示,这样计算机至少能读懂了。
但是这样的方式有没有问题呢?有的, 比如我下面这些词, Man, Woman, King, Queen, Apple,Orange。 如果用上面的方式表示每个向量只有一个1, 其余位置是0. 并且互相的内积都是0。 这样在计算机看来,这些词之间没有关联互相独立。 但实际情况肯定不是这样子的,我们知道苹果和橘子比国王和橘子的关系近的多。所以这种表示方法的一大缺点就是它把每个词孤立起来了,这样使得算法对相关词的泛化能力不强。
比如计算机学到一个语言模型:
I want a glass of orange________.计算机读了之后,会填上一个juice,因为计算机学到了orange juice的关系。 但是如果我把orange换成apple, 计算机就不知道怎么填了,因为它不知道orangeh和apple的关系。
所以这种表示词的方式不好,那我们能不能换一种方式呢?
如果我不是用每个词在词典中的位置,而是找一些特征去描述某个词会不会更好一些呢? 比如还是上面的Man, Woman, King, Queen, Apple, Orange这几个单词,我们找一些特征,比如是不是和性别有关,是不是和高贵有关,是不是和年龄有关,是不是和食物有关…。这样,最后每个词就可能得到一种下面的表示方式(拿吴恩达老师的图看一下)

如果用这种方法,来表示苹果和橘子的时候,苹果和橘子很定会非常相似,至少大部分特征是一样的,这样对于已经知道橙子果汁的算法,很大几率上会明白苹果果汁是什么东西。这样对于不同的单词,算法会泛化的更好。 并且,我们找的特征的个数一般会比词典小的多,比如找300个特征,那么描述每个词的话向量是300维,也比之前的one-hot的方式维度小的多。
所以这种方法就可以捕捉到单词之间的关联了,这就是词嵌入的一种表示方法,word-embedding。
那么我们是如何得到的这种表示呢? 其实是先有一个嵌入矩阵Embedding Matrix的。 就是一开始,我们是用one-hot,也就是字典的位置表示每个词,然后通过嵌入矩阵,就得到了每个词的词嵌入向量。 还是看图说话:

就是我们事先训练好了一个词嵌入矩阵(怎么训练的先不用管,这是后面实战的任务,后面会说), 这个矩阵的每一列其实就是每个单词的词向量,每一行表示一个特征,上图是一个300*10000的矩阵,就是10000个单词,每个单词都是从300个特征上进行衡量。 这样,有了这样的一个矩阵之后,我们拿这个矩阵乘以每个单词自己的one-hot的表示,就会得到每个单词的词向量表示。 即
那么重点来了,这个词嵌入矩阵是怎么学习到的呢? 因为我们其实有了词嵌入矩阵之后,单词的表示就一目了然了。早起的时候,使用的自然语言模型计算嵌入矩阵的, 举个例子:
““I want a glass of orange ______””
我们想让计算机填juice,嵌入矩阵未知,我们可以构建下面的神经网络去训练:

把嵌入矩阵也当做一层参数W, 通过梯度下降的方式得到。 实际上,这种算法能够很好的学习词嵌入。
因为我们在训练网络的时候, 不仅有orange juice, 还会有apple juice。 在这个算法的激励下,苹果和橘子会学到很相似的嵌入。 这样做能够让算法更好的符合训练集。 因为它有时
看到orange juice,有时看到apple juice, 如果只有一个300维的特征向量来表示这些词,算法会发现,要想更好的拟合训练集,就要使苹果、橘子、梨、葡萄等这些水果都拥有相似的
特征向量,这就是早期最成功的的学习矩阵E的算法之一。
但是如果只是为了得到嵌入矩阵E而去训练一个语言模型的话是不是大材小用了一些呢? 毕竟语言模型训练起来可是挺复杂的。
人们就想出了一种简单的方式学习词嵌入,选上下文的方式,比如我如果单纯只是为了得到嵌入矩阵,我根本没必要用一句话进行训练,我用几个单词对或者短语就可以,比如我要预测juice, 就可以把这个当做target, 然后只考虑它周围的词就可以了,orange, a glass of orange这种。
我们一般通过某个单词周围的一些词就基本上可以知道这个词是什么意思了, 比如单词bank, 一般它周围的词都是什么money, 政府啊,金融啊这样的一些词,通过这些,就基本上可以推测bank和什么有关系了。

所以这种上下文的方式也能很好的学习单词之间的关联,并且比起建立一个语言模型来说,要容易的多。 这其实就是Word2Vec的思想。
3. Word2Vec的基本原理
3.1 两种算法
Word2Vec的核心思想是预测每个单词和上下文单词之间的关系! 它有两个算法:
- Skip-grams (SG):给定目标词汇去预测它的上下文。简单地说就是预测上下文。 就像下图这样子:
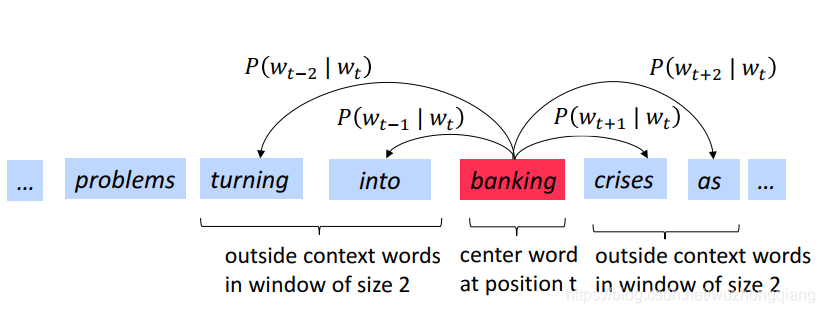
关于Skip-Gram模型的细节, 可以参考我上面给出的那篇博客。这篇博客中就是用Pytorch实现的Skip-Gram模型, 并且还涉及到了一个高效的训练方法负采样。 - Continuous Bag of Words (CBOW):从bag-ofwords上下文去预测目标词汇。也就是从上下文去预测中间词。就不详细讲了, 因为这两个都是模型, 而目的都是求得单词的向量表示。 所以详细介绍上面的一种即可。
3.2 Skip-gram Model
我们对于一个句子,如何选择上下文和目标词呢? 拿一句话:
“I want a glass of orange juice to go along with my cereal.”
Skip-Gram模型的做法是:抽取上下文和目标词配对,来构造一个监督学习问题。这里的上下文不一定总是目标单词之前离得最近的4个单词或最近的n个单词。我们要做的是:
首先随机选择一个单词作为context,例如“orange”;然后我们要做的,随机在一定距离内选另外一个词作为target(使用一个宽度为5或10(自定义)的滑动窗,在context附近选择一个单词作为target),可以是“juice”、“glass”、“my”等等。最终得到了多个context—target对作为监督式学习样本。

那么skip-gram模型究竟是怎么训练的呢?
宏观的训练过程是这样的, 我们需要先选择出一个中心单词c, 然后在c的周围选择上下文单词o, 然后训练一个神经网络来学习c和o的映射关系。 过程是这样的:
- 首先, 我们初始化两个矩阵W, W’分别表示词库里面每个单词作为中心词时候的向量表示和上下文词时候的向量表示(这俩矩阵是维度上的转置关系,不是数值上的转置关系哈)。
- 中心单词c经过W矩阵会得到中心单词c的向量表示, 然后通过W’矩阵会得到该中心单词与所有单词的一个相关性大小, 而我们的目标是通过中间单词c去预测出我们选择的上下文单词o, 所以这时候模型的输出与目标之间会有一个损失, 根据损失,我们就可以通过梯度下降的方式不断地更新W和W’。
- 当模型训练完毕之后, 我们就会得到比较不错的W和W’, 而这两个正好是每个单词作为中心词和上下文词时候的向量表示,我们就学习到了。
上面的这个过程就是宏观层面的训练过程(当然如果看不太明白, 可以结看完下面的细节部分再回来), 因为上面缺失忽略了一些细节, 比如上面的中心单词c长啥样? 通过W之后又长啥样? 通过W’之后又长啥样? 最后模型的输出是什么? 目标函数长什么样?如何获得参数梯度进行梯度下降?等, 如果你是因为这些问题不懂, 很正常, 请接着往下看:
下面就对这些细节部分的原理进行推导和说明。前方高能, 会有一大波数学公式来袭, 请戴好安全帽!
3.3 Wrod2Vec的细节部分
3.3.1 目标函数
首先, 我们从目标函数开始,毕竟以终为始嘛,哈哈。 我们都可以先把
和
看成参数
, 类似神经网络的参数即可, 然后先看看目标函数长啥样:
- 表示最优值
- 表示当前中心词所在位置, 表示词库的总长度
- 表示窗口的大小, 表示从窗口最左边移动到最右边,不等于0是因为不用计算中心词本身
-
表示word representation模型本身, 也就是
和
上式表示尽可能地预测出每个中心词的上下文,即最大化所有概率的乘积。
解释一下上面这个公式, 我们训练的时候, 是希望网络在给定中心单词 和参数 的情况下去输出 的上下文向量,而 正是再说给定 的情况下得到 的概率, 我们肯定是希望这个概率最大, 所以前面有个 , 而上面的连乘只不过是多个中心单词, 每个中心单词又有固定窗口内的上下文向量, 这样说应该明白了吧。
然后,我们把目标函数进行化简, 因为连乘不好算, 我们两边取对数, 这样就变成了下面的形式:
这个只是在取对数的基础上右边加了负号, 而左边变成了
, 因为我们是用梯度下降嘛, 是找最小值。 除以
只是做了一个缩放, 不是重点。所以这个式子应该也很好理解。
那么目标还是里面还有一个问题, 就是这里的 是什么? 因为不换成具体数的话我们还是没法计算目标函数鸭!
为了方便说明, 先给出下面的定义:
- : 单词 作为中心词的词向量表示
- :单词 作为上下文词的词向量表示
因为上面也说过, 每个单词其实有两个词向量表示的, 毕竟每个单词都做上下文和中心词嘛。 这里就是两个词向量表示(也就是
的某一行或者某一列)。那么
简写成
, 且有:
- 表示output或outside之意,即上下文。 用来表示某个需要计算上下文词汇
- 表示center, 就表示中心词
- 表示词库的长度, 从1开始遍历到
再解释这个公式, 为啥要写成这个样子,
表示的是当前的输入中心词
与当前的输出上下文单词
的相似程度,exp只是放大这个相似程度而已, 不用管。 为啥这个就能表示相似程度呢? 因为两个向量的点积运算的含义就是可以衡量两个向量的相似程度, 两个向量越相似, 点积就会越大。 所以这个应该解释明白了。 再看分母
, 这个显然是中心单词
与所有单词的一个相似程度求和。 那么两者一除, 依然是代表了中心单词
与输出的上下文单词
的相似程度,只不过归一化到了0-1之间, 毕竟我们知道概率是0-1之间的, 这就是为啥这个概率是右边形式的原因。 因为右边公式表示了中心单词
与输出的上下文单词
的相似程度, 并且这个相似程度已经归一化到了0-1之间, 我们说给定
希望输出
的概率越大,其实就是希望
和
更相似不是吗? 另外这其实是softmax操作, 不再多解释了, 可能这地方说的越多越乱,哈哈。

3.3.2 具体的流程细节
这里直接拿视频(2017)里的一个图片, 因为我觉得人家解释的非常清楚了:
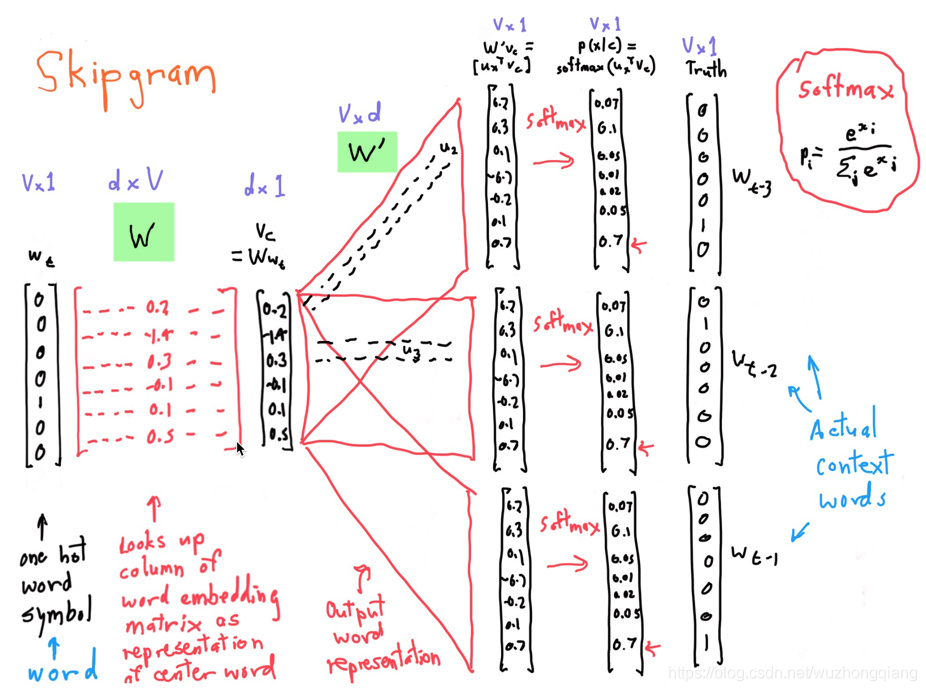
从这里就把这个细节过程看的很明白了吧:
一开始, 我们的中心单词 就是one-hot的表示形式,也就是在词典中的位置,这里的形状是 , 表示词库里面有 个单词, 这里的 张上面那样, 是一个 的矩阵, 表示的是词嵌入的维度, 那么用 (矩阵乘法哈)就会得到中心词的词向量表示 , 大小是 。
然后就是 和上下文矩阵 相乘, 这里的 是 的一个矩阵, 每一行代表每个单词作为上下文的时候的词向量表示, 也就是 , 每一列是词嵌入的维度。 这样通过 就会得到一个 的向量,这个表示的就是中心单词 与每个单词的相似程度。
最后,我们通过softmax操作把这个相似程度转成概率, 选择概率最大的index输出。
上面就是Word2Vec的微观工作过程, 也是训练的正向传播部分。 在实现的层面, 有了这样的一个输出, 然后我们会定义损失函数,然后进行梯度下降即可完成参数的更新,具体的看上面的链接博客, 这里不再过多叙述实现的层面, 这里想继续微观层面, 在上面目标函数的前提下, 我们应该如何求梯度, 然后进行梯度的更新呢?
3.3.3 Word2Vec目标函数的梯度
目前为止,目标函数和流程图都已经清楚了,那么接下来我们需要计算出模型的参数
了。在上面内容中已经介绍了每个单词由两个维度为
的向量表示,常见的办法是将二者拼接,这样我们就可以得到一个非常庞大的向量参数,即

这个应该不用多说了, 每个单词都有作为中心词和上下文的情况, 所以会有两个词向量
。
那么如何优化参数呢? 答: 梯度下降。
那么梯度是啥呢? 我们首先回顾一下目标函数:
要想最小化目标函数, 我们得计算梯度, 也就是
。 由于打卡的时间原因, 我这里就先用笔算了, 不过可以简单说一下这个求偏导怎么求, 这个求偏导,其实主要是右边log的一大串, 这一串先把log项拆成减法的形式, 然后分开求偏导。
第一部分求偏导比较容易, 向量的偏导而已, 而第二部分要注意是链式法则求偏导, 具体的看下面的计算过程:

那么我们就可以得到
我们再分析一下这个公式再说个什么事情哈, 这个是当前希望输出的上下文单词的词向量表示,而 表示的是模型的真实输出结果, 而这个东西其实是真实的输出结果乘以权重然后求和, 其实就是模型的输出结果的期望值, 我们用我们希望的输出结果与模型真实的输出结果的期望作差, 其实就得到了模型进一步改进的方向,也就是希望输出的结果与当前结果的一个差距方向, 而这个方向就是我们的梯度。
这样,我们就求出了一个参数的梯度, 而我们的参数矩阵是有
个参数的, 依照这个方式求出来, 就得到了总的参数的梯度, 接下来就可以用梯度下降了。
当然还有一点需要说明,就是我们上面求的梯度只是
, 其实这只是
矩阵, 而
矩阵的求解方式一致,但是求的是
, 这里也写一下这部分的求解方法:

这个公式的含义是当
,即通过中心词
我们可以正确预测上下文词
了, 这时候我们就不需要调整
了, 否则我们相应的调整
。
好了, Word2Vec的细节部分先介绍到这里吧。 先打卡,后期再补充哈。
4. 总结
这里简单的总结下这篇文章, 这里的主要部分在于Word2Vec公式细节的推导,首先过了一遍词向量的基础知识, 我们如果想让计算机认识单词, 我们一开始是采用了one-hot的方式, 但是这个方式没法体现词与词之间的相关性, 后来就想到了词嵌入的方式, 就是选很多个角度然后去表示单词, 那么这个词嵌入矩阵怎么得到呢? Word2Vec是一个得到这种单词词向量的一种方式, 后面就是重点介绍了Word2Vec的原理部分, 关于宏观的过程和代码实现可以参考我之前的一篇博客。
参考: