Lecture 2 – Word Vectors and Word Senses

1. Review: Main idea of word2vec

Word2vec parameters and computations
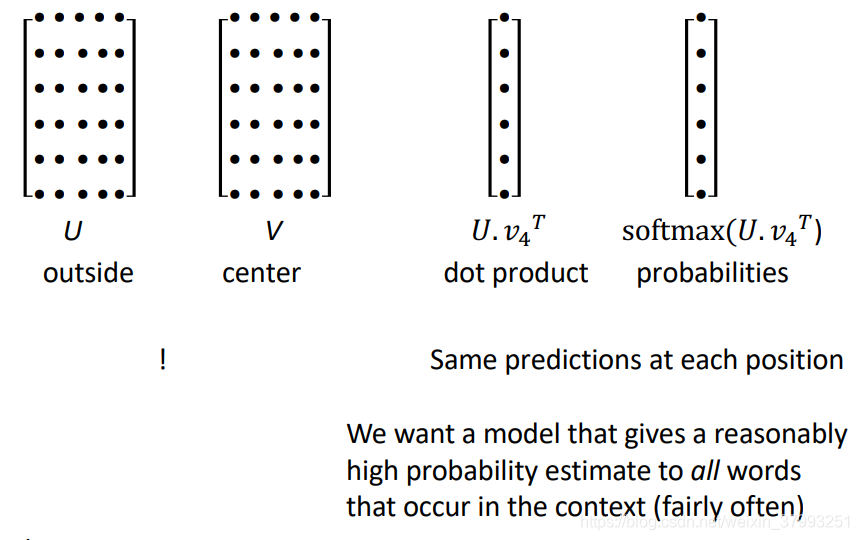
Word2vec maximizes objective function by putting similar words nearby in space

2. Optimization: Gradient Descent
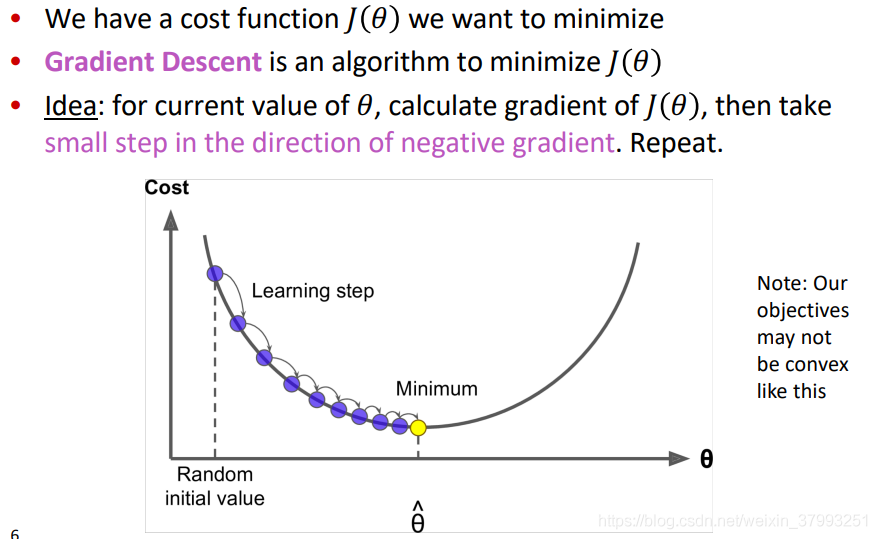
Gradient Descent

Stochastic Gradient Descent
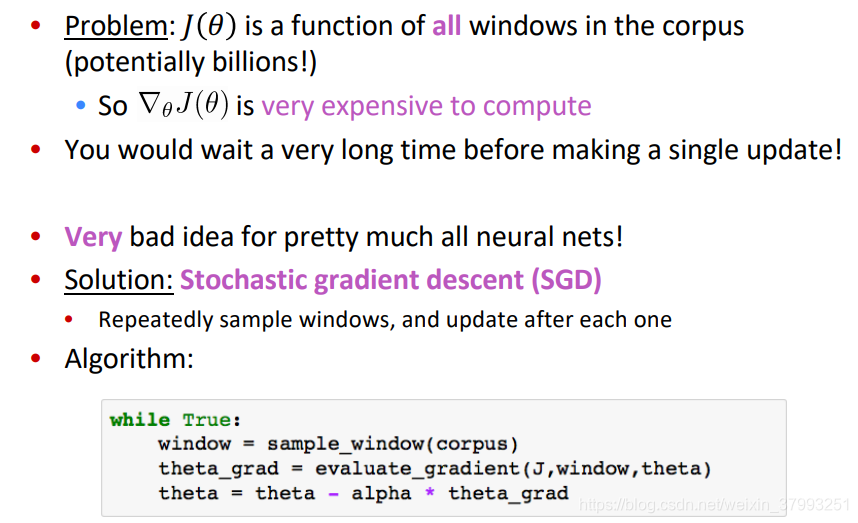
Stochastic gradients with word vectors!
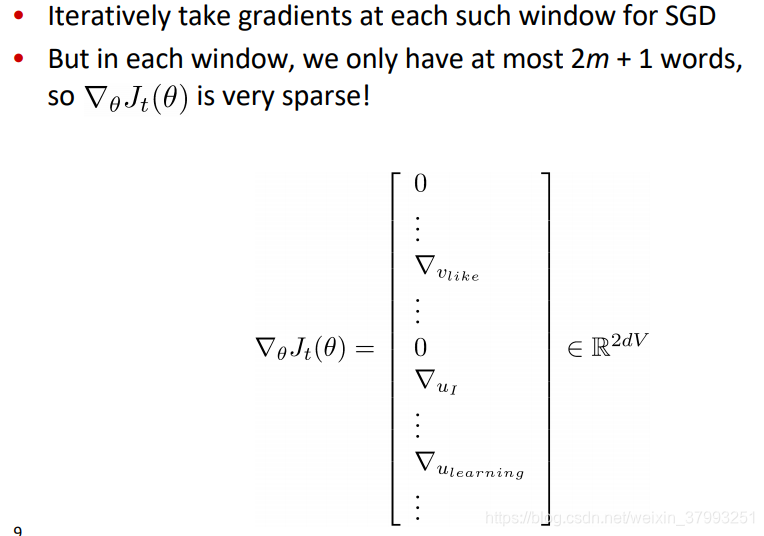

1b. Word2vec: More details
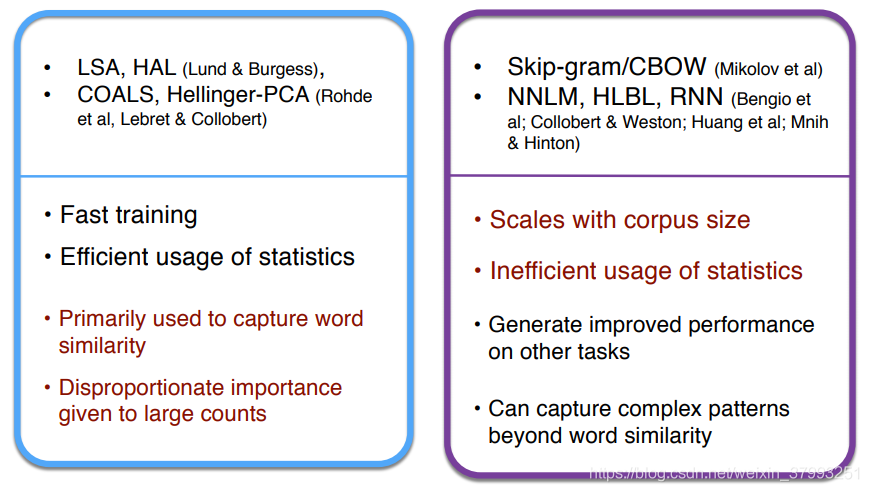
So far, we have looked at two main classes of methods to find word embeddings. The first set are count-based and rely on matrix factorization (e.g. LSA, HAL). While these methods effectively leverage global statistical information, they are primarily used to capture word similarities and do poorly on tasks such as word analogy, indicating a sub-optimal vector space structure. The other set of methods are shallow window-based (e.g. the skip-gram and the CBOW models), which learn word embeddings by making predictions in local context windows. These models demonstrate the capacity to capture complex linguistic patterns beyond word similarity, but fail to make use of the global co-occurrence statistics.

The skip-gram model with negative sampling (HW2)

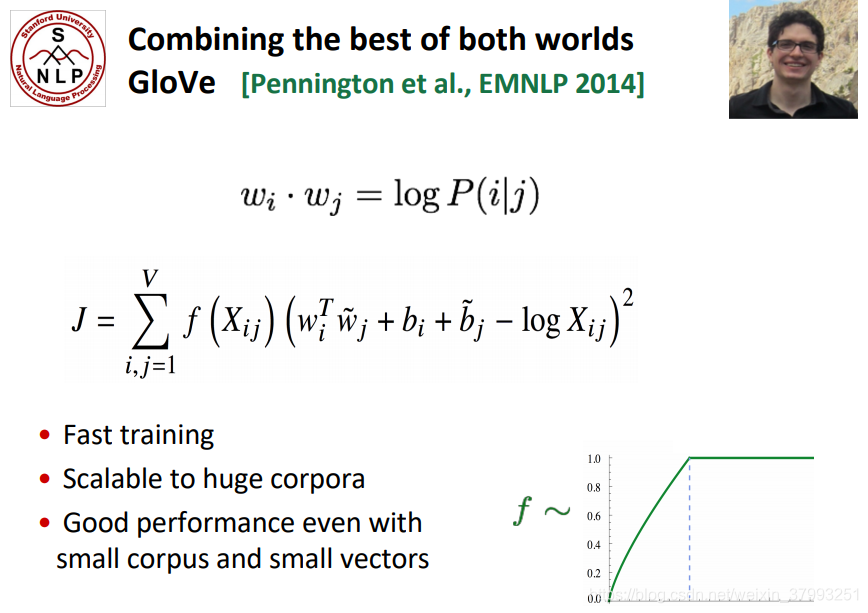
In comparison, GloVe consists of a weighted least squares model that trains on global word-word co-occurrence counts and thus makes efficient use of statistics. The model produces a word vector space with meaningful sub-structure. It shows state-of-the-art performance on the word analogy task, and outperforms other current methods on several word similarity tasks.


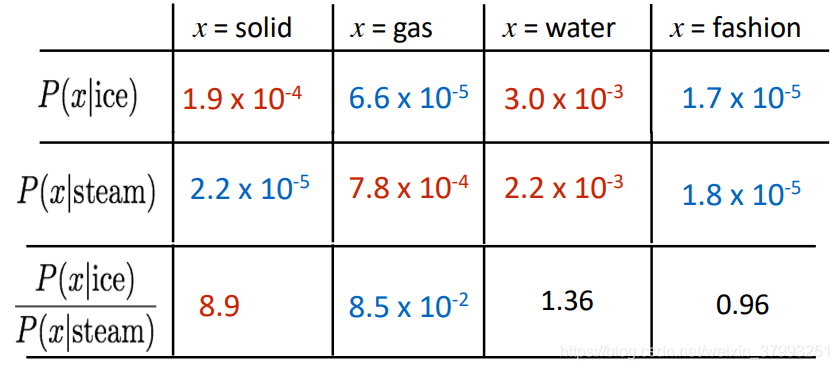
3. But why not capture co-occurrence counts directly?

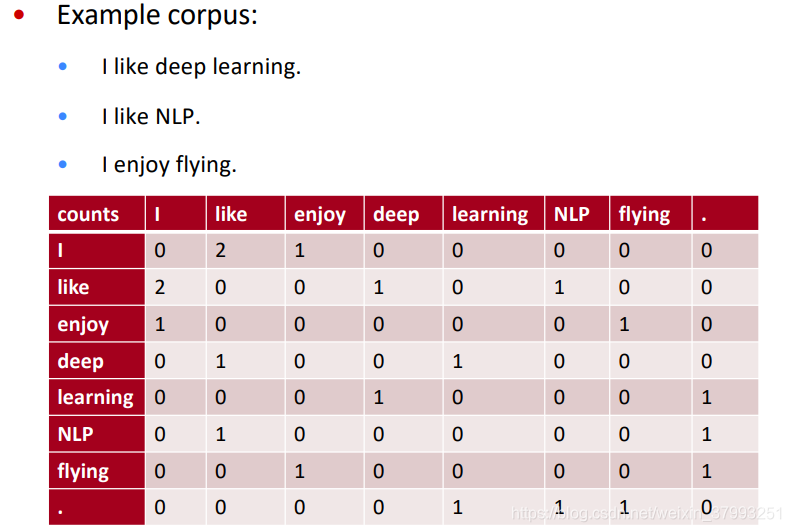
Example: Window based co-occurrence matrix

Window based co-occurrence matrix
Problems with simple co-occurrence vectors

Solution: Low dimensional vectors

Method 1: Dimensionality Reduction on X (HW1)
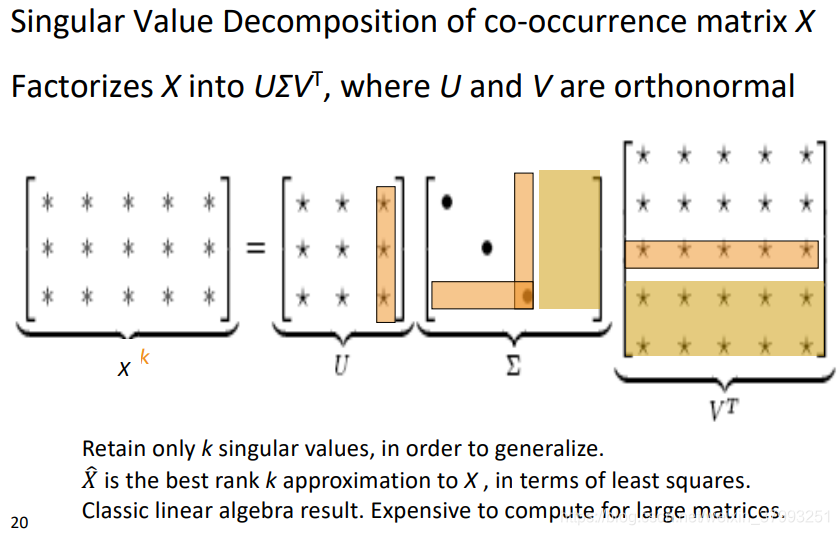
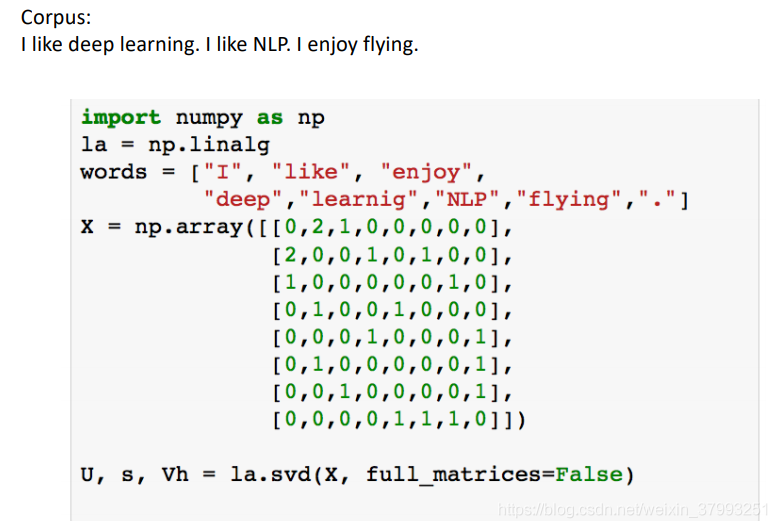
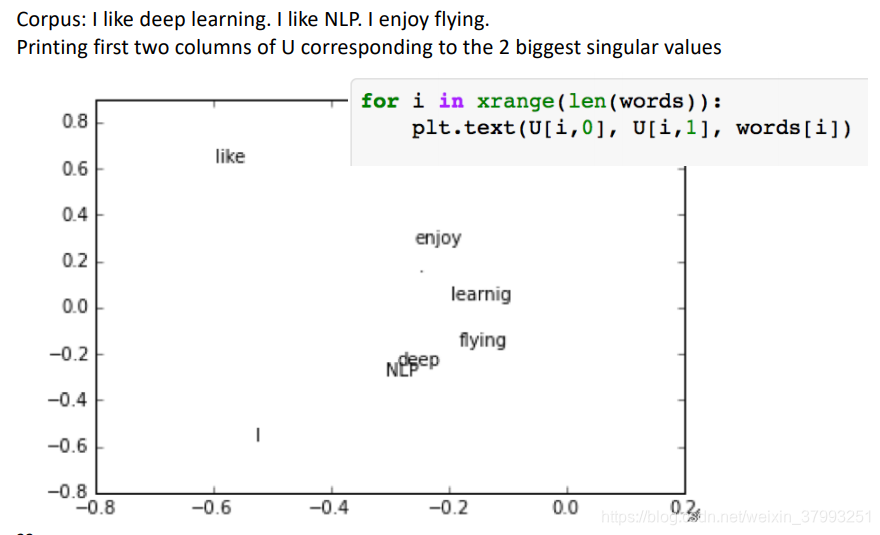
Simple SVD word vectors in Python
Hacks to X (several used in Rohde et al. 2005)

Interesting syntactic patterns emerge in the vectors


Count based vs. direct prediction



How to evaluate word vectors?

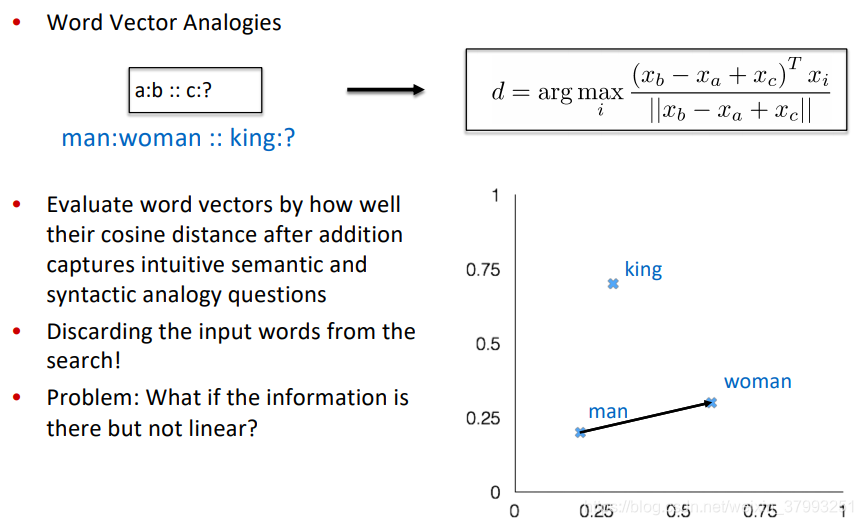
Intrinsic word vector evaluation
Glove Visualizations

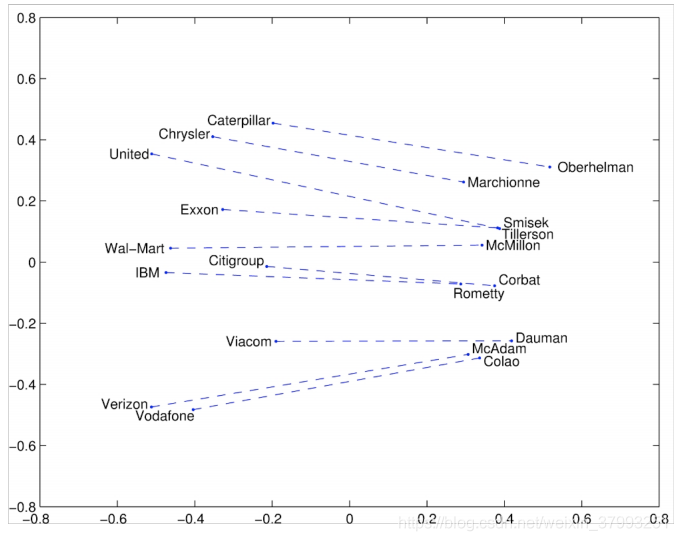
Glove Visualizations: Company - CEO
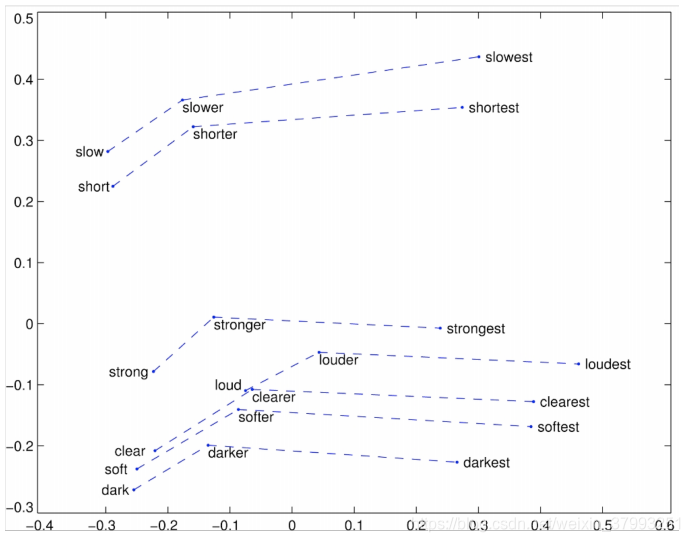
Glove Visualizations: Superlatives
Details of intrinsic word vector evaluation


Analogy evaluation and hyperparameters

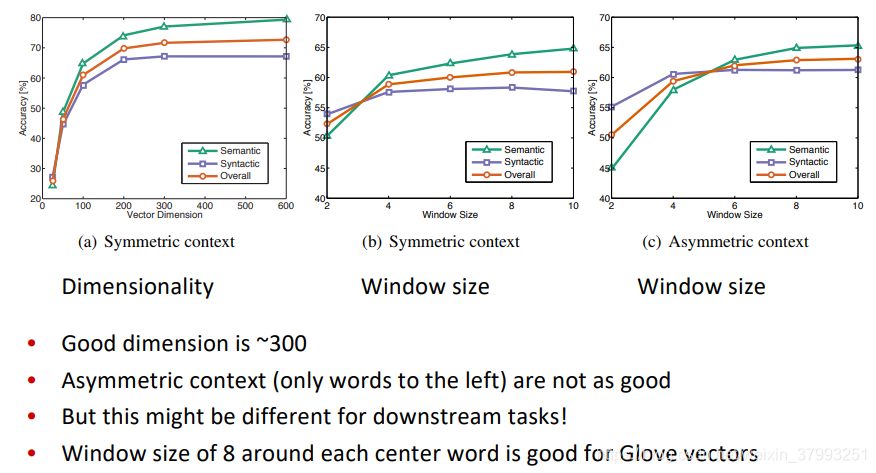
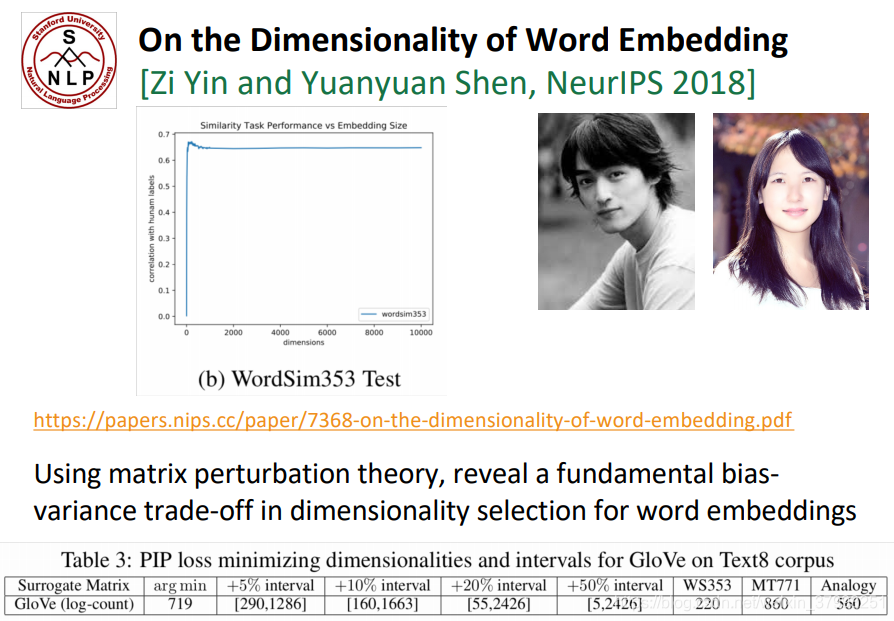
Analogy evaluation and hyperparameters

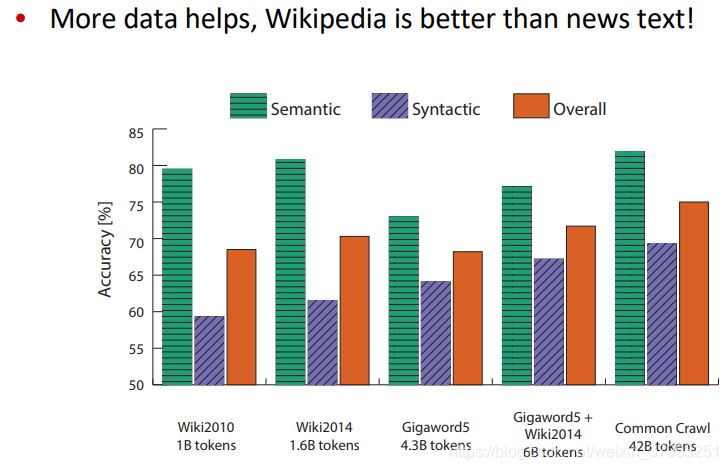
Another intrinsic word vector evaluation
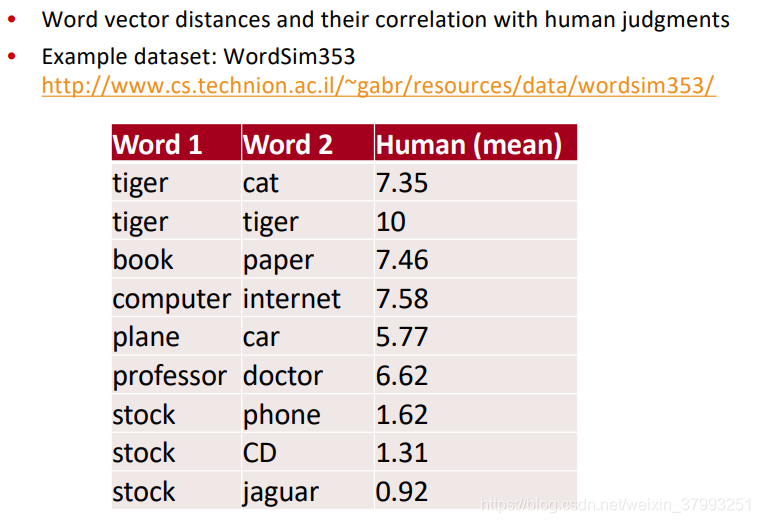
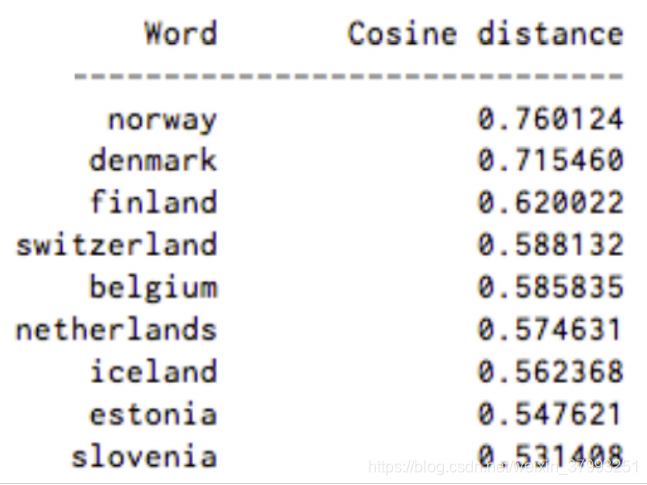
Closest words to “Sweden” (cosine similarity)
Correlation evaluation

Word senses and word sense ambiguity

pike

Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)

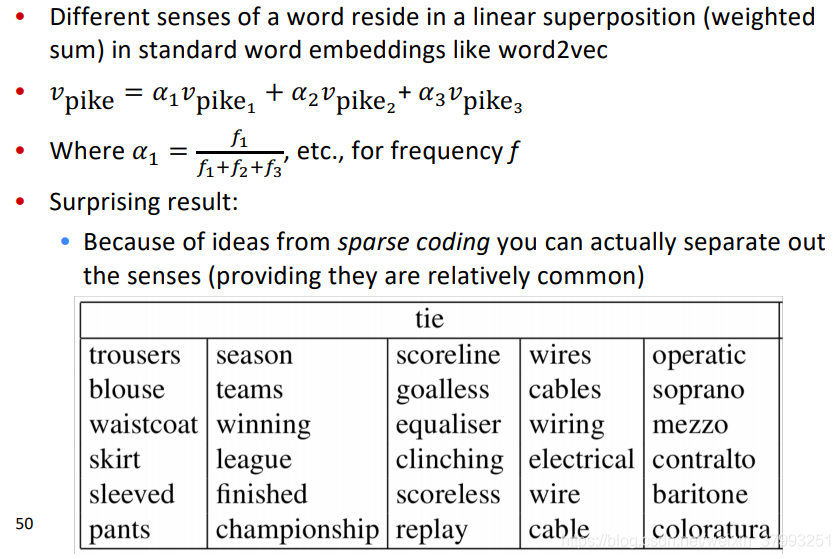
Linear Algebraic Structure of Word Senses, with Applications to Polysemy
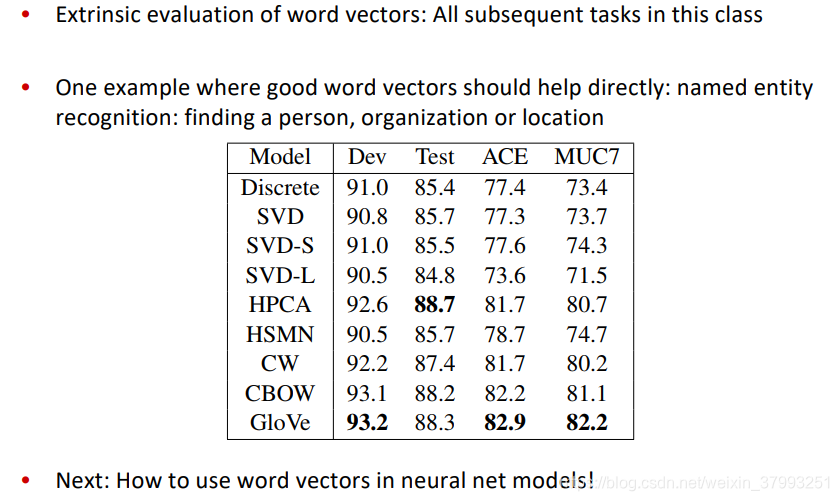
Extrinsic word vector evaluation
Course plan: coming weeks


Office Hours / Help sessions
