(a) 求解预测词向量 Vc的所对应的梯度。
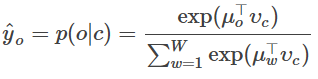
Answer:
在Q2的(b)中,我们已经得到了softmax关于输入向量的梯度=y_hat-y
所以本题的结果为
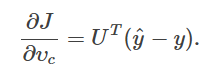
其中U=[μ1,μ2,…,μW]是全体输出向量形成的矩阵
即
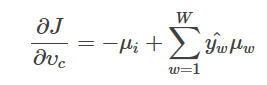
(b) 求解输出词向量μw的梯度(包括μo在内)
Answer:
类似于上题,结果为
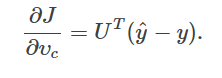
即
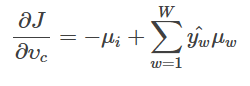
(c) 梯度求解
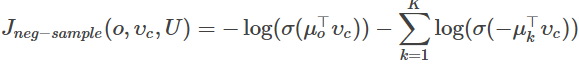
Answer:
同样是计算梯度,使用我们之前的结果即可。
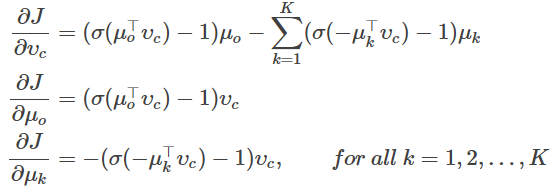
(d)计算由skip-gram和CBOW算法分别算出的全部词向量的梯度
Answer:

我们用F(O,Vc)(其中O表示词汇)来作为损失函数的占位符。题目当中已经有提示,对于skip-gram,以c为中心的周围内容的损失计算为:
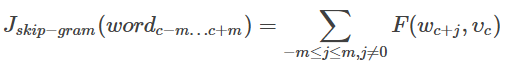
其中,Vc使我们的词向量。
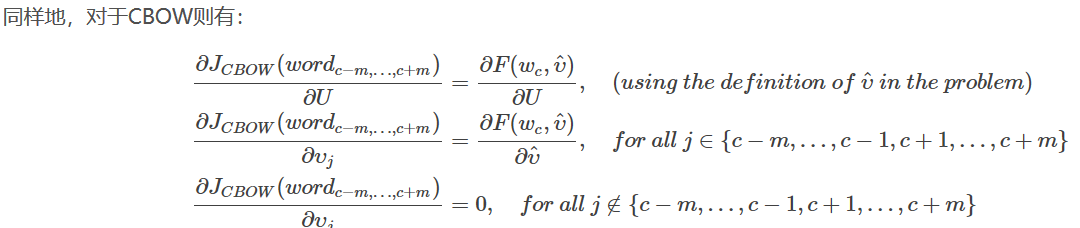
题目中提到,CBOW的损失函数定义为:

(e) 完成word2vec模型
首先完成归一化函数:
def normalizeRows(x): #行归一化函数
""" Row normalization function
Implement a function that normalizes each row of a matrix to have
unit length.
"""
n = x.shape[0]
x /= np.sqrt(np.sum(x**2,axis=1)).reshape((n,1)) + 1e-30 #防止除0加个小数
return x完成word2vec的softmax损失函数:
def softmaxCostAndGradient(predicted, target, outputVectors, dataset):
""" Softmax cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, assuming the softmax prediction function and cross
entropy loss.
Arguments:
predicted -- numpy ndarray, predicted word vector (\hat{v} in
the written component)
target -- integer, the index of the target word
outputVectors -- "output" vectors (as rows) for all tokens
dataset -- needed for negative sampling, unused here.
Return:
cost -- cross entropy cost for the softmax word prediction
gradPred -- the gradient with respect to the predicted word
vector
grad -- the gradient with respect to all the other word
vectors
We will not provide starter code for this function, but feel
free to reference the code you previously wrote for this
assignment!
"""
#针对一个predict word和当前的的target word,完成一个传播过程
#计算预测结果
v_hat = predicted
z = np.dot(outputVectors,v_hat)
preds = softmax(z)
cost = -np.log(preds[target])
#计算梯度
z = preds.copy()
z[target] -= 1.0
grad = np.outer(z,v_hat)
#np.outer函数:
#①对于多维向量,全部展开变为一维向量
#②第一个参数表示倍数,使得第二个向量每次变为几倍
#③第一个参数确定结果的行,第二个参数确定结果的列
gradPred = np.dot(outputVectors.T,z)
return cost, gradPred, gradWord2vec模型负例采样后的损失函数和梯度:
def negSamplingCostAndGradient(predicted, target, outputVectors, dataset,
K=10):
""" Negative sampling cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, using the negative sampling technique. K is the sample
size.
Note: See test_word2vec below for dataset's initialization.
Arguments/Return Specifications: same as softmaxCostAndGradient
"""
# Sampling of indices is done for you. Do not modify this if you
# wish to match the autograder and receive points!
#为每个窗口取k个负样本
indices = [target]
indices.extend(getNegativeSamples(target, dataset, K))
grad = np.zeros(outputVectors.shape)
gradPred = np.zeros(predicted.shape)
cost = 0
z = sigmoid(np.dot(outputVectors[target],predicted))
cost -= np.log(z)
grad[target] += predicted*(z-1.0)
gradPred = outputVectors[target] * (z-1.0)
#最小化这些词随中心词出现在中心词附近的概率
for k in range(K):
sample = indices[k+1]
z = sigmoid(np.dot(outputVectors[sample],predicted))
cost -= np.log(1.0-z)
grad[sample] += predicted*z
gradPred += outputVectors[sample] * z
return cost, gradPred, grad完成skipgram:
def skipgram(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
""" Skip-gram model in word2vec
Implement the skip-gram model in this function.
Arguments:
currentWord -- a string of the current center word
C -- integer, context size
contextWords -- list of no more than 2*C strings, the context words
tokens -- a dictionary that maps words to their indices in
the word vector list
inputVectors -- "input" word vectors (as rows) for all tokens
outputVectors -- "output" word vectors (as rows) for all tokens
word2vecCostAndGradient -- the cost and gradient function for
a prediction vector given the target
word vectors, could be one of the two
cost functions you implemented above.
Return:
cost -- the cost function value for the skip-gram model
grad -- the gradient with respect to the word vectors
"""
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
cword_idx = tokens[currentWord]
v_hat = inputVectors[cword_idx]
#skipgram即根据当前词预测一定范围内的上下文词汇,选择让概率分部值最大的向量
for i in contextWords:#对于窗口中的每个单词
idx = tokens[i] #target的下标(要预测的单词的下标)
c_cost,c_grad_in,c_grad_out = word2vecCostAndGradient(v_hat,idx,outputVectors,dataset)
#更新cost、grad 即使用k个单词来训练这个向量
cost += c_cost
gradOut += c_grad_out
gradIn[cword_idx] += c_grad_in
return cost, gradIn, gradOut(f)完成SGD
注意在python3中已经不用cPickle,直接用pickle就可以了。
def sgd(f, x0, step, iterations, postprocessing=None, useSaved=False,
PRINT_EVERY=10):
""" Stochastic Gradient Descent
Implement the stochastic gradient descent method in this function.
Arguments:
f -- the function to optimize, it should take a single
argument and yield two outputs, a cost and the gradient
with respect to the arguments
x0 -- the initial point to start SGD from
step -- the step size for SGD
iterations -- total iterations to run SGD for
postprocessing -- postprocessing function for the parameters
if necessary. In the case of word2vec we will need to
normalize the word vectors to have unit length.
PRINT_EVERY -- specifies how many iterations to output loss
Return:
x -- the parameter value after SGD finishes
"""
# Anneal learning rate every several iterations
ANNEAL_EVERY = 20000
if useSaved:
start_iter, oldx, state = load_saved_params()
if start_iter > 0:
x0 = oldx
step *= 0.5 ** (start_iter / ANNEAL_EVERY)
if state:
random.setstate(state)
else:
start_iter = 0
x = x0
if not postprocessing:
postprocessing = lambda x: x
expcost = None
for iter in range(start_iter + 1, iterations + 1):
# Don't forget to apply the postprocessing after every iteration!
# You might want to print the progress every few iterations.
cost = None
### YOUR CODE HERE
cost,grad = f(x)
x -= step*grad
postprocessing(x)
### END YOUR CODE
if iter % PRINT_EVERY == 0:
if not expcost:
expcost = cost
else:
expcost = .95 * expcost + .05 * cost
print ("iter %d: %f" % (iter, expcost))
if iter % SAVE_PARAMS_EVERY == 0 and useSaved:
save_params(iter, x)
if iter % ANNEAL_EVERY == 0:
step *= 0.5
return x(f)训练
这里为了使用python3,需要改较多地方,根据报错的地方逐渐修改即可
(h)完成cbow
def cbow(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
"""CBOW model in word2vec
Implement the continuous bag-of-words model in this function.
Arguments/Return specifications: same as the skip-gram model
Extra credit: Implementing CBOW is optional, but the gradient
derivations are not. If you decide not to implement CBOW, remove
the NotImplementedError.
"""
#通过周围单词向量的和来预测中心单词
cost = 0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
D = inputVectors.shape[1]
predicted = np.zeros((D,))
indices = [tokens[cwd] for cwd in contextWords]
#输入为周围单词的向量和
for idx in indices:
predicted += inputVectors[idx, :]
#tokens[currentWord]中心词的下标
cost, gp, gradOut = word2vecCostAndGradient(predicted, tokens[currentWord], outputVectors, dataset)
#即用这个单词来训练周围的向量
gradIn = np.zeros(inputVectors.shape)
for idx in indices:
gradIn[idx, :] += gp
return cost, gradIn, gradOut参考: https://blog.csdn.net/longxinchen_ml/article/details/51765418