目录
论文链接:https://aclanthology.org/2021.emnlp-main.361.pdf

标题翻译:将方面类别情感分析作为文本生成任务加以解决
论文链接:https://aclanthology.org/2021.emnlp-main.361.pdf
摘要
方面类别情感分析越来越受到研究的关注。主流方法通过学习有效的方面类别特定的表示,并在其预先训练的表示中添加特定的输出层,来利用预先训练的语言模型。我们考虑使用预先训练的语言模型的一种更直接的方法,将ACSA任务转换为自然语言生成任务,使用自然语言句子来表示输出。我们的方法允许通过在预训练期间直接遵循任务设置,在seq2seq语言模型中更直接地使用预训练的知识。在几个基准上的实验表明,我们的方法给出了最佳的报告结果,在小样本和零样本设置方面具有很大的优势。
1 引言
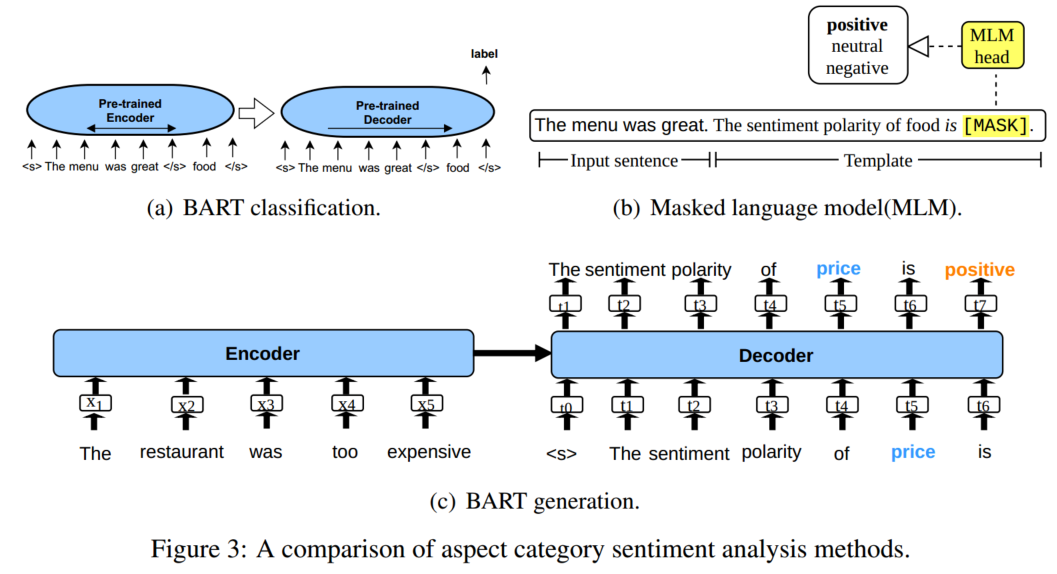
基于方面的情绪分析(ABSA)是一种细粒度的情绪分析任务,包括许多子任务,其中两个子任务是方面类别情绪分析(ACSA)和方面类别检测(ACD)。图1显示了一个示例,其中的输入是“The restaurant was expensive, but the menu was great”。ACD检测方面类别,如price和food,ACSA预测每个方面类别的情绪极性。在这项工作中,我们将重点放在这两项任务以及将两者结合在一起的联合任务上。

先前的研究调查了将ACSA和ACD视为分类任务的各种方法,学习特定方面的句子表征(Wang等人,2016;Ruder等人,2016)。最近,预训练语言模型(PLM)已显示出其在这方面的有效性(Jiang et al,2019)。主要思想是利用预先训练的模型,如BERT(Devlin等人,2019a)来表示输入的特定方面形式(例如,通过将方面类别连接到输入句子的末尾(图3(a))),这为ACSA和ACD分类器提供了有用的语义特征。这些方法给出了极具竞争力的结果(Sun等人,2019;Li等人,2020b)。
上述分类模型受益于情境化表示,其中包含通过对大数据进行预训练而学习的知识(Lin等人,2019)。然而,由于至少两个原因,他们对预先训练的知识的使用可以被视为间接的。首先,通过在预训练的表示之上使用具有单独网络参数的神经网络来执行分类任务。其次,方面范畴的整合使特定方面的输入表示不完全是一个自然语言句子,这与训练前的设置不同。直观地说,通过在任务级别连接预训练和ACSA,可以利用更多的预训练知识,而不仅仅是在表示级别。
我们通过将情感分类任务转化为语言建模任务来研究上述潜力。特别是,如图2所示,ACSA和ACD都被转换为序列到序列(seq2seq)任务,其中编码器获取输入句子,解码器生成自然语言句子。对于ACD,输出遵循一个模板,说明是否讨论了特定方面(例如,“讨论了<category_type>类别”);对于ACSA,说明了特定方面的情感极性(例如,“<given_category>的情感极为<polarity_type>”)。该设置与BART的去噪自动编码器训练方案(Lewis等人,2020)非常一致,我们将其用作预训练模型。与基于分类的方法相比,我们的方法不包括更多的网络参数,因此可以更好地推广到新的领域(Brown等人,2020;Gao等人,2020)。给定一个具有完全看不见的方面类别和情感标签的新领域,我们的方法可以在不改变输出层结构的情况下应用。

除了基于分类的方法外,我们还将掩蔽语言模型(MLM)作为基线,我们的方法的一个自然对应物是掩蔽填充任务。如图3(b)所示,与我们的方法不同,输出模板被连接到输入,关键字被屏蔽以进行预测。这项MLM任务与BERT(Devlin等人,2019a)的预训练非常一致。与这种MLM方法相比,生成方法可以更好地学习作为两个相关序列的输入和输出模板之间的相关性,BART在抽象文本摘要方面的强大性能已经证明了这一点(Lewis等人,2020)。
在三个标准基准数据集上的实验结果表明,生成和MLM方法都优于使用相同预训练语言模型的分类方法。最后,生成方法比MLM方法具有更强的性能,大大优于以前的现有技术方法。此外,使用生成方法,我们表明联合执行ACSA和ACD会比传统的pipeline带来更好的结果。据我们所知,我们是第一个使用生成的预训练语言模型来解决ACSA/ACD问题的人。我们在发布代码https://github.com/lgw863/ACSA-generation。
2 相关工作
Aspect Category Sentiment Analysis Wang等人(2016)提出了一种基于注意力的LSTM网络,当将不同的方面类别作为输入时,该网络可以集中于句子的不同部分。Ruder等人(2016)用分层双向LSTM对文本中句子的相互依赖性进行建模。Yin等人(2017)通过构建伪问答对,将任务建模为机器理解问题。Xue和Li(2018)使用CNN提取情感特征,并使用门控机制选择性地输出与方面类别相关的特征。Xing等人(2019)、Liang等人(2019。Sun等人(2019)从方面类别构建辅助句子,并将ACSA转换为句子对分类任务。Li等人(2020b)通过聚合指示句子中的方面类别的单词的情感来预测句子中提到的方面类别。
为了避免错误传播,提出了几种联合模型,它们联合执行ACD和ACSA。Schmitt等人(2018)提出了两个联合模型:端到端LSTM和端到端CNN,它们同时产生所有方面类别及其相应的情绪极性。Hu等人(2019)提出了约束注意力网络(CAN)来约束注意力权重分配。Wang等人(2019)提出了方面水平情感胶囊模型(AS-Capsules),该模型通过共享组件利用方面类别和情感之间的相关性。Li等人(2020a)提出了一种新的联合模型,该模型包含共享的情绪预测层。
上面所有的模型都是分类方法,使用单独的输出网络来给出输出标签。相反,我们通过直接遵循语言模型的预训练过程来研究自然语言生成方法。
Masked Language Model Methods 有一系列工作使用掩蔽语言模型(MLM)来完成自然语言理解任务。其基本思想是通过在语言建模任务中定义特定的句子提示来利用预先训练的模型中的信息。Brown等人(2020)在文本分类任务中使用提示进行少样本学习。Schick和Schütze(2020)将输入改写为完形填空题,用于文本分类。Schick等人(2020)和Gao等人(2020年)分别通过自动生成标签词和模板来扩展Schick和Schütze(2020)。Petroni等人(2019)通过构建完形填空风格模板,从BERT中提取实体之间的关系。我们是第一个将此类方法应用于ACSA的,并将其作为基线。与这些基于模板的模型不同,我们的最终模型使用BART进行文本生成,与BERT相比,它更好地模拟了输入句子和输出句子之间的相关性。
Generation Methods 已经有工作将NLP问题作为序列生成任务(Vinyals等人,2015;Ma等人,2017;Stanovsky和Dagan,2018;Raffel等人,2020),其中输出是一个token序列,而不是一个自然语言句子。Daza和Frank(2018)将语义角色标记视为一个序列到序列的过程。Li等人(2019)将实体关系提取任务作为一种多回合问答生成方法来解决。我们的工作类似于将NLP任务转换为生成任务。与上述方法不同,我们的目标是充分利用ACSA在BART中预先训练的知识。
3 方法
形式上,对于ACD,输入是一个句子X = {x1, ... , xn},其中xi表示第i个单词。对于ACSA,还给出了一组预先确定的方面类别。我们在3.1节中介绍了相关的预训练语言模型,在3.2节中介绍分类方法,在3.3节中介绍MLM方法,在3.4节中介绍我们的生成方法。
3.1 预训练语言模型
我们将BERT(Devlin等人,2019a)和BART(Lewis等人,2020)作为预训练的语言模型。两者都建立在Transformer(Vaswani等人,2017)架构之上。BERT(Devlin等人,2019a)是用于屏蔽文本填充的Transformer的编码器堆栈,其中模型使用上下文单词来预测屏蔽单词。BART(Lewis等人,2020)是一种用于自然语言生成的去噪自动编码器seq2seq模型预训练。它的训练应用了文档破坏,例如从输入中随机删除标记,以及使用任意噪声函数破坏文本。BART被训练来重构原始文本。
3.2 分类方法
我们使用多层感知器网络作为分类器模型,该模型以表示向量作为输入。BERT和BART都被认为是编码器。
BERT Classification BERT采用“[CLS] input sentence [SEP] given_category [SEP]”作为输入。与“[CLS]”相对应的最终隐藏状态被用作分类的表示。


3.3 掩盖语言模型方法
掩蔽语言模型(MLM)(Devlin等人,2019a)通过填充缺失的标记来完成给定的提示。我们引用包含给定类别和MASK令牌的模板作为提示。对于情绪分析任务,BERT MLM采用输入句子和提示作为模型输入,并预测针对给定类别的情绪极性标签词。对于BART MLM,相同的输入被馈送到编码器和解码器,并且MASK令牌的标签字的最高解码器预测是预测的极性标签(见图3(b))。我们在MLM方法和生成方法中使用相同的模板,遵循第3.4.1节中的模板创建方法。
3.4 生成方法
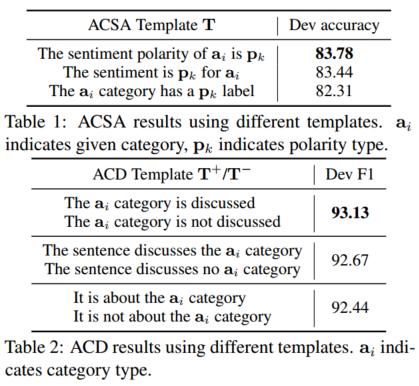
我们将ACSA和ACD作为seq2seq框架下的语言模型排序问题(见图3(c))。目标序列Tai,pk(Tai)= {t1, ... , tm} 是一个由给定类别ai和极性类型pk填充的模板。我们首先在第3.4.1节中介绍了如何创建模板,然后分别在第3.4.2节和第3.4.3节中展示了推理和训练的细节。
3.4.1 模板创建

3.4.2 推理

3.4.3 训练

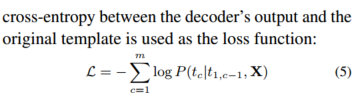
4 实验
我们选择SemEval-2014餐厅评论(Rest14)(Pontiki et al,2014a)、Rest14的变体(Rest14 hard)(Xue和Li,2018)和多方面多情感(MAMS)(Jiang et al,2019)数据集作为句子级情感,TripAdvisor(Wang et al,2010)和BeerAdvocate(McAuley et al,2012;Lei et al,2016)数据集用于文档级情感。在Tay等人(2018)之前的工作之后,采用了训练/开发/测试集的标准划分,其细节如附录A所示。
我们使用预先训练的BERT基线1和BART基线2模型进行任务微调。对于不同的模型,我们从{4e-5、2e-5和1e5}中选择微调学习率,从{8、16、24}中选择批量大小。dropout概率为0.1。根据开发集的最高性能来选择最佳的型号配置。设置细节如附录A所示。
4.1 基线方法
我们使用相同的编码器将我们的生成方法与分类和MLM基线(图3)进行比较。特别是,将BART生成(即图3(c))与BART分类(图3(a))和BART MLM(图3)以及BERT分类和BERT MLM进行比较。此外,我们的方法还与文献中的其他模型进行了比较,如下所示。
对于句子水平的ACSA,我们还将我们的方法与以下文献中最先进的方法进行了比较。(1) 非BERT模型:GCAE(Xue和Li,2018)、As胶囊(Wang等人,2019)和CapsNet(Jiang等人,2019年);(2) 基于BERT(Devlin et al,2019b)的模型:BERT-pair-QA-B(Sun et al,2019)、CapsNet BERT(Jiang et al.,2019)和AC-MIMLLN-BERT(Li et al,2020b)。
对于文档级ACSA,我们将我们的方法与以下方法进行比较。(1) 非BERT模型:LSTM(Tang等人,2015)、HAN(Yang等人,2016)和MR(机器理解模式)(Yin等人,2017);(2) 基于BERT(Devlin等人,2019b)的模型:BERT分类。
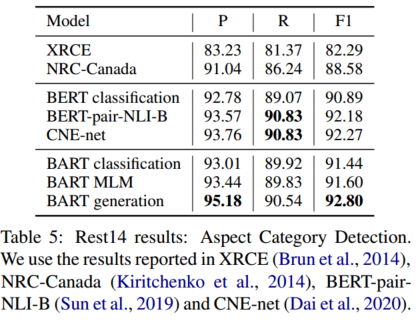
对于ACD,我们将我们的方法与以下方法进行比较。(1) 非BERT模型:XRCE(Brun等人,2014年),NRC加拿大(Kiritchenko等人,2014);(2) 基于BERT(Devlin等人,2019b)的模型:BERT分类,BERT-pair-NLI-B(Sun等人,2019),CNE-net(Dai等人,2020)。
4.2 开发实验


4.3 ACSA实验
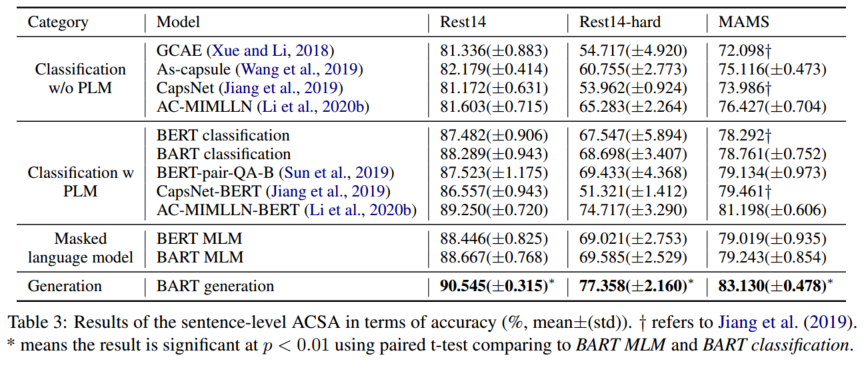
句子级ACSA的结果如表3所示。我们可以看到,首先,BERT MLM和BART MLM的性能分别优于BERT分类和BART分类。特别是,BERT MLM提供了一个强大的基线,优于所有非BERT和BERT分类基线。这表明,在任务级别使用预训练可以取得比在表示级别更好的结果。此外,BART MLM和分类模型比相应的BERT模型表现得更好。其次,BART生成在所有三个数据集上都优于所有基线,这表明我们的模型可以更好地检测一句话中针对不同方面类别的多个情绪极性。第三,BART生成的性能明显优于BART MLM,在MAMS上的准确率提高了3.89%,证明了生成方法的有效性。这显示了用于生成语义相关内容的BART预训练的强度,这也反映在BART在抽象摘要方面的强大性能上 (Lewis et al., 2020)。相反,MLM方法将输入和输出连接成一个序列,因此无法在编码器-解码器预训练中对它们的相关性进行建模。
我们的模型在文档级ACSA上的性能如表4所示。与LSTM、HAN和MR相比,BERT分类和BART分类优于所有基线,这表明了预训练的有效性。BERT传销和BART传销分别超过了BERT分类和BART分类。我们的BART生成模型在TripAdvisor和BeerAdvocate上分别比BART MLM提高了1.15%和0.70%,表明该生成方法可以更有效地将BART用于ACSA。
4.4 ACD实验
Rest14 ACD子任务的结果如表5所示。根据Pontiki等人(2014b),我们使用Micro-F1进行评估。再次,BART生成实现了比BART分类和BART MLM更好的结果。我们的模型在精度和F-1得分方面优于所有基线。特别是,获得了95%以上的准确度分数,这表明我们的模型可以有效地排除输入中未提及的方面类别。
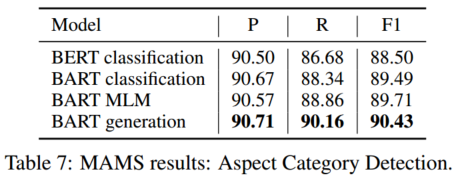
我们还研究了MAMS数据集的性能,该数据集由至少两个独特的方面类别组成,每个输入句子中具有不同的情感极性。表7显示,BART生成优于所有基线,表明我们的模型在一句话中检测多个方面类别的能力更好。
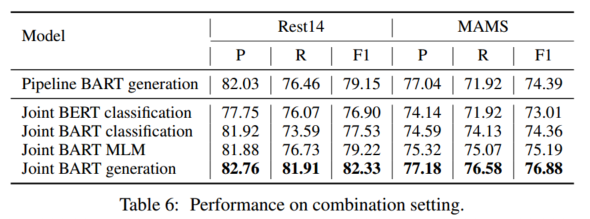
4.5 联合模型
生成方法允许我们通过扩展表1中的第一个模板来建立一个简单的联合模型,使用“<given_category>的情感极性为none”作为不存在方面类别的模板。Rest-14和MAMS的结果如表6所示。我们发现,与管道BART生成相比,联合BART生成在这项任务上取得了更好的结果。联合BART生成在精度、召回率和F-1得分方面优于所有基线,这表明了联合学习的优势。
4.6 少样本和零样本学习
我们评估了ACSA上的模型性能,其中只有少量标记数据可用于训练,通过从大型训练集中随机采样训练实例来模拟低资源数据场景。特别地,我们使用不同数量的实例进行训练,每个类别类型随机采样固定数量的实例(Rest14和MAMS的每个类别类型为10、20、50、100、200、500个实例)。结果如图4所示,其中还比较了BERT分类、BART分类和BART MLM的方法。
可以看出,在所有数据集上,我们的模型都优于BERT分类、BART分类和BART MLM,尤其是在训练实例数量较少的情况下。例如,当只有10个训练实例时,我们的模型在Rest14上的准确率得分为82.01%,相比之下,BERT分类为38.57%,BART分类为50.16%。当实例数量增长到500个时,我们的模型在Rest14和MAMS上的准确率分别比BART MLM高2.24%和2.65%。一个可能的原因是,我们的方法在预训练中更多地利用了直接的情感知识语言模型,直接采用前面提到的BART的原始结构。相比之下,由于间接转移了情感偏见,分类方法无法实现这一点。
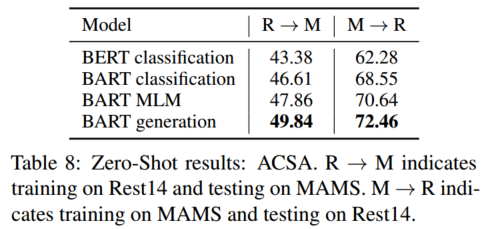
我们的零样本学习实验的结果见表8。在所有情况下,我们的方法都优于所有的基线。特别是,在MAMS上训练的模型在Rest14上的性能优于反向零样本设置,这证明MAMS数据集具有更高的挑战性。


5 分析
5.1 类别频率的影响
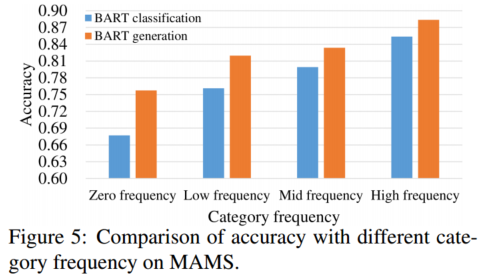
方面类别可以是隐含的,不一定作为术语出现在给定的句子中。为了探索ACSA准确性与给定类别的出现频率之间的相关性,我们根据出现频率将MAMS测试集中的八个类别划分为四个子集。给定句子中从未出现的类别(即杂项)被放入零频率子集,15%的最不频繁的类别(如氛围、员工)被放入低频子集,30%的最频繁类别(如菜单、服务)被放入高频子集,其余类别(如价格、食物、地点)被放入中频子集。
图5显示了BART分类和我们的模型相对于频率的准确性。随着类别出现频率的降低,两个模型之间的准确度相对差距增大。在零频率下,我们的方法比BART分类的准确率高出8.03%。这表明我们的方法在总结抽象或罕见类别的情感极性方面更稳健。即使句子中没有明确的类别术语,生成方法也可以根据上下文给出整个句子的隐含类别意见。
5.2 案例研究
图6显示了BART分类模型无法推断的测试集中的典型示例。在句子(a)中,给定的类别miscellaneous不作为一个术语出现在给定的句子中。该方法可以综合不同方面的情感极性,得到正确的极性。在句子(b)中,“the value on the kids menu is good”,good修改的是这个值,而不是给定的类别菜单。我们的方法给出了正确的极性,不受周围其他方面情绪的影响。最后一个实例(c)具有条件推理,这对于BART分类是困难的。相比之下,捷运一代通过正确识别“if there was…”中的消极性,给出了正确的标签。会更有吸引力。”这可能是因为我们的方法使用预训练的知识来推断输入和输出序列之间的句子间相关性,而BART分类模型由于在附加分类网络中间接使用BART而未能实现这一点。
6 总结
我们研究了一种面向方面类别检测(ACD)和方面类别情感分析(ACSA)的生成方法,该方法可以在不引入额外模型参数的情况下,更好地利用BART在对输入进行语义级总结方面的优势。实验表明,本文提出的方法在句子级和文档级的方面情感分析中都取得了比基线模型更好的性能。与传统的情感分类方法相比,我们的方法在零样本和少样本任务上也更强大。