版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32782771/article/details/84230150
一、摘要
作者提出一个新颖的方法来解决targeted ABSA,通过利用通用知识。用一个包含target-level的attention和sentence-level的attention的层次化attention机制来增强LSTM结构。关于情感相关概念的常识知识被结合到用于情感分类的深度神经网络的端到端训练中。为了将常识知识紧密地集成到递归编码器中,作者提出了LSTM的扩展结构,称为Sentic LSTM。在两个公开数据集上跑实验,结果都是state-of-the-art的。
二、介绍
简单地介绍一下什么是ABSA。“The design of the space is good but the service is horrible。”句子中有两个aspect:space和service。针对这两个aspect的情感是相反的,spave是正面,service是负面。
针对目前state-of-the-art的方法中,作者提出了三个还未解决的问题。
- 一个给定的target可能在句中有多个实例(相同target出现多次)或多个词,目前的研究假设全部实例都是等权重的,并且在这些实例中简单地计算平均值向量来表示。这种过度简化与以下事实相冲突:目标的一个或多个实例通常比其他实例与情感更紧密的联系。
- 其次,现有方法所利用的层次化的attention仅隐含地模拟了在给定target和aspect的情况下,推断情感词视为黑盒。
- 现有的研究不足以在深层神经网络中有效地融入外部知识。比如通用知识,对aspect和情感极性的确认有很大贡献。
为了解决以上问题,作者的贡献如下。 - 提出层次化的attention模型,首先明确地指出target,然后是整个句子。
- 扩展了经典的LSTM结构,其中包含与外部知识集成的组件。
- 将情感常识知识融入到深度神经网络中。
三、相关工作
在这里简单地介绍下什么是ABSA、targeted SA、targeted ABSA。
- ABSA:ABSA的任务是根据一系列aspect对情绪极性进行分类。ABSA面临的最大挑战是如何有效地表达整个句子的特定aspect的情感信息。早起的工作主要依赖于特征工程来表征句子。由于深度学习的兴起,很多最近的工作利用深度神经网络生成embedding,然后喂给分类器。此外,这种表示可以通过attention机制进行增强。最终的情感表示受益于attention机制,因为解决了RNN的缺点,当只有一个输入喂给分类器导致的信息损失。
- targeted SA:targeted SA 旨在分析针对目标实体的情感。目前有很多工作,TD-LSTM、TC-LSTM,DMN。目前的方法要么忽略了多个目标实体(或词)的问题,或者简单地使用一个目标表达式的平均值向量来表示。与上述方法不同,作者使用注意力权重对每个词进行加权,所以一个给定的target可以由其信息量最大的组件表示。
- targeted ABSA:
- 融入外部知识:
四、方法
- 任务定义:一个句子 由一系列单词组成。一个target 有句中的 个单词组成,用 表示, 表示target表达式中的第 个单词。targeted ABSA可以分成两个子任务:解析属于预定义集合的 的方面类别;根据与 相关的每个方面类别对情感极性进行分类。举个例子,‘I live in [West London] for years. I like it and it is safe to live in much of [west London]. Except [Brent] maybe.’ 两个target:West London和Brent。West London的ABSA为[‘general’: positive; ‘safety’: positive],Brent的ABSA为[‘general’: negative; ‘safety’: negative]。
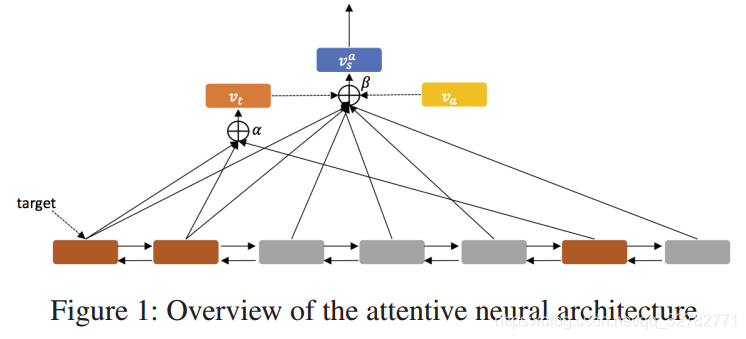
- OverView:作者提出的网络结构由两个组件构成,序列编码器和层次化的attention组件。给定一个句子
,经过Embedding层转化为词向量
。然后再经过双向LSTM层转化为一系列的隐含层输出。棕色部分是target词的位置,用这些词的隐含层输出做一个self-attention来表示这个target。这个向量再和每一个隐含层输出拼接在一起做self-attention,同时输入aspect的embedding,作为整个句子的表示。