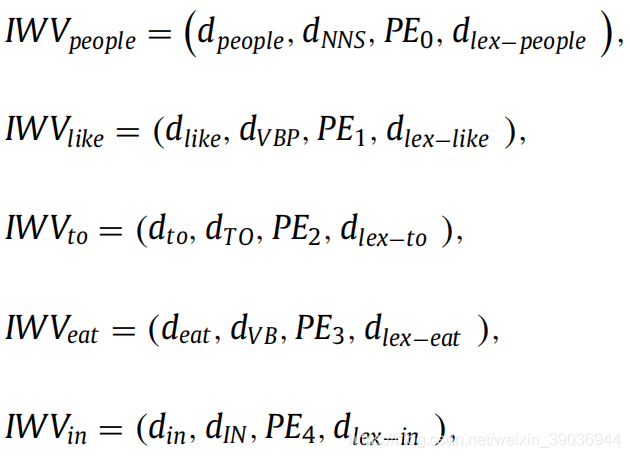文章名:《Sentiment analysis based on improved pre-trained word embeddings》
作者 Seyed Mahdi Rezaeiniaa, Rouhollah Rahmani a,∗, Ali Ghodsi b, Hadi Veisi a
时间 2019
(一)Introduction
目前词嵌入的深度学习算法模型有两种:Word2Vec和Global Vectors (GloVe)。虽然这两种模型挺成功,但是还存在一些局限性,需要改进:(1)由于要对每个单词进行训练并提出一个可接受的向量,所需要的语料库的规模必须要大。例如,谷歌已经使用了大约1000亿个单词来训练Word2Vec算法,并重新发布了300个维度的预先训练的单词向量。当研究的数据集规模较小时,研究人员不得不使用预先训练的单词向量,如Word2Vec和GloVe,但这可能不是最适合他们用于研究的数据。(2)用于表示文档的两种方法的单词向量计算不考虑文档的上下文。例如,“甲虫”作为汽车的词向量等于它作为动物的词向量。(3)这两种模型都忽略了不同时出现的术语之间的关系。(4)忽略给定文本的情感信息,造成对带有情感极性的词向量进行情感分析时判断错误。
(二)Related Works
1.Lexicon-based method
缺点:基于人工标记的文本,并且覆盖率低,范围小。
2.Deep learning method
(三)Proposed Method
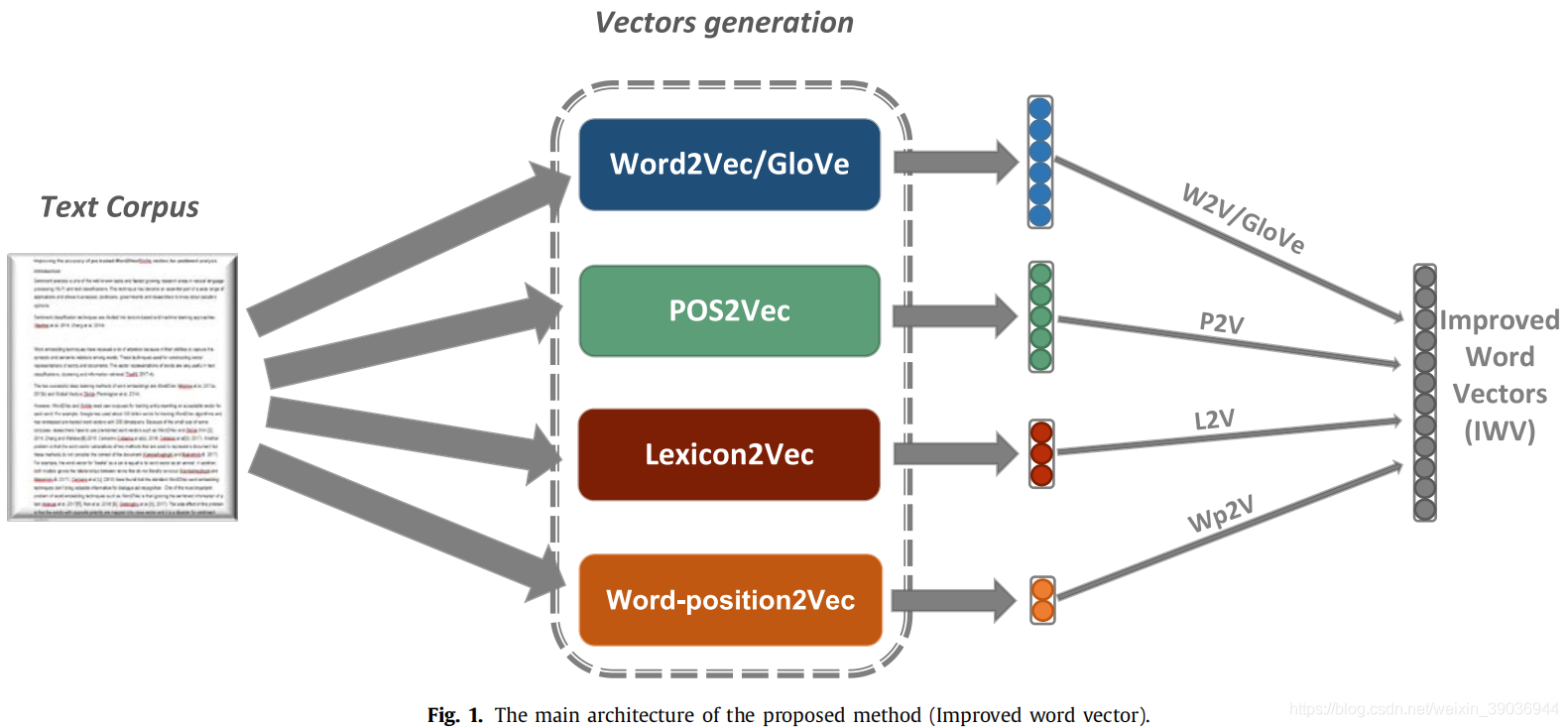
1.Lexicon2Vec (L2V)
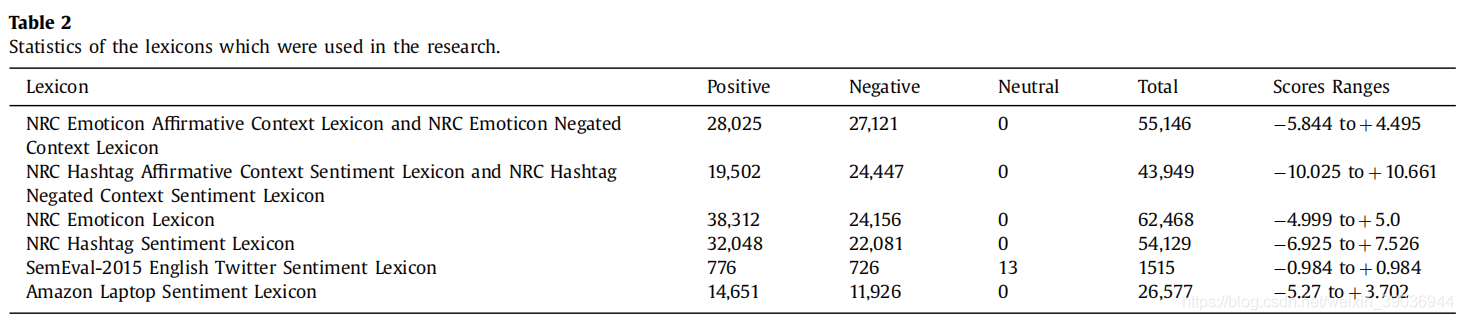
情感和情感词汇是具有极性分数的短语和单词的列表,可用于分析文本。测试了各种词汇,并选择了词汇集,最大限度地提高了情感分析的准确性。我们选择了六个词汇集进行组合,为每个单词分配了向量。这种组合增加了情感分析的准确性。首先,提取每个单词的情感分数。然后,通过将提取的分数串联起来,形成每个单词的词汇向量。在最后一步,归一化词汇向量。

2.POS2Vec (P2V)
为文本中的每个单词进行词性标注(名词、形容词、副词)等等。用Standford parse(斯坦福解析器)进行词性标注,将每个生成的POS标签转换为一个常量向量,并与Word2Vec/GloVe向量连接。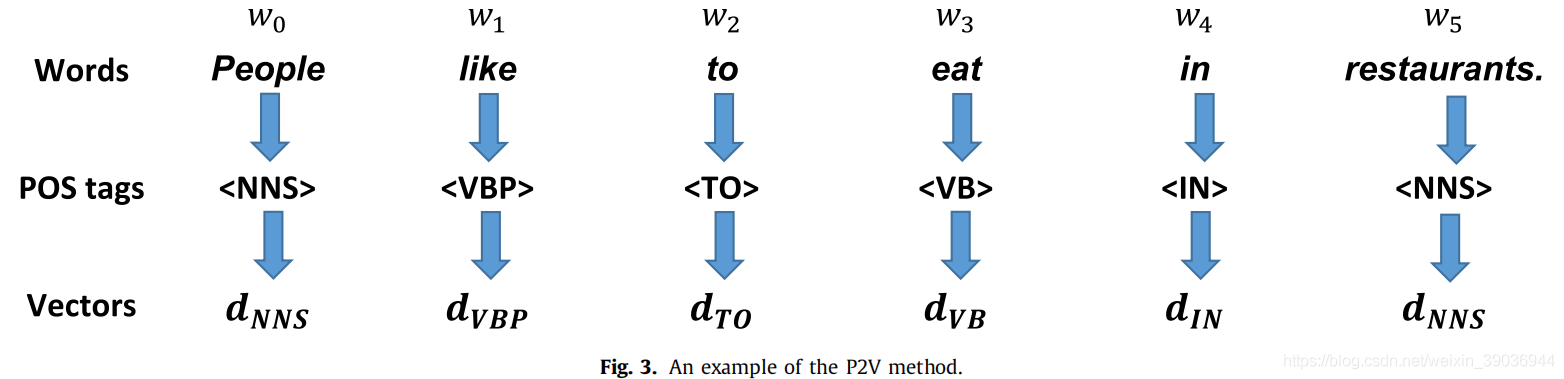
3.Word-position2Vec (Wp2V)
单词位置嵌入的主要思想是找到当前单词到一个文本的两端的相对距离,例如,People like to eat in the restaurants.其中like到people、restaurant的距离分别是-1、4。
通过这种方法,我们对每个源字在一个句子中的位置信息进行编码。

4. Word2Vec and GloVe
Word2Vec基于CBOW(词袋模型)和Skip-Gram。其中,CBOW是根据给出的上下文信息来预测当前单词;Sikp-Gram则是根据当前给出的单词来推测出该词的上下文信息。GloVe是一种全局对数双线性回归模型,是基于矩阵的共现和因式分解来得到向量的。
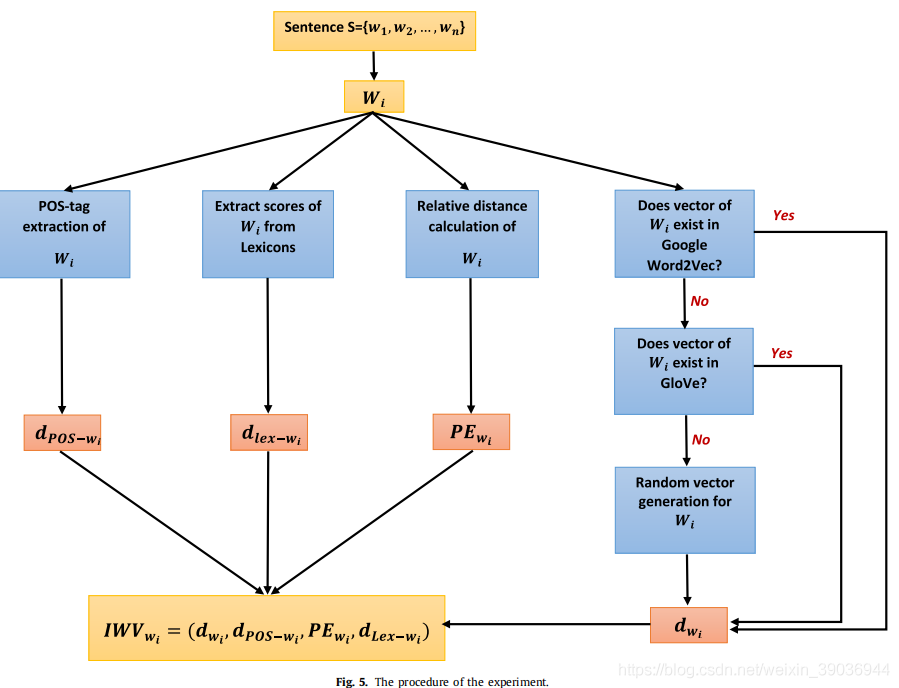
相关代码步骤:(1)在1-4行为每个POS标签分配一个常量向量。(2)6-12行从Word2Vec或GloVe数据集中提取输入句子的每个单词向量,如果一个单词不存在于数据集中,它的向量将随机生成。(3)确定句子中每个单词的POS标签,并为每个POS标签分配一个适当的向量。并在18和19行将位置嵌入向量加入当前生成向量(4)在所有词汇中提取出输入的每个单词的情感分数并将它们标准化。如果词汇中没有该词,那么该词的情感分数设为0;(5)将之前的向量融合生成最终改进后的词向量
举例:People like to eat in restaurants;
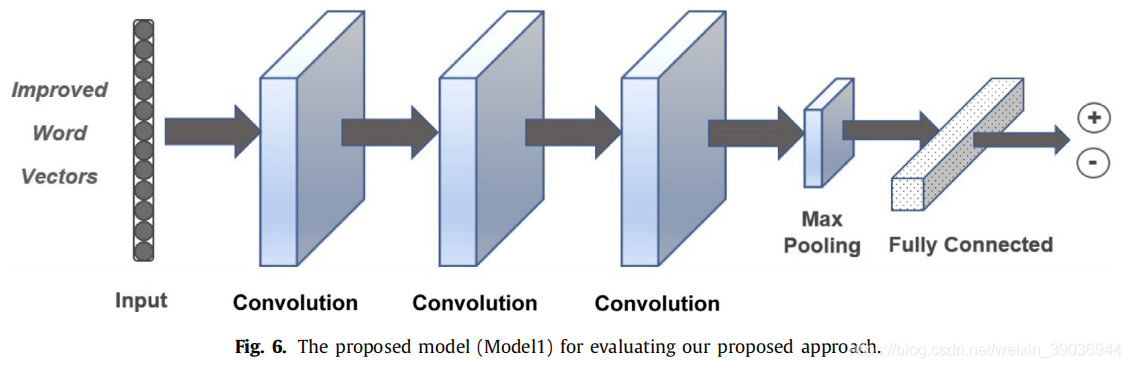
本文提出了一个深度学习模型(我们称之为模型1)来评估在上述六个数据集上生成的向量。该模型由三个卷积层、一个池和一个完全连接体组成模型的D层和输入是改进的字向量(I WV)。如下图所示:
除此之外,又引用了已发表的论文中介绍的三个深度学习模型(
Kim (2014)、
Deriu, Lucchi, Luca, Hofmann, & Jaggi, 2017;Severyn & Moschitti,2015; Wieting, Bansal, Gimpel, &Livescu,2016; Zhang & Wallace, 2015)来检测本文所提出的改进后的向量的准确度。
4. Experiments
1.Datasets
MR(有相同的积极和消极的句子的电影评论数据集,每个评论都包含一个句子)、CR(从亚马逊获得的14种产品的客户评论,分为正面评论和负面评论)、SST(斯坦福情感树库,只使用训练和测试句子和二进制标签(正,负)作为模型。该数据集由从电影评论中提取的11855个单句组成) 、RT(烂番茄电影评论数据集包含5331个正面评论和5331个负面评论)、SST-1(与SST相同,提供了培训/开发/测试拆分和细粒度标签(非常负、负、中性、正、非常正)。
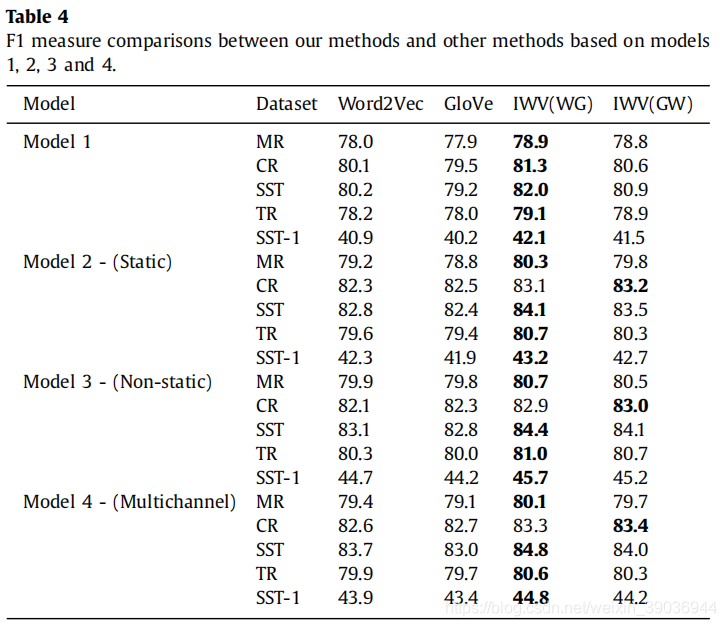
2.Results
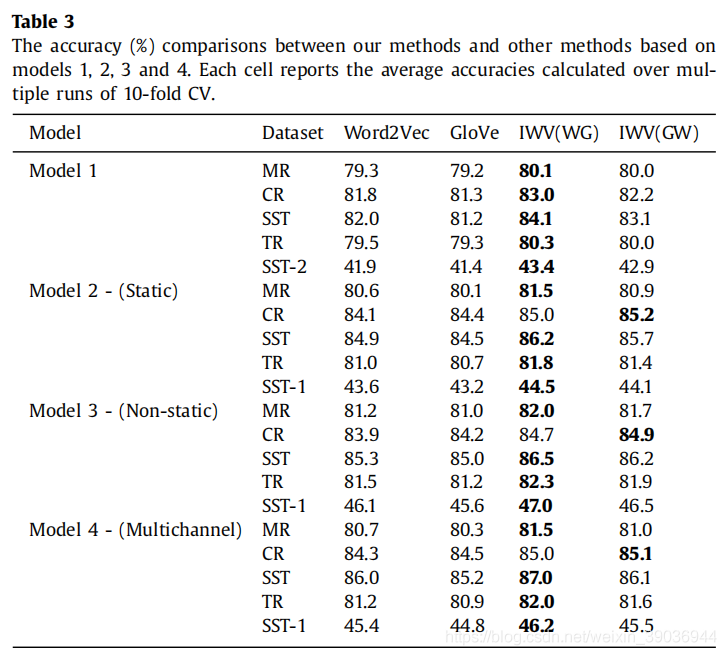
准确度对比和F1分数对比
除了上述两张表格的分析之外,作者还给出不同数据集的对比,均可以看出本文提出的方法在不同的模型和数据集中较之原来的预训练向量嵌入都明显提高了准确度。
5.总结
本文提出的改进词向量嵌入的方法在针对情感分析方面有明显成效,但其他文本分析任务方面尚未探讨。