目录
论文链接:https://aclanthology.org/2022.acl-long.145.pdf
标题翻译:基于方面情感分析的离散意见树归纳
论文链接:https://aclanthology.org/2022.acl-long.145.pdf
摘要
依赖树和图神经网络被广泛应用于基于方面的情感分类,尽管这些方法很有效,但它们都依赖于外部解析器,而外部解析器对于低资源的语言是不可用的,或者在低资源的领域表现更差。此外,依赖树也没有针对基于方面的情感分类进行优化。在本文中,我们提出了一个特定于方面以及和语言无关的离散潜在意见树的模型,作为显式依赖树的替代结构。为了简化复杂结构潜在变量的学习,我们在方面到上下文的注意分数和句法距离之间建立了一个联系,从注意分数中归纳出树。在六个英语基准数据集、一个中文数据集和一个韩语数据集上的结果表明,我们的模型可以达到具有竞争力的性能和可解释性。
1 引言
基于方面的情感分类(ABSA)是识别给定句子中特定方面类别或方面术语的情感极性的任务 (Jiang et al., 2011; Dong et al., 2014;Wang et al., 2016; Tang et al., 2016; Li et al., 2018;Du et al., 2019; Sun et al., 2019a; Seoh et al., 2021;Xiao et al., 2021)。与文档级情感分析不同,同一个文档中的不同方面术语可以承载不同的情感极性。例如,给定一个餐厅评论“装饰很好,但服务可能参差不齐”,对应的“装饰”和“服务”的情感标签分别是积极的和消极的。
如何为每个方面术语找到相应的意见上下文是ABSA面临的关键挑战。为此,最近的努力利用依赖树(Zhang et al., 2019; Sun et al., 2019a;Wang et al., 2020)。句法依赖已经被证明可以更好地捕获方面和意见上下文之间的交互(Huang et al., 2020; Tang et al., 2020)。例如,在图1(a)中,利用句法关系,我们可以发现“dector”和“service”对应的意见词分别是“nice”和“spotty”。

尽管依赖语法很有效,但它有以下局限性。首先,依赖解析器可能对低资源语言不可用,或者在低资源领域表现更差 (Duong et al., 2015; Rotman and Reichart, 2019; V ania et al., 2019; Kurniawan et al., 2021)。其次,依赖树也没有针对基于方面的情感分类进行优化。之前的研究通过手工制作的规则将依赖树转换为特定于方面的形式(Dong et al., 2014; Nguyen and Shirai, 2015; Wang et al., 2020),以提高方面情感分类性能。但是,树结构主要通过节点层次结构进行调整,没有优化ABSA的依赖关系。
在本文中,我们探索了一种简单的方法,为每个方面自动诱导一个离散的意见树结构。图一中显示了两个示例。特别是,给定一个方面和句子,我们的算法根据一组注意力得分递归地诱导出一个树结构,使用句子的BERT表示之上的神经层计算(Devlin et al., 2019)。该算法从根节点开始,通过在当前节点的每一侧选择一个子节点来构建树,并递归地继续分区过程,以获得二值化和词法化的树结构。生成的树作为输入结构,并被输入到图卷积网络(Kipf and Welling, 2017) ,用于学习情感分类器。我们研究了基于政策的强化学习(Williams, 1992) 来训练树诱导器。一个挑战是生成的策略很容易被BERT编码器记住,这导致探索不足(Shi et al., 2019)。为了缓解这个问题,我们提出了一组正则化器来帮助基于BERT的策略生成。
虽然我们的方法在概念上是简单和直接的推理阶段,我们表明它有深刻的理论基础。特别是,使用策略网络训练的基于注意力的树诱导解析器可以被视为标准潜在树结构VAE模型的简化版本(Kingma and Welling, 2014; Yin et al., 2018),其中先验和后载树概率之间的KL发散是通过基于注意的句法距离度量来近似的(Shen et al., 2018a)。
在六个英语基准、一个中国酒店评论数据集和一个韩国汽车评论数据集上的实验表明了我们提出的模型的有效性。离散结构也便于分类结果的解释。此外,我们的算法比全变分潜树变量模型更快、更小、更准确。据我们所知,我们是第一个使用BERT学习特定方面的离散意见树结构的人。我们在https://github.com/CCSoleil/dotGCN.上公开了代码。
2 模型
图2显示了我们提出的模型的体系结构。给定一个输入句子x和一个特定的方面术语a,我们根据一个识别网络推导出一个意见树t,其中
是网络参数的集合。我们在BERT输出向量上应用多层图卷积网络(GCNS)来建模意见树中的结构关系并提取特定方面的特征。最后,我们使用一个基于注意的分类器来学习情感分类器
,其中
是参数集。
为了训练模型,RL用于(章节2.3),标准反向传播用于训练
(章节2.2)。

2.1 基于意见树的分类器
意见树:将输入的句子表示为x = w1w2 . . . wn和方面a = wbwb+1 . . . we。[b, e]是[1,n]的连续跨度。Wi是第i个单词。如图1所示,a的意见树是二叉树。每一个节点包含一个词跨度和最多的两个子节点。a被放在根节点上。除根节点外,每个节点只包含一个单词。对t进行有序遍历可以恢复原来的句子。理想情况下,根节点附近的节点应该包含相应的意见词,例如“nice”对应“装饰”,“spotty”对应“服务”。
算法1展示了用结点分数函数v为a构建符合上述条件的意见树t的过程,其中vi表示对a的情感极性y有贡献的第i个单词的信息分数。是跨度[i,j]中对应单词的分数。我们首先将方面跨度[b,e]作为根节点,然后分别从跨度[1,b-1]和[e+1,n]构建它的左右子节点。要构建左子树和右子树,首先选择跨度中得分最大的元素作为子树的根节点,然后递归地对相应的跨度分区使用build_tree调用。

计算v:继Song et al.(2019)之后,我们将输入“[CLS] w1 w2……wn [SEP] wb wb+1……we”放到BERT当中得到方面特定的句子表示H,然后计算一组面向方面词的注意力得分。
![]()
其中是模型参数,
是ReLU激活函数,
是
求和池化的方面表示。
里面的
包含了BERT、
的模型参数。
图表示:给定t和H,我们使用GCNs来学习每个单词的表示向量。我们把t转换成一个无向图G。具体来说,我们将每个单词作为G中的一个节点,考虑四种类型的边,设计G的邻接矩阵A∈。首先,我们为每个单词包含self循环。其次,我们将方面术语中的每个词完全连接起来。第三,对于根节点的子节点wj,我们将wj连接到a中的每个单词。最后,我们考虑t中除了根节点之外的单个单词节点之间的边。形式上,A是由下面这个给出的:由公式2保证A是对称的。

然后我们使用GCNs来捕获词对之间的结构化关系,给定节点之间的领接矩阵A和(l-1)层的表示矩阵 ∈
,一个GCN给出的第l层表示
为:
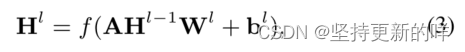
其中f为激活函数(即ReLU), ∈
和
∈
为第l层的模型参数。第一个GCN层
的输入是由句子编码器给出的H。
目标方面表示:我们考虑了“[CLS]”token()的表示向量和最后一层GCN层给出的方面向量(
,
...
)作为面向方面的表示向量,对输入句子表示
进行查询。最后一个方面特定的特征表示c在输入句子表示上是由注意层给出的。
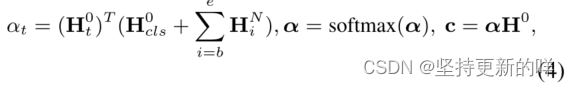
其中是a对
的注意得分,
是归一化得分,c是最终特征。
输出层使用c来计算情感极性得分,最后的情感分布由一个softmax分类器给出。
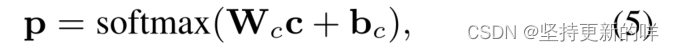
和
为模型参数,p是预测分布。
2.2 情感分类器的训练
交叉熵损失分类器通过最大化训练样本的对数似然来训练。形式上,目标是最小化(6)
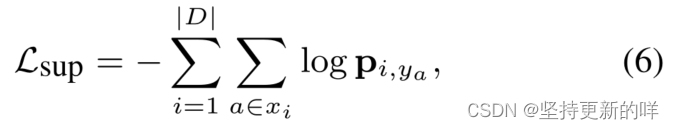
其中|D|为训练数据的大小,为第i个例子
和
中a的情感标签,ya为a的分类概率,由式子5给出。
中的模型参数集合
包括GCN块和等式5中的分类器参数。
树距离正则化损失继(Pouran Ben V eyseh et al. (2020)之后,我们引入了一个语法约束来正则化注意力权重。理想情况下,靠近根节点的单词应该得到较高的关注权重。给定一个意见树t,我们使用到根的最短路径的长度来计算每个单词i的树距离di。在给定距离和注意力分数α的条件下,我们使用KL散度来鼓励方面项参与距离较短的语境。

tdi为归一化树距离,KL为Kullback-Leibler散度。
反向传播在训练过程中,我们将算法1中的argmax操作符替换为随机采样,以探索更多离散结构。由于树抽样过程是一个离散的决策过程,它是不可微的。梯度可以从等式6中的Lsup传播到t和,但不能进一步从t传播到
。因此,我们使用REINFORCE(Williams, 1992) 给出的策略梯度来优化策略网络的
(2.3节)。
2.3 训练树诱导器
假设潜在树t的奖励函数为Rt,强化学习的目标就是最小化负期望奖励函数
![]()
对于每个t,我们使用情感似然对数作为Rt。使用REINFORCE,
相对于
的梯度为:

log(t|x,a)是生成的样本t的似然对数,它可以分解为每个建树步骤的似然对数的和。根据算法1,每次调用build_tree(
,i,j)都涉及到在给定分数
的情况下从跨度[i,j]中选择一个动作k。操作空间包含j-i+1个操作。这个动作的似然对数是由(10)给出的:
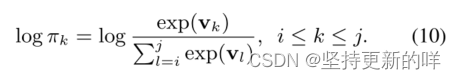
特别地,我们使用等式1中的作为得分函数v。枚举所有可能得树来计算等式9中的期望项是难以处理的,我们使用蒙特卡罗方法(Rubinstein and Kroese,2016),通过取M个样本来逼近训练目标:
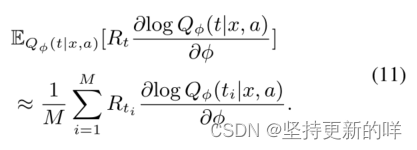
注意力一致性损失与单独依赖增强梯度来训练策略网络不同,我们还引入了注意一致性损失来直接监管策略网络。注意,在我们的模型中有两个注意力分数,第一个是等式1中定义的注意分数,由强化学习算法训练。第二个是等式4中定义的注意分数α,用于为特定于方面的分类器提取有用的上下文特征。α通过端到端方向传播训练。直观地说,获得最大关注分数的词应该是目标方面的有效意见词。因此,策略网络应该使其更接近根节点。为此,我们在两个注意分数之间实施一致的正则化,从而极性导向的注意α可以直接用于监督评分策略
。形式上Latt由(12)给出:
![]()
其中detach是一个停止渐变操作符。
总体损失最后总体损失是由(13)给出:
![]()
其中Lsup是监督损失,Lrl是强化学习损失,Latt是一种新的注意一致性损失,Ltd是一种通过树约束来引导注意分数分布的损失。λrl、λatt和λtd为超参数。
3 变分推理视角
有趣的是,Lsup, Lrl和Latt可以通过变分推理统一到一个理论框架中(Kingma and Welling, 2014)。我们在本节中展示,我们的方法可以被视为潜在树VAE模型的一个更强的扩展。
3.1 变分潜在树模型
为了建模(y|x, a),我们引入一个潜在的离散结构化变量t。形式上,训练目标是最小化负对数似然,
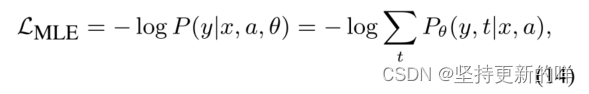
式子14计算所有可能树t的对数和,它是指数的。式子14可以通过使用变分参数φ的证据下界(ELBO)来近似(Kingma和Welling, 2014;Yin等人,2018),

其中(t|x, a)是生成潜在树的先验分布,
(t|x,y,a)是对应的后验分布,log
(y|x, a, t)是对数似然函数(假设潜在树t已经已知),
(t|x,y,a)[log
(y|x, a, t)]是通过考虑所有潜在树在
(t|x,y,a)上的期望对数似然函数。KL项作为正则子,强制匹配先验分布和后验分布。在训练过程中,使用
(t|x, y, a)来诱导树。对于推论,由于y仍然未知,所以使用
(t|x, a)。
在实践中,可以使用尺度超参数β来控制KL项的行为(Bowman et al, 2016b),
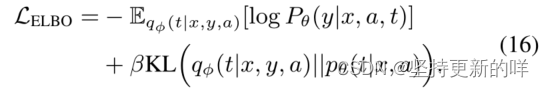
第一项是期望项,第二项是KL项。等式16是ABSA任务的标准VAE模型,但在研究文献中尚未讨论过。它可以使用树熵(Kim et al, 2019b)和神经互信息估计(Fang et al, 2019)进行训练。然而,这两种方法都很慢,因为它们都需要考虑大量的树样本。为了建模(t|x, y, a),我们改为通过类似于等式1的MLP层计算后验的得分函数
,
![]()
其中,
和
为参数,H '和
分别为给定y的后验句和方面表示。为了确保y能引导编码器,我们将输入序列和y一起输入BERT,使用“[CLS] w1 w2…wn [SEP] wf wf+1…wey"来得到H '。
3.2 与我们模型的相关性
我们的方法可以看作是对上述模型的一种新颖的简化,这可以通过将式子16中定义的期望项和KL项分别与式子1和式子4中的注意力得分相关联来证明。特别地,我们考虑将t转换为一种特殊类型的树距离,即方面到上下文注意分数。然后,我们将结构化树样本的概率分布委托给一组注意力分数。直观地说,如果注意力分数相似,生成的树应该高度相似。
近似期望项:考虑到第一个期望项关于φ的梯度是,
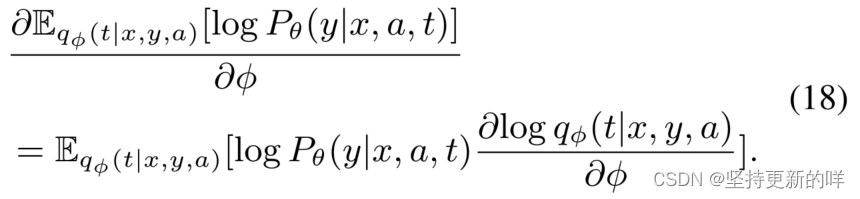
假设后验 (t|x,y,a)近似于识别网络给出的Qφ (t|x, a),等式18等价于Eq 11中的Lrl。
近似KL项:当β = λatt时,KL项与公式12中的Latt相似,即,
![]()
首先,我们将树样本的概率分布委托给一组注意力分数。特别地,我们分别使用和
作为pθ(t|x, a)和qφ (t|x, y, a)的代理。这相当于在训练过程中,将后验分数
和先验分数
馈送给算法1来推导相应的树。其次,由于等式4中的
和注意力得分α都直接由输出标签y监督,我们可以安全地假设
≈α。那么等式16中的KL项KL(
,
)就变成了KL(α,
),即等式12中定义的基于注意的正则化损失。
4 实验
我们在八个基于方面的情感分析基准上进行了实验,包括六个英语数据集,一个中文数据集和一个韩语数据集。数据统计见附录A.3。我们使用Stanza (Qi et al, 2020)作为外部解析器来生成依赖项解析,用于与基于依赖树的模型进行比较,报告每个模型的准确性(Acc.)和宏F1(F1)分数。更多细节见附录A.1。
MAMS Jiang等人(2019)提供了一个最近的挑战数据集,包含4297个句子和11,186个方面。我们将其作为主要数据集,因为它是一个大规模的多方面数据集,与其他数据集相比,每句话中的方面更多。MAMS-small是MAMS的一个小版本。
Chinese hotel reviews dataset Liu等人(2020)为多目标情感分析提供了手动注释的6,339个目标和2,071个项目。
Korean automotive comments dataset Hyun等(2020)提供了一个有30032个韩国语评论方面对的数据集。
SemEval datasets 我们使用了五个SemEval数据集,包括Dong的twitter帖子(twitter)。Pontiki等人(2014)提供的笔记本电脑评论(laptop), SemEval 2014 task4的餐厅评论(Rest14;Pontiki等人2014),SemEval 2015 task 12 (Rest15;Pontiki等人2015)和SemEval 2016 task5 (Rest16;Pontiki et al 2016)。按照Tang et al(2016)和Zhang et al(2019)对这些数据集进行预处理。
4.1 基线
我们将我们的模型表示为dotGCN(离散意见树GCN),与基于bert的模型进行比较,包括不使用树的模型和基于依赖树的模型。此外,变分推断基线(章节3.1)记为viGCN。基线是(1)BERT- SPC是一个简单的基线,通过微调Jiang等人(2019)的BERT的“[CLS]”向量;(2)AEN。Song等人(2019)使用BERT的注意编码器;(3) CapsNet。Jiang等(2019)将胶囊网络与BERT结合;(4) Hard-Span。Hu等人(2019)使用RL来确定特定方面的意见跨度;(5) depGCN。Zhang等人(2019)在依赖树上应用了特定于方面的GCNs;(6) RGAT。Wang等人(2020)在以方面为中心的依赖树上使用关系图注意网络来合并依赖项边缘类型信息;(7) SAGAT。Huang等人(2020)使用图注意网络和BERT,探索序列中的语法和语义信息;(8) DGEDT。Tang等人(2020)通过双向GCN共同考虑BERT输出和基于依赖树的表示。(9) kumaGCN。Chen等(2020)结合了依赖树和自注意神经网络诱导的潜在图;
4.2 开发结果
我们使用MAMS进行开发实验,因为这是最大的数据集,与其他数据集相比,示例更具挑战性。我们实现三个基线,包括BERT-SPC, depGCN和kumaGCN。为了进行公平的比较,我们还通过计算输入依赖树上关于方面项的语法距离,将depGCN和kumaGCN与式子7中的语法正则化损失结合起来。
表1显示了MAMS验证集上的结果。BERT-SPC的准确率为84.08,F1为83.52。令人惊讶的是,基于依赖树的模型不能优于BERT-SPC,它验证了使用跨域依赖解析器完成这项任务的局限性。kumaGCN优于depGCN,因为它能够包含隐式潜在图。添加语法正则化损失通常会提高基于语法的模型的性能。特别是,kumaGCN + Ltd与BERT-SPC不相上下。
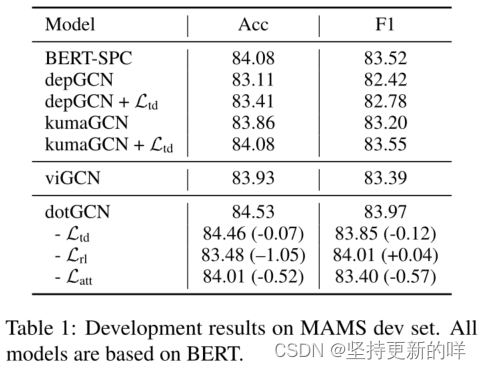
viGCN的性能优于kumaGCN + Ltd和depGCN + Ltd,显示了结构化潜树模型的潜力。我们的dotGCN模型达到了84.53的准确率和83.97的F1,大大优于所有的基线,经验表明,诱导离散意见树是有希望完成这项任务。与viGCN相比,我们的模型给出了更好的分数。此外,我们的模型收敛速度快了近1.8倍(0.66h/epoch vs 1.25h/epoch)。dotGCN不需要计算结构化树样本上的真实后验分布,从而大大减少了计算开销。
消融实验 表1显示了在MAMS验证集上的消融研究,在训练期间去除三个提议的损失项目,即Ltd, Lrl和Latt。我们可以观察到,删除其中任何一个后,模型性能都会下降。删除语法正则化损失会略微影响性能。如果不使用注意一致性损失Latt,该模型落后于BERT-SPC,这表明了我们提出的注意一致性正则化的重要性。在三种设置中,剔除强化学习损失导致的性能下降最大(Acc: 84.53→83.48)。这表明强化学习组件在整个模型中起着核心作用。
4.3 主要结果
MAMS 表2显示了dotGCN的结果和Jiang等人(2019)在MAMS测试集上的基线。我们实现了BERT-SPC,记为BERT-SPC∗,其性能优于Jiang等人(2019)的BERT-SPC模型。与不使用依赖树的基线(BERT-SPC、CapsNet、CapsNet- dr和BERT-SPC∗)相比,dotGCN的结果显著更好(p < 0.01)。为了与基于依赖树的模型进行比较,我们还实现了depGCN+和kumaGCN+
。depGCN+
在MAMS测试集上的精度为84.36,F1为83.88。kumaGCN+
给出了类似的结果,精度为84.37,F1为83.83。我们的dotGCN优于所有基线,给出84.95的精度和84.44的F1。在MAMS和MAMS-small上F1评分的平均准确度方面,dotGCN显著优于depGCN和kumaGCN (p < 0.05)。结果表明,诱导的面向特定方面的离散意见树有望处理多方面的情感任务。
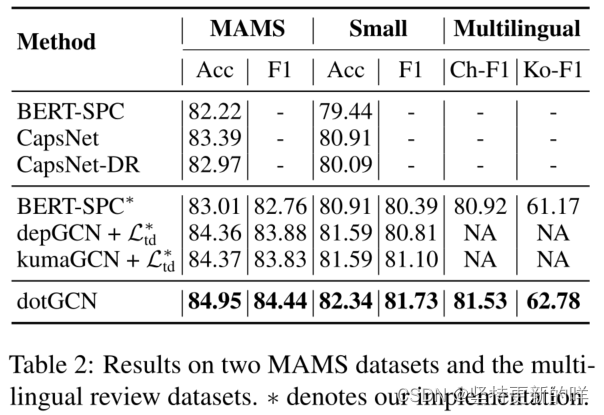
Multilingual 中国酒店评论数据集的结果如表2所示。dotGCN分别优于基线BERT-SPC * 0.72个精度点和0.61个F1。结果表明,我们的模型可以跨语言泛化,而不依赖于特定于语言的解析器。在韩国数据集上,与LCF-BERT (Zeng et al, 2019)相比,我们获得了5.20的精度和11.61 F1的改进,这是最好的基于bert的模型。这些结果表明,我们的模型可以很好地推广到多种语言,并且可能会为这项任务的低资源语言带来潜在的好处。
SemEval 表3显示了我们的模型在SemEval数据集上的结果。首先,基于树的图神经网络模型通常优于BERT-SPC。在五个相对较小的数据集上,我们的模型在平均F1和精度分数方面仍然具有竞争力,如表3所示。特别地,我们的模型在五个数据集中的四个上优于depGCN和depGCN + ,这验证了与自动解析的依赖树相比,增强的离散意见树可以是有希望的结构化表示。

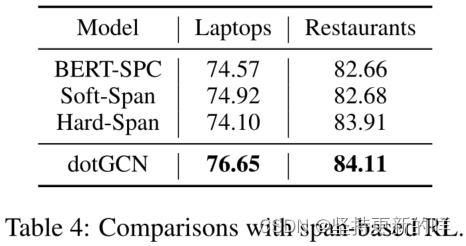
我们还将我们的模型与基于跨度的强化学习模型(Hard-Span;Hu等人 (2019))在Tay等人(2018)预处理的笔记本电脑和餐厅数据集上。如表4所示,在笔记本电脑上,我们的模型比Hard-Span高出2.55个精度点。在餐馆方面,我们的模型获得了与Hard-Span相当的结果。这表明,与意见跨度相比,意见树是更好的表示。
4.4 案例研究
图3a和图3b分别显示了方面术语“扇贝”的诱导树和依赖项解析。意见词“unique”和“tasty”在依赖树中距离方面(超过10个词)较远。在dotGCN的诱导树中,观点词“tasty”和“unique”分别距离方面词“扇贝”2和3个深度,这表明dotGCN可以潜在地处理方面和观点上下文之间的复杂交互。此外,dotGCN诱导的树被二值化,根节点可以包含多个单词,如图4a所示。
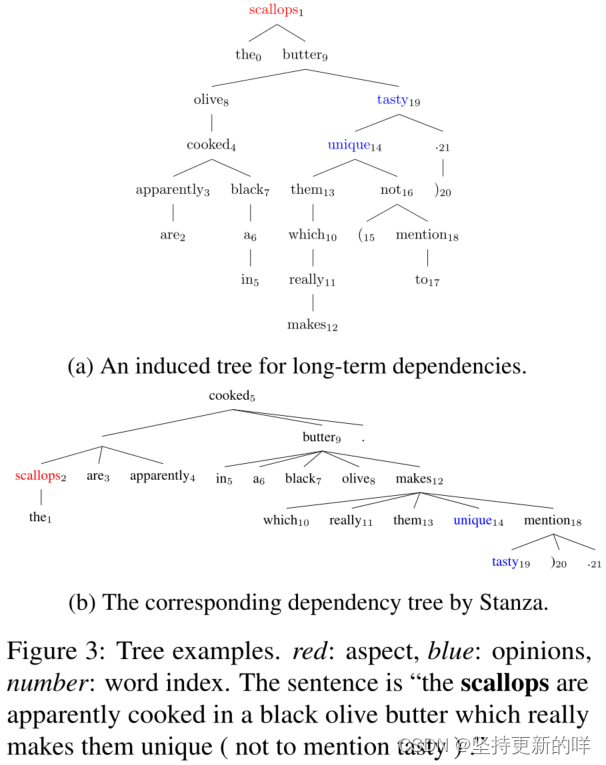
图4a和图4b显示了两个不同情绪极性的方面项的诱导树。对于“creme brulee”,政策网络给“delicious”和“savory”都赋予了很高的权重。有趣的是,它赋予“delicious”比“savory”更高的权重,尽管“savory”比“delicious”更接近它的方面术语。对于“appetizer”,“interesting”这个词比其他两个情感词汇获得了更高的关注分数。这些结果表明,dotGCN能够区分同一句中不同方面术语的不同情感上下文。

4.5 分析
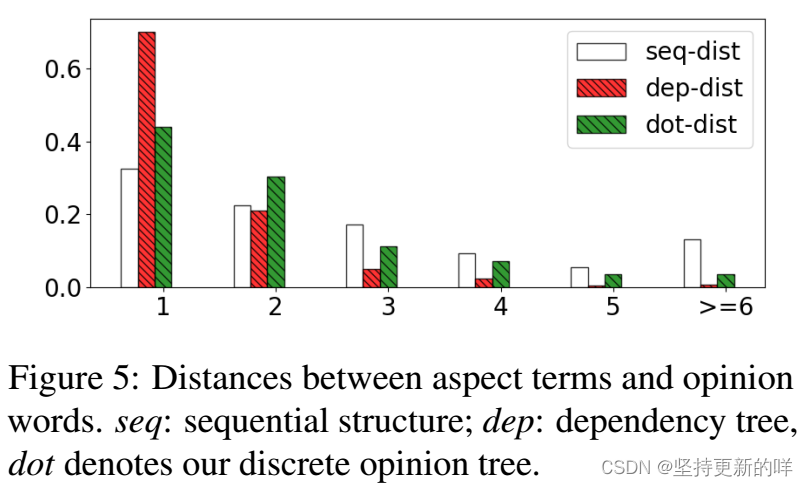
方面术语和观点词之间的距离 图5显示了方面术语和意见词之间的距离。我们使用了Fan等人提供的Rest16注释意见词(2019),比较我们的诱导树和依赖树。在原始序列上计算的距离也包括在内。我们可以观察到,与树形结构相比,序列上的距离分布相对平坦。在这两种树结构中,近90%的观点词距离方面词的深度在3个以内。我们的诱导树的距离分布与依赖树的距离分布相似,这从经验上证明了诱导离散树能够捕捉方面术语和意见之间的相互作用。通过将依赖树作为金标准,我们的树诱导器获得了35.4%的未标记依恋分数(UAS),这表明诱导树与依赖树有显著不同,尽管两者都可以连接意见词和方面术语。
低频率方面 表5显示了MAMS测试集相对于纵横频的分类精度。对于训练语料库中出现的方面项,两种方法都给出了相似的结果。但是,对于不可见的方面,dotGCN的结果比depGCN好。这可能是由于低频率方面的严重解析错误造成的。dotGCN不依赖于外部解析器,因此可以避免这个问题。实验表明,与depGCN相比,诱导树结构在捕获方面意见交互方面具有较强的鲁棒性。
5 相关工作
ABSA的树诱导 在无监督离散诱导方面已经有很多工作(Bowman等人,2016a;Shen等 2018b;Kim等,2019b,a;Jin等,2019;曹等,2020;Yang等,2021;Dai等人,2021),其目的是在没有显式语法注释和任务依赖的监督信号的情况下获得一般的组成树。我们专注于学习ABSA的特定于任务的树结构,其中树是完全二值化和词汇化的。Choi等人(2018)提出了Gumbel Tree LSTM用于学习语义组成的特定任务树。同样,Maillard等人(2019)提出了一种无监督的图表解析器,用于联合学习句子嵌入和语法。但是,它们主要关注句子级别的任务,而不考虑方面信息。
方面级情感分类 最近的许多工作都探索了这一任务的神经注意机制(Tang等人,2016;Ma等 2017;李等,2018;Liang等,2019)。在基于树的方法中,Zhang等人(2019)和Sun等人(2019b)使用GCN对依赖树进行方面级情感分析; 赵等(2019)使用GCN建模方面项之间的全连通图;Wang等人(2020)使用关系图注意网络来合并依赖边类型信息,并构造特定于方面的图结构; 巴恩斯等人(2021)尝试直接预测基于依赖关系的情绪图。Tang等人(2020)使用双变压器结构来增强该任务的依赖关系图。我们的工作类似于我们也考虑结构依赖关系,但不同之处在于我们依赖于自动诱导的树结构而不是外部解析。Chen等人(2020)提出通过从基于自我注意的Hard Kumaraswamy分布(Bastings等)中采样来诱导方面特定的潜在图。然而,为了获得具有竞争力的性能,他们的方法仍然需要外部依赖解析树和诱导潜在图的组合。
Sun等人(2019a)和Xu等人(2019)构造了方面相关的辅助句作为BERT (Devlin等人,2019)的输入,用于加强上下文编码器。Xu等人(2019)提出了基于bert的岗位培训,用于增强面向方面情感分析的特定领域上下文表示。我们的工作分享了类似的特征提取方法,但不同的是,我们专注于为ABSA诱导潜在树。
6 总结
我们提出了一种方法,用于基于方面的情感分析,通过查看方面到上下文的注意分数作为句法距离来获得树。注意力分数是使用RL和一种新的基于注意力的正则化来训练的。与基于依赖树的模型相比,我们的模型在独立于解析器的情况下获得了具有竞争力的性能。我们也提供了一个理论观点,我们的方法使用变分推理。