Overview
1.Text Classification:
In this assignment, you will use scikit-learn, a machine learning toolkit in Python, to implement text classifiers for sentiment analysis. Please read all instructions below carefully.
2. Datasets and evaluation:
You are given the following customer reviews dataset: CR.zip, which includes positive and negative reviews. CR is a small dataset that doesn’t have train/test divisions, so you are required to evaluate the performance using 10-fold crossvalidation. Please use the following scikit-learn modules in your implementation:
scikit-learn documentation:
Bag-of-words (or ngrams) feature extraction using CountVectorizer: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html Use binary features (1/0 rather than counts).
Naïve Bayes classifier: http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html
Logistic Regression classifier: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
Cross validation: http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html
Classification report: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html
Targets
Part1:
Using the scikit-learn modules described above, Implement the following models and report the performance (accuracy and F1) for the CR dataset:
a) A Naïve Bayes classifier with add-1 smoothing using binary bagof-words features.
b) A Naïve Bayes classifier with add-1 smoothing using binary bagof-ngrams features (with unigrams and bigrams).

c) Logistic Regression classifier with L2 regularization (and default parameters) using binary bag-of-words features.
d) Logistic Regression classifier with L2 regularization using binary bag-of-ngrams features (with unigrams and bigrams).
part2:
[optional bonus question]
In this part, you are asked to implement a model that combines the advantages of generative and discriminative models: a logistic regression classifier with Naïve Bayes features.
In Naïve Bayes, we used the MLE probabilities of words/bigrams given a class label. We can use the ratio of these probabilities as features in logistic regression. Define the count vector for the positive class p as the smoothed sum of features for all instances that belong to that class:

where f(xi) is the binary feature vector for example xi. Each element in p is the count for a specific word/bigram with add-1 smoothing. Similarly, the count vector for the negative class q is defined as:
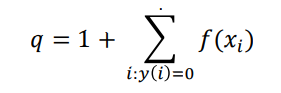
The log-count ratio is defined as:
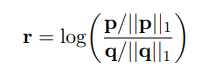
which is the ratio of the positive to negative likelihoods for each word/bigram (the ||x||1 notation is the L1 norm, which is the vector sum since all features are nonnegative). Now instead of using the binary feature vectors f(xi) as input to the logistic regression classifier, use the element-wise product of the log-count ratio vector and each feature vector: r ⊙ f(xi)
Report the performance of this model on the CR dataset using the two sets of features: (a) bag-of-words only, and (b) bag-of-ngrams (unigrams and bigrams).
Process Data
For the following function, set the ngram_range = (1, 1) when only using bag-of words. Set the ngrame_range = (1, 2) when using unigrams and bigrams. Set R = True to calculate the new count vectors and log-count ratio for the bonus quesion.
def create_data(ngram_range, R=False):
"""
neg_Y is 0, pos_Y is 1
:return: train_neg, train_pos, test_neg, test_pos
"""
if R:
neg_doc = read_data(neg=True)
pos_doc = read_data(neg=False)
neg_length = len(neg_doc)
whole_doc = neg_doc + pos_doc
doc = transfer_2_countVectorizer(whole_doc, ngram_range)
neg_doc = doc[:neg_length]
pos_doc = doc[neg_length:]
p = np.sum(pos_doc, axis=0) + 1 # sum of each column and add-1 smoothing
q = np.sum(neg_doc, axis=0) + 1
r = np.log((p / sum(p)) / (q / sum(q)))
pos_doc = np.multiply(r, pos_doc)
neg_doc = np.multiply(r, neg_doc)
else:
neg_doc = read_data(neg=True)
pos_doc = read_data(neg=False)
neg_length = len(neg_doc)
whole_doc = neg_doc + pos_doc
doc = transfer_2_countVectorizer(whole_doc, ngram_range)
neg_doc = doc[:neg_length]
pos_doc = doc[neg_length:]
"""
# split into 9/10 train 1/0 test manually
length = int(neg_doc.shape[0] * 9 / 10)
train_neg = neg_doc[:length]
train_neg_Y = np.array([0] * length)
test_neg = neg_doc[length:]
length = int(pos_doc.shape[0] * 9 / 10)
train_pos = pos_doc[:length]
train_pos_Y = np.array([1] * length)
test_pos = pos_doc[length:]
train_X = np.concatenate((train_neg, train_pos), axis=0)
train_Y = np.concatenate((train_neg_Y, train_pos_Y), axis=0)
return train_X, train_Y, test_neg, test_pos, whole_doc
"""
# by using the 10-fold cross validation function, we do not need to split the data ourselves
input_X = np.concatenate((neg_doc, pos_doc), axis=0)
input_Y = np.concatenate((np.array([0] * neg_doc.shape[0]), np.array([1] * pos_doc.shape[0])), axis=0)
return input_X, input_YModel
Naïve Bayes with add-1 smoothing:
class NaiveBayes:
def train(self, train_X, train_Y):
clf = MultinomialNB(alpha=1.0, fit_prior=True) # alpha = 1 add 1 smoothing
clf.fit(train_X, train_Y)
self.clf = clf
def predic(self, test_data):
return self.clf.predict(test_data)
def crossValidate(self, inputX, inputY):
clf = MultinomialNB(alpha=1.0, fit_prior=True)
predicted = cross_val_predict(clf, inputX, inputY, cv=10)
target_names = ['neg', 'pos']
return classification_report(inputY, predicted, target_names=target_names)Logistic Regression with L2 regularization:
class LogisticRegressionModel:
def train(self, train_X, train_Y, max_iter):
clf = LogisticRegression(max_iter=max_iter, random_state=0, solver='lbfgs',
multi_class = 'multinomial', penalty='l2').fit(train_X, train_Y)
self.clf = clf
def predic(self, test_data):
return self.clf.predict(test_data)
def crossValidate(self, inputX, inputY, max_iter):
clf = LogisticRegression(max_iter=max_iter, random_state=0, solver='lbfgs',
multi_class='multinomial', penalty='l2')
# cv_results = cross_validate(clf, inputX, inputY, cv=10, return_train_score = False)
predicted = cross_val_predict(clf,inputX, inputY, cv=10)
target_names = ['neg', 'pos']
return classification_report(inputY, predicted, target_names=target_names)K-folds Cross Validation:

I put the 10-folds cross validation on the function crossValidate on each model. If we just want to train the data and predict some new unlabeled data, we can use the other two functions train and predic.
Result
For this homework, output precision, recall, f1-score and support to show each model's performance.
1. A Naïve Bayes classifier with add-1 smoothing using binary bagof-words features.

2. A Naïve Bayes classifier with add-1 smoothing using binary bagof-ngrams features (with unigrams and bigrams).

3. Logistic Regression classifier with L2 regularization (and default parameters) using binary bag-of-words features.

4. Logistic Regression classifier with L2 regularization using binary bag-of-ngrams features (with unigrams and bigrams)

optional bonus question
Use the new feature: r ⊙ f(xi). In this project, use the folowing function to calculate this kind of new feature.
create_data(ngram_range, R=True) 5. a logistic regression classifier with Naïve Bayes features (bag-of-words only).

6. bag-of-ngrams (unigrams and bigrams)
