The code and data for this paper are available at https://github.com/HKUST-KnowComp/DMSCMC
Abstract
文档级别的多aspact情感分类对于顾客关系管理是一个重要的任务,在我们的论文中,我们将任务建模为机器理解问题, 其中伪 question-answer 对是由少数aspect相关的关键字和aspect评分构造的。提出了一种分层迭代注意模型, 通过文档和方面问题之间的频繁重复交互来构建 aspect-specific 表示。我们采用层次结构来表示单词级别和句子级别信息, 并使用the attention operations 或者the multiple hop mechanism 来处理aspect问题和文档。TripAdvisor 和 BeerAdvocate 数据集的实验结果表明, 我们的模型优于经典基准。
Introduction
仅仅预测文本情感通常是不够的,因为一个评论文本通常涉及产品和服务的不同方面,如下所示,并且用户比起aspect的评估更喜欢提供整体的评估,因此,文本级别的多aspect情感分类任务很有意义,即预测每个aspect的分数,而不是总体的分数。

- 一个直观的document-level multi-aspect sentiment classification 方法是多任务学习(Caruana, 1997 )。
- 而对于神经网络,我们能够简单的对于每个aspect当作一个分类任务,然后让不同的任务在顶层使用solftmax分类器来抽取task-specific 的表示,同时将输入和隐藏层相互共享提高预测结果相互(Collobert et al., 2011; Luong et al., 2016) 。
但是,这些方法忽略了aspect本身也具有语义信息。比如说,对于人类而言,如果让我们对一个文本进行aspect评估,我们首先会简单阅读这个文档,然后找到aspect-related的关键词,然后看关键词周围的评论,最后将所有有关的片段统计起来进行判定。
在本文中,我们提出了一个新型的当作机器理解问题(Kumar et al., 2016; Sordoni et al., 2016) 的方法来做document-level multi-aspect 情感分析.为了模仿人类分析aspect的过程,我们为每个aspect创建了一系列关键词,比如当我们处理关于room的aspect时,我们生成一些关键词“room,” “bed,” “view,” etc ,然后我们可以询问虚假的问题:“How is the room?” “How is the bed?” “How
is the view?” 并且提供答案“Rating 5.” 在这种情况下, 我们可以训练一个机器理解模型, 以自动进入评论文件相应的文本片段, 来预测aspect评分。具体来说, 我们引入了分层和迭代注意模型来构造面向aspect的表示。我们使用分层体系结构在单词和句子级别上建立aspect问题交互的不同的表示形式。在每个级别, 该模型由输入编码器和迭代注意模块组成。输入编码器通过双向 LSTM (双 LSTM) 模型和非线性映射分别学习文档和问题的记忆。迭代注意模块将记忆作为输入, 并以多个跃点机制依次参加它们, 在文档和方面问题之间进行有效的交互。
本文的贡献是两个方面。
首先, 我们研究了文档级多aspect情绪分类作为机器理解问题, 并引入了分层迭代注意模型。其次, 我们证明了模型在两个数据集上的有效性, 表明我们的模型优于经典基线。
Experiment
Datasets :
1.TripAdvisor (Wang et al., 2010) :seven aspects (value, room, location, cleanliness, check in/front desk, service, and business service)
2. BeerAdvocate(McAuley et al., 2012; Lei et al., 2016) :four aspects (feel, look, smell, and taste)
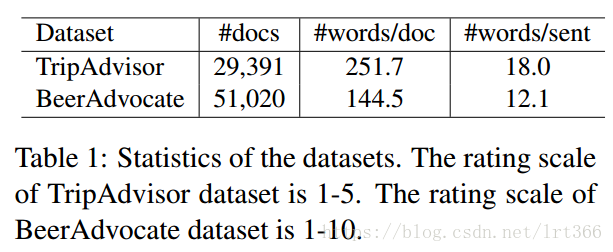
根据这个方法(Lei et al., 2016) ,通过选择不同aspect评级的评论,构造的新数据集如下表1,我们对这个数据集用Stanford corenlp 分词并且随机把他们按照80/10/10% 的比例切分成training, development, 和testing sets
Implementation Details
我们用theano完成所有的神经模型(Theano Development Team, 2016) 。模型的参数和调整基于development sets. 。我们用with Skip-gram model (Mikolov et al., 2013) 在领域语料库用这个(Tang et al., 2015a)方法学习200维的词向量,这个预训练的词向量用老初始化向量矩阵EA 和EB,所有隐藏向量的维度设为200。
对于TripAdvisor ,单词级和句子级迭代注意模块的跃点数分别设置为4和2。
对于BeerAdvocate ,单词级和句子级迭代注意模块的跃点数分别设置为6和2。
被选择的关键词NK=N被设为20
为了避免过拟合,我们使用dropout 和正则化方式如下:
- 将正则化参数设为1e-5
- dropout rate 设为0.3,应用在句子和文档向量上
所有参数通过ADADELTA (Zeiler, 2012) 这个方法训练,即不需要设置初始学习率。Baseline用一样的参数设置。
3.4 Results and Analyses
我们使用精度和平均平方误差 (MSE) 作为评估指标和结果显示在表2中。
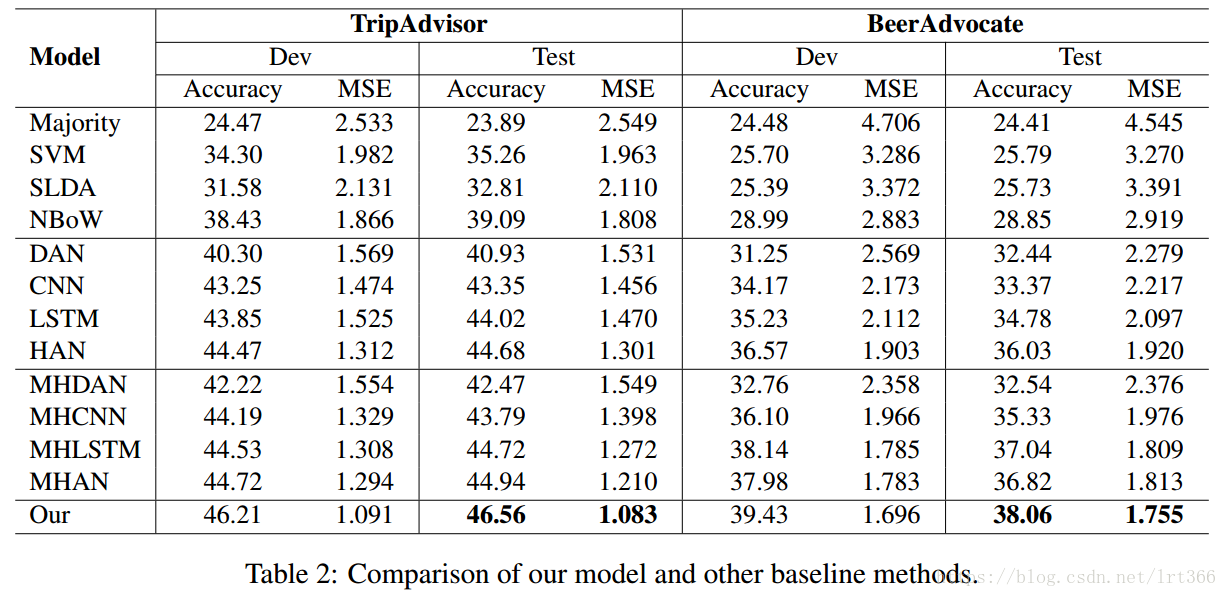
与支持向量机和 SLDA 相比, NBoW 在两个数据集中实现了较高的精度 3%, 这表明嵌入特征比传统的 ngram 特征在这两个数据集上更有效。所有的神经网络模型都优于 NBoW。说明了神经网络在文献情绪分类中的优越性。
从神经网络的结果可以观察到 DAN 的表现比 LSTM 和 cnn 差, 而 LSTM 的结果比 cnn 稍高。可以解释的是, 简单的组合方法在文档中平均嵌入词, 但忽略了语序, 可能不像其他灵活的组合模型, 如 LSTM 和 CNN, 对方面的分类有效。此外, 我们还观察到, 多任务学习和层次结构有利于神经网络。在所有基线中, MHAN 和 MHLSTM 达到比较的结果, 胜过其他的。
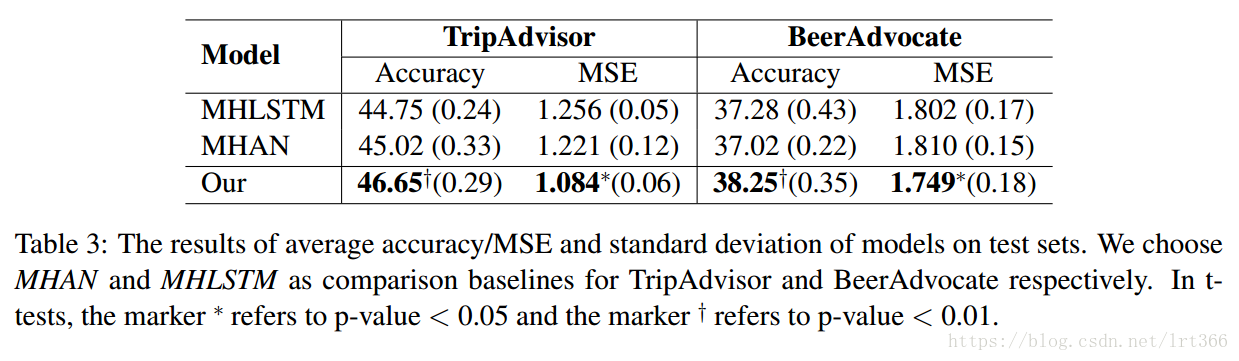
与 MHAN 和 MHLSTM 相比, 本方法分别对 TripAdvisor 和 BeerAdvocate 进行了 1.5% (3% 相对改进) 和 1.0% (2.5% 相对改进) 的改进, 表明迭代注意机制的引入有助于基于深神经网络的模型建立了更具判别性的方面感知表示。请注意, BeerAdvocate 相对比较困难, 因为预测的收视率是从1到 10, 而 TripAdvisor 是1到5。此外, t 测试是通过随机将数据集分解成训练/开发/测试集和随机初始化进行的。测试集的结果在表3中描述, 显示了我们模型的性能是稳定的
Case Study for Attention Results
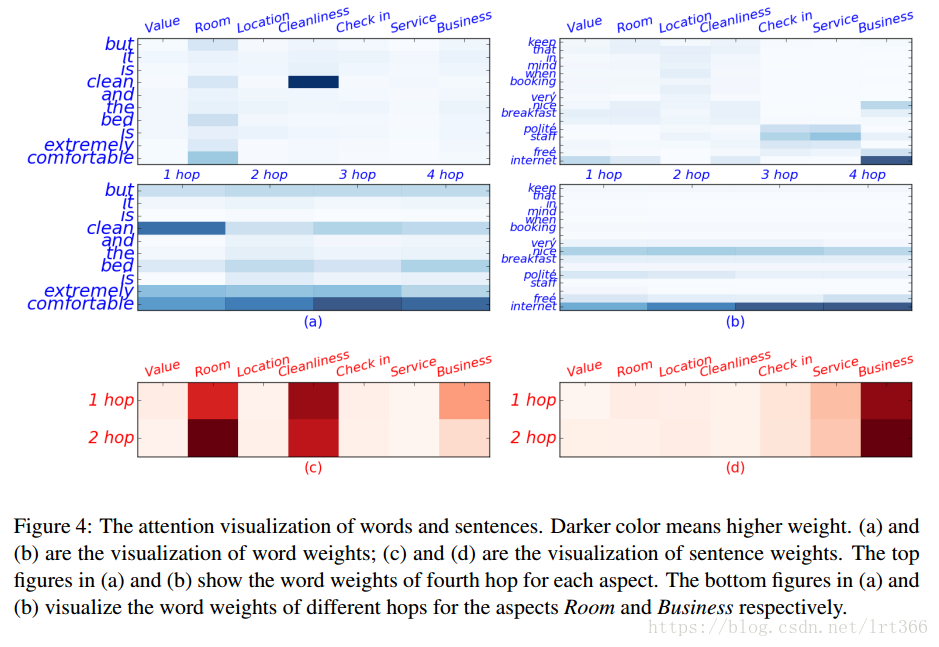
在本节中, 我们从 TripAdvisor 中抽取两个句子, 以显示注意结果的可视化。在图4中显示了单词级和句子级的注意力可视化。我们通过句子权重对单词权重进行规范化, 以确保只突出显示文档中的重要单词。
从 (a) 和 (b) 的顶部数字, 我们观察到我们的模型为每个方面分配不同的注意权重。例如, 在第一句中, "舒适" 和 "床" 在 "纵横" 房间里被赋予更高的权重, 而 "干净" 一词则由 Cleaniness 的角度突出。在第二句中, 互联网这个词被赋予了高度关注的商业价值。此外, (a) 和 (b) 的底层数字表明 (1) 不同跃点数的词权重是多种多样的;(2) 高跃点的注意值更合理。具体地说, 在第一句中, 单词干净的重量高于第一跃点的 "舒适", 而在更高的跃点数中, 舒适胜过干净。在第二句中, 我们观察到词的网络价值随着跃点数的增加而增大。因此, 我们可以看到, 通过提出的迭代注意机制, 为单词获得更合理的权重。同样地, 数字 (c) 和 (d) 表明, 从词的结论也适用于句子。对于第一句来说, 在第一个跃点上, 对于 "纵横" 房间的句子权重要低于清洁度, 但在第二跳中超过了清洁度。第二句话, 在第二个跃点, 业务的权重变得更高。
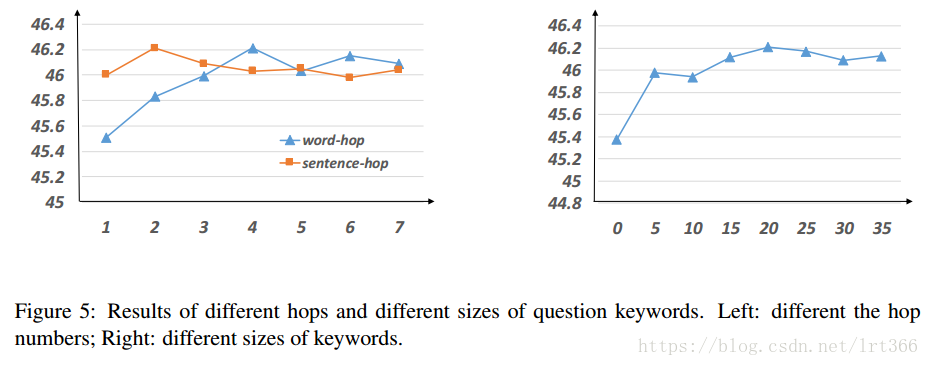
Effects of Hop and Aspect Keywords
在本实验中, 我们研究了跃点数 m 和尺寸的关键字 N 对性能的影响。所有的实验都是在开发集上进行的。由于空间不足, 我们只呈现 TripAdvisor 的结果, BeerAdvocate 的结果与 TripAdvisor 相似。
对于跃点数, 我们从1到7不等, 结果如图 5 (左) 所示。我们可以看到: (1) 在词级时, 当 m ≤4时, 性能会增加, 但在 m 4 之后却没有改善;(2) 在句子层次上, 当 m = 2 时, 模型执行得最好。此外, 我们可以看到, 词级的跃点数导致的变化比句子级别的跃点数大。
对于纵横关键字的大小, 我们从0到35不等, 递增5。请注意, 当 N = 0 时, 我们设置一个好学向量来表示问题内存。结果如图5所示 (右)。我们观察到, 当 n ≤20时, 性能增加, 并且在 n 20 之后没有改善。这表明少量关键字可以帮助建议的模型实现竞争结果
Conclusion
本文将文档级多方面情绪分类模型作为文本理解问题, 提出了一种新的递阶迭代注意模型, 其中文档和伪方面问题在两个词之间交错,在统一模型中学习具有方面意识的文档表示的句子级别。广泛的实验表明, 我们的模型优于其他神经模型的多任务框架和层次结构